
Telif Hakkı 2021 TF-Agents Yazarları.
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Tanıtım
Bu örnek gösterir nasıl bir tren PEKİŞTİRMEK benzer TF-Ajanlar kütüphane kullanılarak Cartpole çevre üzerindeki ajan DQN öğretici .
Eğitim, değerlendirme ve veri toplama için Reinforcement Learning (RL) boru hattındaki tüm bileşenlerde size yol göstereceğiz.
Kurmak
Aşağıdaki bağımlılıkları yüklemediyseniz, çalıştırın:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
hiperparametreler
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
Çevre
RL'deki ortamlar, çözmeye çalıştığımız görevi veya sorunu temsil eder. Standart ortamlar kolayca kullanarak TF-Ajanlar oluşturulabilir suites . Farklı olan suites bir dize ortamı adı verilen, vb OpenAI Spor Salonu, Atari, DM Kontrol, gibi kaynaklardan ortamları yükleme için.
Şimdi CartPole ortamını OpenAI Gym paketinden yükleyelim.
env = suite_gym.load(env_name)
Nasıl göründüğünü görmek için bu ortamı oluşturabiliriz. Bir arabaya serbest sallanan bir direk bağlanmıştır. Amaç, direği yukarı bakacak şekilde tutmak için arabayı sağa veya sola hareket ettirmektir.
env.reset()
PIL.Image.fromarray(env.render())
time_step = environment.step(action) deyimi alır action ortamında. TimeStep döndü tanımlama grubu bu eylem için ortamın sonraki gözlem ve ödül içermektedir. time_step_spec() ve action_spec() ortamında yöntemler özelliklerini (tip, şekil, sınırları) geri time_step ve action sırasıyla.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Böylece, gözlemin 4 şamandıra dizisi olduğunu görüyoruz: arabanın konumu ve hızı ve direğin açısal konumu ve hızı. Sadece iki eylemleri (hareket sola veya sağa hareket) mümkün olduğundan, action_spec 0 vasıta "hareket sol" ve 1 araç bir skaler olan "hareket herkesi."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Genellikle iki ortam yaratırız: biri eğitim, diğeri değerlendirme için. Çoğu ortamlarda saf Python ile yazılmış, ancak bunlar kolayca kullanarak TensorFlow dönüştürülebilir TFPyEnvironment sargısı. Orijinal ortamın API numpy diziler kullanır TFPyEnvironment üzerine / bu dönüştürür Tensors TensorFlow politikaları ve ajanlarla daha kolay etkileşim sizin için.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Ajan
Biz RL sorunu çözmek için kullandığı algoritmanın bir şekilde temsil edilmektedir Agent . PEKİŞTİRMEK ajana ek olarak, TF-Ajanlar çeşitli standart uygulamaları sağlar Agents gibi DQN , DDPG , TD3 , PPO ve SAC .
Bir Ajan PEKİŞTİRMEK oluşturmak için öncelikle bir ihtiyaç Actor Network ortamından bir gözlem verilen eylemi tahmin etmek öğrenebilir.
Biz kolayca bir oluşturabilir Actor Network gözlemleri ve eylemlerin özelliklerini kullanarak. Bu örnekte, bir ağ katmanları belirtebilir fc_layer_params bir başlığın bağımsız değişken grubu ints her gizli tabakanın boyutları (yukarıda Hyperparameters bölümüne bakınız) temsil eder.
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
Biz de bir ihtiyaç optimizer önce oluşturduğumuz ağını eğitmek için ve train_step_counter ağ güncellendi kaç kez takip etmek için değişken.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
Politikalar
TF-Ajanlar olarak, politikaları RL içinde politikaların standart kavramını temsil: Belirli bir time_step bir eylem veya eylemleri üzerinde bir dağılım üretirler. Ana yöntem policy_step = policy.action(time_step) policy_step adlandırılmış başlık olur PolicyStep(action, state, info) . policy_step.action olan action ortamına tatbik edilecek, state durum bilgisi (GSA) politika ve için durumunu temsil eden info , örneğin eylemleri kaydı olasılıkları gibi yardımcı bilgi içerebilir.
Aracılar iki ilke içerir: değerlendirme/dağıtım için kullanılan ana ilke (agent.policy) ve veri toplama için kullanılan başka bir ilke (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
Metrikler ve Değerlendirme
Bir politikayı değerlendirmek için kullanılan en yaygın ölçüm ortalama getiridir. Geri dönüş, bir bölümde bir ortamda bir ilke çalıştırırken elde edilen ödüllerin toplamıdır ve genellikle bunun ortalamasını birkaç bölüm üzerinden alırız. Ortalama getiri metriğini aşağıdaki gibi hesaplayabiliriz.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
Tekrar arabelleği
Çevreden toplanan verilerin takip etmek amacıyla, kullanacağı Reverb , Deepmind etkin, genişletilebilir ve kolay kullanımlı yeniden oynatma sistemi. Yörüngeleri topladığımızda deneyim verilerini depolar ve eğitim sırasında tüketilir.
Bu tekrar tamponu kullanılarak maddesi elde edilebilir depolanacaksa tensörü tarif gözlük kullanılarak inşa edilir tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
En maddeleri için, collect_data_spec a, Trajectory gözlem, işlem içeren demet adı, vs. ödül
Veri toplama
REINFORCE tüm bölümlerden öğrendiği için, verilen veri toplama politikasını kullanarak bir bölüm toplamak ve verileri (gözlemler, eylemler, ödüller vb.) tekrar arabelleğinde yörüngeler olarak kaydetmek için bir işlev tanımlarız. Burada deneyim toplama döngüsünü çalıştırmak için 'PyDriver' kullanıyoruz. Bizim daha TF Ajanlar sürücüsü hakkında bilgi edinebilirsiniz sürücüler öğretici .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
Temsilciyi eğitmek
Eğitim döngüsü, hem ortamdan veri toplamayı hem de aracının ağlarını optimize etmeyi içerir. Yol boyunca, nasıl yaptığımızı görmek için ara sıra temsilcinin politikasını değerlendireceğiz.
Aşağıdakilerin çalışması ~ 3 dakika sürecektir.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
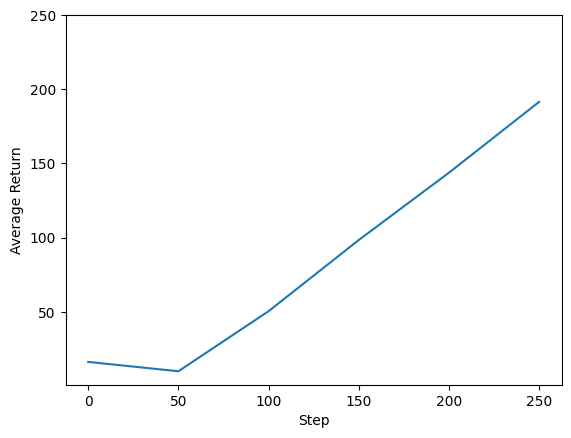
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
görselleştirme
araziler
Temsilcimizin performansını görmek için geri dönüş ve küresel adımların grafiğini çizebiliriz. In Cartpole-v0 , çevre her zaman adımı için kutup kalır +1 bir ödül yukarı verir ve adımların sayısı en fazla 200 olduğundan, mümkün olan maksimum getiri de 200'dür.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
Videolar
Her adımda ortamı işleyerek bir aracının performansını görselleştirmek yararlıdır. Bunu yapmadan önce, videoları bu ortak çalışmaya gömmek için bir fonksiyon oluşturalım.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Aşağıdaki kod, aracının birkaç bölüm için politikasını görselleştirir:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss