| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
L'un des plus grands défis de la reconnaissance vocale automatique est la préparation et l'augmentation des données audio. L'analyse des données audio peut être dans le domaine temporel ou fréquentiel, ce qui ajoute une complexité supplémentaire par rapport à d'autres sources de données telles que les images.
En tant que partie de l'écosystème de tensorflow, tensorflow-io paquet fournit un bon nombre d' API liées audio-utiles qui aide à l' assouplissement de la préparation et l' augmentation des données audio.
Installer
Installez les packages requis et redémarrez le runtime
pip install tensorflow-io
Usage
Lire un fichier audio
Dans tensorflow IO, classe tfio.audio.AudioIOTensor vous permet de lire un fichier audio dans un paresseux chargé IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
Dans l'exemple ci - dessus, le fichier Flac brooklyn.flac est d'un clip audio accessible au public en nuage Google .
L'adresse GCS gs://cloud-samples-tests/speech/brooklyn.flac sont directement utilisés parce GCS est un système de fichiers pris en charge dans tensorflow. En plus de Flac format WAV , Ogg , MP3 et MP4A sont également pris en charge par AudioIOTensor avec détection de format de fichier automatique.
AudioIOTensor est chargé paresseux forme alors que, DTYPE et le taux d' échantillonnage sont présentés au départ. La forme de la AudioIOTensor est représentée par [samples, channels] les 28979 int16 [samples, channels] , ce qui signifie le clip audio chargé est mono canal avec 28979 échantillons dans int16 .
Le contenu du clip audio ne sera lu au besoin, que ce soit en convertissant AudioIOTensor à Tensor par to_tensor() , ou bien trancher. Le découpage est particulièrement utile lorsque seule une petite partie d'un gros clip audio est nécessaire :
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
L'audio peut être lu via :
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
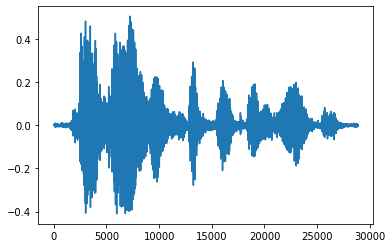
Il est plus pratique de convertir le tenseur en nombres flottants et d'afficher le clip audio sous forme de graphique :
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
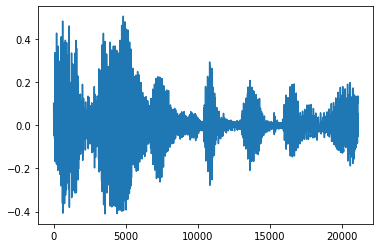
Couper le bruit
Parfois , il est logique de couper le bruit de l'audio, ce qui pourrait être fait via l' API tfio.audio.trim . Renvoyé de l'API est une paire de [start, stop] position du segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
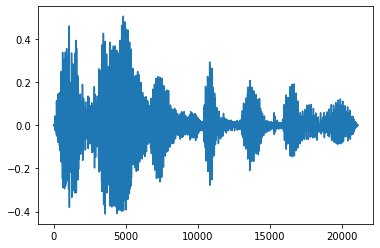
Fondu d'entrée et de sortie
Une technique d'ingénierie audio utile est le fondu, qui augmente ou diminue progressivement les signaux audio. Cela peut se faire par tfio.audio.fade . tfio.audio.fade supports de formes différentes telles que des fondus linear , logarithmic ou exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
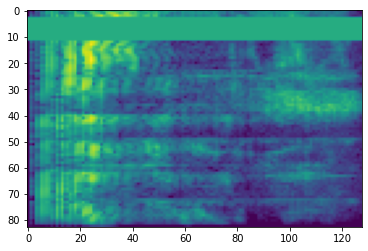
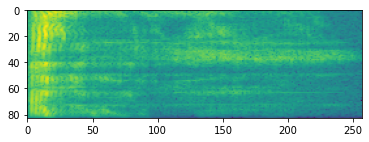
Spectrogramme
Le traitement audio avancé fonctionne souvent sur les changements de fréquence au fil du temps. Dans tensorflow-io une forme d' onde peut être converti en spectrogramme par tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
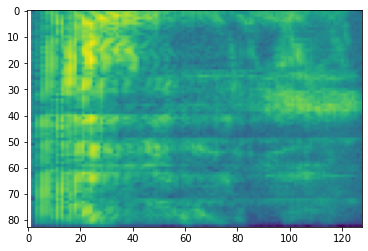
Des transformations supplémentaires à différentes échelles sont également possibles :
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
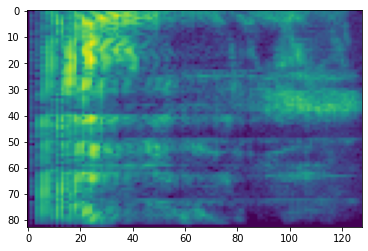
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
SpecAugmentation
En plus de ce qui précède la préparation des données mentionnées et les API augmentation, tensorflow-io paquet fournit également des augmentations de spectrogramme avancées, notamment la fréquence et le temps Masking discuté dans SpecAugment: (. Park et al, 2019) Une méthode simple des données d' augmentation pour la reconnaissance automatique de la parole .
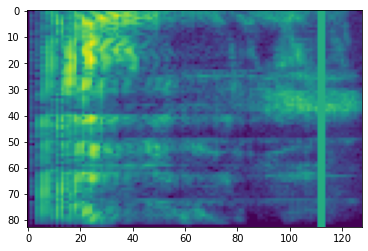
Masquage de fréquence
Dans le masquage de fréquence, des canaux de fréquence [f0, f0 + f) sont masqués où f est choisi parmi une distribution uniforme de 0 au paramètre masque de fréquence F , et f0 est choisi parmi (0, ν − f) où ν est le nombre de canaux de fréquence.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
Masquage temporel
Dans le masquage du temps, t pas de temps consécutifs [t0, t0 + t) sont masqués où t est choisi parmi une distribution uniforme de 0 dans le masque de temps paramètre T , et t0 est choisi parmi [0, τ − t) , où τ est le pas de temps.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>