
| | |  Lihat sumber di GitHub Lihat sumber di GitHub |
Tutorial ini memberikan contoh cara menggunakan data CSV dengan TensorFlow.
Ada dua bagian utama untuk ini:
- Memuat data dari disk
- Pra-pemrosesan menjadi bentuk yang cocok untuk pelatihan.
Tutorial ini berfokus pada pemuatan, dan memberikan beberapa contoh prapemrosesan cepat. Untuk tutorial yang berfokus pada aspek prapemrosesan, lihat panduan dan tutorial lapisan prapemrosesan.
Mempersiapkan
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
Dalam data memori
Untuk kumpulan data CSV kecil, cara paling sederhana untuk melatih model TensorFlow adalah dengan memuatnya ke dalam memori sebagai pandas Dataframe atau array NumPy.
Contoh yang relatif sederhana adalah kumpulan data abalon .
- Kumpulan datanya kecil.
- Semua fitur input adalah semua nilai floating point rentang terbatas.
Berikut cara mendownload data ke dalam Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
Dataset berisi satu set pengukuran abalon , sejenis siput laut.

"Cangkang abalon" (oleh Nicki Dugan Pogue , CC BY-SA 2.0)
Tugas nominal untuk kumpulan data ini adalah memprediksi usia dari pengukuran lain, jadi pisahkan fitur dan label untuk pelatihan:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
Untuk kumpulan data ini, Anda akan memperlakukan semua fitur secara identik. Kemas fitur ke dalam array NumPy tunggal.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Selanjutnya membuat model regresi untuk memprediksi umur. Karena hanya ada satu tensor input, model keras.Sequential sudah cukup di sini.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Untuk melatih model itu, berikan fitur dan label ke Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
Anda baru saja melihat cara paling dasar untuk melatih model menggunakan data CSV. Selanjutnya, Anda akan belajar bagaimana menerapkan preprocessing untuk menormalkan kolom numerik.
Pra-pemrosesan dasar
Ini adalah praktik yang baik untuk menormalkan input ke model Anda. Lapisan prapemrosesan Keras menyediakan cara yang nyaman untuk membangun normalisasi ini ke dalam model Anda.
Lapisan akan menghitung rata-rata dan varians setiap kolom, dan menggunakannya untuk menormalkan data.
Pertama Anda membuat layer:
normalize = layers.Normalization()
Kemudian Anda menggunakan metode Normalization.adapt() untuk mengadaptasi lapisan normalisasi ke data Anda.
normalize.adapt(abalone_features)
Kemudian gunakan lapisan normalisasi dalam model Anda:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Tipe data campuran
Dataset "Titanic" berisi informasi tentang penumpang di Titanic. Tugas nominal pada kumpulan data ini adalah untuk memprediksi siapa yang selamat.

Gambar dari Wikimedia
{kind=link}
Data mentah dapat dengan mudah dimuat sebagai Pandas DataFrame , tetapi tidak langsung dapat digunakan sebagai masukan ke model TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
Karena tipe dan rentang data yang berbeda, Anda tidak bisa begitu saja menumpuk fitur ke dalam array NumPy dan meneruskannya ke model keras.Sequential . Setiap kolom perlu ditangani secara individual.
Sebagai salah satu opsi, Anda dapat melakukan praproses data secara offline (menggunakan alat apa pun yang Anda suka) untuk mengonversi kolom kategorikal menjadi kolom numerik, lalu meneruskan output yang diproses ke model TensorFlow Anda. Kerugian dari pendekatan itu adalah jika Anda menyimpan dan mengekspor model Anda, pra-pemrosesan tidak disimpan dengannya. Lapisan prapemrosesan Keras menghindari masalah ini karena mereka adalah bagian dari model.
Dalam contoh ini, Anda akan membuat model yang mengimplementasikan logika prapemrosesan menggunakan API fungsional Keras . Anda juga bisa melakukannya dengan subclassing .
API fungsional beroperasi pada tensor "simbolis". Tensor "bersemangat" normal memiliki nilai. Sebaliknya, tensor "simbolis" ini tidak. Alih-alih, mereka melacak operasi mana yang dijalankan pada mereka, dan membangun representasi perhitungan, yang bisa Anda jalankan nanti. Berikut ini contoh singkatnya:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Untuk membangun model prapemrosesan, mulailah dengan membangun satu set objek keras.Input simbolis, mencocokkan nama dan tipe data kolom CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
Langkah pertama dalam logika prapemrosesan Anda adalah menggabungkan input numerik bersama-sama, dan menjalankannya melalui lapisan normalisasi:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Kumpulkan semua hasil prapemrosesan simbolis, untuk digabungkan nanti.
preprocessed_inputs = [all_numeric_inputs]
Untuk input string gunakan fungsi tf.keras.layers.StringLookup untuk memetakan dari string ke indeks integer dalam kosakata. Selanjutnya, gunakan tf.keras.layers.CategoryEncoding untuk mengubah indeks menjadi data float32 yang sesuai dengan model.
Pengaturan default untuk lapisan tf.keras.layers.CategoryEncoding membuat vektor one-hot untuk setiap input. Lapisan. layers.Embedding juga akan berfungsi. Lihat panduan dan tutorial lapisan prapemrosesan untuk lebih lanjut tentang topik ini.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
Dengan koleksi inputs dan processing_inputs , Anda dapat menggabungkan semua input yang telah processed_inputs sebelumnya, dan membangun model yang menangani pra-pemrosesan:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
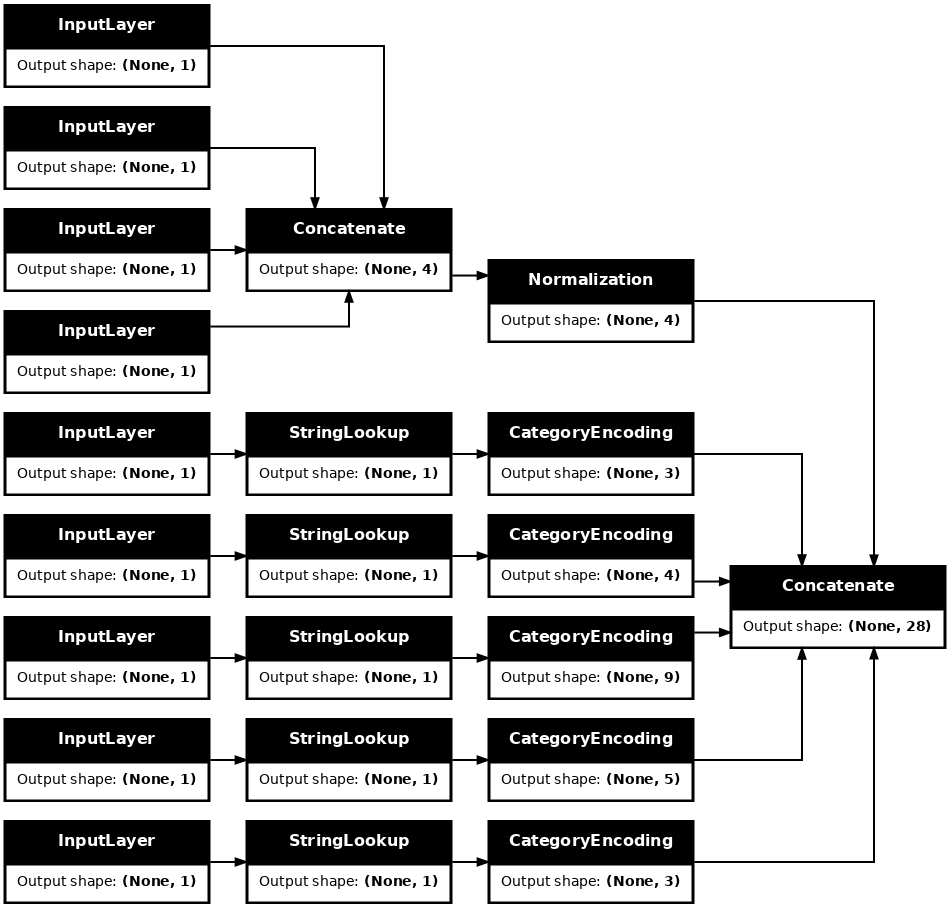
model ini hanya berisi input preprocessing. Anda dapat menjalankannya untuk melihat apa yang dilakukannya pada data Anda. Model Keras tidak secara otomatis mengonversi Pandas DataFrames karena tidak jelas apakah harus dikonversi ke satu tensor atau ke kamus tensor. Jadi konversikan ke kamus tensor:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Potong contoh pelatihan pertama dan berikan ke model pra-pemrosesan ini, Anda melihat fitur numerik dan string one-hots semua digabungkan menjadi satu:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Sekarang buat model di atas ini:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Saat Anda melatih model, berikan kamus fitur sebagai x , dan label sebagai y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Karena prapemrosesan adalah bagian dari model, Anda dapat menyimpan model dan memuatnya kembali di tempat lain dan mendapatkan hasil yang sama:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
Menggunakan tf.data
Di bagian sebelumnya, Anda mengandalkan pengacakan dan pengelompokan data bawaan model saat melatih model.
Jika Anda memerlukan lebih banyak kontrol atas jalur data input atau perlu menggunakan data yang tidak mudah masuk ke memori: gunakan tf.data .
Untuk lebih banyak contoh lihat panduan tf.data .
Di dalam data memori
Sebagai contoh pertama penerapan tf.data ke data CSV, pertimbangkan kode berikut untuk secara manual mengiris kamus fitur dari bagian sebelumnya. Untuk setiap indeks, diperlukan indeks itu untuk setiap fitur:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Jalankan ini dan cetak contoh pertama:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
tf.data.Dataset paling dasar dalam pemuat data memori adalah konstruktor Dataset.from_tensor_slices . Ini mengembalikan tf.data.Dataset yang mengimplementasikan versi umum dari fungsi slices di atas, di TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Anda dapat mengulangi tf.data.Dataset seperti iterable python lainnya:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
Fungsi from_tensor_slices dapat menangani struktur kamus atau tupel bersarang apa pun. Kode berikut membuat kumpulan data dari pasangan (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Untuk melatih model menggunakan Dataset ini, Anda harus setidaknya shuffle dan batch data.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Alih-alih meneruskan features dan labels ke Model.fit , Anda meneruskan kumpulan data:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
Dari satu file
Sejauh ini tutorial ini telah bekerja dengan data dalam memori. tf.data adalah toolkit yang sangat skalabel untuk membangun jalur pipa data, dan menyediakan beberapa fungsi untuk menangani pemuatan file CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Sekarang baca data CSV dari file dan buat tf.data.Dataset .
(Untuk dokumentasi lengkap, lihat tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Fungsi ini mencakup banyak fitur yang mudah digunakan sehingga data mudah digunakan. Ini termasuk:
- Menggunakan header kolom sebagai kunci kamus.
- Secara otomatis menentukan jenis setiap kolom.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
Itu juga dapat mendekompresi data dengan cepat. Berikut adalah file CSV yang di-gzip yang berisi kumpulan data lalu lintas antarnegara bagian metro

Gambar dari Wikimedia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
Setel argumen compression_type untuk membaca langsung dari file terkompresi:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
Cache
Ada beberapa overhead untuk menguraikan data csv. Untuk model kecil ini bisa menjadi hambatan dalam pelatihan.
Tergantung pada kasus penggunaan Anda, mungkin ide yang baik untuk menggunakan Dataset.cache atau data.experimental.snapshot sehingga data csv hanya diuraikan pada zaman pertama.
Perbedaan utama antara metode cache dan snapshot adalah bahwa file cache hanya dapat digunakan oleh proses TensorFlow yang membuatnya, tetapi file snapshot dapat dibaca oleh proses lain.
Misalnya, mengulangi traffic_volume_csv_gz_ds 20 kali, membutuhkan waktu ~15 detik tanpa cache, atau ~2 detik dengan cache.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Jika pemuatan data Anda diperlambat dengan memuat file csv, dan cache serta snapshot tidak mencukupi untuk kasus penggunaan Anda, pertimbangkan untuk mengenkode ulang data Anda ke dalam format yang lebih ramping.
Banyak file
Semua contoh sejauh ini di bagian ini dapat dengan mudah dilakukan tanpa tf.data . Satu tempat di mana tf.data benar-benar dapat menyederhanakan banyak hal adalah ketika berhadapan dengan kumpulan file.
Misalnya, kumpulan data gambar font karakter didistribusikan sebagai kumpulan file csv, satu per font.

Gambar oleh Willi Heidelbach dari Pixabay
Unduh dataset, dan lihat file di dalamnya:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
Saat menangani sekumpulan file, Anda dapat meneruskan file_pattern gaya glob ke fungsi experimental.make_csv_dataset . Urutan file dikocok setiap iterasi.
Gunakan argumen num_parallel_reads untuk mengatur berapa banyak file yang dibaca secara paralel dan disisipkan bersama-sama.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
File csv ini memiliki gambar yang diratakan menjadi satu baris. Nama kolom diformat r{row}c{column} . Ini angkatan pertama:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
Opsional: Bidang pengepakan
Anda mungkin tidak ingin bekerja dengan setiap piksel dalam kolom terpisah seperti ini. Sebelum mencoba menggunakan kumpulan data ini, pastikan untuk mengemas piksel ke dalam tensor gambar.
Berikut adalah kode yang mem-parsing nama kolom untuk membuat gambar untuk setiap contoh:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Terapkan fungsi itu ke setiap batch dalam kumpulan data:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Plot gambar yang dihasilkan:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Fungsi tingkat yang lebih rendah
Sejauh ini tutorial ini berfokus pada utilitas tingkat tertinggi untuk membaca data csv. Ada dua API lain yang mungkin berguna bagi pengguna tingkat lanjut jika kasus penggunaan Anda tidak sesuai dengan pola dasar.
-
tf.io.decode_csv- fungsi untuk mengurai baris teks ke dalam daftar tensor kolom CSV. -
tf.data.experimental.CsvDataset- konstruktor set data csv tingkat yang lebih rendah.
Bagian ini membuat ulang fungsionalitas yang disediakan oleh make_csv_dataset , untuk mendemonstrasikan bagaimana fungsionalitas tingkat yang lebih rendah ini dapat digunakan.
tf.io.decode_csv
Fungsi ini menerjemahkan string, atau daftar string ke dalam daftar kolom.
Tidak seperti make_csv_dataset , fungsi ini tidak mencoba menebak tipe data kolom. Anda menentukan tipe kolom dengan memberikan daftar record_defaults yang berisi nilai tipe yang benar, untuk setiap kolom.
Untuk membaca data Titanic sebagai string menggunakan decode_csv Anda akan mengatakan:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Untuk menguraikannya dengan tipe sebenarnya, buat daftar record_defaults dari tipe yang sesuai:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
Kelas tf.data.experimental.CsvDataset menyediakan antarmuka Dataset CSV minimal tanpa fitur kenyamanan fungsi make_csv_dataset : penguraian header kolom, inferensi tipe kolom, pengacakan otomatis, penyisipan file.
Konstruktor berikut ini menggunakan record_defaults dengan cara yang sama seperti io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Kode di atas pada dasarnya setara dengan:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Banyak file
Untuk mengurai kumpulan data font menggunakan experimental.CsvDataset , Anda harus terlebih dahulu menentukan jenis kolom untuk record_defaults . Mulailah dengan memeriksa baris pertama dari satu file:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Hanya dua bidang pertama yang berupa string, sisanya adalah int atau float, dan Anda bisa mendapatkan jumlah total fitur dengan menghitung koma:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
Konstruktor CsvDatasaet dapat mengambil daftar file input, tetapi membacanya secara berurutan. File pertama dalam daftar CSV adalah AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Jadi ketika Anda meneruskan daftar file ke CsvDataaset , catatan dari AGENCY.csv dibaca terlebih dahulu:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Untuk menyisipkan beberapa file, gunakan Dataset.interleave .
Berikut adalah kumpulan data awal yang berisi nama file csv:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Ini mengacak nama file setiap zaman:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
Metode interleave mengambil map_func yang membuat kumpulan Dataset anak untuk setiap elemen kumpulan data Dataset .
Di sini, Anda ingin membuat CsvDataset dari setiap elemen dataset file:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Dataset yang dikembalikan oleh interleave mengembalikan elemen dengan bersepeda di atas sejumlah child- Dataset s. Perhatikan, di bawah, bagaimana siklus dataset melalui cycle_length=3 tiga file font:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Pertunjukan
Sebelumnya, telah dicatat bahwa io.decode_csv lebih efisien ketika dijalankan pada sekumpulan string.
Hal ini dimungkinkan untuk memanfaatkan fakta ini, saat menggunakan ukuran batch yang besar, untuk meningkatkan kinerja pemuatan CSV (tetapi coba caching terlebih dahulu).
Dengan pemuat bawaan 20, 2048 contoh batch membutuhkan waktu sekitar 17 detik.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
Melewati kumpulan baris teks ke decode_csv berjalan lebih cepat, dalam waktu sekitar 5 detik:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Untuk contoh lain meningkatkan kinerja csv dengan menggunakan batch besar, lihat tutorial overfit dan underfit .
Pendekatan semacam ini mungkin berhasil, tetapi pertimbangkan opsi lain seperti cache dan snapshot , atau enkode ulang data Anda ke dalam format yang lebih ramping.