
Komponent SampleGen TFX Pipeline pobiera dane do potoków TFX. Zużywa zewnętrzne pliki/usługi do generowania przykładów, które będą czytane przez inne komponenty TFX. Zapewnia również spójną i konfigurowalną partycję oraz tasuje zestaw danych na potrzeby najlepszych praktyk ML.
- Zużywa: Dane z zewnętrznych źródeł danych, takich jak CSV,
TFRecord, Avro, Parquet i BigQuery. - Emituje: rekordy
tf.Example, rekordytf.SequenceExamplelub format proto, w zależności od formatu ładunku.
PrzykładGen i inne komponenty
PrzykładGen dostarcza dane do komponentów, które korzystają z biblioteki TensorFlow Data Validation , takiej jak SchemaGen , StatisticsGen i Przykład Validator . Dostarcza również dane do Transform , która korzysta z biblioteki TensorFlow Transform i ostatecznie do celów wdrożenia podczas wnioskowania.
Źródła i formaty danych
Obecnie standardowa instalacja TFX zawiera pełne komponenty PrzykładGen dla tych źródeł danych i formatów:
Dostępne są również niestandardowe moduły executorów, które umożliwiają tworzenie komponentów PrzykładGen dla następujących źródeł danych i formatów:
Zobacz przykłady użycia w kodzie źródłowym i tę dyskusję , aby uzyskać więcej informacji na temat używania i opracowywania niestandardowych modułów wykonawczych.
Ponadto te źródła danych i formaty są dostępne jako przykłady komponentów niestandardowych :
Pozyskiwanie formatów danych obsługiwanych przez Apache Beam
Apache Beam obsługuje pozyskiwanie danych z szerokiego zakresu źródeł danych i formatów ( patrz poniżej ). Te możliwości można wykorzystać do tworzenia niestandardowych komponentów PrzykładGen dla TFX, co demonstrują niektóre istniejące komponenty PrzykładGen ( patrz poniżej ).
Jak korzystać ze składnika PrzykładGen
W przypadku obsługiwanych źródeł danych (obecnie plików CSV, plików TFRecord w formacie tf.Example , tf.SequenceExample i proto oraz wyników zapytań BigQuery) komponentu potoku PrzykładGen można używać bezpośrednio podczas wdrażania i wymaga on niewielkich dostosowań. Na przykład:
example_gen = CsvExampleGen(input_base='data_root')
lub jak poniżej, aby zaimportować zewnętrzny TFRecord bezpośrednio za pomocą tf.Example :
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Rozpiętość, wersja i podział
Rozpiętość to grupa przykładów szkoleniowych. Jeśli Twoje dane są utrwalone w systemie plików, każdy Span może być przechowywany w oddzielnym katalogu. Semantyka zakresu nie jest zakodowana na stałe w TFX; Rozpiętość może odpowiadać dniu danych, godzinie danych lub dowolnej innej grupie mającej znaczenie dla Twojego zadania.
Każdy zakres może przechowywać wiele wersji danych. Aby dać przykład, jeśli usuniesz kilka przykładów z zakresu, aby oczyścić dane o niskiej jakości, może to skutkować nową wersją tego zakresu. Domyślnie komponenty TFX działają w najnowszej wersji w ramach zakresu.
Każdą wersję w ramach zakresu można dalej podzielić na wiele podziałów. Najczęstszym przypadkiem użycia podziału zakresu jest podzielenie go na dane szkoleniowe i ewaluacyjne.
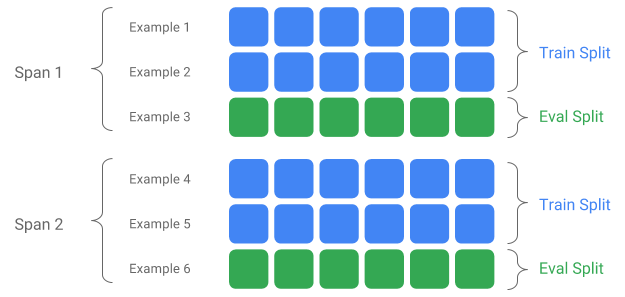
Niestandardowy podział wejścia/wyjścia
Aby dostosować współczynnik podziału pociągu/eval, który będzie wysyłany przez PrzykładGen, ustaw output_config dla komponentu PrzykładGen. Na przykład:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Zwróć uwagę, jak w tym przykładzie ustawiono hash_buckets .
W przypadku źródła wejściowego, które zostało już podzielone, ustaw input_config dla komponentu PrzykładGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
W przypadku przykładowego genu opartego na plikach (np. CsvExampleGen i ImportExampleGen) pattern jest globalnym względnym wzorcem pliku, który odwzorowuje pliki wejściowe z katalogiem głównym określonym przez wejściową ścieżkę bazową. W przypadku przykładowego genu opartego na zapytaniach (np. BigQueryExampleGen, PrestoExampleGen) pattern jest zapytanie SQL.
Domyślnie cały podstawowy katalog wejściowy jest traktowany jako pojedynczy podział wejściowy, a podział wyjściowy pociągu i ewaluacji jest generowany w stosunku 2:1.
Proszę zapoznać się z proto/example_gen.proto , aby zapoznać się z konfiguracją podziału wejścia i wyjścia PrzykładGen. Informacje na temat wykorzystania niestandardowych podziałów na dalszym etapie można znaleźć w przewodniku po komponentach dalszych .
Metoda podziału
Stosując metodę podziału hash_buckets zamiast całego rekordu można zastosować funkcję partycjonowania przykładów. Jeśli funkcja jest obecna, SampleGen użyje odcisku palca tej funkcji jako klucza partycji.
Tej funkcji można użyć do utrzymania stabilnego podziału zgodnie z pewnymi właściwościami przykładów: na przykład użytkownik zawsze zostanie umieszczony w tym samym podziale, jeśli jako nazwę funkcji partycji wybrano „user_id”.
Interpretacja znaczenia „funkcji” i sposobu dopasowania „funkcji” do określonej nazwy zależy od implementacji PrzykładGen i rodzaju przykładów.
W przypadku gotowych implementacji PrzykładGen:
- Jeśli generuje tf.Example, wówczas „funkcja” oznacza wpis w tf.Example.features.feature.
- Jeśli generuje tf.SequenceExample, wówczas „funkcja” oznacza wpis w tf.SequenceExample.context.feature.
- Obsługiwane są tylko funkcje int64 i bytes.
W następujących przypadkach PrzykładGen zgłasza błędy wykonania:
- Określona nazwa funkcji nie istnieje w przykładzie.
- Pusta funkcja:
tf.train.Feature(). - Nieobsługiwane typy funkcji, np. funkcje pływające.
Aby wyprowadzić podział pociągu/eval w oparciu o funkcję z przykładów, ustaw output_config dla komponentu PrzykładGen. Na przykład:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Zwróć uwagę, jak w tym przykładzie ustawiono partition_feature_name .
Przęsło
Rozpiętość można pobrać za pomocą specyfikacji „{SPAN}” we wzorcu wejściowym :
- Ta specyfikacja dopasowuje cyfry i mapuje dane na odpowiednie numery SPAN. Na przykład „data_{SPAN}-*.tfrecord” zbierze pliki takie jak „data_12-a.tfrecord”, „data_12-b.tfrecord”.
- Opcjonalnie tę specyfikację można określić za pomocą szerokości liczb całkowitych podczas mapowania. Na przykład „data_{SPAN:2}.file” jest mapowany na pliki takie jak „data_02.file” i „data_27.file” (jako dane wejściowe odpowiednio dla Span-2 i Span-27), ale nie jest mapowany na „data_1. plik” ani „data_123.file”.
- Jeśli brakuje specyfikacji SPAN, przyjmuje się, że jest to zawsze Span '0'.
- Jeśli określono SPAN, potok przetworzy najnowszy zakres i zapisze numer zakresu w metadanych.
Załóżmy na przykład, że istnieją dane wejściowe:
- „/tmp/span-1/pociąg/dane”
- „/tmp/span-1/eval/data”
- „/tmp/span-2/pociąg/dane”
- „/tmp/span-2/eval/data”
a konfiguracja wejściowa jest pokazana poniżej:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
po uruchomieniu potoku przetworzy on:
- „/tmp/span-2/train/data” jako podział pociągu
- „/tmp/span-2/eval/data” jako podział eval
z numerem zakresu jako „2”. Jeśli później „/tmp/span-3/...” będzie gotowy, po prostu ponownie uruchom potok, a potok pobierze zakres „3” do przetworzenia. Poniżej przedstawiono przykładowy kod wykorzystania specyfikacji zakresu:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Pobranie określonego zakresu można wykonać za pomocą RangeConfig, co opisano szczegółowo poniżej.
Data
Jeśli Twoje źródło danych jest zorganizowane w systemie plików według daty, TFX obsługuje mapowanie dat bezpośrednio na liczby zakresu. Istnieją trzy specyfikacje reprezentujące mapowanie dat na zakresy: {RRRR}, {MM} i {DD}:
- Te trzy specyfikacje powinny być łącznie obecne we wzorcu globu wejściowego, jeśli którykolwiek został określony:
- Można określić wyłącznie specyfikację {SPAN} lub ten zestaw specyfikacji dat.
- Obliczana jest data kalendarzowa z rokiem z RRRR, miesiącem z MM i dniem miesiąca z DD, następnie liczba rozpiętości jest obliczana jako liczba dni od epoki uniksa (tj. 1970-01-01). Na przykład „log-{YYYY}{MM}{DD}.data” dopasowuje plik „log-19700101.data” i wykorzystuje go jako dane wejściowe dla Span-0, a „log-20170101.data” jako dane wejściowe dla Rozpiętość-17167.
- Jeśli określono ten zestaw specyfikacji dat, potok przetworzy najnowszą datę i zapisze odpowiedni numer zakresu w metadanych.
Załóżmy na przykład, że dane wejściowe są uporządkowane według dat kalendarzowych:
- „/tmp/1970-01-02/pociąg/dane”
- „/tmp/1970-01-02/eval/dane”
- „/tmp/1970-01-03/pociąg/dane”
- „/tmp/1970-01-03/eval/dane”
a konfiguracja wejściowa jest pokazana poniżej:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
po uruchomieniu potoku przetworzy on:
- „/tmp/1970-01-03/train/data” jako podział pociągu
- „/tmp/1970-01-03/eval/data” jako podział eval
z numerem zakresu jako „2”. Jeśli później „/tmp/1970-01-04/...” będzie gotowy, po prostu ponownie uruchom potok, a do przetworzenia pobierze on zakres „3”. Poniżej przedstawiono przykładowy kod wykorzystania specyfikacji daty:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Wersja
Wersję można pobrać, używając specyfikacji „{VERSION}” we wzorcu globu wejściowego :
- Ta specyfikacja dopasowuje cyfry i odwzorowuje dane na odpowiednie numery WERSJI w obszarze SPAN. Należy pamiętać, że specyfikacji wersji można używać w połączeniu ze specyfikacją zakresu lub daty.
- Ta specyfikacja może być również opcjonalnie określona za pomocą szerokości w taki sam sposób, jak specyfikacja SPAN. np. „span-{SPAN}/version-{VERSION:4}/data-*”.
- Jeśli brakuje specyfikacji WERSJA, wersja jest ustawiana na Brak.
- Jeśli określono zarówno SPAN, jak i VERSION, potok przetworzy najnowszą wersję dla najnowszego zakresu i zapisze numer wersji w metadanych.
- Jeśli określono WERSJĘ, ale nie SPAN (lub datę), zostanie zgłoszony błąd.
Załóżmy na przykład, że istnieją dane wejściowe:
- „/tmp/span-1/ver-1/train/data”
- „/tmp/span-1/ver-1/eval/data”
- „/tmp/span-2/ver-1/train/data”
- „/tmp/span-2/ver-1/eval/data”
- „/tmp/span-2/ver-2/train/data”
- „/tmp/span-2/ver-2/eval/data”
a konfiguracja wejściowa jest pokazana poniżej:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
po uruchomieniu potoku przetworzy on:
- „/tmp/span-2/ver-2/train/data” jako podział pociągu
- „/tmp/span-2/ver-2/eval/data” jako podział eval
z numerem zakresu jako „2” i numerem wersji jako „2”. Jeśli później „/tmp/span-2/ver-3/…” będzie gotowy, po prostu ponownie uruchom potok, a do przetworzenia pobierze on zakres „2” i wersję „3”. Poniżej przedstawiono przykładowy kod wykorzystania specyfikacji wersji:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Konfiguracja zasięgu
TFX obsługuje pobieranie i przetwarzanie określonego zakresu w opartym na plikach programie PrzykładGen przy użyciu konfiguracji zakresu, abstrakcyjnej konfiguracji używanej do opisywania zakresów dla różnych jednostek TFX. Aby pobrać określony zakres, ustaw range_config dla opartego na pliku komponentu PrzykładGen. Załóżmy na przykład, że istnieją dane wejściowe:
- „/tmp/span-01/pociąg/dane”
- „/tmp/span-01/eval/data”
- „/tmp/span-02/pociąg/dane”
- „/tmp/span-02/eval/data”
Aby konkretnie pobierać i przetwarzać dane z zakresem „1”, oprócz konfiguracji wejściowej określamy konfigurację zakresu. Należy zauważyć, że PrzykładGen obsługuje tylko zakresy statyczne o jednym zakresie (aby określić przetwarzanie określonych pojedynczych zakresów). Dlatego w przypadku StaticRange liczba_rozpiętości_początkowej musi być równa liczbie_rozpiętości_końcowej. Korzystając z podanego zakresu i informacji o szerokości zakresu (jeśli zostały podane) do dopełniania zerami, PrzykładGen zastąpi specyfikację SPAN w dostarczonych wzorach podziału żądanym numerem zakresu. Przykład użycia pokazano poniżej:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Konfiguracji zakresu można również użyć do przetwarzania określonych dat, jeśli zamiast specyfikacji SPAN zostanie użyta specyfikacja daty. Załóżmy na przykład, że dane wejściowe są uporządkowane według dat kalendarzowych:
- „/tmp/1970-01-02/pociąg/dane”
- „/tmp/1970-01-02/eval/dane”
- „/tmp/1970-01-03/pociąg/dane”
- „/tmp/1970-01-03/eval/dane”
Aby konkretnie pobrać i przetworzyć dane z dnia 2 stycznia 1970 r., wykonujemy następujące czynności:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Przykład niestandardowyGen
Jeśli obecnie dostępne komponenty SampleGen nie odpowiadają Twoim potrzebom, możesz stworzyć własny moduł PrzykładGen, który umożliwi Ci odczyt z różnych źródeł danych lub w różnych formatach danych.
Przykładowe dostosowywanie genu w oparciu o pliki (eksperymentalne)
Najpierw rozszerz BaseExampleGenExecutor o niestandardową Beam PTransform, która zapewnia konwersję z podziału danych wejściowych pociągu/eval na przykłady TF. Na przykład executor CsvExampleGen zapewnia konwersję z wejściowego podziału pliku CSV na przykłady TF.
Następnie utwórz komponent z powyższym executorem, tak jak zrobiono to w komponencie CsvExampleGen . Alternatywnie możesz przekazać niestandardowego executora do standardowego komponentu PrzykładGen, jak pokazano poniżej.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Teraz obsługujemy także odczytywanie plików Avro i Parquet przy użyciu tej metody .
Dodatkowe formaty danych
Apache Beam obsługuje odczyt wielu dodatkowych formatów danych . poprzez transformacje we/wy wiązki. Możesz tworzyć niestandardowe komponenty PrzykładGen, wykorzystując transformacje we/wy wiązki, używając wzorca podobnego do przykładu Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
W chwili pisania tego tekstu aktualnie obsługiwane formaty i źródła danych dla zestawu SDK Beam Python obejmują:
- Amazona S3
- Apache Avro
- Apache Hadoopa
- Apacz Kafka
- Parkiet Apacz
- BigQuery w chmurze Google
- BigTable w chmurze Google
- Magazyn danych w chmurze Google
- Google Cloud Pub/Sub
- Magazyn w chmurze Google (GCS)
- MongoDB
Najnowszą listę znajdziesz w dokumentacji Beam .
Przykładowe dostosowywanie genu na podstawie zapytań (eksperymentalne)
Najpierw rozszerz BaseExampleGenExecutor o niestandardową transformację Beam PTransform, która odczytuje z zewnętrznego źródła danych. Następnie utwórz prosty komponent, rozszerzając QueryBasedExampleGen.
Może to wymagać dodatkowej konfiguracji połączeń lub nie. Na przykład moduł wykonawczy BigQuery odczytuje dane przy użyciu domyślnego łącznika Beam.io, który wyodrębnia szczegóły konfiguracji połączenia. Executor Presto wymaga jako danych wejściowych niestandardowej Beam PTransform i niestandardowego protokołu konfiguracji połączenia .
Jeśli dla niestandardowego komponentu PrzykładGen wymagana jest konfiguracja połączenia, utwórz nowy protobuf i przekaż go za pomocą niestandardowej konfiguracji, która jest teraz opcjonalnym parametrem wykonania. Poniżej znajduje się przykład użycia skonfigurowanego komponentu.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Przykładowe komponenty niższego szczebla
Niestandardowa konfiguracja podziału jest obsługiwana dla dalszych komponentów.
StatystykiGen
Domyślnym zachowaniem jest generowanie statystyk dla wszystkich podziałów.
Aby wykluczyć jakiekolwiek podziały, ustaw exclude_splits dla komponentu StatisticsGen. Na przykład:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchematGen
Domyślnym zachowaniem jest generowanie schematu na podstawie wszystkich podziałów.
Aby wykluczyć jakiekolwiek podziały, ustaw exclude_splits dla komponentu SchemaGen. Na przykład:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
Przykładowy walidator
Domyślnym zachowaniem jest sprawdzanie statystyk wszystkich podziałów przykładów wejściowych względem schematu.
Aby wykluczyć jakiekolwiek podziały, ustaw exclude_splits dla komponentu exampleValidator. Na przykład:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Przekształcać
Domyślnym zachowaniem jest analiza i utworzenie metadanych z podziału „pociągu” oraz przekształcenie wszystkich podziałów.
Aby określić podziały analizy i podziały transformacji, ustaw splits_config dla komponentu Transform. Na przykład:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Trener i tuner
Domyślnym zachowaniem jest trenowanie przy podziale „pociągowym” i ocenianie przy podziale „eval”.
Aby określić podziały pociągów i oszacować podziały, ustaw train_args i eval_args dla komponentu Trainer. Na przykład:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Oceniający
Domyślnym zachowaniem jest dostarczanie metryk obliczonych na podstawie podziału „eval”.
Aby obliczyć statystyki oceny dla niestandardowych podziałów, ustaw example_splits dla komponentu Evaluator. Na przykład:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Więcej szczegółów można znaleźć w dokumentach API CsvExampleGen , Implementacja API FileBasedExampleGen i Informacje o API ImportExampleGen .