
SampleGen TFX İşlem Hattı bileşeni, verileri TFX işlem hatlarına alır. Diğer TFX bileşenleri tarafından okunacak Örnekler oluşturmak için harici dosyaları/hizmetleri kullanır. Aynı zamanda tutarlı ve yapılandırılabilir bölümleme sağlar ve ML'nin en iyi uygulaması için veri kümesini karıştırır.
- Tüketim: CSV,
TFRecord, Avro, Parquet ve BigQuery gibi harici veri kaynaklarından alınan veriler. - Yayılanlar:
tf.Examplekayıtları,tf.SequenceExamplekayıtları veya veri yükü formatına bağlı olarak protokol formatı.
SampleGen ve Diğer Bileşenler
ÖrnekGen, TensorFlow Veri Doğrulama kitaplığını kullanan SchemaGen , İstatistikGen ve Örnek Doğrulayıcı gibi bileşenlere veri sağlar. Ayrıca TensorFlow Transform kitaplığını kullanan Transform'a ve sonuç olarak çıkarım sırasında dağıtım hedeflerine veri sağlar.
Veri Kaynakları ve Formatları
Şu anda standart bir TFX kurulumu şu veri kaynakları ve formatları için tam SampleGen bileşenlerini içermektedir:
Bu veri kaynakları ve formatları için SampleGen bileşenlerinin geliştirilmesine olanak tanıyan özel yürütücüler de mevcuttur:
Özel yürütücülerin nasıl kullanılacağı ve geliştirileceği hakkında daha fazla bilgi için kaynak koddaki kullanım örneklerine ve bu tartışmaya bakın.
Ayrıca, bu veri kaynakları ve formatları özel bileşen örnekleri olarak mevcuttur:
Apache Beam tarafından desteklenen veri formatlarını alma
Apache Beam, çok çeşitli veri kaynaklarından ve formatlarından veri almayı destekler ( aşağıya bakın ). Bu yetenekler, mevcut bazı SampleGen bileşenlerinin gösterdiği gibi, TFX için özel SampleGen bileşenleri oluşturmak için kullanılabilir ( aşağıya bakın ).
ÖrnekGen Bileşeni nasıl kullanılır?
Desteklenen veri kaynakları için (şu anda CSV dosyaları, tf.Example ile TFRecord dosyaları, tf.SequenceExample ve proto biçimi ve BigQuery sorgularının sonuçları) SampleGen ardışık düzen bileşeni doğrudan dağıtımda kullanılabilir ve çok az özelleştirme gerektirir. Örneğin:
example_gen = CsvExampleGen(input_base='data_root')
veya harici TFRecord'u doğrudan tf.Example ile içe aktarmak için aşağıdaki gibi:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Yayılma, Sürüm ve Bölme
Span, eğitim örneklerinden oluşan bir gruptur. Verileriniz bir dosya sisteminde tutuluyorsa her Span ayrı bir dizinde saklanabilir. Bir Span'ın semantiği TFX'e sabit kodlanmamıştır; Span, bir günlük veriye, bir saatlik veriye veya göreviniz için anlamlı olan herhangi bir başka gruplandırmaya karşılık gelebilir.
Her Span birden fazla veri Sürümünü tutabilir. Örnek vermek gerekirse, düşük kaliteli verileri temizlemek için bir Span'dan bazı örnekleri kaldırırsanız bu, söz konusu Span'ın yeni bir Sürümünün oluşmasına neden olabilir. Varsayılan olarak TFX bileşenleri bir Span içindeki en son Sürümde çalışır.
Bir Kapsam dahilindeki her Sürüm ayrıca birden fazla Bölüme bölünebilir. Bir Span'ı bölmenin en yaygın kullanım durumu, onu eğitim ve değerlendirme verilerine bölmektir.
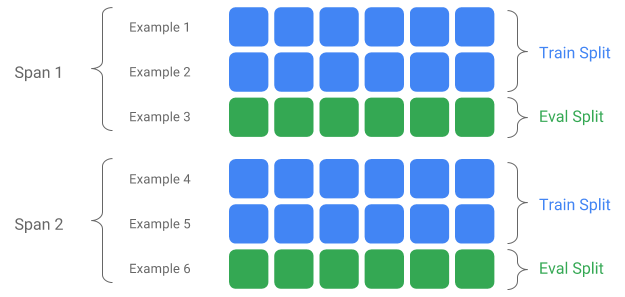
Özel giriş/çıkış ayrımı
SampleGen'in çıktısını alacağı eğitim/değerlendirme ayırma oranını özelleştirmek için, exampleGen bileşeninin output_config ayarlayın. Örneğin:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Bu örnekte hash_buckets nasıl ayarlandığına dikkat edin.
Zaten bölünmüş bir giriş kaynağı için, exampleGen bileşeni için input_config ayarlayın:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Dosya tabanlı örnek gen için (örn. CsvExampleGen ve ImportExampleGen), pattern , giriş tabanı yolu tarafından verilen kök dizine sahip giriş dosyalarıyla eşlenen bir glob göreli dosya modelidir. Sorgu tabanlı örnek gen için (örn. BigQueryExampleGen, PrestoExampleGen), pattern bir SQL sorgusudur.
Varsayılan olarak, giriş temel dizininin tamamı tek bir giriş bölmesi olarak ele alınır ve eğitim ve değerlendirme çıkış bölmesi 2:1 oranında oluşturulur.
SampleGen'in giriş ve çıkış bölme yapılandırması için lütfen proto/example_gen.proto adresine bakın. Ayrıca, aşağı yöndeki özel bölmeleri kullanmak için aşağı yöndeki bileşenler kılavuzuna bakın.
Bölme Yöntemi
hash_buckets bölme yöntemini kullanırken, kaydın tamamı yerine örnekleri bölümlemeye yönelik bir özellik kullanılabilir. Bir özellik mevcutsa, SampleGen bu özelliğin parmak izini bölüm anahtarı olarak kullanacaktır.
Bu özellik, örneklerin belirli özelliklerine göre istikrarlı bir bölünmeyi korumak için kullanılabilir: örneğin, bölüm özelliği adı olarak "user_id" seçilmişse kullanıcı her zaman aynı bölmeye yerleştirilecektir.
Bir "özelliğin" ne anlama geldiğinin yorumlanması ve bir "özelliğin" belirtilen adla nasıl eşleştirileceği, SampleGen uygulamasına ve örneklerin türüne bağlıdır.
Hazır ÖrnekGen uygulamaları için:
- Eğer tf.Example'ı oluşturursa, "özellik" tf.Example.features.feature'daki bir giriş anlamına gelir.
- tf.SequenceExample oluşturursa, "özellik" tf.SequenceExample.context.feature içindeki bir giriş anlamına gelir.
- Yalnızca int64 ve bytes özellikleri desteklenir.
Aşağıdaki durumlarda SampleGen çalışma zamanı hataları atar:
- Belirtilen özellik adı örnekte mevcut değil.
- Boş özellik:
tf.train.Feature(). - Desteklenmeyen özellik türleri, örneğin kayan özellikler.
Örneklerdeki bir özelliğe dayalı olarak eğitim/değerlendirme ayrımının çıktısını almak için, exampleGen bileşeni için output_config ayarlayın. Örneğin:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Bu örnekte partition_feature_name nasıl ayarlandığına dikkat edin.
Açıklık
Span , giriş glob modelinde '{SPAN}' spesifikasyonu kullanılarak alınabilir:
- Bu özellik, rakamları eşleştirir ve verileri ilgili SPAN numaralarıyla eşleştirir. Örneğin, 'data_{SPAN}-*.tfrecord', 'data_12-a.tfrecord', 'data_12-b.tfrecord' gibi dosyaları toplayacaktır.
- İsteğe bağlı olarak bu özellik, eşlendiğinde tamsayıların genişliği ile belirtilebilir. Örneğin, 'data_{SPAN:2}.file', 'data_02.file' ve 'data_27.file' gibi dosyalarla eşleşir (sırasıyla Span-2 ve Span-27 için girişler olarak), ancak 'data_1.dll' ile eşlenmez. file' veya 'data_123.file'.
- SPAN spesifikasyonu eksik olduğunda, her zaman Span '0' olduğu varsayılır.
- SPAN belirtilirse işlem hattı en son yayılma alanını işleyecek ve yayılma numarasını meta verilerde depolayacaktır.
Örneğin, giriş verilerinin olduğunu varsayalım:
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
ve giriş yapılandırması aşağıda gösterilmiştir:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
boru hattını tetiklerken şunları işleyecektir:
- '/tmp/span-2/train/data' tren bölünmesi olarak
- '/tmp/span-2/eval/data' değerlendirme bölünmesi olarak
açıklık numarası '2' olarak. Daha sonra '/tmp/span-3/...' hazırsa, boru hattını tekrar tetiklemeniz yeterlidir; işlenmek üzere '3' aralığını alır. Aşağıda yayılma spesifikasyonunun kullanımına ilişkin kod örneği gösterilmektedir:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Belirli bir aralığın alınması, aşağıda ayrıntıları verilen RangeConfig ile yapılabilir.
Tarih
Veri kaynağınız dosya sisteminde tarihe göre düzenlenmişse TFX, tarihlerin doğrudan aralık numaralarıyla eşlenmesini destekler. Tarihlerden aralıklara eşlemeyi temsil eden üç özellik vardır: {YYYY}, {MM} ve {DD}:
- Herhangi biri belirtilmişse, giriş glob modelinde üç spesifikasyonun bir arada mevcut olması gerekir:
- {SPAN} spesifikasyonu veya bu tarih spesifikasyonları grubu özel olarak belirtilebilir.
- YYYY'den yılı, MM'den ayı ve GG'den ayın gününü içeren bir takvim tarihi hesaplanır, daha sonra aralık numarası, unix döneminden (yani 1970-01-01) bu yana geçen gün sayısı olarak hesaplanır. Örneğin, 'log-{YYYY}{MM}{DD}.data', 'log-19700101.data' dosyasıyla eşleşir ve bunu Span-0 için girdi olarak, 'log-20170101.data' ise girdi olarak kullanır. Açıklık-17167.
- Bu tarih belirtimi kümesi belirtilirse, ardışık düzen en son tarihi işleyecek ve karşılık gelen yayılma numarasını meta verilerde depolayacaktır.
Örneğin, takvim tarihine göre düzenlenmiş giriş verilerinin olduğunu varsayalım:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
ve giriş yapılandırması aşağıdaki gibi gösterilir:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
boru hattını tetiklerken şunları işleyecektir:
- '/tmp/1970-01-03/train/data' tren bölünmesi olarak
- '/tmp/1970-01-03/eval/data' değerlendirme bölünmesi olarak
açıklık numarası '2' olarak. Daha sonra '/tmp/1970-01-04/...' hazırsa, boru hattını tekrar tetiklemeniz yeterlidir; işlenmek üzere '3' aralığını alır. Aşağıda tarih spesifikasyonunun kullanımına ilişkin kod örneği gösterilmektedir:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Sürüm
Sürüm, giriş glob modelinde '{VERSION}' spesifikasyonu kullanılarak alınabilir:
- Bu özellik, rakamları eşleştirir ve verileri SPAN altındaki ilgili SÜRÜM numaralarıyla eşleştirir. Sürüm spesifikasyonunun Span veya Date spesifikasyonuyla birlikte kullanılabileceğini unutmayın.
- Bu spesifikasyon aynı zamanda SPAN spesifikasyonuyla aynı şekilde genişlikle birlikte isteğe bağlı olarak belirtilebilir. örneğin 'span-{SPAN}/version-{VERSION:4}/data-*'.
- VERSION spesifikasyonu eksik olduğunda sürüm Yok olarak ayarlanır.
- Hem SPAN hem de VERSION belirtilirse ardışık düzen, en son yayılma alanı için en son sürümü işleyecek ve sürüm numarasını meta verilerde depolayacaktır.
- VERSION belirtilir ancak SPAN (veya tarih spesifikasyonu) belirtilmezse bir hata oluşturulur.
Örneğin, giriş verilerinin olduğunu varsayalım:
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
ve giriş yapılandırması aşağıdaki gibi gösterilir:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
boru hattını tetiklerken şunları işleyecektir:
- '/tmp/span-2/ver-2/train/data' tren bölünmesi olarak
- '/tmp/span-2/ver-2/eval/data' değerlendirme bölünmesi olarak
yayılma numarası '2' ve sürüm numarası '2'. Daha sonra '/tmp/span-2/ver-3/...' hazırsa, işlem hattını tekrar tetiklemeniz yeterlidir; işlenmek üzere '2' aralığını ve '3' sürümünü alacaktır. Aşağıda sürüm spesifikasyonunun kullanımına ilişkin kod örneği gösterilmektedir:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Aralık Yapılandırması
TFX, farklı TFX varlıkları için aralıkları tanımlamak için kullanılan soyut bir yapılandırma olan range config kullanılarak dosya tabanlı SampleGen'de belirli bir yayılma alanının alınmasını ve işlenmesini destekler. Belirli bir yayılma alanını almak için dosya tabanlı bir SampleGen bileşeninin range_config ayarlayın. Örneğin, giriş verilerinin olduğunu varsayalım:
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
'1' aralığına sahip verileri özel olarak almak ve işlemek için, giriş yapılandırmasına ek olarak bir aralık yapılandırması da belirleriz. SampleGen'in yalnızca tek açıklıklı statik aralıkları desteklediğini unutmayın (belirli ayrı aralıkların işlenmesini belirtmek için). Bu nedenle, StaticRange için start_span_number'ın end_span_number'a eşit olması gerekir. Sıfır doldurma için sağlanan yayılma alanını ve yayılma genişliği bilgisini (varsa) kullanarak, SampleGen, sağlanan bölünmüş desenlerdeki SPAN spesifikasyonunu istenen yayılma numarasıyla değiştirecektir. Aşağıda bir kullanım örneği gösterilmektedir:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Aralık yapılandırması, SPAN spesifikasyonu yerine tarih spesifikasyonu kullanılırsa belirli tarihleri işlemek için de kullanılabilir. Örneğin, takvim tarihine göre düzenlenmiş giriş verilerinin olduğunu varsayalım:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
2 Ocak 1970 tarihli verileri özel olarak almak ve işlemek için aşağıdakileri yapıyoruz:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Özel ÖrnekGen
Şu anda mevcut olan SampleGen bileşenleri ihtiyaçlarınızı karşılamıyorsa, farklı veri kaynaklarından veya farklı veri formatlarında okuma yapmanızı sağlayacak özel bir SampleGen oluşturabilirsiniz.
Dosya Tabanlı SampleGen Özelleştirmesi (Deneysel)
Öncelikle BaseExampleGenExecutor'u, eğitim/değerlendirme giriş bölmenizden TF örneklerine dönüştürme sağlayan özel bir Beam PTransform ile genişletin. Örneğin, CsvExampleGen yürütücüsü, giriş CSV bölümünden TF örneklerine dönüştürme sağlar.
Ardından, CsvExampleGen bileşeninde yapıldığı gibi yukarıdaki yürütücüyle bir bileşen oluşturun. Alternatif olarak, aşağıda gösterildiği gibi standart exampleGen bileşenine özel bir yürütücü aktarın.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Artık Avro ve Parquet dosyalarının bu yöntemle okunmasını da destekliyoruz.
Ek Veri Formatları
Apache Beam bir dizi ek veri formatının okunmasını destekler. Işın G/Ç Dönüşümleri aracılığıyla. Avro örneğine benzer bir desen kullanarak Işın G/Ç Dönüşümlerinden yararlanarak özel ÖrnekGen bileşenleri oluşturabilirsiniz.
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
Bu yazının yazıldığı an itibarıyla Beam Python SDK için şu anda desteklenen formatlar ve veri kaynakları şunları içermektedir:
- Amazon S3
- Apaçi Avro
- Apache Hadoop
- Apaçi Kafka
- Apaçi Parke
- Google Cloud BigQuery
- Google Bulut Büyük Tablo
- Google Bulut Veri Deposu
- Google Cloud Pub/Sub
- Google Bulut Depolama (GCS)
- MongoDB
En son liste için Beam belgelerine bakın.
Sorgu Tabanlı SampleGen Özelleştirmesi (Deneysel)
Öncelikle BaseExampleGenExecutor'u harici veri kaynağından okuyan özel bir Beam PTransform ile genişletin. Ardından QueryBasedExampleGen'i genişleterek basit bir bileşen oluşturun.
Bu, ek bağlantı yapılandırmaları gerektirebilir veya gerektirmeyebilir. Örneğin BigQuery yürütücüsü , bağlantı yapılandırma ayrıntılarını soyutlayan varsayılan bir ışın.io bağlayıcısını kullanarak okur. Presto yürütücüsü , giriş olarak özel bir Beam PTransform ve özel bir bağlantı yapılandırma protobuf'u gerektirir.
Özel bir SampleGen bileşeni için bağlantı yapılandırması gerekiyorsa, yeni bir protobuf oluşturun ve bunu artık isteğe bağlı bir yürütme parametresi olan özel_config aracılığıyla iletin. Aşağıda yapılandırılmış bir bileşenin nasıl kullanılacağına ilişkin bir örnek verilmiştir.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
ÖrnekGen Aşağı Akış Bileşenleri
Aşağı akış bileşenleri için özel bölünmüş yapılandırma desteklenir.
İstatistikGen
Varsayılan davranış, tüm bölümler için istatistik oluşturma işlemi gerçekleştirmektir.
Herhangi bir bölmeyi hariç tutmak için, İstatistikGen bileşenine yönelik exclude_splits ayarlayın. Örneğin:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
ŞemaGen
Varsayılan davranış, tüm bölmelere dayalı bir şema oluşturmaktır.
Herhangi bir bölmeyi hariç tutmak için SchemaGen bileşenine yönelik exclude_splits ayarlayın. Örneğin:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
Örnek Doğrulayıcı
Varsayılan davranış, giriş örneklerindeki tüm bölmelerin istatistiklerini bir şemaya göre doğrulamaktır.
Herhangi bir bölmeyi hariç tutmak için, exampleValidator bileşenine yönelik exclude_splits ayarlayın. Örneğin:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Dönüştür
Varsayılan davranış, 'eğitim' bölümünden meta verileri analiz etmek ve üretmek ve tüm bölünmeleri dönüştürmektir.
Bölmeleri analiz etmeyi ve bölmeleri dönüştürmeyi belirtmek için Transform bileşeni için splits_config öğesini ayarlayın. Örneğin:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Eğitmen ve Ayarlayıcı
Varsayılan davranış, 'eğitim' bölümünde eğitim ve 'değerlendirme' bölümünde değerlendirme şeklindedir.
Tren bölmelerini belirtmek ve bölmeleri değerlendirmek için Trainer bileşeni için train_args ve eval_args ayarlayın. Örneğin:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Değerlendirici
Varsayılan davranış, 'değerlendirme' bölmesinde hesaplanan ölçümleri sağlamaktır.
Özel bölmelere ilişkin değerlendirme istatistiklerini hesaplamak için, Evaluator bileşeni için example_splits ayarlayın. Örneğin:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Daha fazla ayrıntıyı CsvExampleGen API referansında , FileBasedExampleGen API uygulamasında ve ImportExampleGen API referansında bulabilirsiniz.