
يوضح لك هذا البرنامج التعليمي كيفية استخدام TensorFlow Transform (مكتبة tf.Transform ) لتنفيذ المعالجة المسبقة للبيانات للتعلم الآلي (ML). تتيح لك مكتبة tf.Transform الخاصة بـ TensorFlow تحديد تحويلات البيانات على مستوى المثيل والتمرير الكامل من خلال خطوط أنابيب المعالجة المسبقة للبيانات. يتم تنفيذ خطوط الأنابيب هذه بكفاءة باستخدام Apache Beam وتقوم بإنشاء رسم بياني TensorFlow كمنتجات ثانوية لتطبيق نفس التحويلات أثناء التنبؤ كما هو الحال عند تقديم النموذج.
يقدم هذا البرنامج التعليمي مثالاً شاملاً باستخدام Dataflow كمشغل لـ Apache Beam. من المفترض أنك على دراية بـ BigQuery و Dataflow و Vertex AI و TensorFlow Keras API. ويفترض أيضًا أن لديك بعض الخبرة في استخدام Jupyter Notebooks، مثل Vertex AI Workbench .
يفترض هذا البرنامج التعليمي أيضًا أنك على دراية بمفاهيم أنواع المعالجة المسبقة والتحديات والخيارات على Google Cloud، كما هو موضح في المعالجة المسبقة للبيانات لتعلم الآلة: الخيارات والتوصيات .
أهداف
- قم بتنفيذ خط أنابيب Apache Beam باستخدام مكتبة
tf.Transform. - قم بتشغيل خط الأنابيب في Dataflow.
- قم بتنفيذ نموذج TensorFlow باستخدام مكتبة
tf.Transform. - تدريب واستخدام النموذج للتنبؤات.
التكاليف
يستخدم هذا البرنامج التعليمي المكونات التالية القابلة للفوترة في Google Cloud:
لتقدير تكلفة تشغيل هذا البرنامج التعليمي، بافتراض أنك تستخدم كل الموارد ليوم كامل، استخدم حاسبة التسعير المكونة مسبقًا.
قبل أن تبدأ
في وحدة تحكم Google Cloud، في صفحة محدد المشروع، حدد أو أنشئ مشروع Google Cloud .
تأكد من تمكين الفوترة لمشروعك السحابي. تعرف على كيفية التحقق من تمكين الفوترة في المشروع .
تمكين واجهات برمجة تطبيقات Dataflow وVertex AI وNotebooks. تمكين واجهات برمجة التطبيقات
دفاتر Jupyter لهذا الحل
تعرض دفاتر ملاحظات Jupyter التالية مثال التنفيذ:
- يغطي الكمبيوتر المحمول 1 المعالجة المسبقة للبيانات. تتوفر التفاصيل في قسم تنفيذ خط أنابيب Apache Beam لاحقًا.
- يغطي دفتر الملاحظات 2 التدريب النموذجي. يتم توفير التفاصيل في قسم تنفيذ نموذج TensorFlow لاحقًا.
في الأقسام التالية، يمكنك استنساخ دفاتر الملاحظات هذه، ثم تنفيذ دفاتر الملاحظات للتعرف على كيفية عمل مثال التنفيذ.
قم بتشغيل مثيل دفاتر الملاحظات التي يديرها المستخدم
في وحدة تحكم Google Cloud، انتقل إلى صفحة Vertex AI Workbench .
في علامة التبويب دفاتر الملاحظات التي يديرها المستخدم ، انقر فوق +دفتر ملاحظات جديد .
حدد TensorFlow Enterprise 2.8 (مع LTS) بدون وحدات معالجة الرسومات لنوع المثيل.
انقر فوق إنشاء .
بعد إنشاء دفتر الملاحظات، انتظر حتى ينتهي وكيل JupyterLab من التهيئة. عندما يصبح جاهزًا، يتم عرض Open JupyterLab بجوار اسم دفتر الملاحظات.
استنساخ دفتر الملاحظات
في علامة التبويب دفاتر الملاحظات التي يديرها المستخدم ، بجوار اسم دفتر الملاحظات، انقر فوق فتح JupyterLab . يتم فتح واجهة JupyterLab في علامة تبويب جديدة.
إذا عرض JupyterLab مربع حوار "الإنشاء الموصى به" ، فانقر فوق "إلغاء الأمر" لرفض البناء المقترح.
في علامة التبويب Launcher ، انقر فوق Terminal .
في النافذة الطرفية، قم باستنساخ دفتر الملاحظات:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
تنفيذ خط أنابيب Apache Beam
يوفر هذا القسم والقسم التالي تشغيل المسار في Dataflow نظرة عامة وسياقًا لدفتر الملاحظات 1. ويقدم دفتر الملاحظات مثالًا عمليًا لوصف كيفية استخدام مكتبة tf.Transform لمعالجة البيانات مسبقًا. يستخدم هذا المثال مجموعة بيانات Natality، والتي تُستخدم للتنبؤ بأوزان الأطفال بناءً على مدخلات مختلفة. يتم تخزين البيانات في جدول الولادة العام في BigQuery.
تشغيل دفتر الملاحظات 1
في واجهة JupyterLab، انقر فوق ملف > فتح من المسار ، ثم أدخل المسار التالي:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbانقر فوق تحرير > مسح كافة المخرجات .
في قسم تثبيت الحزم المطلوبة ، قم بتنفيذ الخلية الأولى لتشغيل الأمر
pip install apache-beam.الجزء الأخير من الإخراج هو ما يلي:
Successfully installed ...يمكنك تجاهل أخطاء التبعية في الإخراج. لا تحتاج إلى إعادة تشغيل النواة بعد.
قم بتنفيذ الخلية الثانية لتشغيل الأمر
pip install tensorflow-transform. الجزء الأخير من الإخراج هو ما يلي:Successfully installed ... Note: you may need to restart the kernel to use updated packages.يمكنك تجاهل أخطاء التبعية في الإخراج.
انقر فوق Kernel > إعادة تشغيل Kernel .
قم بتنفيذ الخلايا الموجودة في قسمي تأكيد الحزم المثبتة وإنشاء setup.py لتثبيت الحزم على حاويات Dataflow .
في قسم تعيين العلامات العامة ، بجوار
PROJECTوBUCKET، استبدلyour-projectبمعرف مشروع Cloud الخاص بك، ثم قم بتنفيذ الخلية.قم بتنفيذ كافة الخلايا المتبقية حتى الخلية الأخيرة في دفتر الملاحظات. للحصول على معلومات حول ما يجب فعله في كل خلية، راجع الإرشادات الموجودة في دفتر الملاحظات.
نظرة عامة على خط الأنابيب
في مثال دفتر الملاحظات، يقوم Dataflow بتشغيل مسار tf.Transform على نطاق واسع لإعداد البيانات وإنتاج عناصر التحويل. تصف الأقسام اللاحقة في هذا المستند الوظائف التي تنفذ كل خطوة في المسار. الخطوات العامة لخط الأنابيب هي كما يلي:
- قراءة بيانات التدريب من BigQuery.
- تحليل وتحويل بيانات التدريب باستخدام مكتبة
tf.Transform. - اكتب بيانات التدريب المحولة إلى Cloud Storage بتنسيق TFRecord .
- قراءة بيانات التقييم من BigQuery.
- تحويل بيانات التقييم باستخدام الرسم البياني
transform_fnالناتج عن الخطوة 2. - اكتب بيانات التدريب المحولة إلى Cloud Storage بتنسيق TFRecord.
- اكتب عناصر التحويل إلى Cloud Storage والتي سيتم استخدامها لاحقًا لإنشاء النموذج وتصديره.
يوضح المثال التالي رمز Python لخط الأنابيب الشامل. توفر الأقسام التالية توضيحات وقوائم التعليمات البرمجية لكل خطوة.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
اقرأ بيانات التدريب الأولية من BigQuery
الخطوة الأولى هي قراءة بيانات التدريب الأولية من BigQuery باستخدام وظيفة read_from_bq . تقوم هذه الدالة بإرجاع كائن raw_dataset المستخرج من BigQuery. يمكنك تمرير قيمة data_size وتمرير قيمة step train أو eval . يتم إنشاء استعلام مصدر BigQuery باستخدام الدالة get_source_query ، كما هو موضح في المثال التالي:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
قبل إجراء المعالجة المسبقة tf.Transform ، قد تحتاج إلى إجراء معالجة نموذجية تعتمد على Apache Beam، بما في ذلك معالجة الخريطة والتصفية والتجميع والنوافذ. في المثال، تقوم التعليمات البرمجية بتنظيف السجلات المقروءة من BigQuery باستخدام طريقة beam.Map(prep_bq_row) ، حيث تكون prep_bq_row وظيفة مخصصة. تقوم هذه الوظيفة المخصصة بتحويل الكود الرقمي لميزة فئوية إلى تسميات يمكن للإنسان قراءتها.
بالإضافة إلى ذلك، لاستخدام مكتبة tf.Transform لتحليل وتحويل كائن raw_data المستخرج من BigQuery، تحتاج إلى إنشاء كائن raw_dataset ، وهو عبارة عن مجموعة من كائنات raw_data raw_metadata . يتم إنشاء كائن raw_metadata باستخدام وظيفة create_raw_metadata ، كما يلي:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
عند تنفيذ الخلية في دفتر الملاحظات التي تتبع مباشرة الخلية التي تحدد هذا الأسلوب، يتم عرض محتوى كائن raw_metadata.schema . ويتضمن الأعمدة التالية:
-
gestation_weeks(النوع:FLOAT) -
is_male(النوع:BYTES) -
mother_age(النوع:FLOAT) -
mother_race(النوع:BYTES) -
plurality(النوع:FLOAT) -
weight_pounds(النوع:FLOAT)
تحويل بيانات التدريب الخام
تخيل أنك تريد تطبيق تحويلات المعالجة المسبقة النموذجية على الميزات الأولية المدخلة لبيانات التدريب من أجل إعدادها لتعلم الآلة. تتضمن هذه التحويلات عمليات التمرير الكامل وعمليات مستوى المثيل، كما هو موضح في الجدول التالي:
| ميزة الإدخال | تحويل | الإحصائيات اللازمة | يكتب | ميزة الإخراج |
|---|---|---|---|---|
weight_pound | لا أحد | لا أحد | غير متوفر | weight_pound |
mother_age | تطبيع | يعني فار | تمريرة كاملة | mother_age_normalized |
mother_age | حجم دلو متساوي | quantiles | تمريرة كاملة | mother_age_bucketized |
mother_age | حساب السجل | لا أحد | على مستوى المثيل | mother_age_log |
plurality | وضح ما إذا كان أطفالًا منفردين أم متعددين | لا أحد | على مستوى المثيل | is_multiple |
is_multiple | تحويل القيم الاسمية إلى مؤشر رقمي | vocab | تمريرة كاملة | is_multiple_index |
gestation_weeks | مقياس بين 0 و 1 | دقيقة، كحد أقصى | تمريرة كاملة | gestation_weeks_scaled |
mother_race | تحويل القيم الاسمية إلى مؤشر رقمي | vocab | تمريرة كاملة | mother_race_index |
is_male | تحويل القيم الاسمية إلى مؤشر رقمي | vocab | تمريرة كاملة | is_male_index |
يتم تنفيذ هذه التحويلات في دالة preprocess_fn ، التي تتوقع قاموسًا للموترات ( input_features ) وتقوم بإرجاع قاموس الميزات المعالجة ( output_features ).
يوضح التعليمة البرمجية التالية تنفيذ وظيفة preprocess_fn ، باستخدام tf.Transform واجهات برمجة التطبيقات للتحويل الكامل (مسبوقة بـ tft. ) وعمليات TensorFlow (مسبوقة بـ tf. ) على مستوى المثيل:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
يحتوي إطار عمل tf.Transform على العديد من التحويلات الأخرى بالإضافة إلى تلك الموجودة في المثال السابق، بما في ذلك تلك المدرجة في الجدول التالي:
| تحويل | ينطبق على | وصف |
|---|---|---|
scale_by_min_max | الميزات الرقمية | يقيس عمودًا رقميًا في النطاق [ output_min ، output_max ] |
scale_to_0_1 | الميزات الرقمية | إرجاع عمود وهو عمود الإدخال الذي تم تغيير حجمه ليكون له نطاق [ 0 , 1 ] |
scale_to_z_score | الميزات الرقمية | إرجاع عمود قياسي بمتوسط 0 وتباين 1 |
tfidf | ميزات النص | يقوم بتعيين المصطلحات الموجودة في x إلى تكرار المصطلح الخاص بها * تكرار المستند العكسي |
compute_and_apply_vocabulary | الميزات الفئوية | ينشئ مفردات لميزة فئوية ويعينها لعدد صحيح مع هذه المفردة |
ngrams | ميزات النص | ينشئ SparseTensor من n-grams |
hash_strings | الميزات الفئوية | سلاسل التجزئة في الدلاء |
pca | الميزات الرقمية | يحسب PCA في مجموعة البيانات باستخدام التباين المتحيز |
bucketize | الميزات الرقمية | تُرجع عمودًا متساويًا الحجم (معتمدًا على الكميات)، مع فهرس دلو مخصص لكل إدخال |
من أجل تطبيق التحويلات التي تم تنفيذها في وظيفة preprocess_fn على كائن raw_train_dataset الذي تم إنتاجه في الخطوة السابقة من المسار، يمكنك استخدام الأسلوب AnalyzeAndTransformDataset . تتوقع هذه الطريقة كائن raw_dataset كمدخل، وتطبق وظيفة preprocess_fn ، وتنتج كائن transformed_dataset والرسم البياني transform_fn . الكود التالي يوضح هذه المعالجة:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
يتم تطبيق التحويلات على البيانات الأولية على مرحلتين: مرحلة التحليل ومرحلة التحويل. يوضح الشكل 3 لاحقًا في هذا المستند كيفية تقسيم أسلوب AnalyzeAndTransformDataset إلى أسلوب AnalyzeDataset وأسلوب TransformDataset .
مرحلة التحليل
في مرحلة التحليل، يتم تحليل بيانات التدريب الأولية في عملية تمرير كاملة لحساب الإحصائيات اللازمة للتحويلات. يتضمن ذلك حساب المتوسط والتباين والحد الأدنى والحد الأقصى والكميات والمفردات. تتوقع عملية التحليل مجموعة بيانات أولية (بيانات أولية بالإضافة إلى بيانات التعريف الأولية)، وتنتج مخرجين:
-
transform_fn: رسم بياني TensorFlow يحتوي على الإحصائيات المحسوبة من مرحلة التحليل ومنطق التحويل (الذي يستخدم الإحصائيات) كعمليات على مستوى المثيل. كما تمت مناقشته لاحقًا في حفظ الرسم البياني ، يتم حفظ الرسم البيانيtransform_fnليتم إرفاقه بوظيفة نموذجserving_fn. وهذا يجعل من الممكن تطبيق نفس التحويل على نقاط بيانات التنبؤ عبر الإنترنت. -
transform_metadata: كائن يصف المخطط المتوقع للبيانات بعد التحويل.
يتم توضيح مرحلة التحليل في الرسم البياني التالي، الشكل 1:

tf.Transform . تشتمل محللات tf.Transform على min max sum size mean var covariance quantiles vocabulary و pca .
مرحلة التحويل
في مرحلة التحويل، يتم استخدام الرسم البياني transform_fn الذي يتم إنتاجه بواسطة مرحلة التحليل لتحويل بيانات التدريب الأولية في عملية على مستوى المثيل من أجل إنتاج بيانات التدريب المحولة. يتم إقران بيانات التدريب المحولة مع البيانات الوصفية المحولة (التي تنتجها مرحلة التحليل) لإنتاج مجموعة بيانات transformed_train_dataset .
يتم توضيح مرحلة التحويل في الرسم البياني التالي، الشكل 2:

tf.Transform . للمعالجة المسبقة للميزات، يمكنك استدعاء تحويلات tensorflow_transform المطلوبة (المستوردة كـ tft في الكود) في تنفيذ وظيفة preprocess_fn . على سبيل المثال، عند استدعاء عمليات tft.scale_to_z_score ، تقوم مكتبة tf.Transform بترجمة استدعاء الدالة هذا إلى محللات المتوسط والتباين، وتحسب الإحصائيات في مرحلة التحليل، ثم تطبق هذه الإحصائيات لتطبيع الميزة الرقمية في مرحلة التحويل. ويتم كل ذلك تلقائيًا عن طريق استدعاء الأسلوب AnalyzeAndTransformDataset(preprocess_fn) .
يتضمن كيان transformed_metadata.schema الناتج عن هذا الاستدعاء الأعمدة التالية:
-
gestation_weeks_scaled(النوع:FLOAT) -
is_male_index(النوع:INT، is_categorical:True) -
is_multiple_index(النوع:INT، is_categorical:True) -
mother_age_bucketized(النوع:INT، is_categorical:True) -
mother_age_log(النوع:FLOAT) -
mother_age_normalized(النوع:FLOAT) -
mother_race_index(النوع:INT، is_categorical:True) -
weight_pounds(النوع:FLOAT)
كما هو موضح في عمليات المعالجة المسبقة في الجزء الأول من هذه السلسلة، يقوم تحويل المعالم بتحويل الميزات الفئوية إلى تمثيل رقمي. بعد التحويل، يتم تمثيل الميزات الفئوية بقيم عددية. في كيان transformed_metadata.schema ، تشير العلامة is_categorical لأعمدة النوع INT إلى ما إذا كان العمود يمثل ميزة فئوية أو ميزة رقمية حقيقية.
كتابة بيانات التدريب المحولة
بعد معالجة بيانات التدريب مسبقًا باستخدام وظيفة preprocess_fn من خلال مرحلتي التحليل والتحويل، يمكنك كتابة البيانات إلى حوض لاستخدامها في تدريب نموذج TensorFlow. عند تنفيذ خط أنابيب Apache Beam باستخدام Dataflow، يكون الحوض هو Cloud Storage. وبخلاف ذلك، فإن الحوض هو القرص المحلي. على الرغم من أنه يمكنك كتابة البيانات كملف CSV من الملفات المنسقة ذات العرض الثابت، فإن تنسيق الملف الموصى به لمجموعات بيانات TensorFlow هو تنسيق TFRecord. هذا هو تنسيق ثنائي بسيط موجه نحو التسجيل ويتكون من رسائل المخزن المؤقت للبروتوكول tf.train.Example .
يحتوي كل سجل tf.train.Example على ميزة واحدة أو أكثر. يتم تحويلها إلى موترات عندما يتم تغذيتها إلى النموذج للتدريب. يكتب التعليمة البرمجية التالية مجموعة البيانات المحولة إلى ملفات TFRecord في الموقع المحدد:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
قراءة وتحويل وكتابة بيانات التقييم
بعد تحويل بيانات التدريب وإنتاج الرسم البياني transform_fn ، يمكنك استخدامه لتحويل بيانات التقييم. أولاً، عليك قراءة بيانات التقييم من BigQuery وتنظيفها باستخدام الدالة read_from_bq الموضحة سابقًا في قراءة بيانات التدريب الأولية من BigQuery ، وتمرير قيمة eval لمعلمة step . بعد ذلك، يمكنك استخدام التعليمة البرمجية التالية لتحويل مجموعة بيانات التقييم الأولية ( raw_dataset ) إلى التنسيق المحول المتوقع ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
عندما تقوم بتحويل بيانات التقييم، يتم تطبيق العمليات على مستوى المثيل فقط، وذلك باستخدام كل من المنطق في الرسم البياني transform_fn والإحصائيات المحسوبة من مرحلة التحليل في بيانات التدريب. بمعنى آخر، لا يمكنك تحليل بيانات التقييم بطريقة النجاح الكامل لحساب الإحصائيات الجديدة، مثل المتوسط والتباين لتطبيع درجة z للميزات الرقمية في بيانات التقييم. بدلاً من ذلك، يمكنك استخدام الإحصائيات المحسوبة من بيانات التدريب لتحويل بيانات التقييم بطريقة على مستوى المثيل.
لذلك، يمكنك استخدام الأسلوب AnalyzeAndTransform في سياق بيانات التدريب لحساب الإحصائيات وتحويل البيانات. وفي الوقت نفسه، يمكنك استخدام أسلوب TransformDataset في سياق تحويل بيانات التقييم لتحويل البيانات فقط باستخدام الإحصائيات المحسوبة على بيانات التدريب.
تقوم بعد ذلك بكتابة البيانات إلى مخزن (التخزين السحابي أو القرص المحلي، اعتمادًا على المشغل) بتنسيق TFRecord لتقييم نموذج TensorFlow أثناء عملية التدريب. للقيام بذلك، يمكنك استخدام وظيفة write_tfrecords التي تمت مناقشتها في كتابة بيانات التدريب المحولة . يوضح الرسم البياني التالي، الشكل 3، كيفية استخدام الرسم البياني transform_fn الذي تم إنتاجه في مرحلة التحليل لبيانات التدريب لتحويل بيانات التقييم.

transform_fn .احفظ الرسم البياني
تتمثل الخطوة الأخيرة في مسار المعالجة المسبقة tf.Transform في تخزين العناصر، والتي تتضمن الرسم البياني transform_fn الذي تنتجه مرحلة التحليل على بيانات التدريب. يظهر رمز تخزين القطع الأثرية في وظيفة write_transform_artefacts التالية:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
سيتم استخدام هذه القطع الأثرية لاحقًا للتدريب على النماذج وتصديرها للعرض. ويتم أيضًا إنتاج المصنوعات اليدوية التالية، كما هو موضح في القسم التالي:
-
saved_model.pb: يمثل الرسم البياني TensorFlow الذي يتضمن منطق التحويل (الرسم البيانيtransform_fn)، والذي سيتم إرفاقه بواجهة عرض النموذج لتحويل نقاط البيانات الأولية إلى التنسيق المحول. -
variables: تتضمن الإحصائيات المحسوبة أثناء مرحلة تحليل بيانات التدريب، ويتم استخدامها في منطق التحويل في قطعة أثريةsaved_model.pb. -
assets: تتضمن ملفات المفردات، واحد لكل ميزة فئوية تتم معالجتها باستخدام طريقةcompute_and_apply_vocabulary، لاستخدامها أثناء التقديم لتحويل قيمة اسمية أولية مدخلة إلى فهرس رقمي. -
transformed_metadata: دليل يحتوي على ملفschema.jsonالذي يصف مخطط البيانات المحولة.
قم بتشغيل خط الأنابيب في Dataflow
بعد تحديد خط أنابيب tf.Transform ، يمكنك تشغيل خط الأنابيب باستخدام Dataflow. يُظهر الرسم التخطيطي التالي، الشكل 4، الرسم البياني لتنفيذ تدفق البيانات لخط الأنابيب tf.Transform الموضح في المثال.
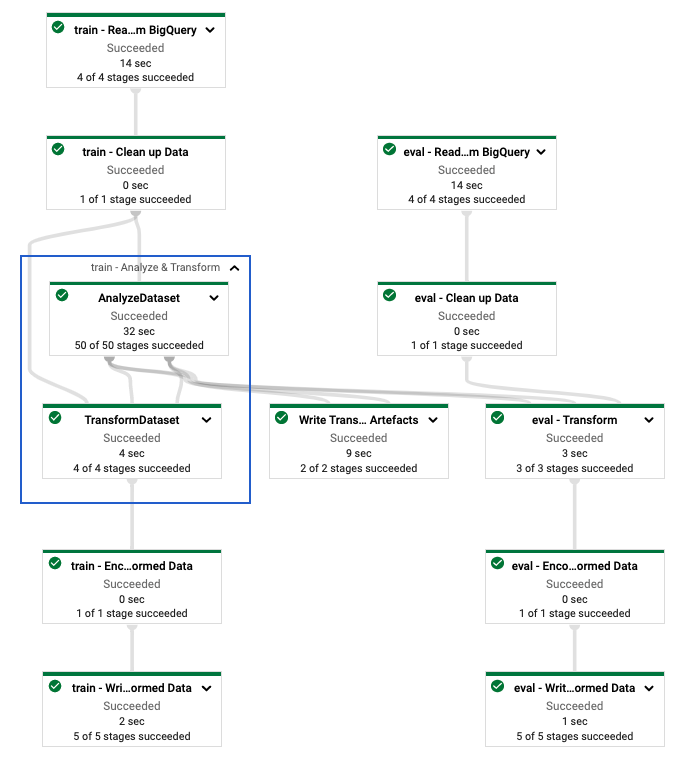
tf.Transform . بعد تنفيذ مسار Dataflow للمعالجة المسبقة لبيانات التدريب والتقييم، يمكنك استكشاف الكائنات المنتجة في Cloud Storage عن طريق تنفيذ الخلية الأخيرة في دفتر الملاحظات. تعرض مقتطفات التعليمات البرمجية الموجودة في هذا القسم النتائج، حيث يكون YOUR_BUCKET_NAME هو اسم مجموعة التخزين السحابي الخاصة بك.
يتم تخزين بيانات التدريب والتقييم المحولة بتنسيق TFRecord في الموقع التالي:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
يتم إنتاج القطع الأثرية التحويلية في الموقع التالي:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
القائمة التالية هي مخرجات المسار، والتي تعرض كائنات البيانات المنتجة والتحف:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
تنفيذ نموذج TensorFlow
يوفر هذا القسم والقسم التالي، تدريب النموذج واستخدامه للتنبؤات ، نظرة عامة وسياقًا للمفكرة 2. يوفر المفكرة مثالاً لنموذج تعلم الآلة للتنبؤ بأوزان الأطفال. في هذا المثال، يتم تنفيذ نموذج TensorFlow باستخدام Keras API. يستخدم النموذج البيانات والعناصر التي يتم إنتاجها بواسطة tf.Transform تم شرح خط أنابيب المعالجة المسبقة للتحويل مسبقًا.
تشغيل دفتر الملاحظات 2
في واجهة JupyterLab، انقر فوق ملف > فتح من المسار ، ثم أدخل المسار التالي:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbانقر فوق تحرير > مسح كافة المخرجات .
في قسم تثبيت الحزم المطلوبة ، قم بتنفيذ الخلية الأولى لتشغيل الأمر
pip install tensorflow-transform.الجزء الأخير من الإخراج هو ما يلي:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.يمكنك تجاهل أخطاء التبعية في الإخراج.
في قائمة Kernel ، حدد Restart Kernel .
قم بتنفيذ الخلايا الموجودة في قسمي تأكيد الحزم المثبتة وإنشاء setup.py لتثبيت الحزم على حاويات Dataflow .
في قسم تعيين العلامات العامة ، بجوار
PROJECTوBUCKET، استبدلyour-projectبمعرف مشروع Cloud الخاص بك، ثم قم بتنفيذ الخلية.قم بتنفيذ كافة الخلايا المتبقية حتى الخلية الأخيرة في دفتر الملاحظات. للحصول على معلومات حول ما يجب فعله في كل خلية، راجع الإرشادات الموجودة في دفتر الملاحظات.
نظرة عامة على إنشاء النموذج
خطوات إنشاء النموذج هي كما يلي:
- قم بإنشاء أعمدة المعالم باستخدام معلومات المخطط المخزنة في دليل
transformed_metadata. - قم بإنشاء النموذج الواسع والعميق باستخدام Keras API باستخدام أعمدة الميزات كمدخل للنموذج.
- قم بإنشاء وظيفة
tfrecords_input_fnلقراءة وتحليل بيانات التدريب والتقييم باستخدام عناصر التحويل. - تدريب وتقييم النموذج.
- قم بتصدير النموذج الذي تم تدريبه عن طريق تحديد دالة
serving_fnالتي تحتوي على الرسم البيانيtransform_fnالمرفق بها. - افحص النموذج الذي تم تصديره باستخدام أداة
saved_model_cli. - استخدم النموذج المصدر للتنبؤ.
لا تشرح هذه الوثيقة كيفية بناء النموذج، لذا فهي لا تناقش بالتفصيل كيفية بناء النموذج أو تدريبه. ومع ذلك، توضح الأقسام التالية كيفية استخدام المعلومات المخزنة في دليل transform_metadata - الذي يتم إنتاجه بواسطة عملية tf.Transform - لإنشاء أعمدة الميزات الخاصة بالنموذج. يوضح المستند أيضًا كيفية استخدام الرسم البياني transform_fn - الذي يتم إنتاجه أيضًا بواسطة عملية tf.Transform - في وظيفة serving_fn عندما يتم تصدير النموذج للعرض.
استخدم عناصر التحويل التي تم إنشاؤها في التدريب النموذجي
عندما تقوم بتدريب نموذج TensorFlow، فإنك تستخدم كائنات train eval المحولة التي تم إنتاجها في خطوة معالجة البيانات السابقة. يتم تخزين هذه الكائنات كملفات مجزأة بتنسيق TFRecord. يمكن أن تكون معلومات المخطط الموجودة في دليل transformed_metadata المحولة التي تم إنشاؤها في الخطوة السابقة مفيدة في تحليل البيانات (كائنات tf.train.Example ) لإدخالها في النموذج للتدريب والتقييم.
تحليل البيانات
نظرًا لأنك تقرأ الملفات بتنسيق TFRecord لتغذية النموذج ببيانات التدريب والتقييم، فأنت بحاجة إلى تحليل كل كائن tf.train.Example في الملفات لإنشاء قاموس الميزات (الموترات). ويضمن ذلك تعيين الميزات إلى طبقة إدخال النموذج باستخدام أعمدة المعالم، والتي تعمل كواجهة للتدريب والتقييم للنموذج. لتحليل البيانات، يمكنك استخدام كائن TFTransformOutput الذي تم إنشاؤه من العناصر التي تم إنشاؤها في الخطوة السابقة:
قم بإنشاء كائن
TFTransformOutputمن العناصر التي تم إنشاؤها وحفظها في خطوة المعالجة المسبقة السابقة، كما هو موضح في قسم حفظ الرسم البياني :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)قم باستخراج كائن
feature_specمن كائنTFTransformOutput:tf_transform_output.transformed_feature_spec()استخدم كائن
feature_specلتحديد الميزات الموجودة في كائنtf.train.Exampleكما في وظيفةtfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
قم بإنشاء أعمدة الميزات
ينتج خط الأنابيب معلومات المخطط في دليل transformed_metadata الذي يصف مخطط البيانات المحولة التي يتوقعها النموذج للتدريب والتقييم. يحتوي المخطط على اسم الميزة ونوع البيانات، مثل ما يلي:
-
gestation_weeks_scaled(النوع:FLOAT) -
is_male_index(النوع:INT، is_categorical:True) -
is_multiple_index(النوع:INT، is_categorical:True) -
mother_age_bucketized(النوع:INT، is_categorical:True) -
mother_age_log(النوع:FLOAT) -
mother_age_normalized(النوع:FLOAT) -
mother_race_index(النوع:INT، is_categorical:True) -
weight_pounds(النوع:FLOAT)
لرؤية هذه المعلومات، استخدم الأوامر التالية:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
يوضح التعليمة البرمجية التالية كيفية استخدام اسم الميزة لإنشاء أعمدة الميزات:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
يقوم الكود بإنشاء عمود tf.feature_column.numeric_column للميزات الرقمية، وعمود tf.feature_column.categorical_column_with_identity للميزات الفئوية.
يمكنك أيضًا إنشاء أعمدة ميزات موسعة، كما هو موضح في الخيار C: TensorFlow في الجزء الأول من هذه السلسلة. في المثال المستخدم لهذه السلسلة، تم إنشاء ميزة جديدة، mother_race_X_mother_age_bucketized ، عن طريق تقاطع المعالم mother_race و mother_age_bucketized باستخدام عمود المعالم tf.feature_column.crossed_column . يتم إنشاء تمثيل منخفض الأبعاد وكثيف لهذه الميزة المتقاطعة باستخدام عمود المعالم tf.feature_column.embedding_column .
يوضح الرسم البياني التالي، الشكل 5، البيانات المحولة وكيفية استخدام البيانات التعريفية المحولة لتعريف نموذج TensorFlow وتدريبه:

تصدير النموذج لخدمة التنبؤ
بعد تدريب نموذج TensorFlow باستخدام Keras API، يمكنك تصدير النموذج المدرب ككائن SavedModel، بحيث يمكنه تقديم نقاط بيانات جديدة للتنبؤ. عندما تقوم بتصدير النموذج، يجب عليك تحديد واجهته - أي مخطط ميزات الإدخال المتوقع أثناء العرض. يتم تعريف مخطط ميزات الإدخال هذا في وظيفة serving_fn ، كما هو موضح في الكود التالي:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
أثناء التقديم، يتوقع النموذج نقاط البيانات في شكلها الأولي (أي المعالم الأولية قبل التحويلات). لذلك، تستقبل الدالة serving_fn الميزات الأولية وتخزنها في كائن features كقاموس Python. ومع ذلك، كما تمت مناقشته سابقًا، يتوقع النموذج المدرب نقاط البيانات في المخطط المحول. لتحويل الميزات الأولية إلى كائنات transformed_features المتوقعة بواسطة واجهة النموذج، يمكنك تطبيق الرسم البياني transform_fn المحفوظ على كائن features من خلال الخطوات التالية:
قم بإنشاء كائن
TFTransformOutputمن العناصر التي تم إنشاؤها وحفظها في خطوة المعالجة المسبقة السابقة:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)قم بإنشاء كائن
TransformFeaturesLayerمن كائنTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()قم بتطبيق الرسم البياني
transform_fnباستخدام كائنTransformFeaturesLayer:transformed_features = model.tft_layer(features)
يوضح الرسم البياني التالي، الشكل 6، الخطوة الأخيرة لتصدير نموذج للعرض:

transform_fn المرفق. تدريب واستخدام النموذج للتنبؤات
يمكنك تدريب النموذج محليًا عن طريق تنفيذ خلايا دفتر الملاحظات. للحصول على أمثلة حول كيفية حزم التعليمات البرمجية وتدريب النموذج الخاص بك على نطاق واسع باستخدام Vertex AI Training، راجع العينات والأدلة في مستودع GitHub لعينات Cloudml من Google.
عند فحص كائن SavedModel الذي تم تصديره باستخدام أداة saved_model_cli ، ترى أن عناصر inputs لتعريف signature_def تتضمن الميزات الأولية، كما هو موضح في المثال التالي:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
توضح لك الخلايا المتبقية من دفتر الملاحظات كيفية استخدام النموذج الذي تم تصديره للتنبؤ المحلي، وكيفية نشر النموذج كخدمة صغيرة باستخدام Vertex AI Prediction. من المهم التأكيد على أن نقطة بيانات الإدخال (العينة) موجودة في المخطط الأولي في كلتا الحالتين.
تنظيف
لتجنب تكبد رسوم إضافية على حساب Google Cloud الخاص بك مقابل الموارد المستخدمة في هذا البرنامج التعليمي، احذف المشروع الذي يحتوي على الموارد.
حذف المشروع
في وحدة تحكم Google Cloud، انتقل إلى صفحة إدارة الموارد .
في قائمة المشاريع، حدد المشروع الذي تريد حذفه، ثم انقر فوق حذف .
في مربع الحوار، اكتب معرف المشروع، ثم انقر فوق إيقاف التشغيل لحذف المشروع.
ما هو التالي
- للتعرف على المفاهيم والتحديات والخيارات المتعلقة بالمعالجة المسبقة للبيانات للتعلم الآلي على Google Cloud، راجع المقالة الأولى في هذه السلسلة، المعالجة المسبقة للبيانات لتعلم الآلة: الخيارات والتوصيات .
- للحصول على مزيد من المعلومات حول كيفية تنفيذ مسار tf.Transform وحزمه وتشغيله في Dataflow، راجع نموذج التنبؤ بالدخل باستخدام مجموعة بيانات التعداد .
- احصل على تخصص Coursera في تعلم الآلة باستخدام TensorFlow على Google Cloud .
- تعرف على أفضل الممارسات لهندسة تعلم الآلة في قواعد تعلم الآلة .
- لمزيد من البنى المرجعية والرسوم البيانية وأفضل الممارسات، استكشف Cloud Architecture Center .