
giriiş
Bu eğitim , TensorFlow Extended (TFX) ve AIPlatform Pipelines'ı tanıtmak ve Google Cloud'da kendi makine öğrenimi ardışık düzenlerinizi oluşturmayı öğrenmenize yardımcı olmak için tasarlanmıştır. TFX, AI Platform Pipelines ve Kubeflow ile entegrasyonun yanı sıra Jupyter not defterlerinde TFX ile etkileşimi gösterir.
Bu eğitimin sonunda Google Cloud'da barındırılan bir ML Pipeline oluşturup çalıştıracaksınız. Her çalışmanın sonuçlarını görselleştirebilecek ve oluşturulan eserlerin kökenini görüntüleyebileceksiniz.
Veri kümesini inceleyerek başlayıp eksiksiz bir çalışma hattıyla biten tipik bir makine öğrenimi geliştirme sürecini izleyeceksiniz. Yol boyunca işlem hattınızda hata ayıklamanın, güncellemenin ve performansı ölçmenin yollarını keşfedeceksiniz.
Chicago Taksi Veri Kümesi


Chicago Şehri tarafından yayımlanan Taxi Trips veri kümesini kullanıyorsunuz.
Google BigQuery'de veri kümesi hakkında daha fazla bilgi edinebilirsiniz. BigQuery kullanıcı arayüzünde veri kümesinin tamamını keşfedin.
Model Hedefi - İkili sınıflandırma
Müşteri %20'den fazla mı yoksa az mı bahşiş verecek?
1. Bir Google Cloud projesi oluşturun
1.a Ortamınızı Google Cloud'da kurun
Başlamak için bir Google Cloud Hesabınıza ihtiyacınız var. Zaten bir tane varsa, Yeni Proje Oluştur'a geçin.
Google Cloud Console'a gidin.
Google Cloud şartlar ve koşullarını kabul edin
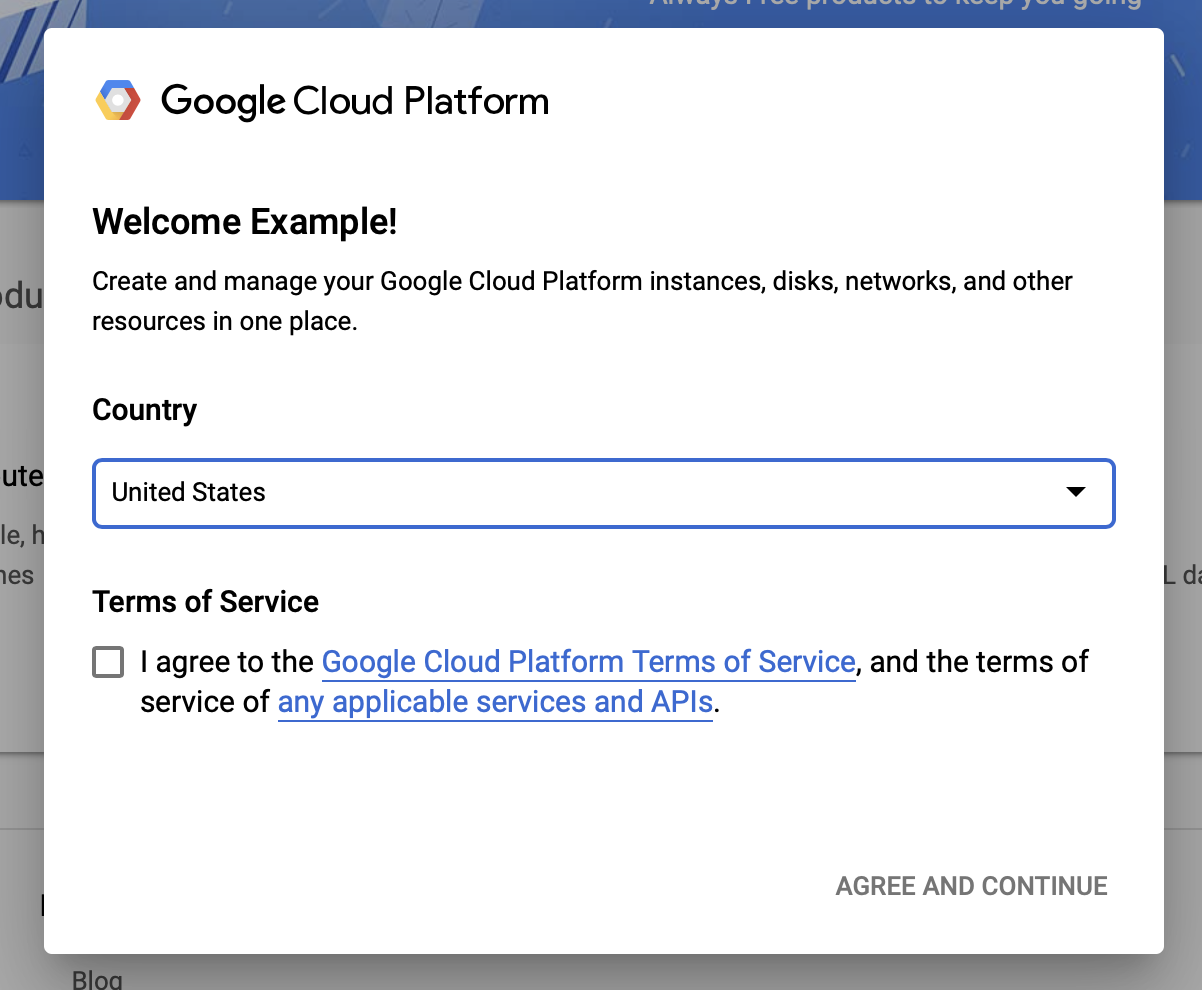
Ücretsiz deneme hesabıyla başlamak istiyorsanız Ücretsiz Dene'ye (veya Ücretsiz başlayın ) tıklayın.
Ülkenizi seçin.
Hizmet şartlarını kabul edin.
Fatura ayrıntılarını girin.
Bu noktada sizden ücret alınmayacaktır. Başka Google Cloud projeniz yoksa bu eğiticiyi, aynı anda maksimum 8 çekirdeğin çalışmasını içeren Google Cloud Ücretsiz Kullanım sınırlarını aşmadan tamamlayabilirsiniz.
1.b Yeni bir proje oluşturun.
- Ana Google Cloud kontrol panelinden , Google Cloud Platform başlığının yanındaki proje açılır menüsünü tıklayın ve Yeni Proje'yi seçin.
- Projenize bir ad verin ve diğer proje ayrıntılarını girin
- Bir proje oluşturduğunuzda, proje açılır menüsünden onu seçtiğinizden emin olun.
2. Yeni bir Kubernetes kümesinde bir AI Platform Pipeline kurun ve dağıtın
AI Platform İşlem Hatları Kümeleri sayfasına gidin.
Ana Gezinme Menüsü altında: ≡ > AI Platform > İşlem Hatları
Yeni bir küme oluşturmak için + Yeni Örnek'e tıklayın.

Kubeflow İşlem Hatları genel bakış sayfasında Yapılandır'a tıklayın.

Kubernetes Engine API'sini etkinleştirmek için "Etkinleştir"i tıklayın
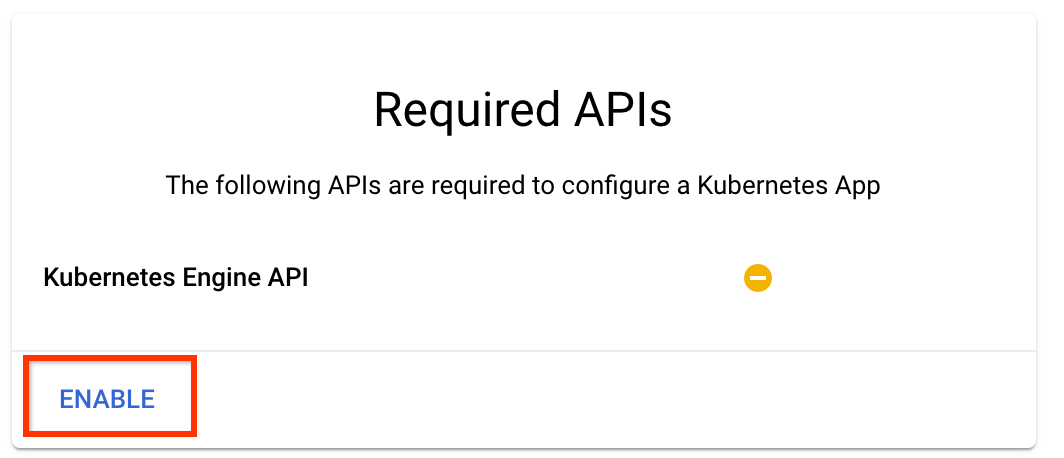
Kubeflow İşlem Hatlarını Dağıt sayfasında:
Kümeniz için bir bölge (veya "bölge") seçin. Ağ ve alt ağ ayarlanabilir ancak bu eğitimin amaçları doğrultusunda bunları varsayılan olarak bırakacağız.
ÖNEMLİ Aşağıdaki bulut API'lerine erişime izin ver etiketli kutuyu işaretleyin. (Bu kümenin projenizin diğer parçalarına erişmesi için bu gereklidir. Bu adımı kaçırırsanız daha sonra düzeltmek biraz zor olabilir.)
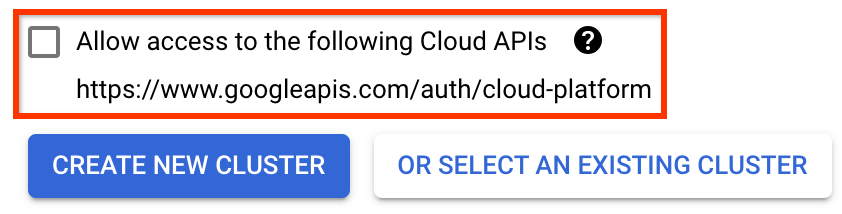
Yeni Küme Oluştur'u tıklayın ve küme oluşturulana kadar birkaç dakika bekleyin. Bu birkaç dakika sürecektir. Tamamlandığında şöyle bir mesaj göreceksiniz:
"Küme-1" kümesi "us-central1-a" bölgesinde başarıyla oluşturuldu.
Bir ad alanı ve örnek adı seçin (varsayılanları kullanmakta sorun yoktur). Bu eğitimin amaçları doğrultusunda executor.emissary veya yönetilenstorage.enabled'ı işaretlemeyin.
Dağıt'a tıklayın ve işlem hattı dağıtılana kadar birkaç dakika bekleyin. Kubeflow Pipelines'ı dağıtarak Hizmet Şartlarını kabul etmiş olursunuz.
3. Cloud AI Platform Notebook örneğini kurun.
Vertex AI Workbench sayfasına gidin. Workbench'i ilk kez çalıştırdığınızda Notebooks API'yi etkinleştirmeniz gerekecektir.
Ana Gezinme Menüsü altında: ≡ -> Vertex AI -> Workbench
İstenirse Compute Engine API'yi etkinleştirin.
TensorFlow Enterprise 2.7 (veya üzeri) yüklü olan Yeni bir Not Defteri oluşturun.
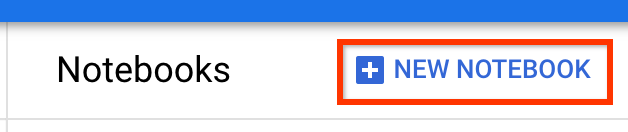
Yeni Dizüstü Bilgisayar -> TensorFlow Enterprise 2.7 -> GPU'suz
Bir bölge ve bölge seçin ve not defteri örneğine bir ad verin.
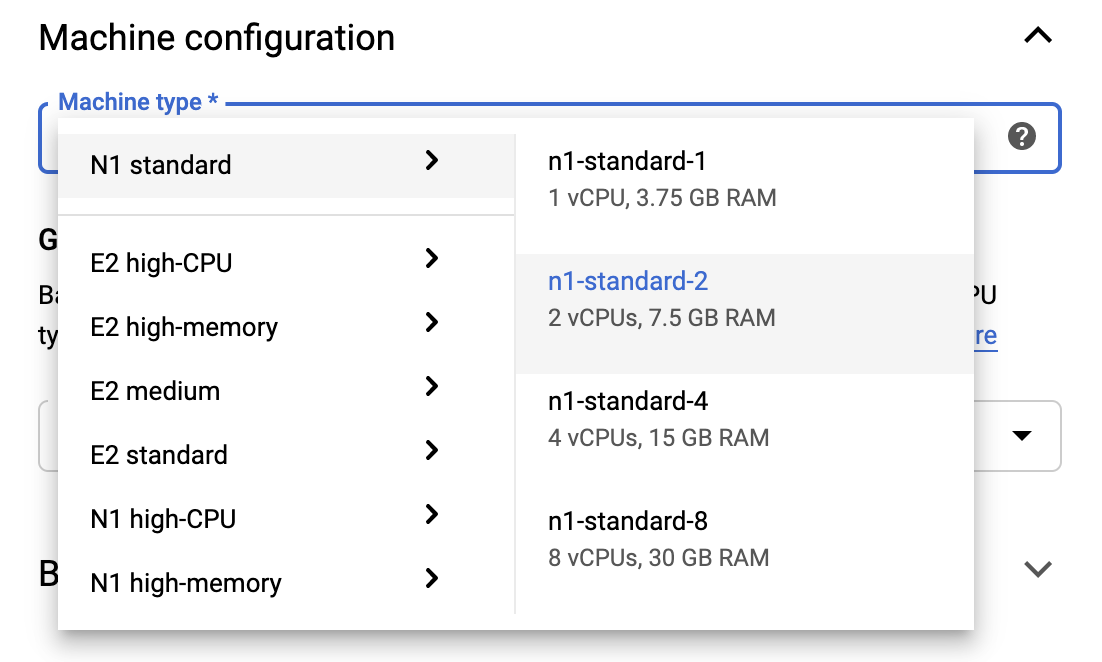
Ücretsiz Kullanım sınırları dahilinde kalmak için, bu örnekte kullanılabilen vCPU sayısını 4'ten 2'ye düşürmek amacıyla buradaki varsayılan ayarları değiştirmeniz gerekebilir:
- Yeni not defteri formunun altındaki Gelişmiş Seçenekler'i seçin.
Ücretsiz katmanda kalmanız gerekiyorsa Makine yapılandırması altında 1 veya 2 vCPU'lu bir yapılandırma seçmek isteyebilirsiniz.
Yeni not defterinin oluşturulmasını bekleyin ve ardından Not Defterleri API'sini Etkinleştir'e tıklayın.
4. Başlarken Not Defteri'ni başlatın
AI Platform İşlem Hatları Kümeleri sayfasına gidin.
Ana Gezinme Menüsü altında: ≡ -> AI Platform -> İşlem Hatları
Bu öğreticide kullandığınız kümenin satırında İşlem Hatları Kontrol Panelini Aç öğesine tıklayın.

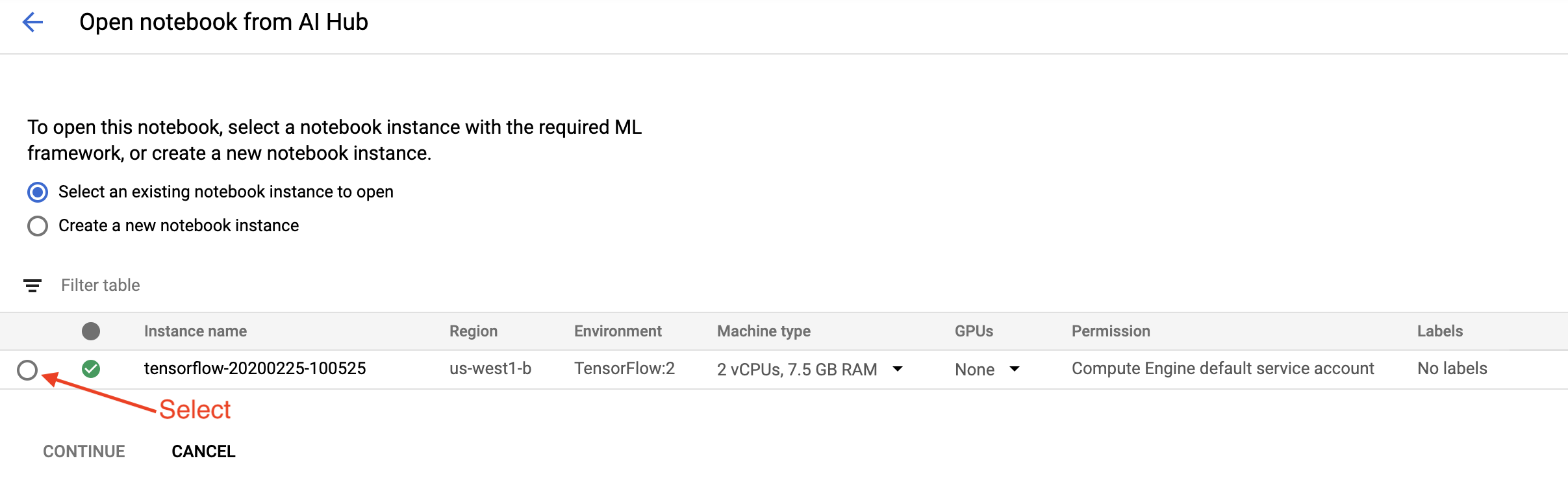
Başlarken sayfasında Google Cloud'da Cloud AI Platform Not Defteri Aç'ı tıklayın.

Bu eğitim için kullandığınız Notebook örneğini seçin, Devam Et'i ve ardından Onayla'yı seçin .
5. Defterde çalışmaya devam edin
Düzenlemek
Başlarken Not Defteri, Jupyter Lab'ın çalıştığı VM'ye TFX ve Kubeflow Pipelines'ın (KFP) kurulmasıyla başlar.
Daha sonra hangi TFX sürümünün kurulu olduğunu kontrol eder, bir içe aktarma işlemi gerçekleştirir ve Proje Kimliğini ayarlayıp yazdırır:

Google Cloud hizmetlerinize bağlanın
İşlem hattı yapılandırması, dizüstü bilgisayardan alabileceğiniz ve çevresel değişken olarak ayarlayabileceğiniz proje kimliğinize ihtiyaç duyar.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Şimdi KFP kümesi uç noktanızı ayarlayın.
Bu, Pipelines kontrol panelinin URL'sinden bulunabilir. Kubeflow Pipeline kontrol paneline gidin ve URL'ye bakın. Uç nokta, URL'deki https:// ile başlayan ve googleusercontent.com kadar olan her şeydir.
ENDPOINT='' # Enter YOUR ENDPOINT here.
Dizüstü bilgisayar daha sonra özel Docker görüntüsü için benzersiz bir ad belirler:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Bir şablonu proje dizininize kopyalayın
İşlem hattınız için bir ad belirlemek üzere sonraki not defteri hücresini düzenleyin. Bu derste my_pipeline kullanacağız.
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
Dizüstü bilgisayar daha sonra işlem hattı şablonunu kopyalamak için tfx CLI'yi kullanır. Bu eğitim, ikili sınıflandırmayı gerçekleştirmek için Chicago Taksi veri kümesini kullanır; böylece şablon, modeli taxi olarak ayarlar:
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
Dizüstü bilgisayar daha sonra CWD içeriğini proje dizinine değiştirir:
%cd {PROJECT_DIR}
Boru hattı dosyalarına göz atın
Cloud AI Platform Notebook'un sol tarafında bir dosya tarayıcısı görmelisiniz. Boru hattı adınızı ( my_pipeline ) içeren bir dizin bulunmalıdır. Açın ve dosyaları görüntüleyin. (Bunları not defteri ortamından da açabilecek ve düzenleyebileceksiniz.)
# You can also list the files from the shellls
Yukarıdaki tfx template copy komutu, bir ardışık düzen oluşturan dosyalardan oluşan temel bir yapı iskelesi oluşturdu. Bunlara Python kaynak kodları, örnek veriler ve Jupyter not defterleri dahildir. Bunlar bu özel örnek için verilmiştir. Kendi işlem hatlarınız için bunlar, işlem hattınızın gerektirdiği destekleyici dosyalar olacaktır.
İşte Python dosyalarının kısa açıklaması.
-
pipeline- Bu dizin boru hattının tanımını içerir-
configs.py- işlem hattı çalıştırıcıları için ortak sabitleri tanımlar -
pipeline.py— TFX bileşenlerini ve bir ardışık düzeni tanımlar
-
-
models- Bu dizin ML model tanımlarını içerir.-
features.pyfeatures_test.py— modelin özelliklerini tanımlar -
preprocessing.py/preprocessing_test.py—tf::Transformkullanarak ön işleme işlerini tanımlar -
estimator- Bu dizin Tahminci tabanlı bir model içerir.-
constants.py- modelin sabitlerini tanımlar -
model.py/model_test.py- TF tahmincisini kullanarak DNN modelini tanımlar
-
-
keras- Bu dizin Keras tabanlı bir model içerir.-
constants.py- modelin sabitlerini tanımlar -
model.py/model_test.py- Keras'ı kullanarak DNN modelini tanımlar
-
-
-
beam_runner.py/kubeflow_runner.py— her orkestrasyon motoru için çalıştırıcıları tanımlayın
7. İlk TFX işlem hattınızı Kubeflow'ta çalıştırın
Dizüstü bilgisayar, işlem hattını tfx run CLI komutunu kullanarak çalıştıracaktır.
Depolama birimine bağlanın
İşlem hatlarını çalıştırmak , ML-Metadata'da depolanması gereken yapılar oluşturur. Yapıtlar, bir dosya sisteminde veya blok depolamada depolanması gereken dosyalar olan yükleri ifade eder. Bu eğitimde, meta veri yüklerimizi depolamak için kurulum sırasında otomatik olarak oluşturulan paketi kullanarak GCS'yi kullanacağız. Adı <your-project-id>-kubeflowpipelines-default olacaktır.
Boru hattını oluşturun
Not defteri, örnek verilerimizi daha sonra ardışık düzenimizde kullanabilmemiz için GCS paketine yükleyecektir.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv Dizüstü bilgisayar daha sonra işlem hattını oluşturmak için tfx pipeline create komutunu kullanır.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
Bir işlem hattı oluştururken, Docker görüntüsü oluşturmak için Dockerfile oluşturulacaktır. Bu dosyaları diğer kaynak dosyalarla birlikte kaynak kontrol sisteminize (örneğin git) eklemeyi unutmayın.
Boru hattını çalıştırın
Dizüstü bilgisayar daha sonra işlem hattınızın yürütme çalıştırmasını başlatmak için tfx run create komutunu kullanır. Bu çalıştırmanın Kubeflow Pipelines Kontrol Panelindeki Denemeler altında da listelendiğini göreceksiniz.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}İşlem hattınızı Kubeflow Pipelines Kontrol Panelinden görüntüleyebilirsiniz.
8. Verilerinizi doğrulayın
Herhangi bir veri bilimi veya makine öğrenimi projesinde ilk görev, verileri anlamak ve temizlemektir.
- Her özelliğe ilişkin veri türlerini anlayın
- Anormallikleri ve eksik değerleri arayın
- Her özelliğin dağılımlarını anlayın
Bileşenler


- SampleGen giriş veri kümesini alır ve böler.
- İstatistikGen, veri kümesine ilişkin istatistikleri hesaplar.
- SchemaGen SchemaGen istatistikleri inceler ve bir veri şeması oluşturur.
- SampleValidator, veri kümesindeki anormallikleri ve eksik değerleri arar.
Jupyter laboratuvar dosya düzenleyicisinde:
pipeline / pipeline.py dosyasında, bu bileşenleri ardışık düzeninize ekleyen satırların açıklamalarını kaldırın:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen şablon dosyaları kopyalandığında zaten etkindi.)
İşlem hattını güncelleyin ve yeniden çalıştırın
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Boru hattını kontrol edin
Kubeflow Orchestrator için KFP kontrol panelini ziyaret edin ve işlem hattı çalıştırmanıza ilişkin sayfada işlem hattı çıktılarını bulun. Soldaki "Denemeler" sekmesini ve Deneyler sayfasında "Tüm çalıştırmalar"ı tıklayın. İşlem hattınızın adını içeren çalıştırmayı bulabilmelisiniz.
Daha gelişmiş örnek
Burada sunulan örnek aslında yalnızca başlamanıza yardımcı olmak içindir. Daha gelişmiş bir örnek için TensorFlow Veri Doğrulama Colab'ına bakın.
Bir veri kümesini araştırmak ve doğrulamak amacıyla TFDV'yi kullanma hakkında daha fazla bilgi için tensorflow.org'daki örneklere bakın .
9. Özellik mühendisliği
Özellik mühendisliği ile verilerinizin tahmin kalitesini artırabilir ve/veya boyutluluğunu azaltabilirsiniz.
- Özellik geçişleri
- Kelime Dağarcığı
- Gömmeler
- PCA
- Kategorik kodlama
TFX kullanmanın faydalarından biri, dönüşüm kodunuzu bir kez yazmanız ve ortaya çıkan dönüşümlerin eğitim ve sunum arasında tutarlı olmasıdır.
Bileşenler

- Transform, veri kümesi üzerinde özellik mühendisliği gerçekleştirir.
Jupyter laboratuvar dosya düzenleyicisinde:
pipeline / pipeline.py dosyasında, Transform'u işlem hattına ekleyen satırı bulun ve açıklamasını kaldırın.
# components.append(transform)
İşlem hattını güncelleyin ve yeniden çalıştırın
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Boru hattı çıkışlarını kontrol edin
Kubeflow Orchestrator için KFP kontrol panelini ziyaret edin ve işlem hattı çalıştırmanıza ilişkin sayfada işlem hattı çıktılarını bulun. Soldaki "Denemeler" sekmesini ve Deneyler sayfasında "Tüm çalıştırmalar"ı tıklayın. İşlem hattınızın adını içeren çalıştırmayı bulabilmelisiniz.
Daha gelişmiş örnek
Burada sunulan örnek aslında yalnızca başlamanıza yardımcı olmak içindir. Daha gelişmiş bir örnek için TensorFlow Transform Colab'a bakın.
10. Eğitim
Güzel, temiz, dönüştürülmüş verilerinizle bir TensorFlow modelini eğitin.
- Tutarlı bir şekilde uygulanmaları için önceki adımdaki dönüşümleri dahil edin
- Sonuçları üretim için SavedModel olarak kaydedin
- TensorBoard'u kullanarak eğitim sürecini görselleştirin ve keşfedin
- Ayrıca model performansının analizi için bir EvalSavedModel'i kaydedin
Bileşenler
- Eğitmen bir TensorFlow modelini eğitir.
Jupyter laboratuvar dosya düzenleyicisinde:
pipeline / pipeline.py dosyasında, Trainer'ı boru hattına ekleyen öğeyi bulun ve açıklamasını kaldırın:
# components.append(trainer)
İşlem hattını güncelleyin ve yeniden çalıştırın
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Boru hattı çıkışlarını kontrol edin
Kubeflow Orchestrator için KFP kontrol panelini ziyaret edin ve işlem hattı çalıştırmanıza ilişkin sayfada işlem hattı çıktılarını bulun. Soldaki "Denemeler" sekmesini ve Deneyler sayfasında "Tüm çalıştırmalar"ı tıklayın. İşlem hattınızın adını içeren çalıştırmayı bulabilmelisiniz.
Daha gelişmiş örnek
Burada sunulan örnek aslında yalnızca başlamanıza yardımcı olmak içindir. Daha gelişmiş bir örnek için TensorBoard Eğitimine bakın.
11. Model performansını analiz etme
Üst düzey ölçümlerden daha fazlasını anlama.
- Kullanıcılar yalnızca kendi sorguları için model performansını deneyimler
- Veri dilimlerindeki düşük performans, üst düzey ölçümlerle gizlenebilir
- Model adaleti önemlidir
- Çoğunlukla kullanıcıların veya verilerin önemli alt kümeleri çok önemlidir ve küçük olabilir
- Kritik ancak olağandışı koşullarda performans
- Etkileyiciler gibi önemli kitlelere yönelik performans
- Şu anda üretimde olan bir modeli değiştiriyorsanız, öncelikle yenisinin daha iyi olduğundan emin olun.
Bileşenler
- Değerlendirici eğitim sonuçlarının derinlemesine analizini yapar.
Jupyter laboratuvar dosya düzenleyicisinde:
pipeline / pipeline.py dosyasında, Değerlendiriciyi işlem hattına ekleyen satırı bulun ve açıklamasını kaldırın:
components.append(evaluator)
İşlem hattını güncelleyin ve yeniden çalıştırın
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Boru hattı çıkışlarını kontrol edin
Kubeflow Orchestrator için KFP kontrol panelini ziyaret edin ve işlem hattı çalıştırmanıza ilişkin sayfada işlem hattı çıktılarını bulun. Soldaki "Denemeler" sekmesini ve Deneyler sayfasında "Tüm çalıştırmalar"ı tıklayın. İşlem hattınızın adını içeren çalıştırmayı bulabilmelisiniz.
12. Modelin sunumu
Yeni model hazırsa öyle yapın.
- Pusher, SavedModels'ı iyi bilinen konumlara dağıtıyor
Dağıtım hedefleri, iyi bilinen konumlardan yeni modeller alıyor
- TensorFlow Sunumu
- TensorFlow Lite
- TensorFlow JS
- TensorFlow Merkezi
Bileşenler
- İtici, modeli hizmet veren bir altyapıya dağıtır.
Jupyter laboratuvar dosya düzenleyicisinde:
pipeline / pipeline.py dosyasında, Pusher'ı boru hattına ekleyen satırı bulun ve açıklamasını kaldırın:
# components.append(pusher)
Boru hattı çıkışlarını kontrol edin
Kubeflow Orchestrator için KFP kontrol panelini ziyaret edin ve işlem hattı çalıştırmanıza ilişkin sayfada işlem hattı çıktılarını bulun. Soldaki "Denemeler" sekmesini ve Deneyler sayfasında "Tüm çalıştırmalar"ı tıklayın. İşlem hattınızın adını içeren çalıştırmayı bulabilmelisiniz.
Kullanılabilir dağıtım hedefleri
Artık modelinizi eğitip doğruladınız ve modeliniz artık üretime hazır. Artık modelinizi aşağıdakiler dahil TensorFlow dağıtım hedeflerinden herhangi birine dağıtabilirsiniz:
- Modelinizi bir sunucu veya sunucu grubunda sunmak ve REST ve/veya gRPC çıkarım isteklerini işlemek için TensorFlow Serving .
- Modelinizi bir Android veya iOS yerel mobil uygulamasına veya Raspberry Pi, IoT veya mikro denetleyici uygulamasına dahil etmek için TensorFlow Lite .
- Modelinizi bir web tarayıcısında veya Node.JS uygulamasında çalıştırmak için TensorFlow.js .
Daha gelişmiş örnekler
Yukarıda sunulan örnek aslında yalnızca başlamanıza yardımcı olmak içindir. Aşağıda diğer Bulut hizmetleriyle entegrasyona ilişkin bazı örnekler verilmiştir.
Kubeflow Pipelines kaynağıyla ilgili hususlar
İş yükünüzün gereksinimlerine bağlı olarak Kubeflow Pipelines dağıtımınızın varsayılan yapılandırması ihtiyaçlarınızı karşılayabilir veya karşılamayabilir. KubeflowDagRunnerConfig çağrınızda pipeline_operator_funcs kullanarak kaynak yapılandırmalarınızı özelleştirebilirsiniz.
pipeline_operator_funcs KubeflowDagRunner derlenen KFP işlem hattı spesifikasyonunda oluşturulan tüm ContainerOp örneklerini dönüştüren OpFunc öğelerinin bir listesidir.
Örneğin, belleği yapılandırmak için gereken bellek miktarını bildirmek üzere set_memory_request kullanabiliriz. Bunu yapmanın tipik bir yolu, set_memory_request için bir sarmalayıcı oluşturmak ve bunu ardışık düzen OpFunc s listesine eklemek için kullanmaktır:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Benzer kaynak yapılandırma işlevleri şunları içerir:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
BigQueryExampleGen deneyin
BigQuery, sunucusuz, yüksek düzeyde ölçeklenebilir ve uygun maliyetli bir bulut veri ambarıdır. BigQuery, TFX'teki eğitim örnekleri için kaynak olarak kullanılabilir. Bu adımda BigQueryExampleGen işlem hattına ekleyeceğiz.
Jupyter laboratuvar dosya düzenleyicisinde:
pipeline.py açmak için çift tıklayın . CsvExampleGen yorumlayın ve BigQueryExampleGen örneğini oluşturan satırın açıklamasını kaldırın. Ayrıca create_pipeline fonksiyonunun query argümanının açıklamasını da kaldırmanız gerekir.
BigQuery için hangi GCP projesini kullanacağımızı belirtmemiz gerekiyor ve bu, bir ardışık düzen oluştururken beam_pipeline_args içinde --project ayarı yapılarak yapılır.
configs.py açmak için çift tıklayın . BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS ve BIG_QUERY_QUERY tanımlarının açıklamasını kaldırın. Bu dosyadaki proje kimliğini ve bölge değerini GCP projeniz için doğru değerlerle değiştirmelisiniz.
Dizini bir seviye yukarı değiştirin. Dosya listesinin üzerindeki dizinin adına tıklayın. Dizinin adı, boru hattı adını değiştirmediyseniz my_pipeline olan boru hattının adıdır.
kubeflow_runner.py açmak için çift tıklayın . create_pipeline işlevi için iki bağımsız değişkenin ( query ve beam_pipeline_args açıklamalarını kaldırın.
Artık ardışık düzen örnek kaynak olarak BigQuery'yi kullanmaya hazır. İşlem hattını daha önce olduğu gibi güncelleyin ve 5. ve 6. adımlarda yaptığımız gibi yeni bir yürütme çalıştırması oluşturun.
İşlem hattını güncelleyin ve yeniden çalıştırın
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Dataflow'u deneyin
Birçok TFX Bileşeni, veri paralel ardışık düzenleri uygulamak için Apache Beam'i kullanır ve bu , Google Cloud Dataflow'u kullanarak veri işleme iş yüklerini dağıtabileceğiniz anlamına gelir. Bu adımda Kubeflow orkestratörünü Apache Beam için veri işleme arka ucu olarak Dataflow'u kullanacak şekilde ayarlayacağız.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Dizini değiştirmek için pipeline çift tıklayın ve configs.py açmak için çift tıklayın . GOOGLE_CLOUD_REGION ve DATAFLOW_BEAM_PIPELINE_ARGS tanımlarının açıklamasını kaldırın.
Dizini bir seviye yukarı değiştirin. Dosya listesinin üstündeki dizinin adına tıklayın. Dizinin adı, eğer değişmediyseniz my_pipeline olan boru hattının adıdır.
kubeflow_runner.py açmak için çift tıklayın . beam_pipeline_args açıklamasını kaldırın. (Ayrıca 7. Adımda eklediğiniz mevcut beam_pipeline_args yorum olarak belirttiğinizden emin olun.)
İşlem hattını güncelleyin ve yeniden çalıştırın
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Dataflow işlerinizi Cloud Console'daki Dataflow'da bulabilirsiniz.
KFP ile Cloud AI Platform Eğitimini ve Tahminini Deneyin
TFX , Eğitim ve Tahmin için Cloud AI Platformu gibi çeşitli yönetilen GCP hizmetleriyle birlikte çalışır. Trainer bileşeninizi, makine öğrenimi modellerinin eğitimi için yönetilen bir hizmet olan Cloud AI Platform Training'i kullanacak şekilde ayarlayabilirsiniz. Üstelik modeliniz oluşturulduğunda ve sunulmaya hazır olduğunda, modelinizi hizmet için Cloud AI Platform Prediction'a aktarabilirsiniz . Bu adımda Trainer ve Pusher bileşenimizi Cloud AI Platform hizmetlerini kullanacak şekilde ayarlayacağız.
Dosyaları düzenlemeden önce AI Platform Training & Prediction API'yi etkinleştirmeniz gerekebilir.
Dizini değiştirmek için pipeline çift tıklayın ve configs.py açmak için çift tıklayın . GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS ve GCP_AI_PLATFORM_SERVING_ARGS tanımının açıklamasını kaldırın. Cloud AI Platform Training'de bir model eğitmek için özel oluşturulmuş konteyner görüntümüzü kullanacağız, bu nedenle GCP_AI_PLATFORM_TRAINING_ARGS masterConfig.imageUri yukarıdaki CUSTOM_TFX_IMAGE ile aynı değere ayarlamalıyız.
Dizini bir seviye yukarı değiştirin ve kubeflow_runner.py açmak için çift tıklayın . ai_platform_training_args ve ai_platform_serving_args açıklamalarını kaldırın.
İşlem hattını güncelleyin ve yeniden çalıştırın
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Eğitim işlerinizi Cloud AI Platform İşleri bölümünde bulabilirsiniz. İşlem hattınız başarıyla tamamlandıysa modelinizi Cloud AI Platform Modelleri'nde bulabilirsiniz.
14. Kendi verilerinizi kullanın
Bu öğreticide Chicago Taxi veri kümesini kullanarak bir model için bir işlem hattı oluşturdunuz. Şimdi kendi verilerinizi ardışık düzene koymayı deneyin. Verileriniz, Google Cloud Storage, BigQuery veya CSV dosyaları da dahil olmak üzere ardışık düzenin erişebildiği her yerde depolanabilir.
Verilerinizi karşılamak için işlem hattı tanımını değiştirmeniz gerekir.
Verileriniz dosyalarda saklanıyorsa
-
kubeflow_runner.pydosyasındaDATA_PATHdeğiştirerek konumu belirtin.
Verileriniz BigQuery'de depolanıyorsa
- Configs.py'deki
BIG_QUERY_QUERYsorgu ifadenizde değiştirin. -
models/features.pydosyasına özellikler ekleyin. - Eğitim amacıyla giriş verilerini dönüştürmek için
modelspreprocessing.pydeğiştirin. - ML modelinizi tanımlamak için
models/keras/model.pyvemodels/keras/constants.pydeğiştirin.
Eğitmen hakkında daha fazla bilgi edinin
Eğitim hatları hakkında daha fazla ayrıntı için Eğitmen bileşen kılavuzuna bakın.
Temizleme
Bu projede kullanılan tüm Google Cloud kaynaklarını temizlemek için eğitim için kullandığınız Google Cloud projesini silebilirsiniz .
Alternatif olarak, her bir konsolu ziyaret ederek kaynakları ayrı ayrı temizleyebilirsiniz: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine