
بمجرد وصول بياناتك إلى مسار TFX، يمكنك استخدام مكونات TFX لتحليلها وتحويلها. يمكنك استخدام هذه الأدوات حتى قبل تدريب النموذج.
هناك العديد من الأسباب لتحليل بياناتك وتحويلها:
- للعثور على مشاكل في البيانات الخاصة بك. تشمل المشاكل الشائعة ما يلي:
- البيانات المفقودة، مثل المعالم ذات القيم الفارغة.
- يتم التعامل مع التسميات كميزات، بحيث يتمكن النموذج الخاص بك من إلقاء نظرة خاطفة على الإجابة الصحيحة أثناء التدريب.
- الميزات ذات القيم خارج النطاق الذي تتوقعه.
- شذوذ البيانات.
- يحتوي نموذج النقل المستفادة على معالجة مسبقة لا تتطابق مع بيانات التدريب.
- لتصميم مجموعات ميزات أكثر فعالية. على سبيل المثال، يمكنك التعرف على:
- ميزات إعلامية خاصة.
- ميزات زائدة عن الحاجة.
- الميزات التي تختلف على نطاق واسع لدرجة أنها قد تؤدي إلى إبطاء التعلم.
- ميزات ذات معلومات تنبؤية فريدة قليلة أو معدومة.
يمكن لأدوات TFX المساعدة في العثور على أخطاء البيانات والمساعدة في هندسة الميزات.
التحقق من صحة بيانات TensorFlow
ملخص
يحدد التحقق من صحة بيانات TensorFlow الحالات الشاذة في التدريب وخدمة البيانات، ويمكنه إنشاء مخطط تلقائيًا عن طريق فحص البيانات. يمكن تكوين المكون لاكتشاف فئات مختلفة من الحالات الشاذة في البيانات. يمكن
- قم بإجراء عمليات التحقق من الصلاحية من خلال مقارنة إحصائيات البيانات مع المخطط الذي يقنن توقعات المستخدم.
- اكتشف انحراف خدمة التدريب من خلال مقارنة الأمثلة في بيانات التدريب وخدمة البيانات.
- كشف انحراف البيانات من خلال النظر في سلسلة من البيانات.
نقوم بتوثيق كل من هذه الوظائف بشكل مستقل:
التحقق من صحة المثال القائم على المخطط
يحدد التحقق من صحة بيانات TensorFlow أي حالات شاذة في بيانات الإدخال من خلال مقارنة إحصائيات البيانات بالمخطط. يقوم المخطط بتدوين الخصائص التي من المتوقع أن تلبيها البيانات المدخلة، مثل أنواع البيانات أو القيم الفئوية، ويمكن تعديلها أو استبدالها بواسطة المستخدم.
عادةً ما يتم استدعاء التحقق من صحة بيانات Tensorflow عدة مرات في سياق خط أنابيب TFX: (i) لكل تقسيم تم الحصول عليه من exampleGen، و(ii) لجميع البيانات المحولة مسبقًا المستخدمة بواسطة Transform و(iii) لجميع بيانات ما بعد التحويل التي تم إنشاؤها بواسطة تحويل. عند استدعائها في سياق التحويل (ii-iii)، يمكن تعيين خيارات الإحصائيات والقيود المستندة إلى المخطط عن طريق تعريف stats_options_updater_fn . وهذا مفيد بشكل خاص عند التحقق من صحة البيانات غير المنظمة (مثل ميزات النص). انظر رمز المستخدم للحصول على مثال.
ميزات المخطط المتقدم
يغطي هذا القسم تكوينات المخطط الأكثر تقدمًا والتي يمكن أن تساعد في الإعدادات الخاصة.
ميزات متفرقة
عادةً ما يقدم تشفير الميزات المتفرقة في الأمثلة ميزات متعددة من المتوقع أن يكون لها نفس التكافؤ لجميع الأمثلة. على سبيل المثال الميزة المتفرقة:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
يتطلب تعريف الميزة المتفرقة فهرسًا واحدًا أو أكثر وميزة قيمة واحدة تشير إلى الميزات الموجودة في المخطط. يتيح تحديد الميزات المتفرقة بشكل صريح لـ TFDV التحقق من تطابق تكافؤ جميع الميزات المشار إليها.
تقدم بعض حالات الاستخدام قيودًا مماثلة على التكافؤ بين الميزات، ولكنها لا تقوم بالضرورة بتشفير ميزة متفرقة. من المفترض أن يؤدي استخدام الميزة المتفرقة إلى إلغاء الحظر عنك، ولكنه ليس مثاليًا.
بيئات المخطط
تفترض عمليات التحقق الافتراضية أن جميع الأمثلة في المسار تلتزم بمخطط واحد. في بعض الحالات، يكون إدخال اختلافات طفيفة في المخطط أمرًا ضروريًا، على سبيل المثال، تكون الميزات المستخدمة كتسميات مطلوبة أثناء التدريب (وينبغي التحقق من صحتها)، ولكنها تكون مفقودة أثناء التقديم. يمكن استخدام البيئات للتعبير عن هذه المتطلبات، على وجه الخصوص default_environment() in_environment() و not_in_environment() .
على سبيل المثال، افترض أن هناك ميزة تسمى "LABEL" مطلوبة للتدريب، ولكن من المتوقع أن تكون مفقودة من العرض. ويمكن التعبير عن ذلك من خلال:
- حدد بيئتين متميزتين في المخطط: ["SERVING"، "TRAINING"] واربط "LABEL" بالبيئة "TRAINING" فقط.
- قم بربط بيانات التدريب بالبيئة "التدريب" وبيانات الخدمة بالبيئة "الخدمة".
جيل المخطط
يتم تحديد مخطط بيانات الإدخال كمثال لمخطط TensorFlow.
بدلاً من إنشاء مخطط يدويًا من الصفر، يمكن للمطور الاعتماد على إنشاء المخطط التلقائي الخاص بـ TensorFlow Data Validation. على وجه التحديد، يقوم TensorFlow Data Validation تلقائيًا بإنشاء مخطط أولي استنادًا إلى الإحصائيات المحسوبة على بيانات التدريب المتوفرة في المسار. يمكن للمستخدمين ببساطة مراجعة هذا المخطط الذي تم إنشاؤه تلقائيًا، وتعديله حسب الحاجة، والتحقق منه في نظام التحكم في الإصدار، ودفعه بشكل صريح إلى المسار لمزيد من التحقق من الصحة.
يتضمن TFDV infer_schema() لإنشاء مخطط تلقائيًا. على سبيل المثال:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
يؤدي هذا إلى إنشاء مخطط تلقائي بناءً على القواعد التالية:
إذا تم بالفعل إنشاء المخطط تلقائيًا، فسيتم استخدامه كما هو.
بخلاف ذلك، يقوم TensorFlow Data Validation بفحص إحصائيات البيانات المتاحة ويحسب المخطط المناسب للبيانات.
ملاحظة: يعد المخطط الذي تم إنشاؤه تلقائيًا هو أفضل جهد ويحاول فقط استنتاج الخصائص الأساسية للبيانات. ومن المتوقع أن يقوم المستخدمون بمراجعته وتعديله حسب الحاجة.
التدريب على خدمة الكشف عن الانحراف
ملخص
يمكن للتحقق من صحة بيانات TensorFlow اكتشاف انحراف التوزيع بين التدريب وخدمة البيانات. يحدث انحراف التوزيع عندما يختلف توزيع قيم الميزات لبيانات التدريب بشكل كبير عن بيانات العرض. أحد الأسباب الرئيسية لانحراف التوزيع هو استخدام مجموعة مختلفة تمامًا لتدريب توليد البيانات للتغلب على نقص البيانات الأولية في المجموعة المطلوبة. سبب آخر هو آلية أخذ العينات الخاطئة التي تختار فقط عينة فرعية من بيانات العرض للتدريب عليها.
السيناريو المثال
راجع دليل بدء التحقق من صحة بيانات TensorFlow للحصول على معلومات حول تكوين اكتشاف الانحراف في خدمة التدريب.
كشف الانجراف
يتم دعم اكتشاف الانجراف بين فترات متتالية من البيانات (على سبيل المثال، بين فترة N وامتداد N+1)، مثل بين أيام مختلفة من بيانات التدريب. نحن نعبر عن الانجراف من حيث مسافة L-infinity للميزات الفئوية والتباعد التقريبي لـ Jensen-Shannon للميزات الرقمية. يمكنك ضبط مسافة العتبة بحيث تتلقى تحذيرات عندما يكون الانحراف أعلى من المقبول. عادةً ما يكون تحديد المسافة الصحيحة عملية تكرارية تتطلب معرفة المجال والتجريب.
راجع دليل البدء للتحقق من صحة بيانات TensorFlow للحصول على معلومات حول تكوين اكتشاف الانجراف.
استخدام التصورات للتحقق من بياناتك
يوفر التحقق من صحة بيانات TensorFlow أدوات لتصور توزيع قيم الميزات. من خلال فحص هذه التوزيعات في دفتر ملاحظات Jupyter باستخدام Facets ، يمكنك اكتشاف المشكلات الشائعة المتعلقة بالبيانات.
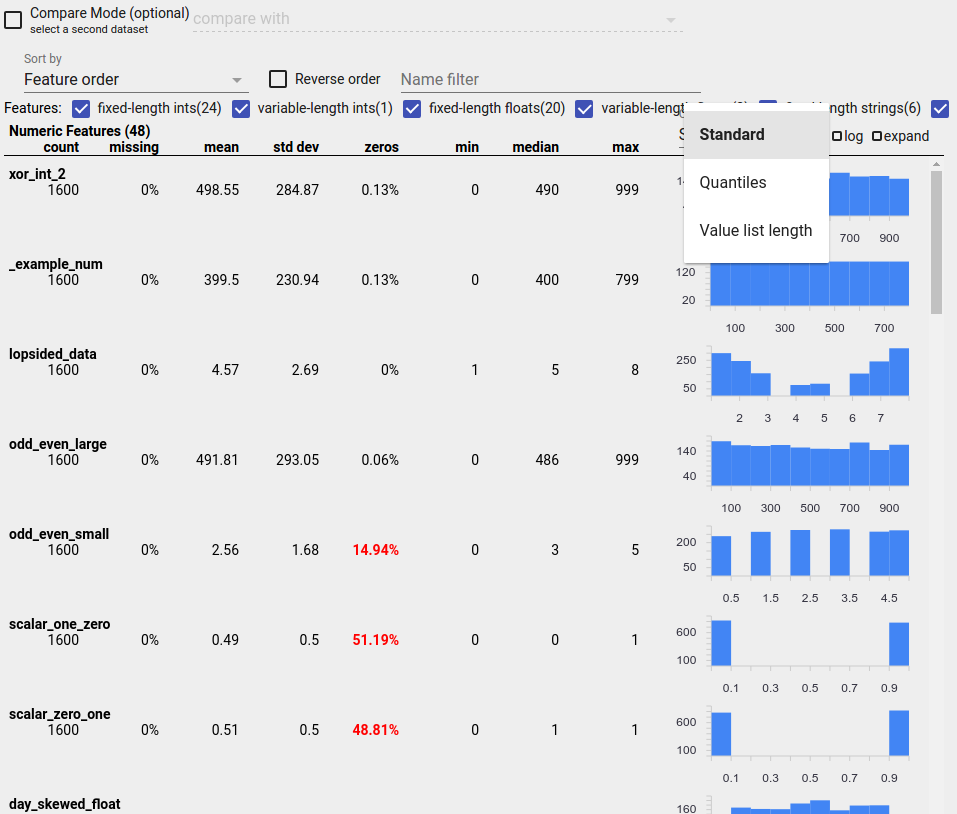
تحديد التوزيعات المشبوهة
يمكنك تحديد الأخطاء الشائعة في بياناتك باستخدام شاشة عرض Facets Overview للبحث عن التوزيعات المشبوهة لقيم الميزات.
بيانات غير متوازنة
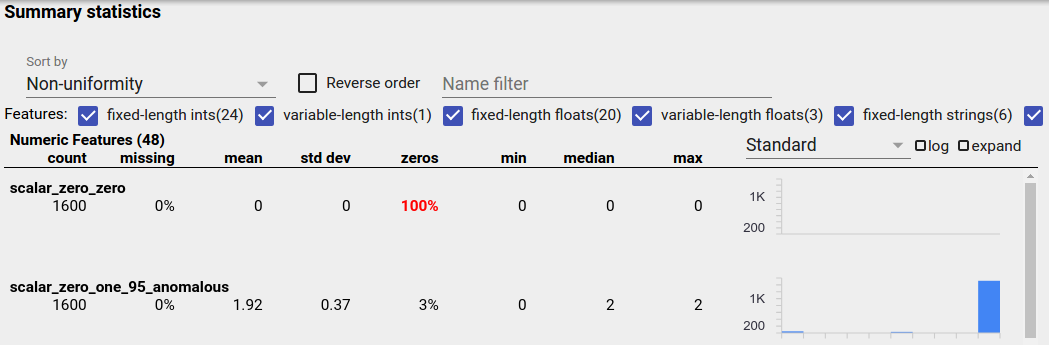
الميزة غير المتوازنة هي ميزة تسود فيها قيمة واحدة. يمكن أن تحدث الميزات غير المتوازنة بشكل طبيعي، ولكن إذا كانت الميزة دائمًا لها نفس القيمة، فقد يكون لديك خطأ في البيانات. لاكتشاف الميزات غير المتوازنة في نظرة عامة على الأوجه، اختر "عدم التوحيد" من القائمة المنسدلة "الفرز حسب".
سيتم إدراج أكثر الميزات غير المتوازنة في أعلى كل قائمة من قائمة أنواع الميزات. على سبيل المثال، تُظهر لقطة الشاشة التالية ميزة واحدة كلها أصفار، وأخرى غير متوازنة إلى حد كبير، في أعلى قائمة "الميزات الرقمية":
البيانات الموزعة بشكل موحد
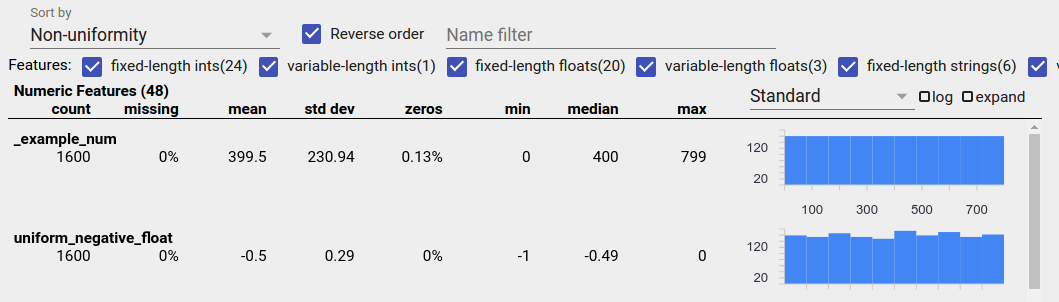
الميزة الموزعة بشكل موحد هي الميزة التي تظهر لها جميع القيم الممكنة بالقرب من نفس التردد. كما هو الحال مع البيانات غير المتوازنة، يمكن أن يحدث هذا التوزيع بشكل طبيعي، ولكن يمكن أن ينتج أيضًا عن أخطاء في البيانات.
لاكتشاف الميزات الموزعة بشكل موحد في نظرة عامة على الأوجه، اختر "عدم التوحيد" من القائمة المنسدلة "الفرز حسب" وحدد مربع الاختيار "الترتيب العكسي":
يتم تمثيل بيانات السلسلة باستخدام المخططات الشريطية إذا كان هناك 20 قيمة فريدة أو أقل، وكرسم بياني للتوزيع التراكمي إذا كان هناك أكثر من 20 قيمة فريدة. لذلك بالنسبة لبيانات السلسلة، يمكن أن تظهر التوزيعات الموحدة إما على شكل رسوم بيانية شريطية مسطحة مثل تلك الموجودة أعلاه أو خطوط مستقيمة مثل تلك الموجودة أدناه:

الأخطاء التي يمكن أن تنتج بيانات موزعة بشكل موحد
فيما يلي بعض الأخطاء الشائعة التي يمكن أن تنتج بيانات موزعة بشكل موحد:
استخدام السلاسل لتمثيل أنواع البيانات غير المتسلسلة مثل التواريخ. على سبيل المثال، سيكون لديك العديد من القيم الفريدة لميزة التاريخ والوقت مع تمثيلات مثل "2017-03-01-11-45-03". سيتم توزيع القيم الفريدة بشكل موحد.
بما في ذلك مؤشرات مثل "رقم الصف" كميزات. هنا مرة أخرى لديك العديد من القيم الفريدة.
البيانات المفقودة
للتحقق مما إذا كانت الميزة تفتقد القيم بالكامل:
- اختر "المبلغ المفقود/صفر" من القائمة المنسدلة "الفرز حسب".
- حدد مربع الاختيار "الترتيب العكسي".
- انظر إلى العمود "المفقود" لمعرفة النسبة المئوية للمثيلات التي تحتوي على قيم مفقودة لميزة ما.
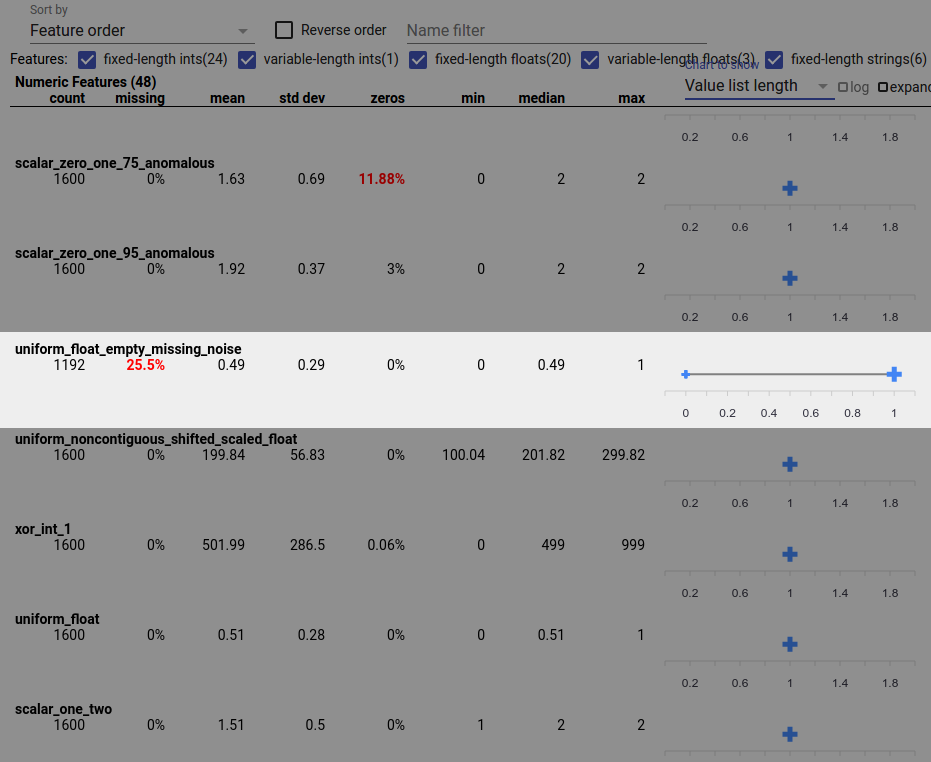
يمكن أن يتسبب خطأ البيانات أيضًا في عدم اكتمال قيم الميزات. على سبيل المثال، قد تتوقع أن تحتوي قائمة قيم الميزة دائمًا على ثلاثة عناصر وتكتشف أنها تحتوي في بعض الأحيان على عنصر واحد فقط. للتحقق من القيم غير المكتملة أو الحالات الأخرى التي لا تحتوي فيها قوائم قيم الميزات على العدد المتوقع من العناصر:
اختر "طول قائمة القيم" من القائمة المنسدلة "المخطط للإظهار" الموجودة على اليمين.
انظر إلى المخطط الموجود على يمين كل صف ميزة. يعرض المخطط نطاق أطوال قائمة القيم للمعلم. على سبيل المثال، يُظهر الصف المميز في لقطة الشاشة أدناه ميزة تحتوي على بعض قوائم القيم ذات الطول الصفري:
اختلافات كبيرة في الحجم بين الميزات
إذا كانت ميزاتك تختلف بشكل كبير في الحجم، فقد يواجه النموذج صعوبات في التعلم. على سبيل المثال، إذا كانت بعض الميزات تختلف من 0 إلى 1 والبعض الآخر يختلف من 0 إلى 1,000,000,000، فسيكون لديك اختلاف كبير في الحجم. قارن بين العمودين "الحد الأقصى" و"الحد الأدنى" عبر المعالم للعثور على مقاييس متنوعة على نطاق واسع.
فكر في تسوية قيم الميزات لتقليل هذه الاختلافات الواسعة.
التسميات ذات التسميات غير الصالحة
لدى مقدرو TensorFlow قيود على نوع البيانات التي يقبلونها كتسميات. على سبيل المثال، تعمل المصنفات الثنائية عادةً فقط مع التصنيفات {0، 1}.
قم بمراجعة قيم التسمية في نظرة عامة على الواجهات وتأكد من مطابقتها لمتطلبات المقدرين .