
| | |  Voir sur GitHub Voir sur GitHub | |
Ce Colab est une démonstration de l' utilisation de Hub tensorflow pour la classification des textes dans les langues non anglais / locales. Ici , nous choisissons Bangla comme langue locale et l' utilisation de mots incorporations pour résoudre pré - entraîné une tâche de classification multiclassent où nous classons articles de presse Bangla dans 5 catégories. Les incorporations pour Bangla vient pré - entraîné de FastText qui est une bibliothèque par Facebook avec des vecteurs libérés de mots pour 157 langues pré - entraîné.
Nous allons utiliser l'exportateur de l' intégration TF-pré - entraîné Hub pour convertir le mot plongement à un module intégrant texte, puis utilisez le module pour former un classificateur avec tf.keras , utilisateur haut niveau de tensorflow API conviviale pour construire des modèles d'apprentissage en profondeur. Même si nous utilisons ici des intégrations fastText, il est possible d'exporter d'autres intégrations pré-entraînées à partir d'autres tâches et d'obtenir rapidement des résultats avec le hub Tensorflow.
Installer
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Base de données
Nous utiliserons BARD (Bangla article Dataset) qui a environ 376226 articles collectés de différents portails d'information Bangla et étiquetés avec 5 catégories: économie, Etat, international, sports et divertissement. Nous télécharger le fichier de Google Drive ce ( bit.ly/BARD_DATASET lien) fait référence à partir de ce référentiel GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Exporter des vecteurs de mots pré-entraînés vers le module TF-Hub
TF-Hub fournit quelques scripts utiles pour convertir mot incorporations aux modules de plongement texte TF-hub ici . Pour le module de Bangla ou toute autre langue, nous avons simplement télécharger le mot intégration .txt ou .vec fichier dans le même répertoire que export_v2.py et exécutez le script.
L'exportateur lit les vecteurs qu'il exporte vers l' enrobage et un tensorflow SavedModel . Un SavedModel contient un programme TensorFlow complet comprenant des poids et un graphique. TF-Hub peut charger le SavedModel comme le module , que nous utiliserons pour construire le modèle de classification de texte. Puisque nous utilisons tf.keras pour construire le modèle, nous utiliserons hub.KerasLayer , qui fournit une enveloppe pour un module TF-Hub à utiliser comme couche Keras.
D' abord , nous aurons notre mot incorporations de FastText et exportateur de l' intégration TF-Hub repo .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Ensuite, nous exécuterons le script d'exportation sur notre fichier d'intégration. Étant donné que les intégrations fastText ont une ligne d'en-tête et sont assez volumineuses (environ 3,3 Go pour Bangla après la conversion en module), nous ignorons la première ligne et exportons uniquement les 100 000 premiers jetons vers le module d'intégration de texte.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
Le module d'incorporation de texte prend un lot de phrases dans un tenseur de chaînes 1D en entrée et génère les vecteurs de forme d'incorporation (batch_size, embedding_dim) correspondant aux phrases. Il prétraite l'entrée en divisant sur des espaces. Incorporations Word sont combinés pour incorporations phrase avec le sqrtn combinateur (Voir ici ). Pour la démonstration, nous passons une liste de mots Bangla en entrée et obtenons les vecteurs d'intégration correspondants.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Convertir en ensemble de données Tensorflow
Étant donné que l'ensemble de données est vraiment grand au lieu de charger l'ensemble de ces données dans la mémoire , nous allons utiliser un générateur pour produire des échantillons en exécution par lots en utilisant tensorflow Dataset fonctions. L'ensemble de données est également très déséquilibré, donc, avant d'utiliser le générateur, nous allons mélanger l'ensemble de données.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Nous pouvons vérifier la répartition des étiquettes dans les exemples d'apprentissage et de validation après le brassage.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
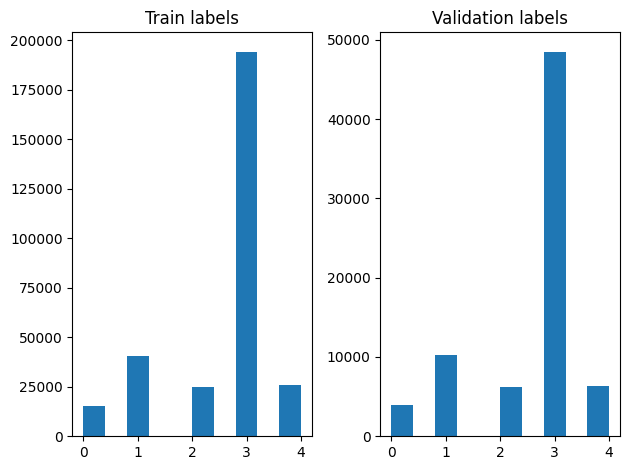
Pour créer un DataSet en utilisant un générateur, nous avons d' abord écrire une fonction de générateur qui lit chacun des articles de file_paths et les étiquettes de la gamme d'étiquettes, et les rendements un exemple de formation à chaque étape. Nous passons cette fonction de générateur à la tf.data.Dataset.from_generator méthode et spécifier les types de sortie. Chaque exemple de formation est un tuple contenant un article de tf.string type de données et une étiquette codée à chaud. Nous avons divisé l'ensemble de données avec une scission train validation de 80-20 à l' aide tf.data.Dataset.skip et tf.data.Dataset.take méthodes.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Formation et évaluation du modèle
Étant donné que nous avons déjà ajouté une enveloppe autour de notre module pour l' utiliser comme toute autre couche Keras, nous pouvons créer un petit séquentiel modèle qui est une pile linéaire de couches. Nous pouvons ajouter notre module intégration de texte avec model.add comme toute autre couche. Nous compilons le modèle en spécifiant la perte et l'optimiseur et l'entraînons pour 10 époques. L' tf.keras API peut gérer tensorflow datasets en entrée, afin que nous puissions passer une instance Dataset à la méthode d' ajustement pour la formation du modèle. Puisque nous utilisons la fonction génératrice, tf.data se chargera de générer les échantillons, les batches et les nourrir au modèle.
Modèle
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Entraînement
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Évaluation
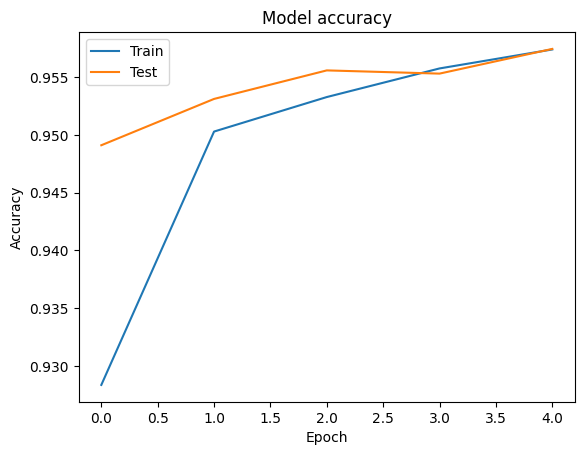
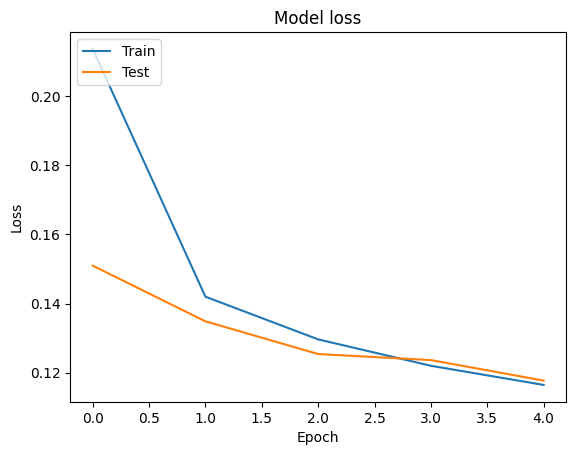
On peut visualiser les courbes de précision et de perte de données de formation et de validation à l' aide de l' tf.keras.callbacks.History objet retourné par la tf.keras.Model.fit méthode, qui contient la valeur de la perte et de précision pour chaque époque.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Prédiction
Nous pouvons obtenir les prédictions pour les données de validation et vérifier la matrice de confusion pour voir les performances du modèle pour chacune des 5 classes. Parce que tf.keras.Model.predict méthode retourne un tableau e des probabilités pour chaque classe, ils peuvent être convertis en étiquettes de classe en utilisant np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Comparez les performances
Maintenant , nous pouvons prendre les bonnes étiquettes pour les données de validation d' labels et de les comparer avec nos prévisions pour obtenir un classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Nous pouvons également comparer les performances de notre modèle avec les résultats publiés obtenus dans l'original papier , qui avait une 0.96 précision .Les auteurs originaux ont décrit de nombreuses étapes de prétraitement effectuées sur l'ensemble de données, telles que la suppression ponctuations et chiffres, la suppression top 25 la plupart fRequest mots d'arrêt. Comme on peut le voir dans le classification_report , nous gérons également d'obtenir une précision et une précision 0,96 après la formation pour seulement 5 époques sans pré - traitement!
Dans cet exemple, lorsque nous avons créé la couche Keras de notre module d'intégration, nous avons mis le paramètre trainable=False , ce qui signifie que les poids ne seront pas d' enrobage mis à jour lors de la formation. Essayez de régler à True pour atteindre environ 97% en utilisant la précision cet ensemble de données après seulement deux époques.