
مقدمة
TFX عبارة عن منصة للتعلم الآلي (ML) على نطاق الإنتاج من Google تعتمد على TensorFlow. فهو يوفر إطار عمل للتكوين ومكتبات مشتركة لدمج المكونات المشتركة اللازمة لتحديد نظام التعلم الآلي الخاص بك وتشغيله ومراقبته.
تي اف اكس 1.0
يسعدنا أن نعلن عن توفر TFX 1.0.0 . هذا هو الإصدار التجريبي الأولي من TFX، والذي يوفر واجهات برمجة التطبيقات (APIs) العامة الثابتة والعناصر. يمكنك التأكد من أن خطوط أنابيب TFX المستقبلية الخاصة بك ستستمر في العمل بعد الترقية ضمن نطاق التوافق المحدد في RFC هذا.
تثبيت

![]()
pip install tfx
الحزم الليلية
تستضيف TFX أيضًا حزمًا ليلية على https://pypi-nightly.tensorflow.org على Google Cloud. لتثبيت أحدث حزمة ليلية، يرجى استخدام الأمر التالي:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
سيؤدي هذا إلى تثبيت الحزم الليلية لتبعيات TFX الرئيسية مثل تحليل نموذج TensorFlow (TFMA)، والتحقق من صحة بيانات TensorFlow (TFDV)، وتحويل TensorFlow (TFT)، والمكتبات المشتركة الأساسية TFX (TFX-BSL)، وبيانات تعريف ML (MLMD).
حول تي إف إكس
TFX عبارة عن منصة لبناء وإدارة سير عمل تعلم الآلة في بيئة الإنتاج. توفر TFX ما يلي:
مجموعة أدوات لبناء خطوط أنابيب ML. تتيح لك خطوط أنابيب TFX تنسيق سير عمل تعلم الآلة على العديد من الأنظمة الأساسية، مثل: Apache Airflow وApache Beam وKubeflow Pipelines.
مجموعة من المكونات القياسية التي يمكنك استخدامها كجزء من المسار، أو كجزء من البرنامج النصي للتدريب على تعلم الآلة. توفر مكونات TFX القياسية وظائف مثبتة لمساعدتك على البدء في إنشاء عملية تعلم الآلة بسهولة.
المكتبات التي توفر الوظائف الأساسية للعديد من المكونات القياسية. يمكنك استخدام مكتبات TFX لإضافة هذه الوظيفة إلى المكونات المخصصة الخاصة بك، أو استخدامها بشكل منفصل.
TFX عبارة عن مجموعة أدوات للتعلم الآلي على نطاق إنتاج Google تعتمد على TensorFlow. فهو يوفر إطار عمل للتكوين ومكتبات مشتركة لدمج المكونات المشتركة اللازمة لتحديد نظام التعلم الآلي الخاص بك وتشغيله ومراقبته.
مكونات TFX القياسية
خط أنابيب TFX عبارة عن سلسلة من المكونات التي تنفذ خط أنابيب ML والذي تم تصميمه خصيصًا لمهام التعلم الآلي القابلة للتطوير وعالية الأداء. يتضمن ذلك النمذجة والتدريب وخدمة الاستدلال وإدارة عمليات النشر لأهداف عبر الإنترنت والجوال الأصلي وJavaScript.
يتضمن خط أنابيب TFX عادةً المكونات التالية:
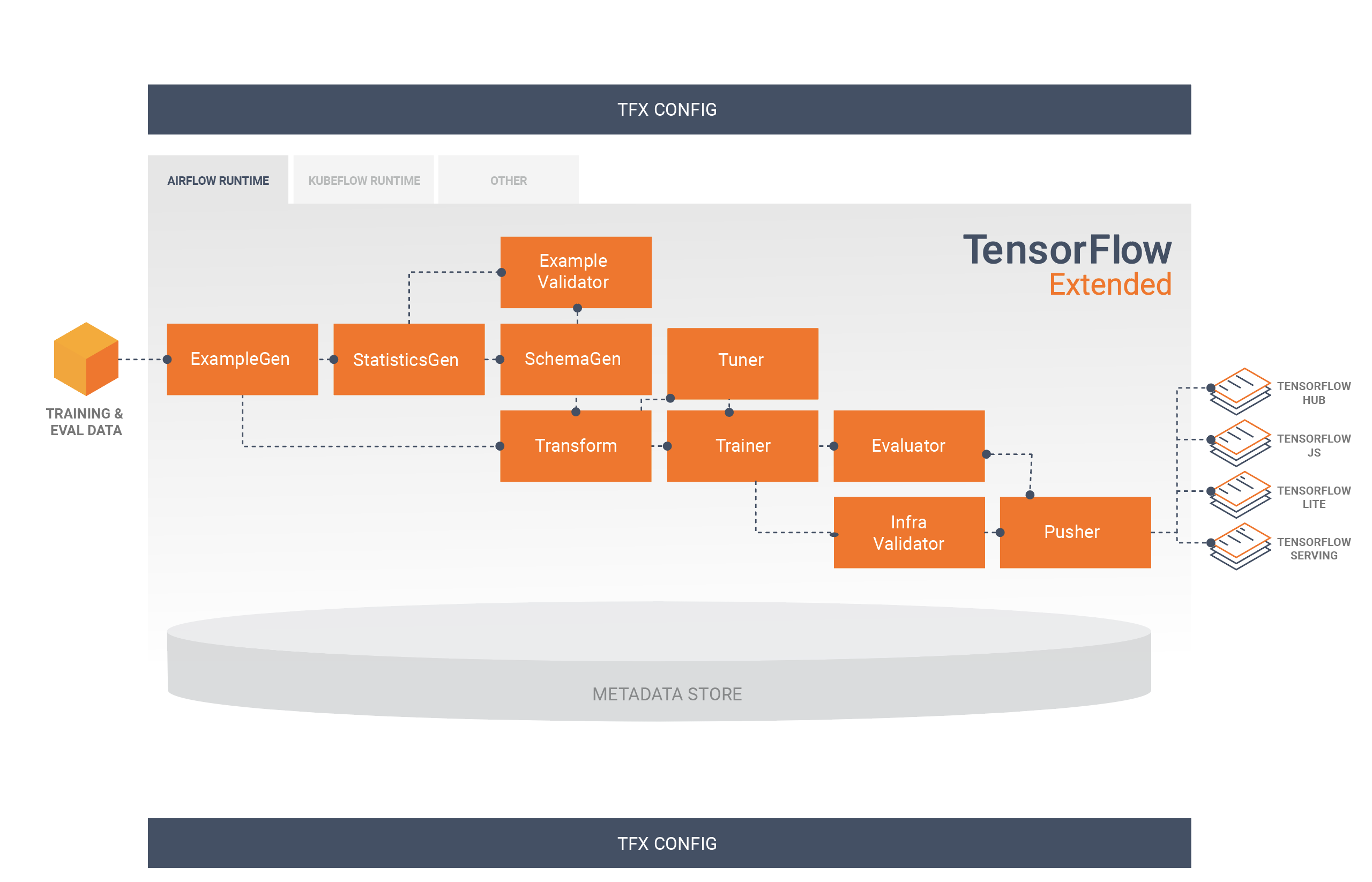
يعد exampleGen مكون الإدخال الأولي لخط الأنابيب الذي يستوعب مجموعة بيانات الإدخال ويقسمها اختياريًا.
تقوم StatisticsGen بحساب إحصائيات مجموعة البيانات.
يقوم SchemaGen بفحص الإحصائيات وإنشاء مخطط البيانات.
يبحث exampleValidator عن الحالات الشاذة والقيم المفقودة في مجموعة البيانات.
يقوم التحويل بإجراء هندسة الميزات على مجموعة البيانات.
يقوم المدرب بتدريب النموذج.
يقوم الموالف بضبط المعلمات الفائقة للنموذج.
يقوم المُقيم بإجراء تحليل عميق لنتائج التدريب ويساعدك على التحقق من صحة النماذج المصدرة، مما يضمن أنها "جيدة بما يكفي" ليتم دفعها إلى الإنتاج.
يتحقق InfraValidator من أن النموذج قابل للعرض بالفعل من البنية الأساسية، ويمنع دفع النموذج السيئ.
ينشر Pusher النموذج على البنية التحتية للخدمة.
يقوم BulkInferrer بإجراء معالجة مجمعة على نموذج يحتوي على طلبات استدلال غير مسماة.
يوضح هذا الرسم البياني تدفق البيانات بين هذه المكونات:
مكتبات TFX
يتضمن TFX كلا من المكتبات ومكونات خطوط الأنابيب. يوضح هذا الرسم البياني العلاقات بين مكتبات TFX ومكونات خطوط الأنابيب:
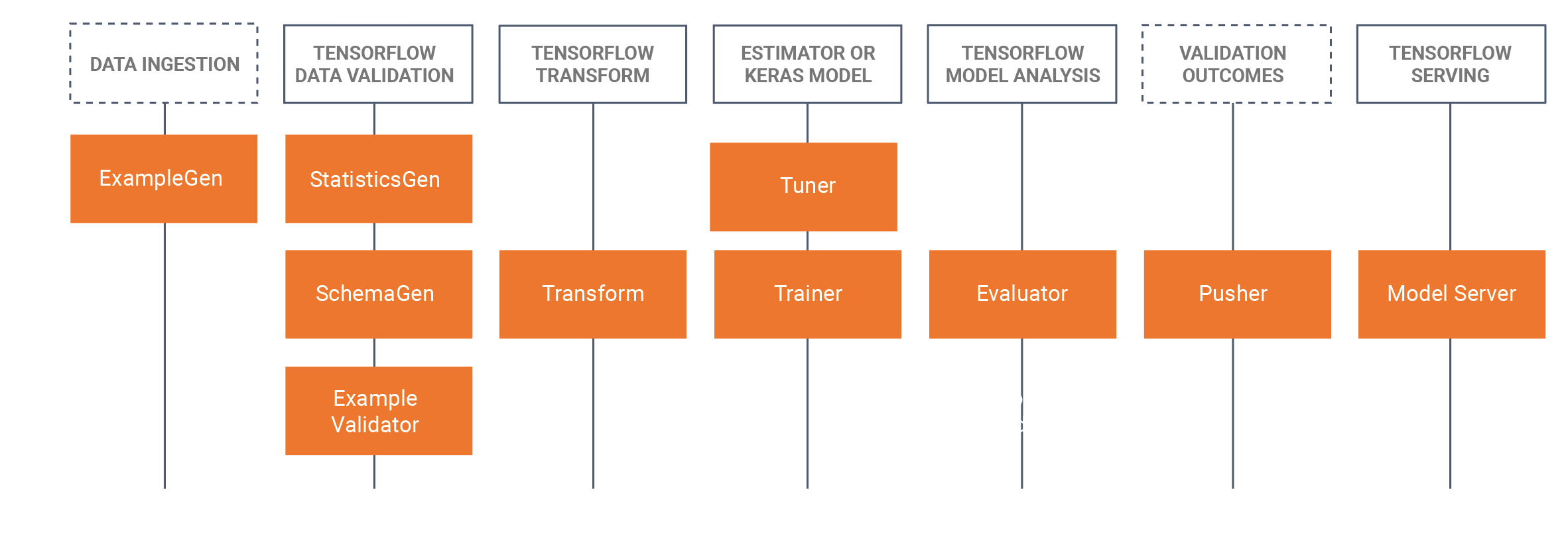
توفر TFX العديد من حزم Python وهي المكتبات المستخدمة لإنشاء مكونات خطوط الأنابيب. ستستخدم هذه المكتبات لإنشاء مكونات خطوط الأنابيب الخاصة بك حتى تتمكن التعليمات البرمجية الخاصة بك من التركيز على الجوانب الفريدة لخطوط الأنابيب الخاصة بك.
تتضمن مكتبات TFX ما يلي:
TensorFlow Data Validation (TFDV) هي مكتبة لتحليل بيانات التعلم الآلي والتحقق من صحتها. لقد تم تصميمه ليكون قابلاً للتطوير بشكل كبير ويعمل بشكل جيد مع TensorFlow وTFX. يتضمن TFDV:
- حساب قابل للتوسيع لإحصائيات ملخص التدريب وبيانات الاختبار.
- التكامل مع العارض لتوزيع البيانات والإحصائيات، وكذلك مقارنة الأوجه لأزواج مجموعات البيانات (Facets).
- إنشاء مخطط بيانات آليًا لوصف التوقعات حول البيانات مثل القيم والنطاقات والمفردات المطلوبة.
- عارض المخطط لمساعدتك في فحص المخطط.
- اكتشاف الحالات الشاذة لتحديد الحالات الشاذة، مثل الميزات المفقودة، أو القيم خارج النطاق، أو أنواع الميزات الخاطئة، على سبيل المثال لا الحصر.
- عارض الحالات الشاذة حتى تتمكن من معرفة الميزات التي بها حالات شاذة ومعرفة المزيد من أجل تصحيحها.
TensorFlow Transform (TFT) عبارة عن مكتبة لمعالجة البيانات مسبقًا باستخدام TensorFlow. يُعد تحويل TensorFlow مفيدًا للبيانات التي تتطلب تمريرًا كاملاً، مثل:
- تطبيع قيمة الإدخال عن طريق الانحراف المتوسط والمعياري.
- تحويل السلاسل إلى أعداد صحيحة عن طريق توليد المفردات على كافة قيم الإدخال.
- تحويل العوامات إلى أعداد صحيحة عن طريق تعيينها إلى مجموعات بناءً على توزيع البيانات المرصودة.
يتم استخدام TensorFlow لنماذج التدريب مع TFX. فهو يستوعب بيانات التدريب وكود النمذجة وينشئ نتيجة SavedModel. كما أنه يدمج أيضًا خط الأنابيب الهندسي المميز الذي تم إنشاؤه بواسطة TensorFlow Transform لمعالجة بيانات الإدخال مسبقًا.
يتم استخدام KerasTuner لضبط المعلمات الفائقة للنموذج.
تحليل نموذج TensorFlow (TFMA) عبارة عن مكتبة لتقييم نماذج TensorFlow. يتم استخدامه مع TensorFlow لإنشاء EvalSavedModel، والذي يصبح الأساس لتحليله. فهو يسمح للمستخدمين بتقييم نماذجهم على كميات كبيرة من البيانات بطريقة موزعة، باستخدام نفس المقاييس المحددة في مدربهم. يمكن حساب هذه المقاييس عبر شرائح مختلفة من البيانات وتصورها في دفاتر ملاحظات Jupyter.
توفر بيانات تعريف TensorFlow (TFMD) تمثيلات قياسية لبيانات التعريف المفيدة عند تدريب نماذج التعلم الآلي باستخدام TensorFlow. يمكن إنتاج البيانات التعريفية يدويًا أو تلقائيًا أثناء تحليل بيانات الإدخال، ويمكن استهلاكها للتحقق من صحة البيانات واستكشافها وتحويلها. تتضمن تنسيقات تسلسل البيانات التعريفية ما يلي:
- مخطط يصف البيانات الجدولية (على سبيل المثال، tf.Examples).
- مجموعة من الإحصائيات الموجزة حول مجموعات البيانات هذه.
البيانات الوصفية لتعلم الآلة (MLMD) هي مكتبة لتسجيل واسترجاع البيانات التعريفية المرتبطة بسير عمل مطور تعلم الآلة وعالم البيانات. في أغلب الأحيان تستخدم البيانات الوصفية تمثيلات TFMD. يدير MLMD الثبات باستخدام SQL-Lite و MySQL ومخازن البيانات المماثلة الأخرى.
التقنيات الداعمة
مطلوب
- يعد Apache Beam نموذجًا مفتوح المصدر وموحدًا لتحديد خطوط أنابيب المعالجة المتوازية للبيانات المجمعة والدفقية. تستخدم TFX Apache Beam لتنفيذ خطوط أنابيب متوازية للبيانات. يتم بعد ذلك تنفيذ خط الأنابيب بواسطة إحدى الواجهات الخلفية للمعالجة الموزعة المدعومة من Beam، والتي تشمل Apache Flink وApache Spark و Google Cloud Dataflow وغيرها.
خياري
تعمل المنسقات مثل Apache Airflow وKubeflow على تسهيل عملية تكوين مسار تعلم الآلة وتشغيله ومراقبته وصيانته.
Apache Airflow عبارة عن منصة لتأليف مسارات العمل وجدولتها ومراقبتها برمجيًا. يستخدم TFX Airflow لتأليف سير العمل كرسوم بيانية غير دورية موجهة (DAGs) للمهام. يقوم برنامج جدولة Airflow بتنفيذ المهام على مجموعة من العمال مع اتباع التبعيات المحددة. تجعل الأدوات المساعدة لسطر الأوامر الغنية إجراء العمليات الجراحية المعقدة على DAGs أمرًا سهلاً. تعمل واجهة المستخدم الغنية على تسهيل تصور خطوط الأنابيب قيد التشغيل في الإنتاج ومراقبة التقدم واستكشاف المشكلات وإصلاحها عند الحاجة. عندما يتم تعريف سير العمل على أنه تعليمات برمجية، فإنه يصبح أكثر قابلية للصيانة والإصدار والاختبار والتعاون.
Kubeflow ملتزم بجعل عمليات نشر سير عمل التعلم الآلي (ML) على Kubernetes بسيطة ومحمولة وقابلة للتطوير. لا يتمثل هدف Kubeflow في إعادة إنشاء خدمات أخرى، بل في توفير طريقة مباشرة لنشر أفضل الأنظمة مفتوحة المصدر لتعلم الآلة في البنى التحتية المتنوعة. تتيح خطوط أنابيب Kubeflow تكوين وتنفيذ مسارات عمل قابلة للتكرار على Kubeflow، ومتكاملة مع التجارب والتجارب القائمة على أجهزة الكمبيوتر المحمولة. تتضمن خدمات Kubeflow Pipelines على Kubernetes مخزن البيانات التعريفية المستضاف ومحرك التنسيق القائم على الحاوية وخادم الكمبيوتر المحمول وواجهة المستخدم لمساعدة المستخدمين على تطوير وتشغيل وإدارة خطوط أنابيب تعلم الآلة المعقدة على نطاق واسع. تسمح Kubeflow Pipelines SDK بإنشاء ومشاركة المكونات وتكوين خطوط الأنابيب برمجياً.
قابلية النقل وقابلية التشغيل البيني
تم تصميم TFX ليكون محمولاً في بيئات متعددة وأطر عمل التنسيق، بما في ذلك Apache Airflow و Apache Beam و Kubeflow . كما أنه قابل للنقل إلى منصات حوسبة مختلفة، بما في ذلك الأنظمة الأساسية المحلية والسحابية مثل Google Cloud Platform (GCP) . على وجه الخصوص، تتفاعل TFX مع خدمات GCP المُدارة بواسطة الخادم، مثل Cloud AI Platform للتدريب والتنبؤ ، و Cloud Dataflow لمعالجة البيانات الموزعة للعديد من الجوانب الأخرى من دورة حياة ML.
النموذج مقابل SavedModel
نموذج
النموذج هو مخرجات العملية التدريبية . وهو السجل المتسلسل للأوزان التي تم تعلمها أثناء عملية التدريب. يمكن استخدام هذه الأوزان لاحقًا لحساب التنبؤات لأمثلة المدخلات الجديدة. بالنسبة إلى TFX وTensorFlow، يشير "النموذج" إلى نقاط التفتيش التي تحتوي على الأوزان التي تم تعلمها حتى تلك النقطة.
لاحظ أن "النموذج" قد يشير أيضًا إلى تعريف الرسم البياني الحسابي TensorFlow (أي ملف Python) الذي يعبر عن كيفية حساب التنبؤ. يمكن استخدام الحواسين بالتبادل بناءً على السياق.
نموذج محفوظ
- ما هو SavedModel : تسلسل عالمي، محايد للغة، محكم، قابل للاسترداد لنموذج TensorFlow.
- سبب أهميته : فهو يمكّن الأنظمة ذات المستوى الأعلى من إنتاج نماذج TensorFlow وتحويلها واستهلاكها باستخدام تجريد واحد.
SavedModel هو تنسيق التسلسل الموصى به لخدمة نموذج TensorFlow في الإنتاج، أو تصدير نموذج مدرب لتطبيق الهاتف المحمول أو JavaScript الأصلي. على سبيل المثال، لتحويل نموذج إلى خدمة REST لإجراء التنبؤات، يمكنك إجراء تسلسل للنموذج باعتباره SavedModel وتقديمه باستخدام TensorFlow Serving. راجع تقديم نموذج TensorFlow لمزيد من المعلومات.
مخطط
تستخدم بعض مكونات TFX وصفًا لبيانات الإدخال الخاصة بك يسمى المخطط . المخطط هو مثيل schema.proto . المخططات هي نوع من المخزن المؤقت للبروتوكول ، والمعروفة بشكل عام باسم "protobuf". يمكن للمخطط تحديد أنواع البيانات لقيم المعالم، وما إذا كان يجب أن تكون الميزة موجودة في جميع الأمثلة، ونطاقات القيمة المسموح بها، والخصائص الأخرى. تتمثل إحدى فوائد استخدام التحقق من صحة بيانات TensorFlow (TFDV) في أنه سيتم إنشاء مخطط تلقائيًا عن طريق استنتاج الأنواع والفئات والنطاقات من بيانات التدريب.
فيما يلي مقتطف من مخطط protobuf:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
تستخدم المكونات التالية المخطط:
- التحقق من صحة بيانات TensorFlow
- تحويل TensorFlow
في خط أنابيب TFX النموذجي، يقوم TensorFlow Data Validation بإنشاء مخطط يتم استهلاكه بواسطة المكونات الأخرى.
التطوير باستخدام TFX
توفر TFX منصة قوية لكل مرحلة من مراحل مشروع التعلم الآلي، بدءًا من البحث والتجريب والتطوير على جهازك المحلي وحتى النشر. لتجنب تكرار التعليمات البرمجية والقضاء على احتمالية انحراف التدريب/الخدمة، يوصى بشدة بتنفيذ خط أنابيب TFX الخاص بك لكل من التدريب النموذجي ونشر النماذج المدربة، واستخدام مكونات التحويل التي تستفيد من مكتبة TensorFlow Transform لكل من التدريب والاستدلال. ومن خلال القيام بذلك، ستستخدم نفس كود المعالجة المسبقة والتحليل بشكل متسق، وستتجنب الاختلافات بين البيانات المستخدمة للتدريب والبيانات التي يتم تغذيتها لنماذجك المدربة في الإنتاج، بالإضافة إلى الاستفادة من كتابة هذا الكود مرة واحدة.
استكشاف البيانات وتصورها وتنظيفها
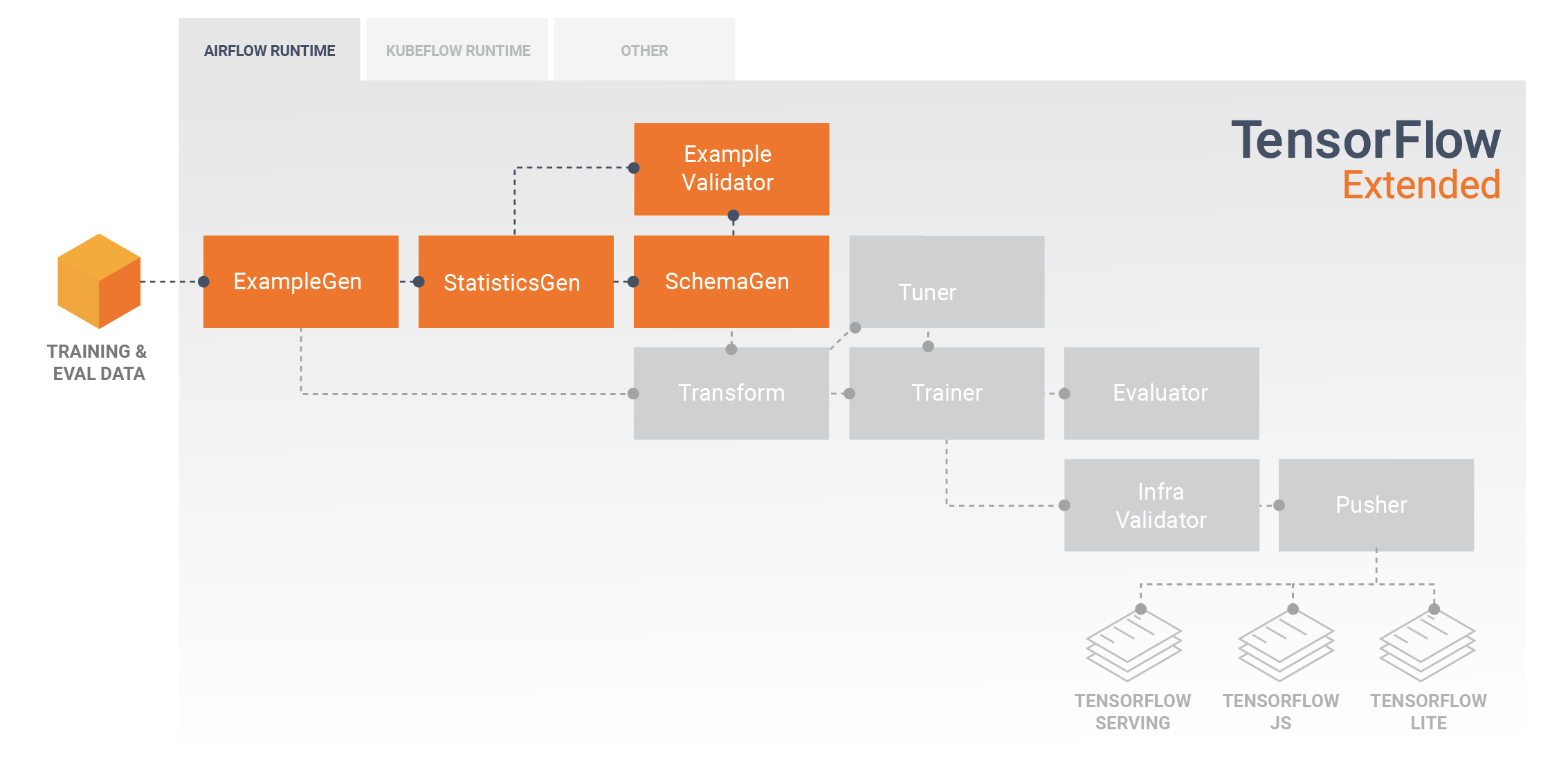
تبدأ خطوط أنابيب TFX عادةً بمكون exampleGen ، الذي يقبل بيانات الإدخال وينسقها على هيئة tf.Examples. غالبًا ما يتم ذلك بعد تقسيم البيانات إلى مجموعات بيانات التدريب والتقييم بحيث يكون هناك نسختان فعليًا من مكونات exampleGen، واحدة لكل من التدريب والتقييم. يتبع ذلك عادةً مكون StatisticsGen ومكون SchemaGen ، الذي سيفحص بياناتك ويستنتج مخطط البيانات والإحصائيات. سيتم استهلاك المخطط والإحصائيات بواسطة مكون exampleValidator ، والذي سيبحث عن الحالات الشاذة والقيم المفقودة وأنواع البيانات غير الصحيحة في بياناتك. تستفيد كل هذه المكونات من إمكانيات مكتبة TensorFlow Data Validation .
يعد التحقق من صحة بيانات TensorFlow (TFDV) أداة قيمة عند إجراء الاستكشاف الأولي لمجموعة البيانات الخاصة بك وتصورها وتنظيفها. يقوم TFDV بفحص بياناتك ويستنتج أنواع البيانات والفئات والنطاقات، ثم يساعد تلقائيًا في تحديد الحالات الشاذة والقيم المفقودة. كما يوفر أيضًا أدوات تصور يمكنها مساعدتك في فحص مجموعة البيانات الخاصة بك وفهمها. بعد اكتمال المسار الخاص بك، يمكنك قراءة البيانات التعريفية من MLMD واستخدام أدوات التصور الخاصة بـ TFDV في دفتر ملاحظات Jupyter لتحليل بياناتك.
بعد التدريب الأولي للنموذج ونشره، يمكن استخدام TFDV لمراقبة البيانات الجديدة من طلبات الاستدلال إلى نماذجك المنشورة، والبحث عن الحالات الشاذة و/أو الانحراف. يعد هذا مفيدًا بشكل خاص لبيانات السلاسل الزمنية التي تتغير بمرور الوقت نتيجة للاتجاه أو الموسمية، ويمكن أن يساعد في الإبلاغ عند وجود مشاكل في البيانات أو عندما تحتاج النماذج إلى إعادة تدريبها على البيانات الجديدة.
تصور البيانات
بعد الانتهاء من التشغيل الأول لبياناتك من خلال قسم المسار الذي يستخدم TFDV (عادةً StatisticsGen وSchemaGen وExampleValidator) يمكنك تصور النتائج في دفتر ملاحظات بنمط Jupyter. بالنسبة لعمليات التشغيل الإضافية، يمكنك مقارنة هذه النتائج أثناء إجراء التعديلات، حتى تصبح بياناتك مثالية للنموذج والتطبيق الخاص بك.
سوف تقوم أولاً بالاستعلام عن بيانات تعريف ML (MLMD) لتحديد نتائج عمليات التنفيذ هذه لهذه المكونات، ثم استخدام واجهة برمجة تطبيقات دعم المرئيات في TFDV لإنشاء المرئيات في دفتر الملاحظات الخاص بك. يتضمن ذلك tfdv.load_statistics() و tfdv.visualize_statistics() باستخدام هذا التمثيل المرئي، يمكنك فهم خصائص مجموعة البيانات الخاصة بك بشكل أفضل، وتعديلها إذا لزم الأمر كما هو مطلوب.
نماذج التطوير والتدريب
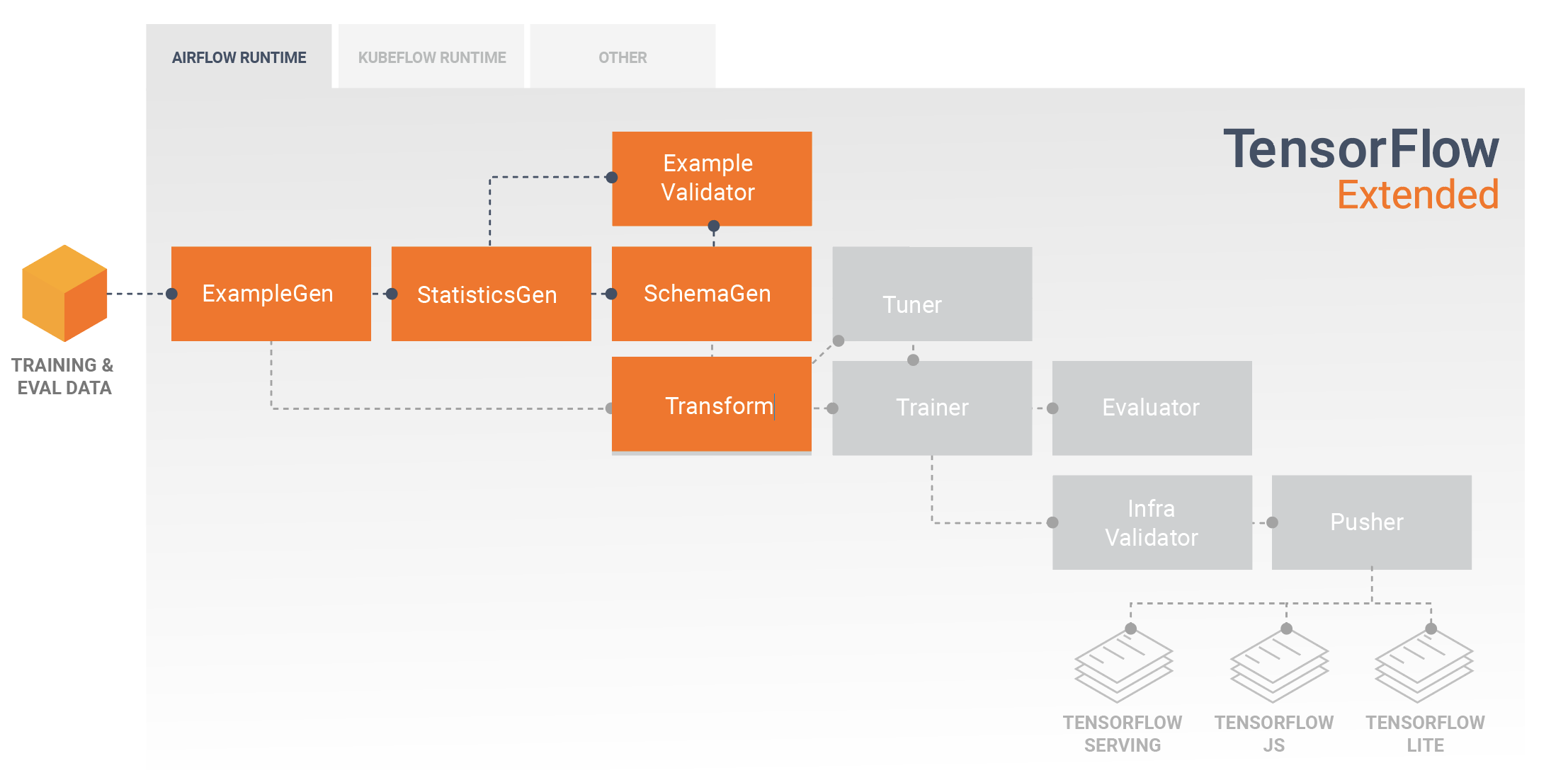
سيتضمن خط أنابيب TFX النموذجي مكون تحويل ، والذي سيؤدي هندسة الميزات من خلال الاستفادة من إمكانات مكتبة TensorFlow Transform (TFT) . يستهلك مكون التحويل المخطط الذي تم إنشاؤه بواسطة مكون SchemaGen، ويطبق تحويلات البيانات لإنشاء الميزات التي سيتم استخدامها لتدريب النموذج الخاص بك ودمجها وتحويلها. يجب أيضًا إجراء تنظيف القيم المفقودة وتحويل الأنواع في مكون التحويل إذا كان هناك احتمال أن تكون هذه موجودة أيضًا في البيانات المرسلة لطلبات الاستدلال. هناك بعض الاعتبارات المهمة عند تصميم كود TensorFlow للتدريب على TFX.
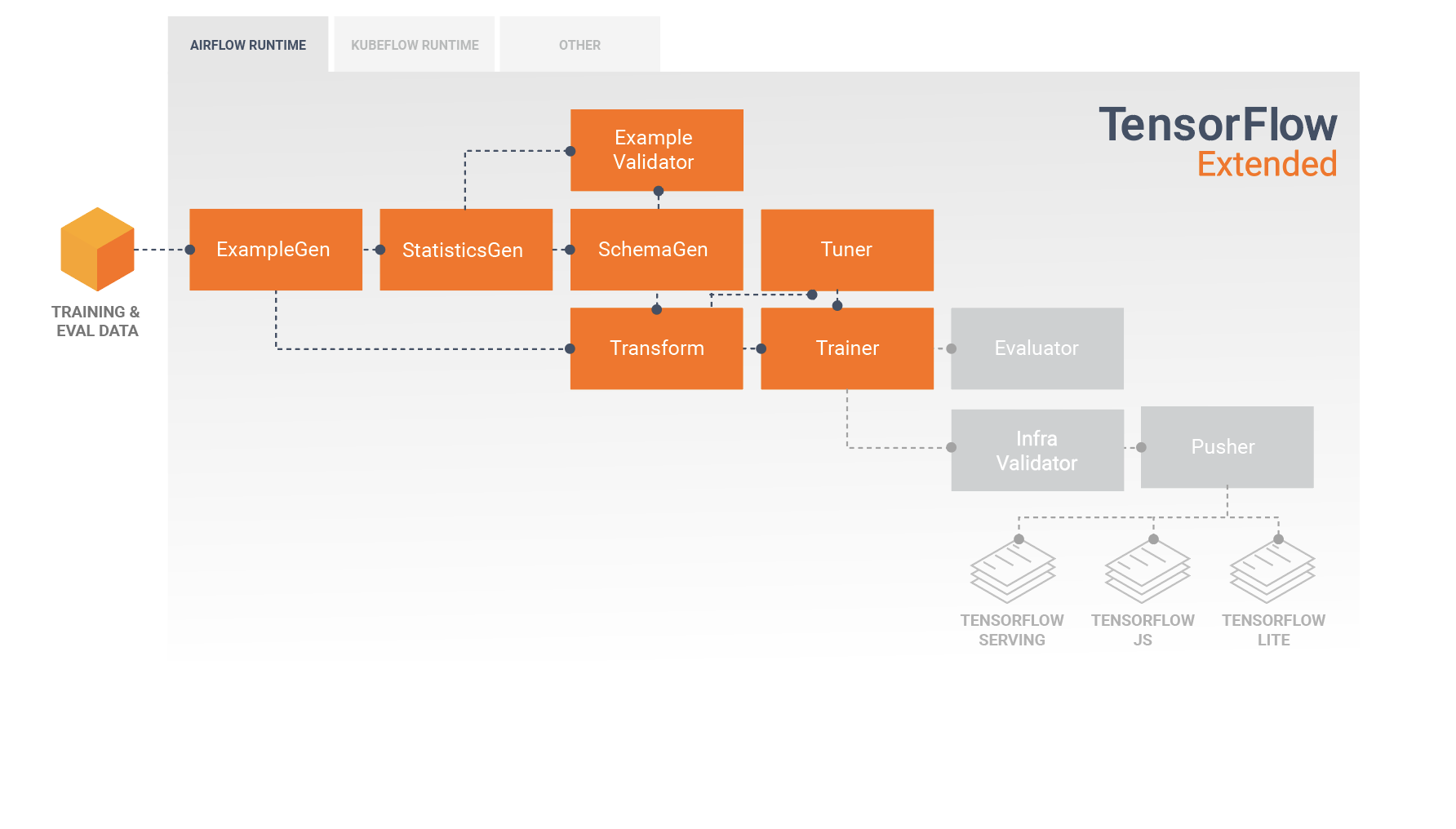
نتيجة مكون التحويل هي SavedModel الذي سيتم استيراده واستخدامه في كود النمذجة الخاص بك في TensorFlow، أثناء مكون المدرب . يتضمن هذا النموذج المحفوظ جميع تحويلات هندسة البيانات التي تم إنشاؤها في مكون التحويل، بحيث يتم تنفيذ التحويلات المتطابقة باستخدام نفس التعليمات البرمجية بالضبط أثناء كل من التدريب والاستدلال. باستخدام كود النمذجة، بما في ذلك SavedModel من مكون التحويل، يمكنك استهلاك بيانات التدريب والتقييم الخاصة بك وتدريب النموذج الخاص بك.
عند العمل مع النماذج المستندة إلى Estimator، يجب أن يحفظ القسم الأخير من كود النمذجة الخاص بك النموذج الخاص بك باعتباره SavedModel وEvalSavedModel. يضمن الحفظ كنموذج EvalSavedModel أن المقاييس المستخدمة في وقت التدريب متاحة أيضًا أثناء التقييم (لاحظ أن هذا غير مطلوب للنماذج المستندة إلى keras). يتطلب حفظ EvalSavedModel أن تقوم باستيراد مكتبة TensorFlow Model Analysis (TFMA) في مكون المدرب الخاص بك.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
يمكن إضافة مكون Tuner اختياري قبل Trainer لضبط المعلمات الفائقة (على سبيل المثال، عدد الطبقات) للنموذج. باستخدام النموذج المحدد ومساحة البحث الخاصة بالمعلمات الفائقة، ستجد خوارزمية الضبط أفضل المعلمات الفائقة بناءً على الهدف.
تحليل وفهم أداء النموذج
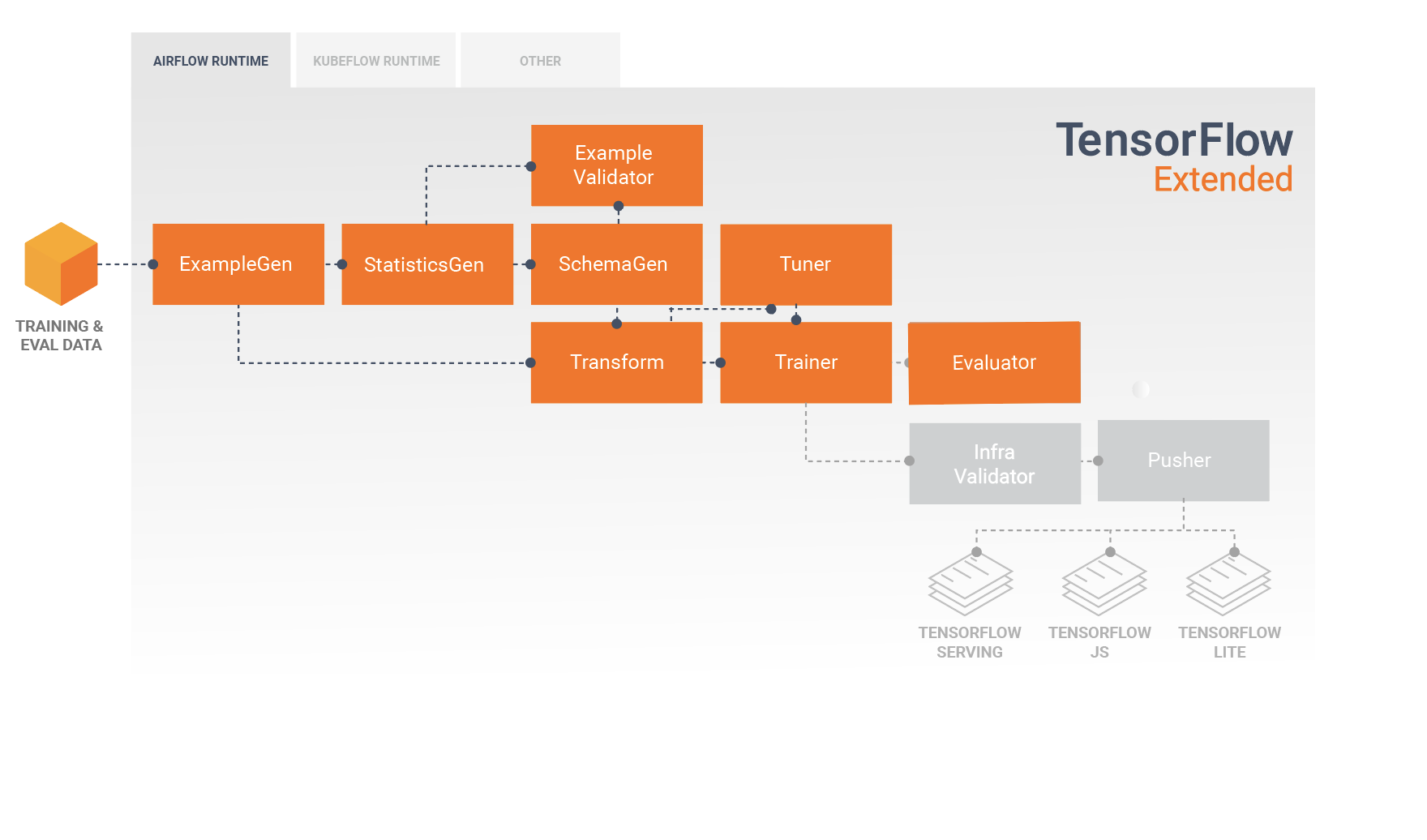
بعد تطوير النموذج الأولي والتدريب عليه، من المهم تحليل أداء النموذج الخاص بك وفهمه حقًا. سيتضمن خط أنابيب TFX النموذجي مكونًا للمقيم ، والذي يعزز قدرات مكتبة تحليل نموذج TensorFlow (TFMA) ، والتي توفر مجموعة أدوات قوية لهذه المرحلة من التطوير. يستهلك مكون المُقيم النموذج الذي قمت بتصديره أعلاه، ويسمح لك بتحديد قائمة tfma.SlicingSpec التي يمكنك استخدامها عند تصور أداء النموذج الخاص بك وتحليله. تحدد كل SlicingSpec شريحة من بيانات التدريب الخاصة بك التي تريد فحصها، مثل فئات معينة للميزات الفئوية، أو نطاقات معينة للميزات الرقمية.
على سبيل المثال، قد يكون هذا مهمًا لمحاولة فهم أداء النموذج الخاص بك لشرائح مختلفة من عملائك، والتي يمكن تقسيمها حسب المشتريات السنوية أو البيانات الجغرافية أو الفئة العمرية أو الجنس. يمكن أن يكون هذا مهمًا بشكل خاص لمجموعات البيانات ذات الذيول الطويلة، حيث قد يخفي أداء المجموعة المهيمنة أداءً غير مقبول لمجموعات مهمة ولكنها أصغر. على سبيل المثال، قد يكون أداء نموذجك جيدًا للموظفين العاديين ولكنه يفشل فشلًا ذريعًا للموظفين التنفيذيين، وقد يكون من المهم بالنسبة لك معرفة ذلك.
تحليل النموذج والتصور
بعد الانتهاء من التشغيل الأول لبياناتك من خلال تدريب النموذج الخاص بك وتشغيل مكون التقييم (الذي يعزز TFMA ) على نتائج التدريب، يمكنك تصور النتائج في دفتر ملاحظات بنمط Jupyter. بالنسبة لعمليات التشغيل الإضافية، يمكنك مقارنة هذه النتائج أثناء إجراء التعديلات، حتى تصبح نتائجك مثالية للنموذج والتطبيق الخاص بك.
ستقوم أولاً بالاستعلام عن البيانات التعريفية لـ ML (MLMD) لتحديد نتائج عمليات التنفيذ هذه لهذه المكونات، ثم استخدام واجهة برمجة تطبيقات دعم المرئيات في TFMA لإنشاء المرئيات في دفتر الملاحظات الخاص بك. يتضمن ذلك tfma.load_eval_results و tfma.view.render_slicing_metrics باستخدام هذا التصور، يمكنك فهم خصائص النموذج الخاص بك بشكل أفضل، وتعديله إذا لزم الأمر كما هو مطلوب.
التحقق من صحة أداء النموذج
كجزء من تحليل أداء النموذج، قد ترغب في التحقق من صحة الأداء مقابل خط الأساس (مثل نموذج العرض الحالي). يتم التحقق من صحة النموذج عن طريق تمرير كل من النموذج المرشح والنموذج الأساسي إلى مكون المقيم . يقوم المقيم بحساب المقاييس (مثل المساحة تحت المنحة والخسارة) لكل من المرشح وخط الأساس إلى جانب مجموعة مقابلة من مقاييس الفرق. يمكن بعد ذلك تطبيق العتبات واستخدامها لبوابة دفع النماذج الخاصة بك إلى الإنتاج.
التحقق من إمكانية تقديم النموذج
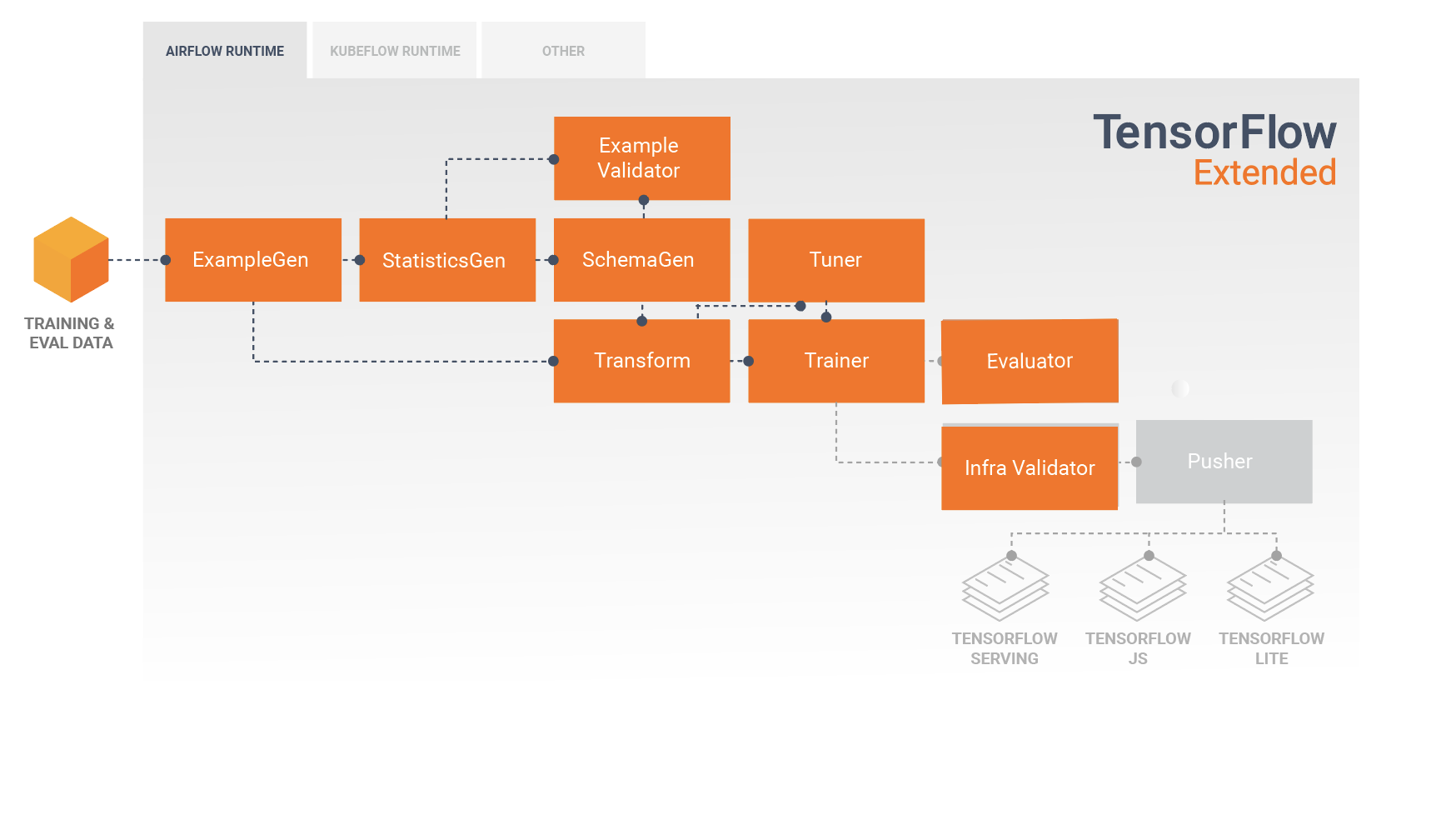
قبل نشر النموذج المُدرب، قد ترغب في التحقق مما إذا كان النموذج قابلاً للعرض بالفعل في البنية الأساسية للخدمة. وهذا مهم بشكل خاص في بيئات الإنتاج للتأكد من أن النموذج المنشور حديثًا لا يمنع النظام من خدمة التنبؤات. سيقوم مكون InfraValidator بنشر النموذج الخاص بك في بيئة معزولة، ويرسل بشكل اختياري طلبات حقيقية للتحقق من أن النموذج الخاص بك يعمل بشكل صحيح.
أهداف النشر
بمجرد قيامك بتطوير النموذج الذي يرضيك وتدريبه، فقد حان الوقت لنشره على هدف (أهداف) نشر واحد أو أكثر حيث سيتلقى طلبات الاستدلال. يدعم TFX النشر إلى ثلاث فئات من أهداف النشر. يمكن نشر النماذج المدربة التي تم تصديرها كنماذج محفوظة إلى أي من أهداف النشر هذه أو جميعها.
الاستدلال: خدمة TensorFlow
TensorFlow Serving (TFS) هو نظام خدمة مرن وعالي الأداء لنماذج التعلم الآلي، مصمم لبيئات الإنتاج. يستهلك SavedModel وسيقبل طلبات الاستدلال عبر واجهات REST أو gRPC. يتم تشغيله كمجموعة من العمليات على واحد أو أكثر من خوادم الشبكة، باستخدام واحدة من العديد من البنى المتقدمة للتعامل مع المزامنة والحساب الموزع. راجع وثائق TFS لمزيد من المعلومات حول تطوير حلول TFS ونشرها.
في المسار النموذجي، سيتم التحقق من صحة نموذج SavedModel الذي تم تدريبه في مكون المدرب أولاً باستخدام الأشعة تحت الحمراء في مكون InfraValidator . يقوم InfraValidator بإطلاق خادم نموذج TFS الكناري لخدمة SavedModel فعليًا. إذا تم التحقق من الصحة، فسيقوم مكون Pusher أخيرًا بنشر SavedModel إلى البنية التحتية TFS الخاصة بك. يتضمن ذلك التعامل مع الإصدارات المتعددة وتحديثات النماذج.
الاستدلال في تطبيقات الهاتف المحمول وإنترنت الأشياء الأصلية: TensorFlow Lite
TensorFlow Lite عبارة عن مجموعة من الأدوات المخصصة لمساعدة المطورين على استخدام نماذج TensorFlow المدربة في تطبيقات الهاتف المحمول وإنترنت الأشياء الأصلية. فهو يستهلك نفس SavedModels مثل TensorFlow Serving، ويطبق تحسينات مثل القياس الكمي والتشذيب لتحسين حجم وأداء النماذج الناتجة لمواجهة تحديات التشغيل على الأجهزة المحمولة وأجهزة إنترنت الأشياء. راجع وثائق TensorFlow Lite لمزيد من المعلومات حول استخدام TensorFlow Lite.
الاستدلال في جافا سكريبت: TensorFlow JS
TensorFlow JS هي مكتبة JavaScript للتدريب ونشر نماذج ML في المتصفح وعلى Node.js. فهو يستهلك نفس SavedModels مثل TensorFlow Serving وTensorFlow Lite، ويحولها إلى تنسيق الويب TensorFlow.js. راجع وثائق TensorFlow JS لمزيد من التفاصيل حول استخدام TensorFlow JS.
إنشاء خط أنابيب TFX مع تدفق الهواء
تحقق من ورشة تدفق الهواء للحصول على التفاصيل
إنشاء خط أنابيب TFX باستخدام Kubeflow
يثبت
يتطلب Kubeflow مجموعة Kubernetes لتشغيل خطوط الأنابيب على نطاق واسع. راجع إرشادات نشر Kubeflow التي ترشدك عبر خيارات نشر مجموعة Kubeflow.
تكوين وتشغيل خط أنابيب TFX
يرجى اتباع البرنامج التعليمي لـ TFX on Cloud AI Platform Pipeline لتشغيل نموذج TFX لخط الأنابيب على Kubeflow. تم وضع مكونات TFX في حاوية لتكوين خط أنابيب Kubeflow وتوضح العينة القدرة على تكوين خط الأنابيب لقراءة مجموعة البيانات العامة الكبيرة وتنفيذ خطوات التدريب ومعالجة البيانات على نطاق واسع في السحابة.
واجهة سطر الأوامر لإجراءات خطوط الأنابيب
يوفر TFX واجهة سطر أوامر (CLI) موحدة تساعد على تنفيذ مجموعة كاملة من إجراءات خطوط الأنابيب مثل إنشاء خطوط الأنابيب وتحديثها وتشغيلها وإدراجها وحذفها على مختلف المنسقين بما في ذلك Apache Airflow وApache Beam وKubeflow. للحصول على التفاصيل، يرجى اتباع هذه التعليمات .