
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Этот учебник содержит введение в встраивание слов. Вы будете обучать свои собственные вложения слов, используя простую модель Keras для задачи классификации настроений, а затем визуализировать их в проекторе встраивания (показанном на изображении ниже).

Представление текста в виде чисел
Модели машинного обучения принимают векторы (массивы чисел) в качестве входных данных. При работе с текстом первое, что вы должны сделать, — это придумать стратегию преобразования строк в числа (или «векторизации» текста) перед его передачей в модель. В этом разделе вы рассмотрите три стратегии для этого.
Горячие кодировки
В качестве первой идеи вы можете «горячо» закодировать каждое слово в вашем словаре. Рассмотрим предложение «Кошка села на коврик». Словарный запас (или уникальные слова) в этом предложении: (кот, коврик, на, сидел, тот). Для представления каждого слова вы создадите нулевой вектор с длиной, равной словарному запасу, а затем поместите единицу в индекс, соответствующий слову. Этот подход показан на следующей диаграмме.
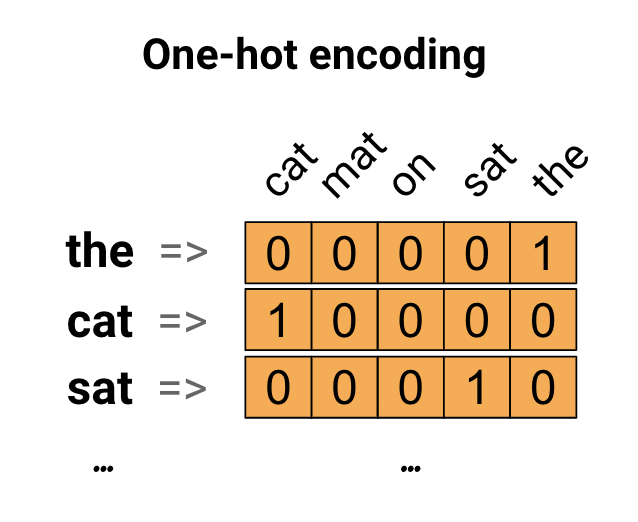
Чтобы создать вектор, содержащий кодировку предложения, вы можете затем соединить горячие векторы для каждого слова.
Кодируйте каждое слово уникальным номером
Второй подход, который вы можете попробовать, состоит в том, чтобы кодировать каждое слово, используя уникальный номер. Продолжая приведенный выше пример, вы можете присвоить 1 «кошке», 2 «коврику» и так далее. Затем вы можете закодировать предложение «Кошка сидела на коврике» как плотный вектор, например [5, 1, 4, 3, 5, 2]. Этот подход эффективен. Вместо разреженного вектора теперь у вас плотный (где все элементы заполнены).
Однако у этого подхода есть два недостатка:
Целочисленное кодирование является произвольным (оно не фиксирует никаких отношений между словами).
Целочисленное кодирование может быть сложным для интерпретации модели. Например, линейный классификатор изучает один вес для каждой функции. Поскольку нет никакой связи между сходством любых двух слов и сходством их кодировок, эта комбинация весовых характеристик не имеет смысла.
Вложения слов
Встраивание слов дает нам способ использовать эффективное, плотное представление, в котором похожие слова имеют аналогичную кодировку. Важно отметить, что вам не нужно указывать эту кодировку вручную. Вложение — это плотный вектор значений с плавающей запятой (длина вектора — это параметр, который вы указываете). Вместо того, чтобы указывать значения для встраивания вручную, они являются обучаемыми параметрами (веса, полученные моделью во время обучения, точно так же, как модель изучает веса для плотного слоя). Обычно можно увидеть вложения слов, которые являются 8-мерными (для небольших наборов данных) и до 1024-мерными при работе с большими наборами данных. Встраивание более высокого размера может фиксировать тонкие отношения между словами, но для изучения требуется больше данных.
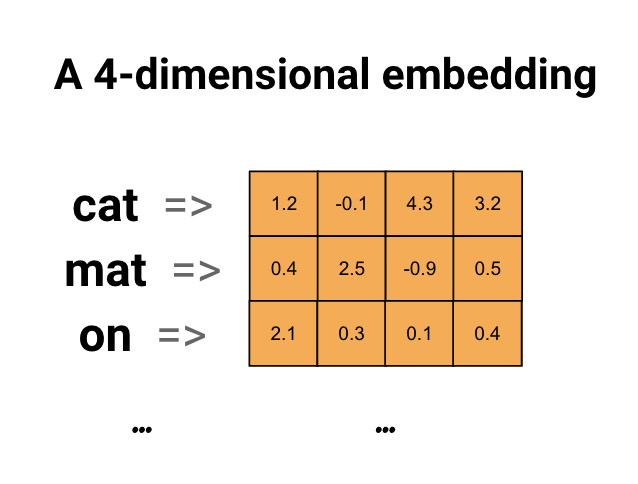
Выше приведена схема встраивания слов. Каждое слово представлено в виде 4-мерного вектора значений с плавающей запятой. Другой способ представить вложение - это "таблица поиска". После того, как эти веса будут изучены, вы можете закодировать каждое слово, найдя плотный вектор, которому оно соответствует в таблице.
Настраивать
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
Загрузите набор данных IMDb
В этом руководстве вы будете использовать большой набор данных обзора фильмов . Вы будете обучать модель классификатора настроений на этом наборе данных и в процессе изучать вложения с нуля. Чтобы узнать больше о загрузке набора данных с нуля, см. учебник по загрузке текста .
Загрузите набор данных с помощью файловой утилиты Keras и просмотрите каталоги.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
Загляните в каталог train/ . В нем есть папки pos и neg с обзорами фильмов, помеченными как положительные и отрицательные соответственно. Вы будете использовать обзоры из папок pos и neg для обучения модели бинарной классификации.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
В каталоге train также есть дополнительные папки, которые следует удалить перед созданием набора данных для обучения.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Затем создайте tf.data.Dataset , используя tf.keras.utils.text_dataset_from_directory . Подробнее об использовании этой утилиты можно прочитать в этом туториале по классификации текста .
Используйте каталог train для создания наборов данных обучения и проверки с разделением 20% для проверки.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Взгляните на несколько обзоров фильмов и их метки (1: positive, 0: negative) из набора данных поезда.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Настройте набор данных для производительности
Это два важных метода, которые вы должны использовать при загрузке данных, чтобы убедиться, что ввод-вывод не блокируется.
.cache() сохраняет данные в памяти после их загрузки с диска. Это гарантирует, что набор данных не станет узким местом при обучении вашей модели. Если ваш набор данных слишком велик, чтобы поместиться в память, вы также можете использовать этот метод для создания производительного кэша на диске, который более эффективен для чтения, чем множество небольших файлов.
.prefetch() перекрывает предварительную обработку данных и выполнение модели во время обучения.
Вы можете узнать больше об обоих методах, а также о том, как кэшировать данные на диск, в руководстве по производительности данных .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Использование слоя внедрения
Keras упрощает использование встраивания слов. Взгляните на слой Embedding .
Слой Embedding можно понимать как таблицу поиска, которая отображает целочисленные индексы (которые обозначают определенные слова) в плотные векторы (их вложения). Размерность (или ширина) встраивания — это параметр, с которым вы можете поэкспериментировать, чтобы увидеть, что хорошо подходит для вашей задачи, почти так же, как вы экспериментировали бы с количеством нейронов в плотном слое.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
Когда вы создаете слой Embedding, веса для внедрения инициализируются случайным образом (как и для любого другого слоя). Во время обучения они постепенно корректируются с помощью обратного распространения ошибки. После обучения изученные вложения слов будут примерно кодировать сходство между словами (так как они были изучены для конкретной проблемы, на которой обучается ваша модель).
Если вы передаете целое число в слой внедрения, результат заменяет каждое целое число вектором из таблицы внедрения:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
Для задач с текстом или последовательностью слой Embedding принимает двумерный тензор целых чисел формы (samples, sequence_length) , где каждая запись представляет собой последовательность целых чисел. Он может встраивать последовательности переменной длины. Вы можете передать в слой встраивания выше пакеты с формами (32, 10) (пакет из 32 последовательностей длиной 10) или (64, 15) (пакет из 64 последовательностей длиной 15).
Возвращенный тензор имеет на одну ось больше, чем входной, векторы встраивания выровнены по новой последней оси. Передайте ему входную партию (2, 3) а выход (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
При получении пакета последовательностей в качестве входных данных слой внедрения возвращает трехмерный тензор с плавающей запятой формы (samples, sequence_length, embedding_dimensionality) . Для преобразования этой последовательности переменной длины в фиксированное представление существует множество стандартных подходов. Вы можете использовать слой RNN, Attention или объединение, прежде чем передавать его на плотный слой. В этом руководстве используется объединение в пул, поскольку оно является самым простым. Классификация текста с учебным пособием по RNN — хороший следующий шаг.
Предварительная обработка текста
Затем определите шаги предварительной обработки набора данных, необходимые для вашей модели классификации настроений. Инициализируйте слой TextVectorization с нужными параметрами для векторизации обзоров фильмов. Вы можете узнать больше об использовании этого слоя в учебнике по классификации текста .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
Создание модели классификации
Используйте Keras Sequential API , чтобы определить модель классификации настроений. В данном случае это модель стиля «Непрерывный мешок слов».
- Слой
TextVectorizationпреобразует строки в словарные индексы. Вы уже инициализировалиvectorize_layerкак слой TextVectorization и построили его словарь, вызвавadaptдляtext_ds. Теперь vectorize_layer можно использовать в качестве первого слоя вашей сквозной модели классификации, передавая преобразованные строки в слой Embedding. Слой
Embeddingберет словарь в целочисленной кодировке и ищет вектор внедрения для каждого индекса слова. Эти векторы изучаются по мере обучения модели. Векторы добавляют измерение к выходному массиву. Результирующие размеры:(batch, sequence, embedding).Слой
GlobalAveragePooling1Dвозвращает выходной вектор фиксированной длины для каждого примера путем усреднения по измерению последовательности. Это позволяет модели обрабатывать ввод переменной длины самым простым способом.Выходной вектор фиксированной длины передается через полносвязный (
Dense) слой с 16 скрытыми единицами.Последний слой плотно связан с одним выходным узлом.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Скомпилируйте и обучите модель
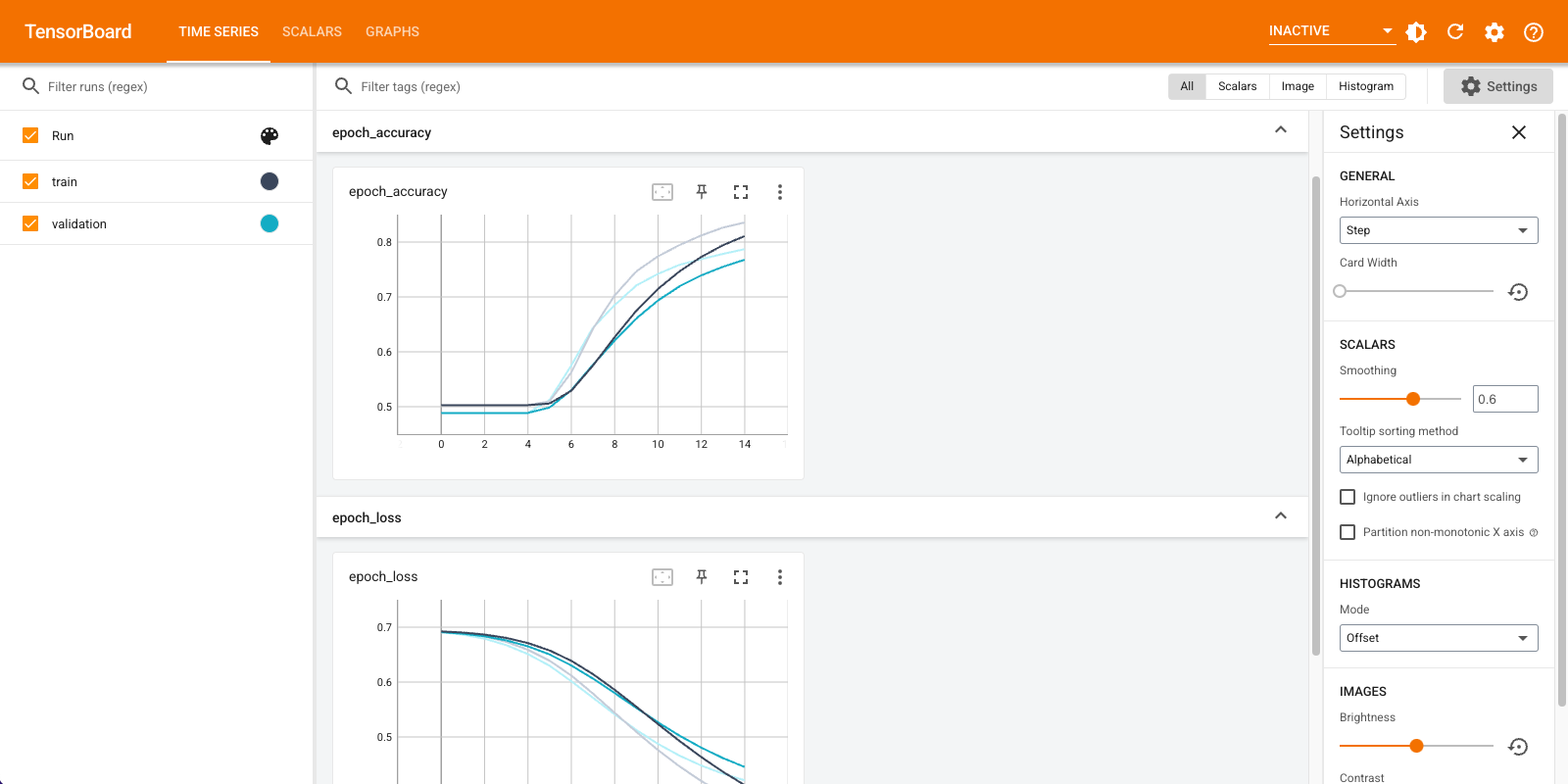
Вы будете использовать TensorBoard для визуализации метрик, включая потери и точность. Создайте tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Скомпилируйте и обучите модель с помощью оптимизатора Adam и потерь BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
При таком подходе модель достигает точности проверки около 78% (обратите внимание, что модель переоснащается, поскольку точность обучения выше).
Вы можете просмотреть сводную информацию о модели, чтобы узнать больше о каждом уровне модели.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Визуализируйте метрики модели в TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
Получить обученные вложения слов и сохранить их на диск
Затем извлеките вложения слов, изученные во время обучения. Вложения — это веса слоя Embedding в модели. Матрица весов имеет форму (vocab_size, embedding_dimension) .
Получите веса из модели, используя get_layer() и get_weights() . Функция get_vocabulary() предоставляет словарь для создания файла метаданных с одним токеном на строку.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Запишите веса на диск. Чтобы использовать Embedding Projector , вы загрузите два файла в формате, разделенном табуляцией: файл векторов (содержащий встраивание) и файл метаданных (содержащий слова).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
Если вы запускаете это руководство в Colaboratory , вы можете использовать следующий фрагмент кода, чтобы загрузить эти файлы на свой локальный компьютер (или использовать браузер файлов, Вид -> Содержание -> Браузер файлов ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Визуализируйте вложения
Чтобы визуализировать встраивания, загрузите их на проектор встраивания.
Откройте встроенный проектор (он также может работать в локальном экземпляре TensorBoard).
Нажмите «Загрузить данные».
Загрузите два файла, которые вы создали выше:
vecs.tsvиmeta.tsv.
Встраивания, которые вы обучили, теперь будут отображаться. Вы можете искать слова, чтобы найти их ближайших соседей. Например, попробуйте выполнить поиск по слову «красивый». Вы можете увидеть соседей, как "замечательные".
Следующие шаги
В этом руководстве показано, как обучать и визуализировать встраивание слов с нуля в небольшом наборе данных.
Чтобы обучить встраивания слов с помощью алгоритма Word2Vec, попробуйте учебник Word2Vec .
Чтобы узнать больше о расширенной обработке текста, прочитайте модель Transformer для понимания языка .