
| | |  Voir sur GitHub Voir sur GitHub | | |
Le CORD-19 Module intégration texte pivotant de TF-Hub ( https://tfhub.dev/tensorflow/cord-19/swivel-128d/1 ) a été conçu pour appuyer les chercheurs qui analysent le texte des langues naturelles liées à Covid-19. Ces incorporations ont été formés sur les titres, auteurs, résumés, textes du corps, et les titres de référence des articles dans le jeu de données CORD-19 .
Dans cette collaboration, nous allons :
- Analyser les mots sémantiquement similaires dans l'espace d'inclusion
- Former un classificateur sur l'ensemble de données SciCite à l'aide des plongements CORD-19
Installer
import functools
import itertools
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd
import tensorflow.compat.v1 as tf
tf.disable_eager_execution()
tf.logging.set_verbosity('ERROR')
import tensorflow_datasets as tfds
import tensorflow_hub as hub
try:
from google.colab import data_table
def display_df(df):
return data_table.DataTable(df, include_index=False)
except ModuleNotFoundError:
# If google-colab is not available, just display the raw DataFrame
def display_df(df):
return df
Analyser les encastrements
Commençons par analyser le plongement en calculant et en traçant une matrice de corrélation entre différents termes. Si l'intégration a appris à capturer avec succès le sens de différents mots, les vecteurs d'intégration de mots sémantiquement similaires doivent être proches les uns des autres. Jetons un coup d'œil à quelques termes liés à COVID-19.
# Use the inner product between two embedding vectors as the similarity measure
def plot_correlation(labels, features):
corr = np.inner(features, features)
corr /= np.max(corr)
sns.heatmap(corr, xticklabels=labels, yticklabels=labels)
with tf.Graph().as_default():
# Load the module
query_input = tf.placeholder(tf.string)
module = hub.Module('https://tfhub.dev/tensorflow/cord-19/swivel-128d/1')
embeddings = module(query_input)
with tf.train.MonitoredTrainingSession() as sess:
# Generate embeddings for some terms
queries = [
# Related viruses
"coronavirus", "SARS", "MERS",
# Regions
"Italy", "Spain", "Europe",
# Symptoms
"cough", "fever", "throat"
]
features = sess.run(embeddings, feed_dict={query_input: queries})
plot_correlation(queries, features)
2021-11-05 11:36:25.521420: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions.
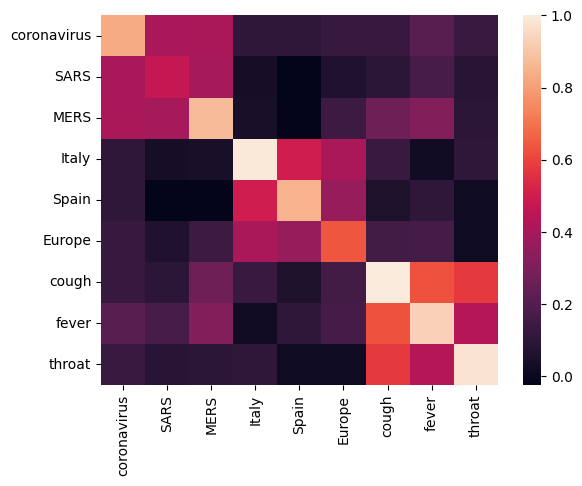
Nous pouvons voir que l'intégration a réussi à capturer le sens des différents termes. Chaque mot est similaire aux autres mots de son groupe (c. proche de 0).
Voyons maintenant comment nous pouvons utiliser ces intégrations pour résoudre une tâche spécifique.
SciCite : classification des intentions de citation
Cette section montre comment utiliser l'intégration pour des tâches en aval telles que la classification de texte. Nous allons utiliser l' ensemble de données SciCite de tensorflow datasets pour classer les intentions de citation dans les journaux académiques. À partir d'une phrase avec une citation d'un article universitaire, indiquez si l'intention principale de la citation est une information de base, l'utilisation de méthodes ou la comparaison de résultats.
Configurer l'ensemble de données à partir de TFDS
class Dataset:
"""Build a dataset from a TFDS dataset."""
def __init__(self, tfds_name, feature_name, label_name):
self.dataset_builder = tfds.builder(tfds_name)
self.dataset_builder.download_and_prepare()
self.feature_name = feature_name
self.label_name = label_name
def get_data(self, for_eval):
splits = THE_DATASET.dataset_builder.info.splits
if tfds.Split.TEST in splits:
split = tfds.Split.TEST if for_eval else tfds.Split.TRAIN
else:
SPLIT_PERCENT = 80
split = "train[{}%:]".format(SPLIT_PERCENT) if for_eval else "train[:{}%]".format(SPLIT_PERCENT)
return self.dataset_builder.as_dataset(split=split)
def num_classes(self):
return self.dataset_builder.info.features[self.label_name].num_classes
def class_names(self):
return self.dataset_builder.info.features[self.label_name].names
def preprocess_fn(self, data):
return data[self.feature_name], data[self.label_name]
def example_fn(self, data):
feature, label = self.preprocess_fn(data)
return {'feature': feature, 'label': label}, label
def get_example_data(dataset, num_examples, **data_kw):
"""Show example data"""
with tf.Session() as sess:
batched_ds = dataset.get_data(**data_kw).take(num_examples).map(dataset.preprocess_fn).batch(num_examples)
it = tf.data.make_one_shot_iterator(batched_ds).get_next()
data = sess.run(it)
return data
TFDS_NAME = 'scicite'
TEXT_FEATURE_NAME = 'string'
LABEL_NAME = 'label'
THE_DATASET = Dataset(TFDS_NAME, TEXT_FEATURE_NAME, LABEL_NAME)
Jetons un coup d'œil à quelques exemples étiquetés de l'ensemble de formation
NUM_EXAMPLES = 20
data = get_example_data(THE_DATASET, NUM_EXAMPLES, for_eval=False)
display_df(
pd.DataFrame({
TEXT_FEATURE_NAME: [ex.decode('utf8') for ex in data[0]],
LABEL_NAME: [THE_DATASET.class_names()[x] for x in data[1]]
}))
Formation d'un classificateur d'intention citaton
Nous allons former un classificateur sur l' ensemble de données SciCite à l' aide d' un estimateur. Configurons input_fns pour lire l'ensemble de données dans le modèle
def preprocessed_input_fn(for_eval):
data = THE_DATASET.get_data(for_eval=for_eval)
data = data.map(THE_DATASET.example_fn, num_parallel_calls=1)
return data
def input_fn_train(params):
data = preprocessed_input_fn(for_eval=False)
data = data.repeat(None)
data = data.shuffle(1024)
data = data.batch(batch_size=params['batch_size'])
return data
def input_fn_eval(params):
data = preprocessed_input_fn(for_eval=True)
data = data.repeat(1)
data = data.batch(batch_size=params['batch_size'])
return data
def input_fn_predict(params):
data = preprocessed_input_fn(for_eval=True)
data = data.batch(batch_size=params['batch_size'])
return data
Construisons un modèle qui utilise les plongements CORD-19 avec une couche de classification au-dessus.
def model_fn(features, labels, mode, params):
# Embed the text
embed = hub.Module(params['module_name'], trainable=params['trainable_module'])
embeddings = embed(features['feature'])
# Add a linear layer on top
logits = tf.layers.dense(
embeddings, units=THE_DATASET.num_classes(), activation=None)
predictions = tf.argmax(input=logits, axis=1)
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(
mode=mode,
predictions={
'logits': logits,
'predictions': predictions,
'features': features['feature'],
'labels': features['label']
})
# Set up a multi-class classification head
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=labels, logits=logits)
loss = tf.reduce_mean(loss)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=params['learning_rate'])
train_op = optimizer.minimize(loss, global_step=tf.train.get_or_create_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
elif mode == tf.estimator.ModeKeys.EVAL:
accuracy = tf.metrics.accuracy(labels=labels, predictions=predictions)
precision = tf.metrics.precision(labels=labels, predictions=predictions)
recall = tf.metrics.recall(labels=labels, predictions=predictions)
return tf.estimator.EstimatorSpec(
mode=mode,
loss=loss,
eval_metric_ops={
'accuracy': accuracy,
'precision': precision,
'recall': recall,
})
Hyperparamètres
EMBEDDING = 'https://tfhub.dev/tensorflow/cord-19/swivel-128d/1'
TRAINABLE_MODULE = False
STEPS = 8000
EVAL_EVERY = 200
BATCH_SIZE = 10
LEARNING_RATE = 0.01
params = {
'batch_size': BATCH_SIZE,
'learning_rate': LEARNING_RATE,
'module_name': EMBEDDING,
'trainable_module': TRAINABLE_MODULE
}
Former et évaluer le modèle
Entraînons et évaluons le modèle pour voir les performances sur la tâche SciCite
estimator = tf.estimator.Estimator(functools.partial(model_fn, params=params))
metrics = []
for step in range(0, STEPS, EVAL_EVERY):
estimator.train(input_fn=functools.partial(input_fn_train, params=params), steps=EVAL_EVERY)
step_metrics = estimator.evaluate(input_fn=functools.partial(input_fn_eval, params=params))
print('Global step {}: loss {:.3f}, accuracy {:.3f}'.format(step, step_metrics['loss'], step_metrics['accuracy']))
metrics.append(step_metrics)
2021-11-05 11:36:35.089196: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:8: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead. /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/legacy_tf_layers/core.py:255: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead. return layer.apply(inputs) 2021-11-05 11:36:37.257679: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 0: loss 0.795, accuracy 0.683 2021-11-05 11:36:39.963864: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:36:42.567978: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 200: loss 0.720, accuracy 0.725 2021-11-05 11:36:44.412196: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:36:46.167367: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 400: loss 0.685, accuracy 0.735 2021-11-05 11:36:47.454541: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:36:49.859524: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 600: loss 0.657, accuracy 0.743 2021-11-05 11:36:51.159394: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:36:52.973479: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 800: loss 0.628, accuracy 0.766 2021-11-05 11:36:54.272092: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:36:56.197500: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 1000: loss 0.612, accuracy 0.771 2021-11-05 11:36:57.712701: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:36:59.448515: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 1200: loss 0.597, accuracy 0.776 2021-11-05 11:37:00.731476: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:02.656841: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 1400: loss 0.590, accuracy 0.779 2021-11-05 11:37:03.997415: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:05.749426: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 1600: loss 0.590, accuracy 0.779 2021-11-05 11:37:07.015652: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:08.900851: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 1800: loss 0.578, accuracy 0.779 2021-11-05 11:37:10.373800: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:12.102286: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 2000: loss 0.587, accuracy 0.773 2021-11-05 11:37:13.767595: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:15.731627: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 2200: loss 0.573, accuracy 0.785 2021-11-05 11:37:17.022574: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:18.746940: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 2400: loss 0.566, accuracy 0.785 2021-11-05 11:37:20.026853: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:21.980533: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 2600: loss 0.575, accuracy 0.775 2021-11-05 11:37:23.273076: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:25.039058: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 2800: loss 0.563, accuracy 0.782 2021-11-05 11:37:26.531677: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:28.482071: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 3000: loss 0.566, accuracy 0.783 2021-11-05 11:37:29.764582: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:31.474578: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 3200: loss 0.560, accuracy 0.784 2021-11-05 11:37:32.745235: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:34.614998: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 3400: loss 0.561, accuracy 0.781 2021-11-05 11:37:35.899823: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:37.566025: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 3600: loss 0.551, accuracy 0.789 2021-11-05 11:37:39.015831: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:40.902011: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 3800: loss 0.552, accuracy 0.783 2021-11-05 11:37:42.175585: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:43.887723: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 4000: loss 0.560, accuracy 0.779 2021-11-05 11:37:45.190449: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:47.072682: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 4200: loss 0.547, accuracy 0.790 2021-11-05 11:37:48.363401: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:50.068385: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 4400: loss 0.558, accuracy 0.781 2021-11-05 11:37:51.357653: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:53.266687: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 4600: loss 0.548, accuracy 0.787 2021-11-05 11:37:54.746584: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:56.482845: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 4800: loss 0.541, accuracy 0.792 2021-11-05 11:37:57.753726: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:37:59.675499: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 5000: loss 0.546, accuracy 0.784 2021-11-05 11:38:00.956026: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:02.706523: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 5200: loss 0.539, accuracy 0.790 2021-11-05 11:38:03.991646: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:05.864592: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 5400: loss 0.540, accuracy 0.788 2021-11-05 11:38:07.325910: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:09.053490: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 5600: loss 0.544, accuracy 0.785 2021-11-05 11:38:10.336937: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:12.242602: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 5800: loss 0.539, accuracy 0.790 2021-11-05 11:38:13.523562: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:15.234561: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 6000: loss 0.544, accuracy 0.788 2021-11-05 11:38:16.496935: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:18.398152: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 6200: loss 0.536, accuracy 0.789 2021-11-05 11:38:19.665205: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:21.576480: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 6400: loss 0.537, accuracy 0.788 2021-11-05 11:38:22.862922: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:24.759211: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 6600: loss 0.544, accuracy 0.790 2021-11-05 11:38:26.042820: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:27.790787: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 6800: loss 0.539, accuracy 0.784 2021-11-05 11:38:29.061025: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:30.972826: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 7000: loss 0.539, accuracy 0.788 2021-11-05 11:38:32.280235: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:34.021577: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 7200: loss 0.536, accuracy 0.784 2021-11-05 11:38:35.536367: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:37.468553: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 7400: loss 0.534, accuracy 0.785 2021-11-05 11:38:38.732636: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:40.459254: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 7600: loss 0.535, accuracy 0.784 2021-11-05 11:38:41.727159: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. 2021-11-05 11:38:43.631400: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. Global step 7800: loss 0.539, accuracy 0.788
global_steps = [x['global_step'] for x in metrics]
fig, axes = plt.subplots(ncols=2, figsize=(20,8))
for axes_index, metric_names in enumerate([['accuracy', 'precision', 'recall'],
['loss']]):
for metric_name in metric_names:
axes[axes_index].plot(global_steps, [x[metric_name] for x in metrics], label=metric_name)
axes[axes_index].legend()
axes[axes_index].set_xlabel("Global Step")
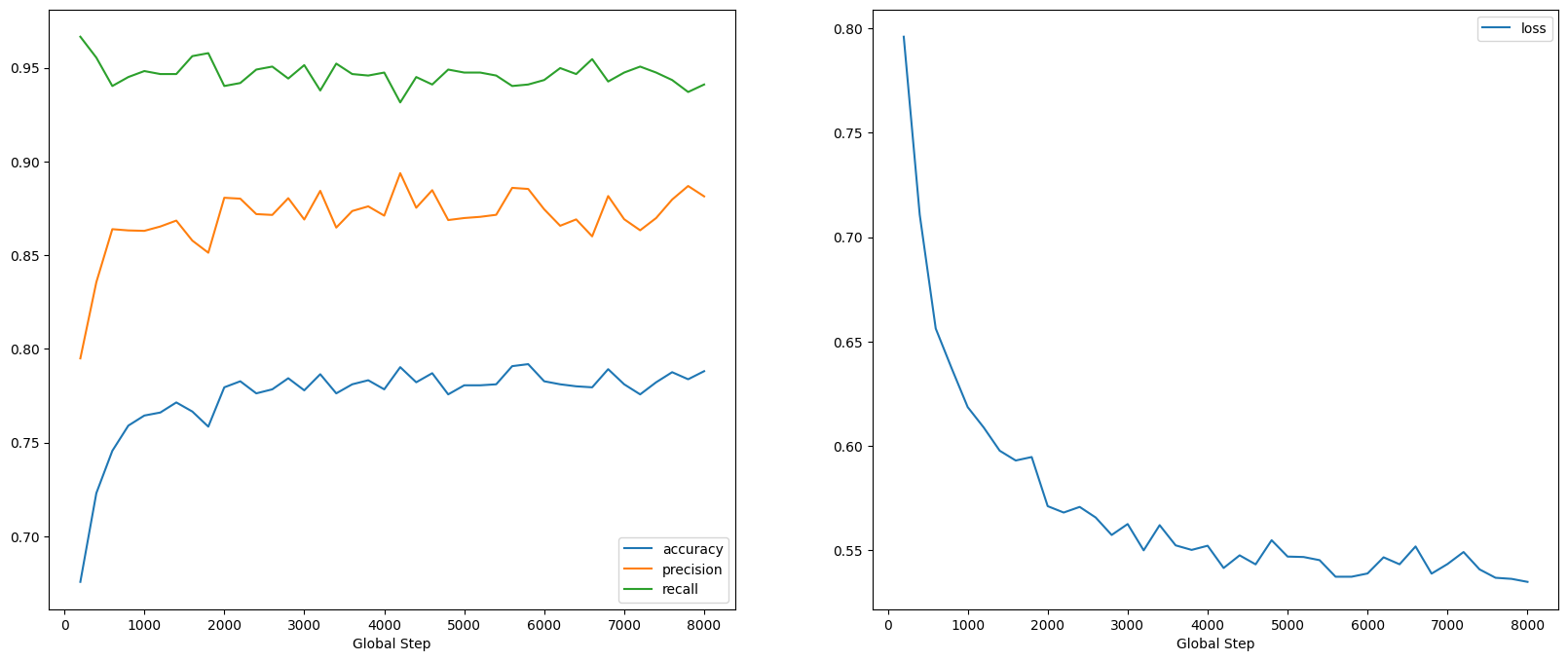
On peut voir que la perte diminue rapidement tandis que surtout la précision augmente rapidement. Traçons quelques exemples pour vérifier comment la prédiction se rapporte aux vraies étiquettes :
predictions = estimator.predict(functools.partial(input_fn_predict, params))
first_10_predictions = list(itertools.islice(predictions, 10))
display_df(
pd.DataFrame({
TEXT_FEATURE_NAME: [pred['features'].decode('utf8') for pred in first_10_predictions],
LABEL_NAME: [THE_DATASET.class_names()[pred['labels']] for pred in first_10_predictions],
'prediction': [THE_DATASET.class_names()[pred['predictions']] for pred in first_10_predictions]
}))
2021-11-05 11:38:45.219327: W tensorflow/core/common_runtime/graph_constructor.cc:1511] Importing a graph with a lower producer version 27 into an existing graph with producer version 898. Shape inference will have run different parts of the graph with different producer versions. /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:8: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.
Nous pouvons voir que pour cet échantillon aléatoire, le modèle prédit la bonne étiquette la plupart du temps, indiquant qu'il peut assez bien intégrer des phrases scientifiques.
Et après?
Maintenant que vous en savez un peu plus sur les encastrements CORD-19 Swivel de TF-Hub, nous vous encourageons à participer au concours CORD-19 Kaggle pour contribuer à acquérir des connaissances scientifiques à partir de textes académiques liés à COVID-19.
- Participer à la CORD-19 Kaggle Défi
- En savoir plus sur le Covid-19 Recherche ouverte Dataset (CORD-19)
- Voir la documentation et plus sur les incorporations TF-Hub à https://tfhub.dev/tensorflow/cord-19/swivel-128d/1
- Explorez l'espace plongement CORD-19 avec le tensorflow Embedding projecteur