
TensorFlow Data Validation (TFDV) は、トレーニング データとサービング データを分析して以下を行うことができます。
コア API は、その上に構築され、ノートブックのコンテキストで呼び出すことができる便利なメソッドを使用して、各機能をサポートします。
記述的なデータ統計の計算
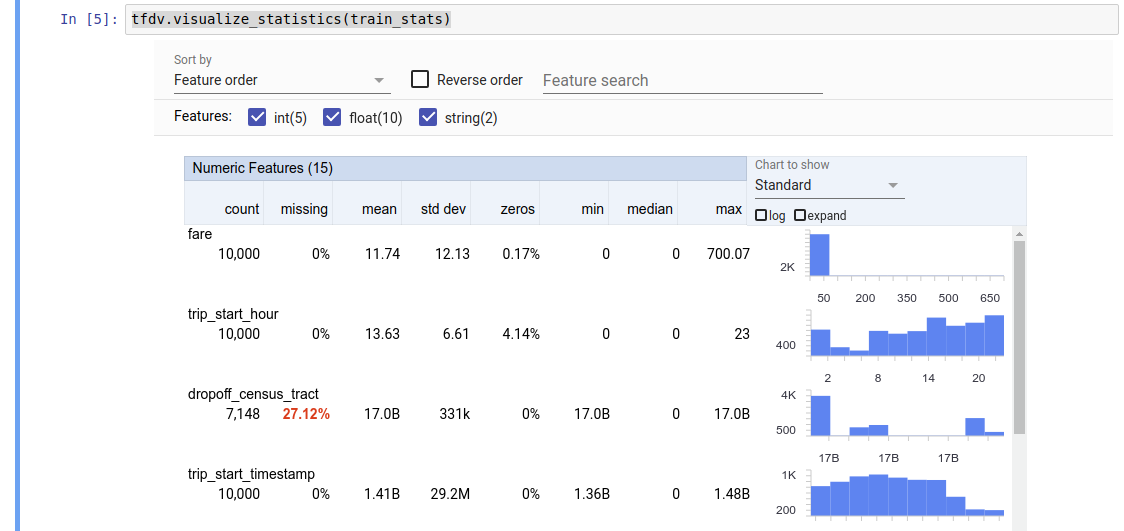
TFDV は、存在する特徴とその値の分布の形状に関してデータの概要を迅速に提供する記述統計を計算できます。ファセット概要などのツールを使用すると、これらの統計を簡潔に視覚化して簡単に閲覧できます。
たとえば、 pathがTFRecord形式のファイル ( tensorflow.Example型のレコードを保持する) を指しているとします。次のスニペットは、TFDV を使用した統計の計算を示しています。
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
戻り値はDatasetFeatureStatisticsListプロトコル バッファーです。サンプル ノートブックには、ファセット概要を使用した統計の視覚化が含まれています。
tfdv.visualize_statistics(stats)
前の例では、データがTFRecordファイルに保存されていることを前提としています。 TFDV は CSV 入力形式もサポートしており、他の一般的な形式に対する拡張性もあります。利用可能なデータ デコーダはここで見つけることができます。さらに、TFDV は、pandas DataFrame として表されるメモリ内データを持つユーザーにtfdv.generate_statistics_from_dataframeユーティリティ関数を提供します。
データ統計のデフォルトセットを計算することに加えて、TFDV はセマンティックドメイン (画像、テキストなど) の統計も計算できます。セマンティック ドメイン統計の計算を有効にするには、 enable_semantic_domain_statsを True に設定したtfdv.StatsOptionsオブジェクトをtfdv.generate_statistics_from_tfrecordに渡します。
Google Cloud 上で実行
内部的には、TFDV はApache Beamのデータ並列処理フレームワークを使用して、大規模なデータセットにわたる統計の計算を拡張します。 TFDV とより深く統合したいアプリケーション (データ生成パイプラインの最後に統計生成を付加する、カスタム形式でデータの統計を生成するなど) の場合、API は統計生成用の Beam PTransform も公開します。
Google Cloud で TFDV を実行するには、TFDV ホイール ファイルをダウンロードして Dataflow ワーカーに提供する必要があります。次のように、wheel ファイルを現在のディレクトリにダウンロードします。
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
次のスニペットは、Google Cloud での TFDV の使用例を示しています。
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
この場合、生成された統計プロトコルは、 GCS_STATS_OUTPUT_PATHに書き込まれる TFRecord ファイルに保存されます。
注 Google Cloud でtfdv.generate_statistics_...関数(例: tfdv.generate_statistics_from_tfrecord )を呼び出す場合は、 output_pathを指定する必要があります。 None を指定するとエラーになる場合があります。
データに対するスキーマの推論
スキーマは、データの予期されるプロパティを記述します。これらのプロパティの一部は次のとおりです。
- どの機能が存在すると予想されるか
- 彼らのタイプ
- 各例の特徴の値の数
- すべての例にわたる各特徴の存在
- 期待される機能のドメイン。
つまり、スキーマは「正しい」データに対する期待を記述しているため、データ内のエラーを検出するために使用できます (後述)。さらに、同じスキーマを使用して、データ変換用のTensorFlow Transformをセットアップすることができます。スキーマはかなり静的であることが期待されることに注意してください。たとえば、いくつかのデータセットは同じスキーマに準拠できますが、統計 (前述) はデータセットごとに異なる可能性があります。
スキーマの作成は、特に多くの特徴を持つデータセットの場合、面倒な作業になる可能性があるため、TFDV は、記述統計に基づいてスキーマの初期バージョンを生成する方法を提供します。
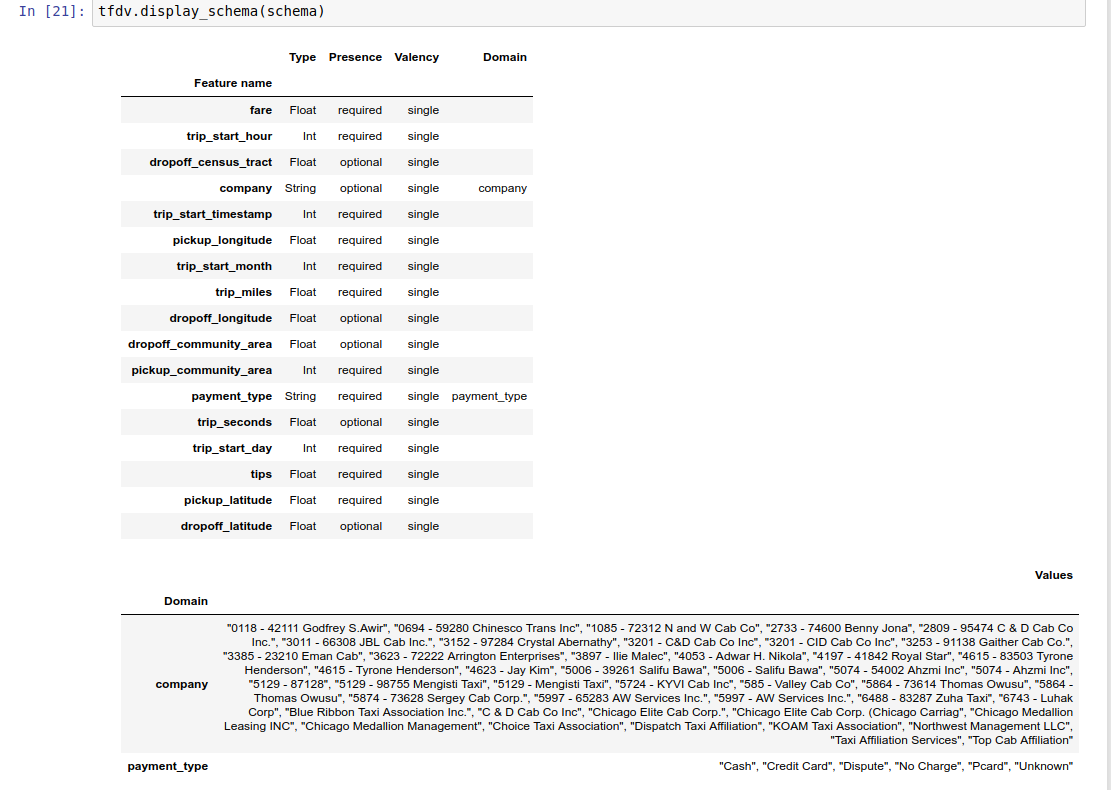
schema = tfdv.infer_schema(stats)
一般に、TFDV は、スキーマが特定のデータセットに過剰適合することを避けるために、保守的なヒューリスティックを使用して統計から安定したデータ プロパティを推測します。 TFDV のヒューリスティックでは見逃した可能性のあるデータに関するドメイン知識を取得するために、推論されたスキーマを確認し、必要に応じて調整することを強くお勧めします。
デフォルトでは、機能のvalue_count.minがvalue_count.maxと等しい場合、 tfdv.infer_schema必要な各機能の形状を推測します。形状推論を無効にするには、 infer_feature_shape引数を False に設定します。
スキーマ自体はスキーマ プロトコル バッファとして保存されるため、標準のプロトコル バッファ API を使用して更新/編集できます。 TFDV は、これらの更新を簡単にするためのいくつかのユーティリティ メソッドも提供します。たとえば、単一の値を取る必須の文字列機能payment_typeを記述する次のスタンザがスキーマに含まれているとします。
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
例の少なくとも 50% に機能を追加する必要があることをマークするには、次のようにします。
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
サンプル ノートブックには、スキーマを簡単に視覚化した表が含まれており、スキーマにエンコードされた各機能とその主な特性がリストされています。
データにエラーがないかチェックする
スキーマが与えられると、データセットがスキーマに設定された期待に準拠しているかどうか、またはデータに異常が存在するかどうかをチェックできます。データのエラーをチェックするには、(a) データセットの統計をスキーマと照合することで、データセット全体の集計で、または (b) サンプルごとにエラーをチェックします。
データセットの統計をスキーマと照合する
集計内のエラーをチェックするために、TFDV はデータセットの統計をスキーマと照合し、不一致をマークします。例えば:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
結果は異常プロトコル バッファのインスタンスであり、統計がスキーマと一致しないエラーが記述されます。たとえば、 other_pathのデータに、スキーマで指定されたドメインの外にある機能payment_typeの値を含む例が含まれているとします。
これにより異常が発生します
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
これは、特徴値の 1% 未満の統計でドメイン外の値が見つかったことを示します。
これが予期されていた場合は、次のようにスキーマを更新できます。
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
異常が本当にデータエラーを示している場合は、基礎となるデータをトレーニングに使用する前に修正する必要があります。
このモジュールで検出できるさまざまな異常タイプをここにリストします。
サンプル ノートブックには、異常が表として簡単に視覚化され、エラーが検出された機能と各エラーの簡単な説明がリストされています。

例ごとにエラーをチェックする
TFDV は、データセット全体の統計をスキーマと比較するのではなく、サンプルごとにデータを検証するオプションも提供します。 TFDV は、例ごとにデータを検証し、見つかった異常な例の要約統計を生成する機能を提供します。例えば:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
validate_examples_in_tfrecordが返すanomalous_example_statsは、各データセットが特定の異常を示すサンプルのセットで構成されるDatasetFeatureStatisticsListプロトコル バッファーです。これを使用して、特定の異常を示すデータセット内の例の数とそれらの例の特徴を判断できます。
スキーマ環境
デフォルトでは、検証ではパイプライン内のすべてのデータセットが単一のスキーマに準拠していると想定されます。場合によっては、わずかなスキーマの変更を導入する必要があります。たとえば、ラベルとして使用される特徴はトレーニング中に必要ですが (検証する必要があります)、提供中には欠落します。
環境を使用して、そのような要件を表現できます。特に、スキーマ内の機能は、default_environment、in_environment、not_in_environment を使用して一連の環境に関連付けることができます。
たとえば、ヒント機能がトレーニングでラベルとして使用されているが、提供データには存在しない場合です。環境が指定されていない場合、異常として表示されます。
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

これを修正するには、すべての機能のデフォルト環境を「トレーニング」と「サービス」の両方に設定し、「ヒント」機能をサービス環境から除外する必要があります。
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
データのスキューとドリフトのチェック
TFDV は、データセットがスキーマに設定された期待値に準拠しているかどうかをチェックするだけでなく、以下を検出する機能も提供します。
- トレーニング データと提供データの間のスキュー
- 異なる日のトレーニング データ間のずれ
TFDV は、スキーマで指定されたドリフト/スキュー コンパレータに基づいて、さまざまなデータセットの統計を比較することによってこのチェックを実行します。たとえば、トレーニング データセットとサービス データセット内の「payment_type」特徴の間に歪みがあるかどうかを確認するには、次のようにします。
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
注 L-無限大ノルムはカテゴリ特徴量の歪みのみを検出します。 infinity_normしきい値を指定する代わりに、 skew_comparatorでjensen_shannon_divergenceしきい値を指定すると、数値特徴とカテゴリ特徴の両方のスキューが検出されます。
データセットがスキーマに設定された期待に準拠しているかどうかを確認する場合と同様に、結果もAnomaliesプロトコル バッファーのインスタンスであり、トレーニング データセットとサービス データセットの間のスキューを示します。たとえば、提供データに、値Cashを持つ特徴payement_typeを持つサンプルが大幅に多く含まれているとします。これにより、スキュー異常が発生します。
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
異常が本当にトレーニング データと提供データの間の歪みを示している場合は、モデルのパフォーマンスに直接影響を与える可能性があるため、さらなる調査が必要です。
サンプル ノートブックには、スキュー ベースの異常をチェックする簡単な例が含まれています。
異なる日のトレーニング データ間のドリフトの検出も同様の方法で実行できます。
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
注 L-無限大ノルムはカテゴリ特徴量の歪みのみを検出します。 infinity_normしきい値を指定する代わりに、 skew_comparatorでjensen_shannon_divergenceしきい値を指定すると、数値特徴とカテゴリ特徴の両方のスキューが検出されます。
カスタム データ コネクタの作成
データ統計を計算するために、TFDV はさまざまな形式の入力データを処理するための便利なメソッドをいくつか提供します (例: tf.train.ExampleのTFRecord 、CSV など)。使用するデータ形式がこのリストにない場合は、入力データを読み取るためのカスタム データ コネクタを作成し、それを TFDV コア API に接続してデータ統計を計算する必要があります。
データ統計を計算するための TFDV コア API は、入力例のバッチの PCollection (入力例のバッチはArrow RecordBatch として表されます) を取得し、単一のDatasetFeatureStatisticsListプロトコル バッファーを含む PCollection を出力するBeam PTransformです。
Arrow RecordBatch で入力例をバッチ処理するカスタム データ コネクタを実装したら、データ統計を計算するためにtfdv.GenerateStatistics API に接続する必要があります。 tf.train.ExampleのTFRecord例に挙げます。 tfx_bsl TFExampleRecordデータ コネクタを提供します。以下は、これをtfdv.GenerateStatistics API に接続する方法の例です。
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
データのスライスに対する統計の計算
TFDV は、データのスライスにわたる統計を計算するように構成できます。スライスは、Arrow RecordBatchを受け取り、形式(slice key, record batch)のタプルのシーケンスを出力するスライス関数を提供することで有効にできます。 TFDV は、統計を計算するときにtfdv.StatsOptionsの一部として提供できる特徴量ベースのスライス関数を生成する簡単な方法を提供します。
スライスが有効な場合、出力DatasetFeatureStatisticsListプロトには、スライスごとに 1 つずつ、複数のDatasetFeatureStatisticsプロトが含まれます。各スライスは、 DatasetFeatureStatistics プロトでデータセット名として設定される一意の名前によって識別されます。デフォルトでは、TFDV は構成されたスライスに加えてデータセット全体の統計を計算します。
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])