
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве демонстрируется классификация текста, начиная с простых текстовых файлов, хранящихся на диске. Вы обучите двоичный классификатор выполнять анализ настроений в наборе данных IMDB. В конце записной книжки вы можете попробовать выполнить упражнение, в котором вы обучите многоклассовый классификатор предсказывать тег для вопроса о программировании в Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
Анализ настроений
Эта записная книжка обучает модель анализа настроений классифицировать отзывы о фильмах как положительные или отрицательные на основе текста обзора. Это пример бинарной — или двухклассовой — классификации, важной и широко применимой проблемы машинного обучения.
Вы будете использовать большой набор данных обзоров фильмов , который содержит текст 50 000 обзоров фильмов из базы данных фильмов в Интернете . Они разделены на 25 000 отзывов для обучения и 25 000 отзывов для тестирования. Наборы для обучения и тестирования сбалансированы , то есть содержат равное количество положительных и отрицательных отзывов.
Загрузите и изучите набор данных IMDB
Давайте загрузим и извлечем набор данных, а затем изучим структуру каталогов.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
aclImdb/train/pos и aclImdb/train/neg содержат множество текстовых файлов, каждый из которых представляет собой отдельный обзор фильма. Давайте взглянем на один из них.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Загрузите набор данных
Далее вы загрузите данные с диска и подготовите их в формат, подходящий для обучения. Для этого вы будете использовать полезную утилиту text_dataset_from_directory , которая ожидает следующую структуру каталогов.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
Чтобы подготовить набор данных для бинарной классификации, вам понадобятся две папки на диске, соответствующие class_a и class_b . Это будут положительные и отрицательные отзывы о фильмах, которые можно найти в aclImdb/train/pos и aclImdb/train/neg . Поскольку набор данных IMDB содержит дополнительные папки, вы удалите их перед использованием этой утилиты.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Далее вы будете использовать утилиту text_dataset_from_directory для создания помеченного tf.data.Dataset . tf.data — мощный набор инструментов для работы с данными.
При проведении эксперимента по машинному обучению рекомендуется разделить набор данных на три части: обучение , проверка и тестирование .
Набор данных IMDB уже разделен на обучающий и тестовый, но в нем отсутствует проверочный набор. Давайте создадим проверочный набор, используя разделение обучающих данных 80:20, используя приведенный ниже аргумент validation_split .
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Как вы можете видеть выше, в папке для обучения есть 25 000 примеров, из которых вы будете использовать 80% (или 20 000) для обучения. Как вы скоро увидите, вы можете обучить модель, передав набор данных непосредственно в model.fit . Если вы новичок в tf.data , вы также можете перебрать набор данных и распечатать несколько примеров следующим образом.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
Обратите внимание, что обзоры содержат необработанный текст (со знаками препинания и случайными HTML-тегами, такими как <br/> ). Вы покажете, как обращаться с ними в следующем разделе.
Метки — 0 или 1. Чтобы увидеть, какие из них соответствуют положительным и отрицательным отзывам о фильмах, вы можете проверить свойство class_names в наборе данных.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
Далее вы создадите набор данных для проверки и тестирования. Вы будете использовать оставшиеся 5000 отзывов из обучающего набора для проверки.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Подготовьте набор данных для обучения
Далее вы будете стандартизировать, токенизировать и векторизовать данные, используя полезный слой tf.keras.layers.TextVectorization .
Стандартизация относится к предварительной обработке текста, обычно для удаления знаков препинания или элементов HTML для упрощения набора данных. Токенизация относится к разбиению строк на токены (например, разбиение предложения на отдельные слова путем разбиения по пробелам). Векторизация относится к преобразованию токенов в числа, чтобы их можно было передать в нейронную сеть. Все эти задачи могут быть выполнены с помощью этого слоя.
Как вы видели выше, обзоры содержат различные теги HTML, такие как <br /> . Эти теги не будут удалены стандартизатором по умолчанию в слое TextVectorization (который по умолчанию преобразует текст в нижний регистр и удаляет знаки препинания, но не удаляет HTML). Вы напишете пользовательскую функцию стандартизации для удаления HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
Далее вы создадите слой TextVectorization . Вы будете использовать этот слой для стандартизации, токенизации и векторизации наших данных. Вы устанавливаете для параметра output_mode значение int , чтобы создавать уникальные целочисленные индексы для каждого токена.
Обратите внимание, что вы используете функцию разделения по умолчанию и пользовательскую функцию стандартизации, которую вы определили выше. Вы также определите некоторые константы для модели, такие как явная максимальная sequence_length , которая заставит слой дополнять или усекать последовательности точно до значений sequence_length .
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Затем вы вызовете adapt , чтобы подогнать состояние слоя предварительной обработки к набору данных. Это заставит модель построить индекс строк для целых чисел.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Давайте создадим функцию, чтобы увидеть результат использования этого слоя для предварительной обработки некоторых данных.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Как вы можете видеть выше, каждый токен был заменен целым числом. Вы можете найти токен (строку), которому соответствует каждое целое число, вызвав .get_vocabulary() на слое.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Вы почти готовы обучить свою модель. В качестве последнего шага предварительной обработки вы примените созданный ранее слой TextVectorization к набору данных для обучения, проверки и тестирования.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Настройте набор данных для производительности
Это два важных метода, которые вы должны использовать при загрузке данных, чтобы убедиться, что ввод-вывод не блокируется.
.cache() сохраняет данные в памяти после их загрузки с диска. Это гарантирует, что набор данных не станет узким местом при обучении вашей модели. Если ваш набор данных слишком велик, чтобы поместиться в память, вы также можете использовать этот метод для создания производительного кэша на диске, который более эффективен для чтения, чем множество небольших файлов.
.prefetch() перекрывает предварительную обработку данных и выполнение модели во время обучения.
Вы можете узнать больше об обоих методах, а также о том, как кэшировать данные на диск, в руководстве по производительности данных .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Создайте модель
Пришло время создать вашу нейронную сеть:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
Слои укладываются последовательно для построения классификатора:
- Первый слой — это слой
Embedding. Этот слой принимает обзоры в целочисленном кодировании и ищет вектор встраивания для каждого индекса слова. Эти векторы изучаются по мере обучения модели. Векторы добавляют измерение к выходному массиву. Результирующие размеры:(batch, sequence, embedding). Чтобы узнать больше о встраиваниях, см. руководство по встраиванию слов . - Затем слой
GlobalAveragePooling1Dвозвращает выходной вектор фиксированной длины для каждого примера путем усреднения по измерению последовательности. Это позволяет модели обрабатывать ввод переменной длины самым простым способом. - Этот выходной вектор фиксированной длины передается через полносвязный (
Dense) слой с 16 скрытыми единицами. - Последний слой плотно связан с одним выходным узлом.
Функция потерь и оптимизатор
Модель нуждается в функции потерь и оптимизаторе для обучения. Поскольку это проблема бинарной классификации, а модель выводит вероятность (одноэлементный слой с сигмовидной активацией), вы будете использовать функцию потерь losses.BinaryCrossentropy .
Теперь настройте модель для использования оптимизатора и функции потерь:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
Обучите модель
Вы обучите модель, передав объект dataset методу подгонки.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Оценить модель
Посмотрим, как поведет себя модель. Будет возвращено два значения. Потеря (число, которое представляет нашу ошибку, чем меньше значение, тем лучше) и точность.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
Этот довольно наивный подход обеспечивает точность около 86%.
Создайте график точности и потерь с течением времени
model.fit() возвращает объект History , содержащий словарь всего, что произошло во время обучения:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Есть четыре записи: по одной для каждой отслеживаемой метрики во время обучения и проверки. Вы можете использовать их для построения графика потерь при обучении и проверке для сравнения, а также точности обучения и проверки:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
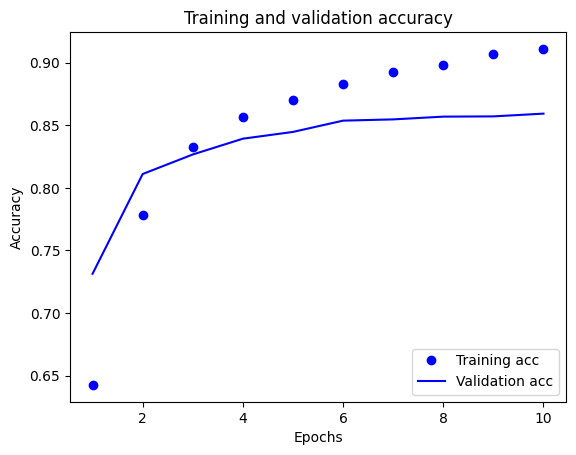
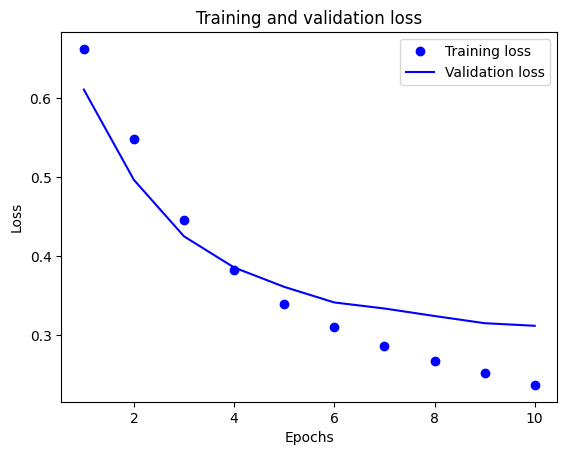
На этом графике точки представляют потери и точность обучения, а сплошные линии — потери и точность проверки.
Обратите внимание, что потери при обучении уменьшаются с каждой эпохой, а точность обучения увеличивается с каждой эпохой. Это ожидается при использовании оптимизации градиентного спуска — она должна минимизировать желаемое количество на каждой итерации.
Это не относится к потерям при проверке и точности — кажется, что они достигают пика перед точностью обучения. Это пример переобучения: модель лучше работает с обучающими данными, чем с данными, которые она никогда раньше не видела. После этого момента модель чрезмерно оптимизируется и изучает представления, характерные для обучающих данных, которые не обобщаются на тестовые данные.
В этом конкретном случае вы можете предотвратить переоснащение, просто остановив обучение, когда точность проверки перестанет увеличиваться. Один из способов сделать это — использовать обратный вызов tf.keras.callbacks.EarlyStopping .
Экспорт модели
В приведенном выше коде вы применили слой TextVectorization к набору данных перед передачей текста в модель. Если вы хотите, чтобы ваша модель могла обрабатывать необработанные строки (например, чтобы упростить ее развертывание), вы можете включить в модель слой TextVectorization . Для этого вы можете создать новую модель, используя веса, которые вы только что обучили.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Вывод по новым данным
Чтобы получить прогнозы для новых примеров, вы можете просто вызвать model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
Включение логики предварительной обработки текста в вашу модель позволяет вам экспортировать модель для производства, что упрощает развертывание и снижает вероятность перекоса обучения/тестирования .
Существует разница в производительности, которую следует учитывать при выборе места применения слоя TextVectorization. Использование его вне вашей модели позволяет вам выполнять асинхронную обработку ЦП и буферизацию ваших данных при обучении на графическом процессоре. Итак, если вы обучаете свою модель на графическом процессоре, вы, вероятно, захотите использовать этот вариант, чтобы получить максимальную производительность при разработке модели, а затем переключиться на включение слоя TextVectorization внутри вашей модели, когда вы будете готовы к развертыванию. .
Посетите этот учебник , чтобы узнать больше о сохранении моделей.
Упражнение: многоклассовая классификация по вопросам Stack Overflow
В этом руководстве показано, как с нуля обучить двоичный классификатор на наборе данных IMDB. В качестве упражнения вы можете изменить эту записную книжку, чтобы обучить многоклассовый классификатор прогнозировать тег вопроса по программированию в Stack Overflow .
Для вас подготовлен набор данных , содержащий несколько тысяч вопросов по программированию (например, «Как мне отсортировать словарь по значению в Python?»), размещенных в Stack Overflow. Каждый из них помечен ровно одним тегом (Python, CSharp, JavaScript или Java). Ваша задача — принять вопрос в качестве входных данных и предсказать соответствующий тег, в данном случае Python.
Набор данных, с которым вы будете работать, содержит несколько тысяч вопросов, извлеченных из гораздо более крупного общедоступного набора данных Stack Overflow в BigQuery , который содержит более 17 миллионов сообщений.
После загрузки набора данных вы обнаружите, что структура каталогов аналогична набору данных IMDB, с которым вы работали ранее:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Чтобы выполнить это упражнение, вы должны изменить эту записную книжку для работы с набором данных Stack Overflow, внеся следующие изменения:
В верхней части записной книжки обновите код, который загружает набор данных IMDB, на код для загрузки уже подготовленного набора данных Stack Overflow . Поскольку набор данных Stack Overflow имеет аналогичную структуру каталогов, вам не потребуется вносить много изменений.
Измените последний слой вашей модели на
Dense(4), так как теперь есть четыре выходных класса.При компиляции модели измените потери на
tf.keras.losses.SparseCategoricalCrossentropy. Это правильная функция потерь для использования в задаче классификации нескольких классов, когда метки для каждого класса являются целыми числами (в данном случае они могут быть 0, 1 , 2 или 3 ). Кроме того, измените метрику наmetrics=['accuracy'], так как это проблема классификации нескольких классов (tf.metrics.BinaryAccuracyиспользуется только для бинарных классификаторов).При отображении точности во времени измените
binary_accuracyиval_binary_accuracyнаaccuracyиval_accuracyсоответственно.Как только эти изменения будут завершены, вы сможете обучить мультиклассовый классификатор.
Узнать больше
В этом учебном пособии классификация текста представлена с нуля. Чтобы узнать больше о рабочем процессе классификации текста в целом, ознакомьтесь с руководством по классификации текста от Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.