
| | |  Xem trên GitHub Xem trên GitHub | | |
Hướng dẫn này chứa mã hoàn chỉnh để tinh chỉnh BERT nhằm thực hiện phân tích tình cảm trên tập dữ liệu đánh giá phim IMDB văn bản thuần túy. Ngoài việc đào tạo một người mẫu, bạn sẽ học cách xử lý trước văn bản thành một định dạng thích hợp.
Trong sổ tay này, bạn sẽ:
- Tải tập dữ liệu IMDB
- Tải mô hình BERT từ TensorFlow Hub
- Xây dựng mô hình của riêng bạn bằng cách kết hợp BERT với bộ phân loại
- Đào tạo mô hình của riêng bạn, tinh chỉnh BERT như một phần của điều đó
- Lưu mô hình của bạn và sử dụng nó để phân loại các câu
Nếu bạn là người mới đến làm việc với các tập dữ liệu IMDB, vui lòng xem phân loại văn bản cơ bản để biết thêm chi tiết.
Về BERT
Bert và kiến trúc Transformer encoder khác đã thành công vang dội trên một loạt các nhiệm vụ trong NLP (xử lý ngôn ngữ tự nhiên). Họ tính toán các biểu diễn không gian-vectơ của ngôn ngữ tự nhiên phù hợp để sử dụng trong các mô hình học sâu. Dòng mô hình BERT sử dụng kiến trúc bộ mã hóa Transformer để xử lý từng mã thông báo của văn bản đầu vào trong ngữ cảnh đầy đủ của tất cả các mã thông báo trước và sau, do đó có tên: Biểu diễn bộ mã hóa hai chiều từ Người biến áp.
Các mô hình BERT thường được đào tạo trước trên một kho văn bản lớn, sau đó được tinh chỉnh cho các tác vụ cụ thể.
Thành lập
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
Bạn sẽ sử dụng tối ưu hóa AdamW từ tensorflow / mô hình .
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Phân tích tình cảm
Máy tính xách tay này huấn luyện một mô hình phân tích tình cảm để đánh giá phim classify như tích cực hay tiêu cực, dựa trên văn bản của tổng quan.
Bạn sẽ sử dụng lớn Movie Review Dataset có chứa nội dung của 50.000 đánh giá phim từ Internet Movie Database .
Tải xuống tập dữ liệu IMDB
Hãy tải xuống và giải nén tập dữ liệu, sau đó khám phá cấu trúc thư mục.
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
Tiếp theo, bạn sẽ sử dụng text_dataset_from_directory tiện ích để tạo ra một nhãn tf.data.Dataset .
Tập dữ liệu IMDB đã được chia thành huấn luyện và thử nghiệm, nhưng nó thiếu tập hợp xác thực. Hãy tạo ra một tập hợp kiểm chứng bằng một tách 80:20 của dữ liệu huấn luyện bằng công validation_split luận dưới đây.
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
Hãy cùng xem qua một vài đánh giá.
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Đang tải mô hình từ TensorFlow Hub
Tại đây, bạn có thể chọn mô hình BERT mà bạn sẽ tải từ TensorFlow Hub và tinh chỉnh. Có nhiều mô hình BERT có sẵn.
- Bert-Base , nhồi và hơn bảy mô hình với trọng lượng đào tạo phát hành bởi các tác giả Bert gốc.
- BERTS nhỏ có kiến trúc tương tự nói chung nhưng ít hơn và / hoặc khối Transformer nhỏ hơn, cho phép bạn khám phá cân bằng giữa tốc độ, quy mô và chất lượng.
- ALBERT : bốn kích cỡ khác nhau của "Một Lite Bert" làm giảm kích thước mô hình (nhưng không phải thời gian tính toán) bằng cách chia sẻ các thông số giữa các lớp.
- Bert Các chuyên gia : Tám mô hình mà tất cả đều có kiến trúc Bert-base nhưng đưa ra một sự lựa chọn giữa các lĩnh vực pre-đào tạo khác nhau, để gắn kết chặt chẽ hơn với các nhiệm vụ mục tiêu.
- Electra có kiến trúc giống như Bert (trong ba kích cỡ khác nhau), nhưng bị trước được đào tạo như một phân biệt trong một thiết lập tương tự như một đối nghịch Mạng Generative (GAN).
- Bert với Talking Heads-Attention và Cổng Gelu [ cơ sở , lớn ] có hai cải tiến cho cốt lõi của kiến trúc Transformer.
Tài liệu về mô hình trên TensorFlow Hub có nhiều chi tiết hơn và tham chiếu đến các tài liệu nghiên cứu. Thực hiện theo các liên kết trên, hoặc nhấp vào tfhub.dev URL in sau khi thực hiện di động tiếp theo.
Đề xuất là bắt đầu với BERT nhỏ (với ít tham số hơn) vì chúng nhanh hơn để tinh chỉnh. Nếu bạn thích một mô hình nhỏ nhưng có độ chính xác cao hơn, ALBERT có thể là lựa chọn tiếp theo của bạn. Nếu bạn muốn độ chính xác cao hơn nữa, hãy chọn một trong các kích thước BERT cổ điển hoặc các tinh chỉnh gần đây của chúng như Electra, Talking Heads hoặc BERT Expert.
Bên cạnh những mô hình có sẵn dưới đây, có nhiều phiên bản của các mô hình có dung lượng lớn và có thể mang lại độ chính xác tốt hơn, nhưng họ là quá lớn để có thể tinh chỉnh trên một GPU duy nhất. Bạn sẽ có thể để làm điều đó trên nhiệm vụ KEO Giải quyết sử dụng Bert trên colab TPU .
Bạn sẽ thấy trong đoạn mã bên dưới rằng việc chuyển đổi URL tfhub.dev là đủ để thử bất kỳ mô hình nào trong số này, vì tất cả sự khác biệt giữa chúng được gói gọn trong SavedModels từ TF Hub.
Chọn một mô hình BERT để tinh chỉnh
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
Mô hình tiền xử lý
Đầu vào văn bản cần được chuyển đổi thành id mã thông báo số và được sắp xếp thành nhiều Tensors trước khi được nhập vào BERT. TensorFlow Hub cung cấp một mô hình tiền xử lý phù hợp cho từng mô hình BERT được thảo luận ở trên, mô hình này thực hiện chuyển đổi này bằng cách sử dụng TF ops từ thư viện TF.text. Không cần thiết phải chạy mã Python thuần túy bên ngoài mô hình TensorFlow của bạn để xử lý trước văn bản.
Mô hình tiền xử lý phải là mô hình được tham chiếu bởi tài liệu của mô hình BERT, bạn có thể đọc mô hình này tại URL được in ở trên. Đối với các mô hình BERT từ menu thả xuống ở trên, mô hình tiền xử lý được chọn tự động.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
Hãy thử mô hình tiền xử lý trên một số văn bản và xem kết quả:
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
Như bạn có thể thấy, bây giờ bạn có 3 kết quả đầu ra từ tiền xử lý rằng một mô hình Bert sẽ sử dụng ( input_words_id , input_mask và input_type_ids ).
Một số điểm quan trọng khác:
- Đầu vào được cắt ngắn thành 128 mã thông báo. Số lượng thẻ có thể được tùy chỉnh, và bạn có thể xem chi tiết hơn về Giải quyết các nhiệm vụ KEO sử dụng Bert trên colab TPU .
- Các
input_type_idschỉ có một giá trị (0) vì đây là một đầu vào câu duy nhất. Đối với đầu vào nhiều câu, nó sẽ có một số cho mỗi đầu vào.
Vì bộ tiền xử lý văn bản này là một mô hình TensorFlow, nên Nó có thể được đưa trực tiếp vào mô hình của bạn.
Sử dụng mô hình BERT
Trước khi đưa BERT vào mô hình của riêng bạn, chúng ta hãy xem xét kết quả đầu ra của nó. Bạn sẽ tải nó từ TF Hub và xem các giá trị trả về.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
Các mô hình Bert trả về một bản đồ với 3 phím quan trọng: pooled_output , sequence_output , encoder_outputs :
-
pooled_outputđại diện cho mỗi chuỗi đầu vào như một toàn thể. Hình dạng là[batch_size, H]. Bạn có thể coi đây là một phần nhúng cho toàn bộ bài đánh giá phim. -
sequence_outputđại diện cho mỗi đầu vào mã thông báo trong bối cảnh. Hình dạng là[batch_size, seq_length, H]. Bạn có thể coi đây là cách nhúng theo ngữ cảnh cho mọi mã thông báo trong bài đánh giá phim. -
encoder_outputslà kích hoạt trung gian củaLkhối Transformer.outputs["encoder_outputs"][i]là một tensor hình dạng[batch_size, seq_length, 1024]với kết quả đầu ra của thứ i khối Transformer, cho0 <= i < L. Giá trị cuối cùng của danh sách là bằngsequence_output.
Đối với các tinh chỉnh bạn sẽ sử dụng pooled_output mảng.
Xác định mô hình của bạn
Bạn sẽ tạo một mô hình tinh chỉnh rất đơn giản, với mô hình tiền xử lý, mô hình BERT đã chọn, một lớp Dày và một lớp Bỏ học.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
Hãy kiểm tra xem mô hình có chạy với đầu ra của mô hình tiền xử lý hay không.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
Tất nhiên, đầu ra là vô nghĩa vì người mẫu chưa được đào tạo.
Chúng ta hãy nhìn vào cấu trúc của mô hình.
tf.keras.utils.plot_model(classifier_model)
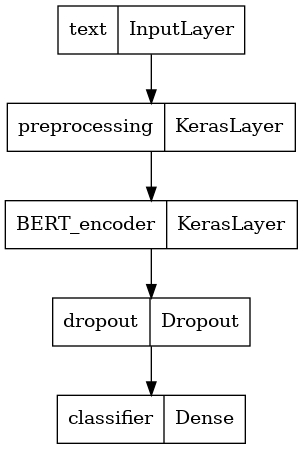
Đào tạo người mẫu
Bây giờ bạn có tất cả các phần để đào tạo một mô hình, bao gồm mô-đun tiền xử lý, bộ mã hóa BERT, dữ liệu và bộ phân loại.
Thiếu chức năng
Do đây là một vấn đề phân loại nhị phân và mô hình kết quả đầu ra một xác suất (một lớp duy nhất đơn vị), bạn sẽ sử dụng losses.BinaryCrossentropy chức năng thua lỗ.
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
Trình tối ưu hóa
Để tinh chỉnh, hãy sử dụng cùng một trình tối ưu hóa mà BERT đã được đào tạo ban đầu: "Những khoảnh khắc thích ứng" (Adam). Ưu này giảm thiểu sự mất mát dự đoán và làm theo quy tắc bởi sự phân rã trọng lượng (không sử dụng những khoảnh khắc), mà còn được gọi là AdamW .
Đối với tỷ lệ học ( init_lr ), bạn sẽ sử dụng cùng một lịch trình như Bert-đào tạo trước: phân rã tuyến tính của một tỷ lệ học ban đầu danh nghĩa, bắt đầu bằng một giai đoạn khởi động tuyến tính trong 10% đầu tiên của huấn luyện bước ( num_warmup_steps ). Phù hợp với bài báo BERT, tốc độ học ban đầu nhỏ hơn để tinh chỉnh (tốt nhất là 5e-5, 3e-5, 2e-5).
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
Tải mô hình BERT và đào tạo
Sử dụng classifier_model bạn đã tạo trước đó, bạn có thể biên dịch các mô hình với sự mất mát, số liệu và tối ưu hóa.
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
Đánh giá mô hình
Hãy xem mô hình hoạt động như thế nào. Hai giá trị sẽ được trả về. Mất mát (một số đại diện cho lỗi, các giá trị càng thấp càng tốt) và độ chính xác.
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
Vẽ biểu đồ độ chính xác và mất mát theo thời gian
Dựa trên History đối tượng được trả về bởi model.fit() . Bạn có thể lập biểu đồ của quá trình đào tạo và mất xác thực để so sánh, cũng như độ chính xác của quá trình đào tạo và xác nhận:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>

Trong biểu đồ này, các đường màu đỏ thể hiện sự mất mát trong quá trình huấn luyện và độ chính xác, còn các đường màu xanh là sự mất xác thực và độ chính xác.
Xuất để suy luận
Bây giờ bạn chỉ cần lưu mô hình đã tinh chỉnh của mình để sử dụng sau này.
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
Hãy tải lại mô hình, để bạn có thể thử song song với mô hình vẫn còn trong bộ nhớ.
reloaded_model = tf.saved_model.load(saved_model_path)
Tại đây, bạn có thể kiểm tra mô hình của mình trên bất kỳ câu nào bạn muốn, chỉ cần thêm vào biến ví dụ bên dưới.
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Nếu bạn muốn sử dụng mô hình của bạn trên TF Phục vụ , hãy nhớ rằng nó sẽ gọi SavedModel của bạn thông qua một trong những chữ ký tên của nó. Trong Python, bạn có thể kiểm tra chúng như sau:
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Bước tiếp theo
Bước tiếp theo, bạn có thể thử Giải quyết các nhiệm vụ KEO sử dụng Bert trên một hướng dẫn TPU , mà chạy trên một TPU và chương trình bạn làm thế nào để làm việc với nhiều đầu vào.