
Beberapa tahun terakhir telah melihat peningkatan lapisan grafis terdiferensiasi baru yang dapat dimasukkan ke dalam arsitektur jaringan saraf. Dari trafo spasial hingga perender grafis yang dapat dibedakan, lapisan baru ini memanfaatkan pengetahuan yang diperoleh selama bertahun-tahun melalui visi komputer dan penelitian grafis untuk membangun arsitektur jaringan yang baru dan lebih efisien. Pemodelan prioritas geometris dan batasan secara eksplisit ke dalam jaringan saraf membuka pintu ke arsitektur yang dapat dilatih dengan kuat, efisien, dan yang lebih penting, dengan cara yang diawasi sendiri.
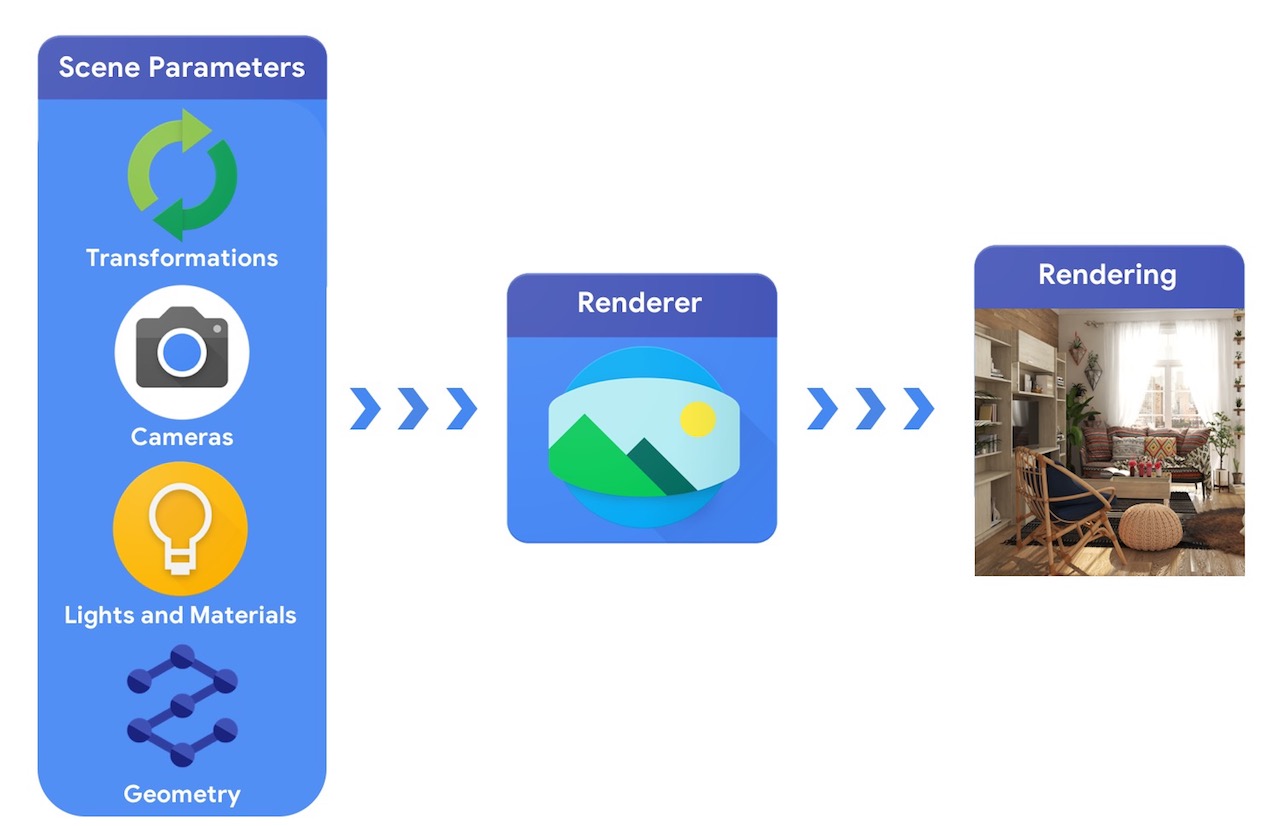
Pada tingkat tinggi, pipa grafik komputer membutuhkan representasi objek 3D dan posisi absolutnya di tempat kejadian, deskripsi bahan pembuatnya, lampu, dan kamera. Deskripsi adegan ini kemudian ditafsirkan oleh perender untuk menghasilkan rendering sintetis.
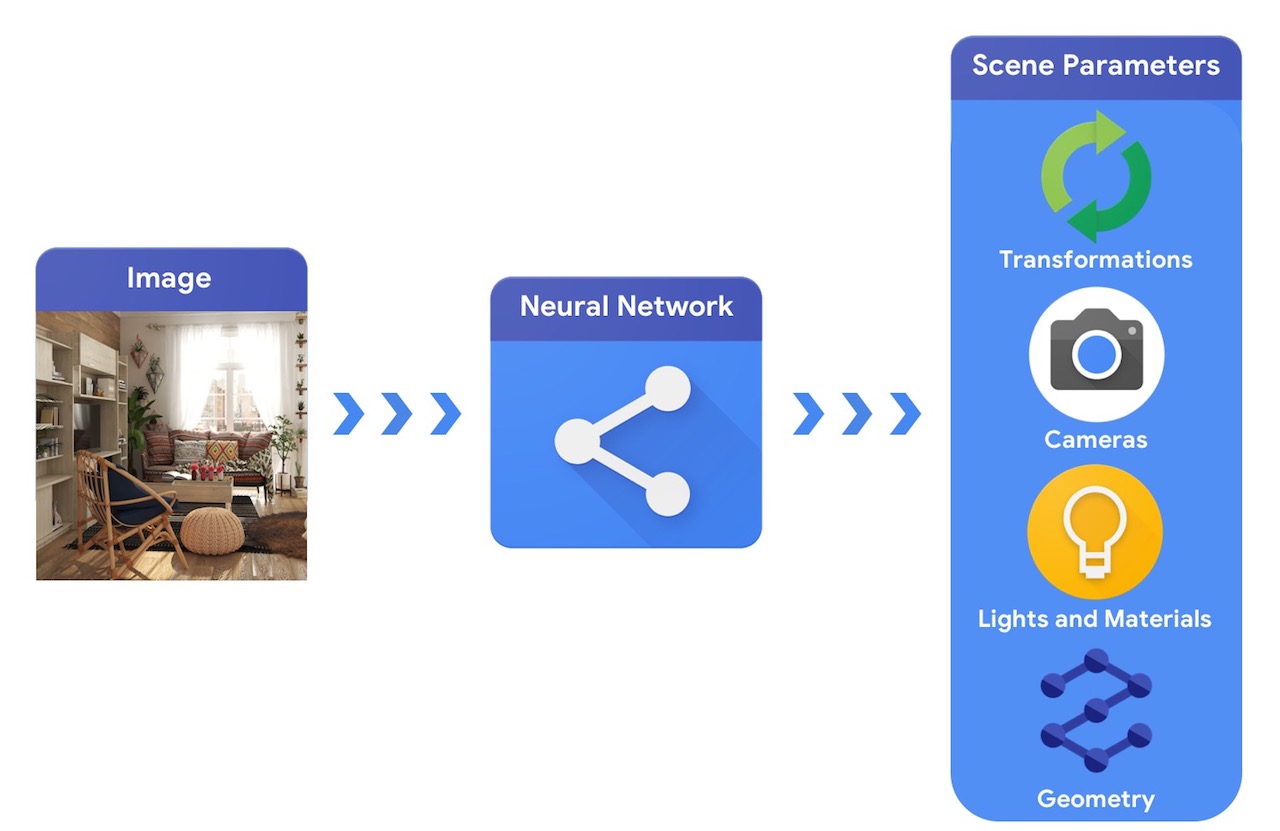
Sebagai perbandingan, sistem visi komputer akan mulai dari gambar dan mencoba menyimpulkan parameter pemandangan. Hal ini memungkinkan prediksi objek mana yang ada di tempat kejadian, bahan apa yang dibuat, dan posisi serta orientasi tiga dimensi.
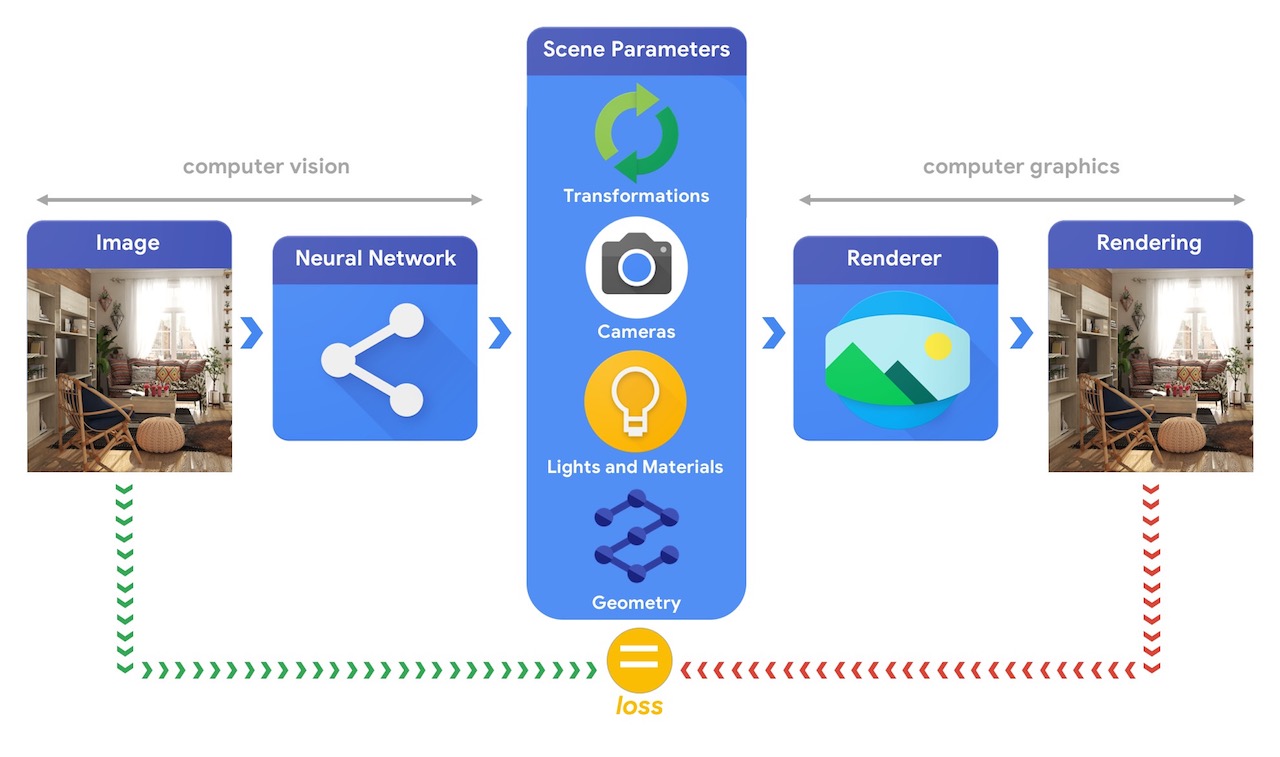
Melatih sistem pembelajaran mesin yang mampu menyelesaikan tugas penglihatan 3D yang kompleks ini paling sering membutuhkan data dalam jumlah besar. Karena pelabelan data adalah proses yang mahal dan kompleks, penting untuk memiliki mekanisme untuk merancang model pembelajaran mesin yang dapat memahami dunia tiga dimensi sambil dilatih tanpa banyak pengawasan. Menggabungkan visi komputer dan teknik grafik komputer memberikan peluang unik untuk memanfaatkan sejumlah besar data tak berlabel yang tersedia. Seperti yang diilustrasikan pada gambar di bawah, ini dapat, misalnya, dicapai dengan menggunakan analisis dengan sintesis di mana sistem visi mengekstrak parameter pemandangan dan sistem grafis menampilkan kembali gambar berdasarkan parameter tersebut. Jika rendering cocok dengan gambar asli, sistem penglihatan telah mengekstrak parameter pemandangan secara akurat. Dalam pengaturan ini, visi komputer dan grafik komputer berjalan beriringan, membentuk sistem pembelajaran mesin tunggal yang mirip dengan autoencoder, yang dapat dilatih dengan cara yang diawasi sendiri.
Tensorflow Graphics sedang dikembangkan untuk membantu mengatasi jenis tantangan ini dan untuk melakukannya, Tensorflow Graphics menyediakan serangkaian lapisan grafis dan geometri yang dapat dibedakan (misalnya kamera, model reflektansi, transformasi spasial, konvolusi mesh) dan fungsionalitas penampil 3D (misalnya 3D TensorBoard) yang dapat digunakan untuk melatih dan men-debug model pembelajaran mesin pilihan Anda.