
ML メタデータ (MLMD) は、 ML 開発者およびデータ サイエンティストのワークフローに関連付けられたメタデータを記録および取得するためのライブラリです。 MLMD はTensorFlow Extended (TFX)の不可欠な部分ですが、独立して使用できるように設計されています。
本番環境の ML パイプラインを実行するたびに、さまざまなパイプライン コンポーネント、その実行 (トレーニング実行など)、結果として得られるアーティファクト (トレーニング済みモデルなど) に関する情報を含むメタデータが生成されます。パイプラインの予期しない動作やエラーが発生した場合、このメタデータを利用してパイプライン コンポーネントの系統を分析し、問題をデバッグできます。このメタデータは、ソフトウェア開発におけるログインに相当すると考えてください。
MLMD は、ML パイプラインの相互接続された部分を個別に分析するのではなく、すべて理解して分析するのに役立ち、ML パイプラインに関する次のような質問に答えるのに役立ちます。
- モデルはどのデータセットでトレーニングされましたか?
- モデルのトレーニングに使用されたハイパーパラメーターは何ですか?
- どのパイプライン実行でモデルが作成されましたか?
- どのトレーニング実行がこのモデルにつながりましたか?
- このモデルを作成した TensorFlow のバージョンはどれですか?
- 失敗したモデルはいつプッシュされましたか?
メタデータストア
MLMD は、次のタイプのメタデータをメタデータ ストアと呼ばれるデータベースに登録します。
- ML パイプラインのコンポーネント/ステップを通じて生成されたアーティファクトに関するメタデータ
- これらのコンポーネント/ステップの実行に関するメタデータ
- パイプラインおよび関連する系統情報に関するメタデータ
メタデータ ストアは、ストレージ バックエンドとの間でメタデータを記録および取得するための API を提供します。ストレージ バックエンドはプラグイン可能であり、拡張することができます。 MLMD は、SQLite (メモリ内とディスクをサポート) および MySQL のすぐに使用できるリファレンス実装を提供します。
この図は、MLMD の一部であるさまざまなコンポーネントの概要を示しています。
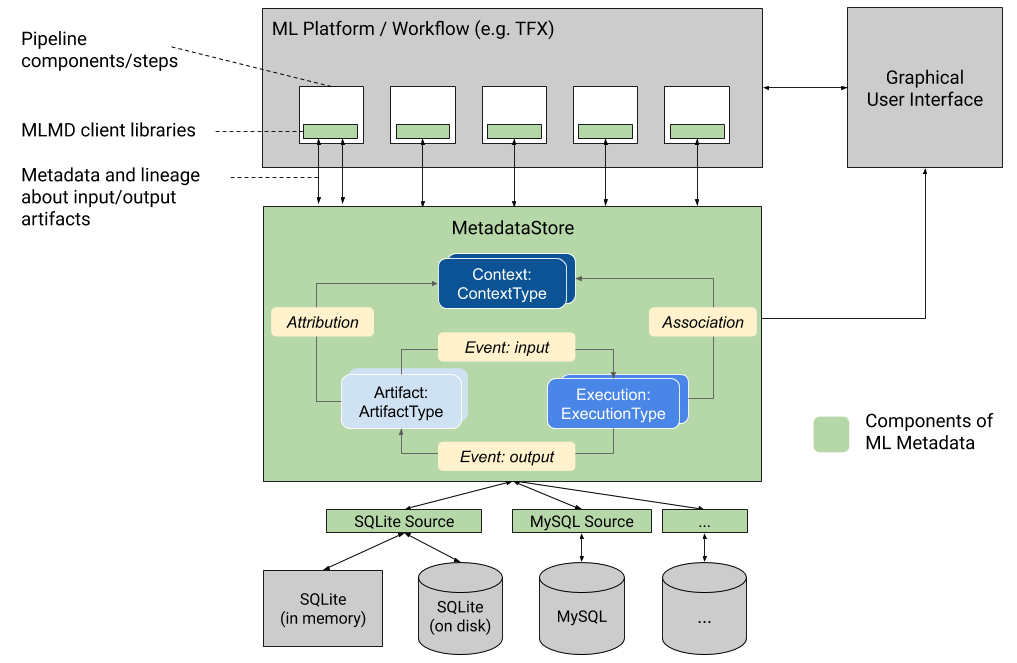
メタデータ ストレージ バックエンドとストア接続構成
MetadataStoreオブジェクトは、使用されるストレージ バックエンドに対応する接続構成を受け取ります。
- Fake Database は、高速な実験とローカル実行のためのインメモリ DB (SQLite を使用) を提供します。ストア オブジェクトが破棄されると、データベースも削除されます。
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite はディスクからファイルを読み書きします。
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL はMySQL サーバーに接続します。
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
同様に、Google CloudSQL で MySQL インスタンスを使用する場合 (クイックスタート、接続概要)、該当する場合は SSL オプションを使用することもできます。
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL はPostgreSQL サーバーに接続します。
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
同様に、Google CloudSQL で PostgreSQL インスタンスを使用する場合 (クイックスタート、接続概要)、該当する場合は SSL オプションを使用することもできます。
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
データモデル
メタデータ ストアは、次のデータ モデルを使用して、ストレージ バックエンドからメタデータを記録および取得します。
-
ArtifactType、メタデータ ストアに保存されるアーティファクトのタイプとそのプロパティを記述します。これらの型をコードでメタデータ ストアにオンザフライで登録したり、シリアル化された形式からストアにロードしたりできます。型を登録すると、その定義はストアの存続期間全体にわたって使用できます。 -
ArtifactArtifactTypeの特定のインスタンスと、メタデータ ストアに書き込まれるそのプロパティを記述します。 -
ExecutionType、ワークフロー内のコンポーネントまたはステップのタイプとその実行時パラメータを記述します。 -
ExecutionML ワークフロー内のコンポーネントの実行またはステップと実行時パラメーターの記録です。実行はExecutionTypeのインスタンスとして考えることができます。 ML パイプラインまたはステップを実行すると、実行が記録されます。 -
Event、成果物と実行の間の関係の記録です。実行が発生すると、その実行で使用されたすべてのアーティファクトと、生成されたすべてのアーティファクトがイベントに記録されます。これらのレコードにより、ワークフロー全体で系統追跡が可能になります。 MLMD はすべてのイベントを調べることで、どのような実行が行われ、その結果としてどのようなアーティファクトが作成されたかを把握します。 MLMD は、任意のアーティファクトからすべての上流入力に再帰的に戻ることができます。 -
ContextTypeワークフロー内のアーティファクトと実行の概念的なグループのタイプとその構造プロパティを記述します。例: プロジェクト、パイプライン実行、実験、所有者など。 -
ContextContextTypeのインスタンスです。グループ内の共有情報を取得します。例: プロジェクト名、変更リストのコミット ID、実験の注釈など。ContextType内にユーザー定義の一意の名前があります。 -
Attributionは、成果物とコンテキストの間の関係の記録です。 -
Association、実行とコンテキストの間の関係の記録です。
MLMD 機能
ML ワークフロー内のすべてのコンポーネント/ステップの入出力とその系統を追跡することで、ML プラットフォームでいくつかの重要な機能を有効にすることができます。次のリストは、主要な利点の一部の概要を示したものですが、すべてを網羅しているわけではありません。
- 特定のタイプのすべてのアーティファクトをリストします。例: トレーニングされたすべてのモデル。
- 比較のために同じタイプの 2 つのアーティファクトをロードします。例: 2 つの実験の結果を比較します。
- 関連するすべての実行とコンテキストの入力および出力アーティファクトの DAG を表示します。例: デバッグと検出のための実験のワークフローを視覚化します。
- すべてのイベントを再帰して、アーティファクトがどのように作成されたかを確認します。例: どのようなデータがモデルに入力されたかを確認します。データ保持計画を実施します。
- 特定のアーティファクトを使用して作成されたすべてのアーティファクトを識別します。例: 特定のデータセットからトレーニングされたすべてのモデルを表示します。悪いデータに基づいてモデルをマークします。
- 以前に同じ入力に対して実行が実行されたかどうかを確認します。例: コンポーネント/ステップが同じ作業をすでに完了しており、以前の出力をそのまま再利用できるかどうかを判断します。
- ワークフロー実行のコンテキストを記録およびクエリします。例: ワークフローの実行に使用される所有者と変更リストを追跡します。実験によって系統をグループ化する。成果物をプロジェクトごとに管理します。
- プロパティおよび 1 ホップ近傍ノードに対する宣言型ノードのフィルタリング機能。例: パイプライン コンテキストの下で、あるタイプのアーティファクトを検索します。指定されたプロパティの値が範囲内にある型付きアーティファクトを返します。同じ入力を持つコンテキスト内の以前の実行を検索します。
MLMD API とメタデータ ストアを使用してリネージ情報を取得する方法を示す例については、 MLMD チュートリアルを参照してください。
ML メタデータを ML ワークフローに統合する
MLMD をシステムに統合することに関心のあるプラットフォーム開発者の場合は、以下のワークフロー例を使用して、低レベル MLMD API を使用してトレーニング タスクの実行を追跡します。ノートブック環境で高レベルの Python API を使用して、実験のメタデータを記録することもできます。
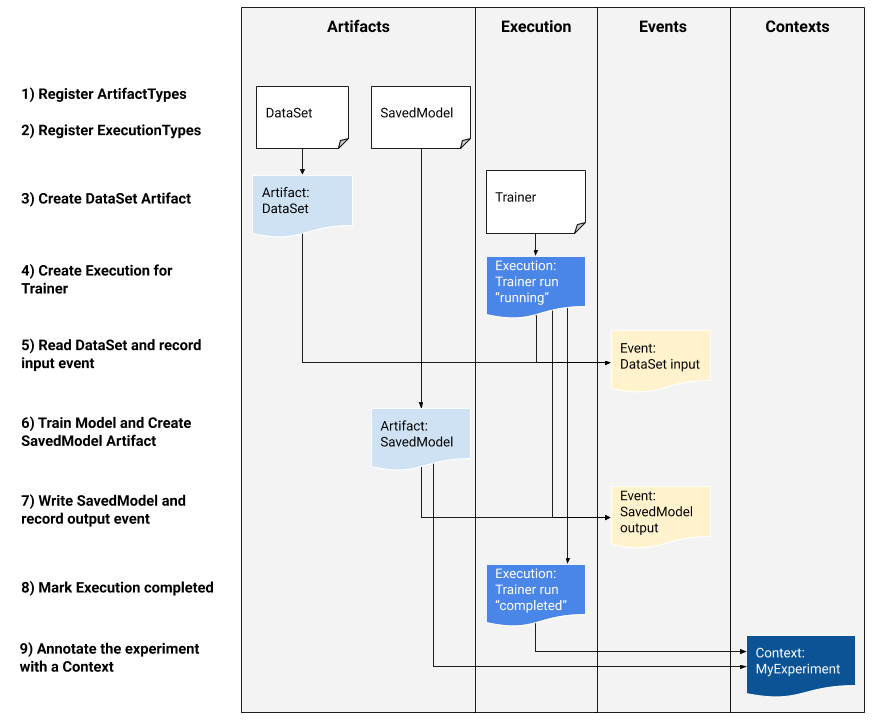
1) 成果物の種類を登録する
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) ML ワークフローのすべてのステップの実行タイプを登録する
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) DataSet ArtifactType のアーティファクトを作成します
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) トレーナー実行の実行を作成する
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) 入力イベントの定義とデータの読み取り
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) 出力アーティファクトを宣言する
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) 出力イベントを記録する
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) 実行を完了としてマークします
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) 属性とアサーション アーティファクトを使用して、コンテキストの下でアーティファクトと実行をグループ化する
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
リモート gRPC サーバーで MLMD を使用する
以下に示すように、リモート gRPC サーバーで MLMD を使用できます。
- サーバーを起動する
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
デフォルトでは、サーバーはリクエストごとに偽のメモリ内データベースを使用し、呼び出し間でメタデータを保持しません。 SQLite ファイルまたは MySQL インスタンスを使用するように MLMD MetadataStoreServerConfigを使用して構成することもできます。構成はテキスト protobuf ファイルに保存し、 --metadata_store_server_config_file=path_to_the_config_fileを使用してバイナリに渡すことができます。
テキスト protobuf 形式のMetadataStoreServerConfigファイルの例:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- クライアント スタブを作成して Python で使用する
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- RPC 呼び出しで MLMD を使用する
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
リソース
MLMD ライブラリには、ML パイプラインですぐに使用できる高レベルの API が含まれています。詳細については、 MLMD API ドキュメントを参照してください。
MLMD 宣言型ノード フィルタリングを確認して、プロパティおよび 1 ホップ近傍ノードで MLMD 宣言型ノード フィルタリング機能を使用する方法を確認してください。
また、 MLMD チュートリアルを参照して、MLMD を使用してパイプライン コンポーネントの系統を追跡する方法を学習してください。
MLMD は、リリース間でのスキーマとデータの移行を処理するユーティリティを提供します。詳細については、MLMDガイドを参照してください。