
지난 몇 년 동안 신경망 아키텍처에 삽입할 수 있는 차별화 가능한 새로운 그래픽 레이어가 늘어났습니다. 공간 변환기에서 차별화 가능한 그래픽 렌더러에 이르기까지 이들 새로운 레이어는 수년간의 컴퓨터 비전 및 그래픽 연구에서 얻은 지식을 활용하여 새롭고 보다 효율적인 네트워크 아키텍처를 빌드합니다. 기하학적 형태 및 제약 조건을 신경망에 명시적으로 모델링하면 강력하고 효율적이며, 무엇보다도 자가 감독 방식으로 학습할 수 있는 아키텍처의 문이 열리게 됩니다.
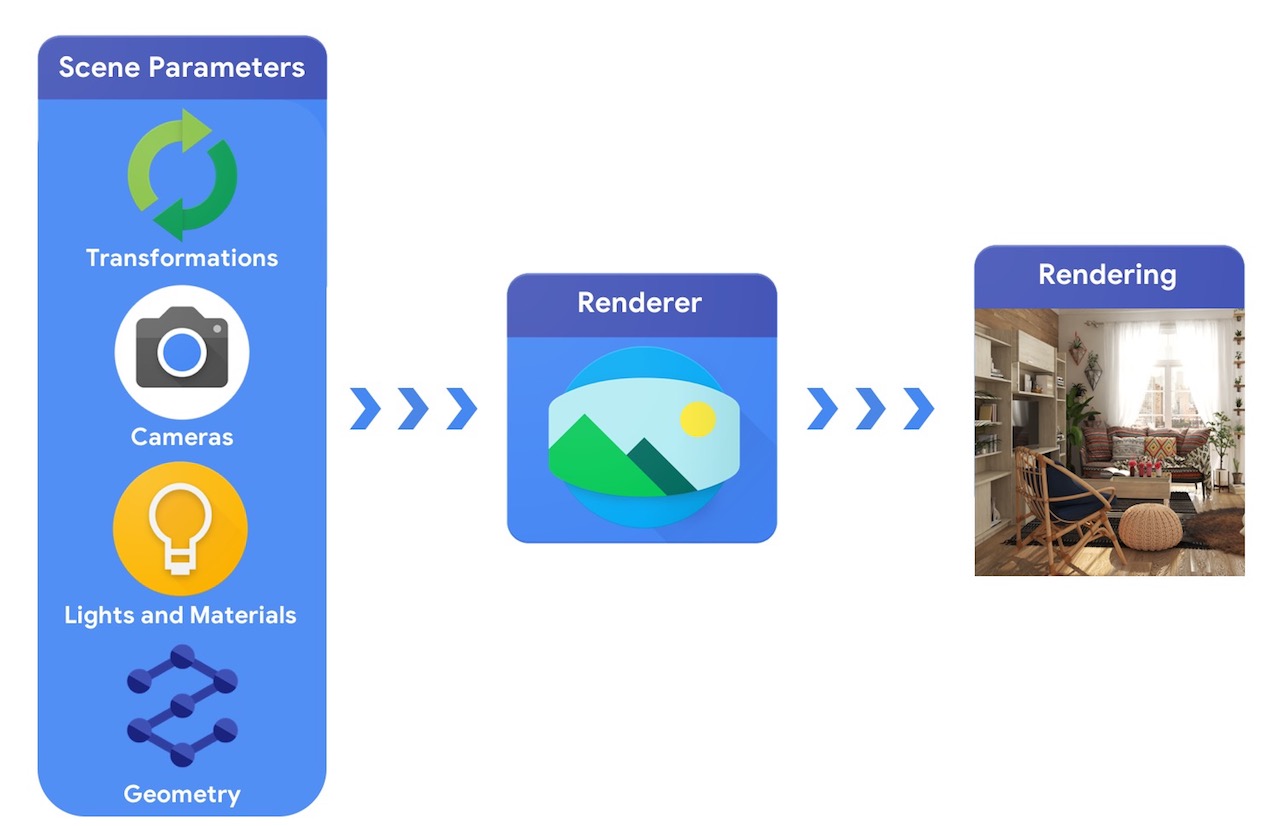
상위 수준에서 컴퓨터 그래픽 파이프라인은 3D 객체의 표현과 장면에서의 절대 위치, 해당 개체가 만들어진 재료에 대한 설명, 조명 및 카메라가 필요합니다. 그런 다음 이 장면 설명은 합성 렌더링을 생성하기 위해 렌더러에 의해 해석됩니다.
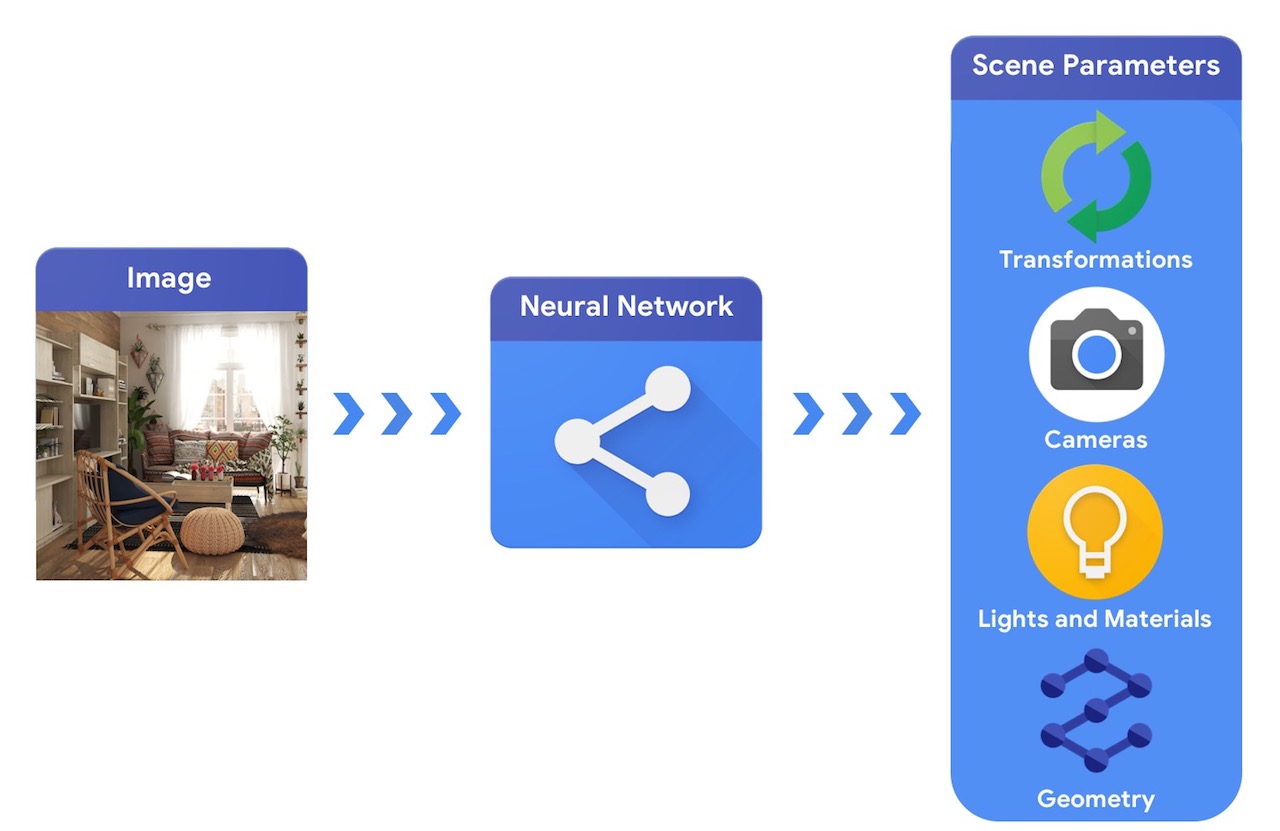
이에 비해 컴퓨터 비전 시스템은 이미지에서 시작하여 장면의 매개변수를 추론하려고 합니다. 이를 통해 장면에 있는 객체, 재질, 3차원 위치 및 방향을 예측할 수 있습니다.
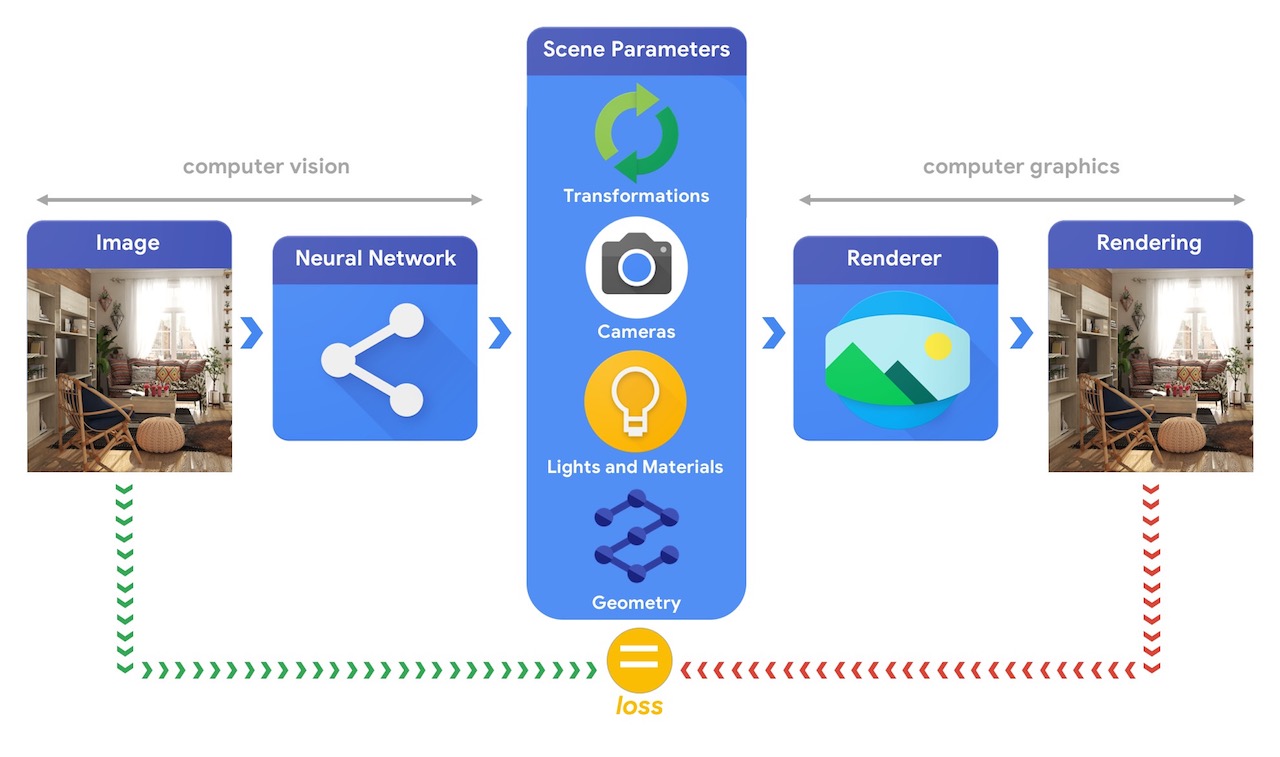
이러한 복잡한 3D 비전 작업을 해결할 수 있는 머신러닝 시스템을 훈련하려면 대개 많은 양의 데이터가 필요합니다. 데이터에 레이블을 지정하는 것은 비용이 많이 들고 복잡한 프로세스이므로 별다른 감독 없이 훈련을 받으면서 3차원 세계를 이해할 수 있는 머신러닝 모델을 설계하는 메커니즘을 갖는 것이 중요합니다. 컴퓨터 비전과 컴퓨터 그래픽 기술을 결합하면 레이블이 지정되지 않은 방대한 양의 데이터를 쉽게 활용할 수 있습니다. 예를 들어, 아래 이미지에서 볼 수 있듯이, 비전 시스템이 장면 매개변수를 추출하고 그래픽 시스템이 이를 기반으로 이미지를 다시 렌더링하는 합성 분석을 사용하여 달성할 수 있습니다. 렌더링이 원본 이미지와 일치하면 비전 시스템이 장면 매개변수를 정확하게 추출한 것입니다. 이 설정에서는 컴퓨터 비전과 컴퓨터 그래픽이 함께 사용되어 autoencoder와 유사한 단일 머신러닝 시스템을 형성하며 자가 감독 방식으로 학습할 수 있습니다.
Tensorflow Graphics는 이러한 유형의 문제를 해결하기 위해 개발되고 있으며, 선택한 머신러닝 모델을 훈련하고 디버그하는 데 사용할 수 있는 차별화 가능한 그래픽 및 지오메트리 레이어(예: 카메라, 반사 모델, 공간 변환, 메시 컨볼루션) 및 3D 뷰어 기능(예: 3D TensorBoard)을 제공합니다.