| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Jednym z największych wyzwań związanych z automatycznym rozpoznawaniem mowy jest przygotowanie i rozszerzenie danych dźwiękowych. Analiza danych dźwiękowych może odbywać się w dziedzinie czasu lub częstotliwości, co dodatkowo zwiększa złożoność w porównaniu z innymi źródłami danych, takimi jak obrazy.
Jako część ekosystemu TensorFlow, tensorflow-io pakiet zawiera sporo użytecznych interfejsów API związanych z audio-pomagającego ułatwiając przygotowanie i powiększania danych audio.
Ustawiać
Zainstaluj wymagane pakiety i uruchom ponownie środowisko wykonawcze
pip install tensorflow-io
Stosowanie
Przeczytaj plik audio
W TensorFlow IO, klasa tfio.audio.AudioIOTensor pozwala odczytać plik audio na leniwe załadowane IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
W powyższym przykładzie plik Flac brooklyn.flac jest publicznie dostępnego klipu audio w Google Cloud .
GCS adres gs://cloud-samples-tests/speech/brooklyn.flac są stosowane bezpośrednio, ponieważ GCS jest obsługiwany system plików w TensorFlow. Oprócz Flac formatu WAV , Ogg , MP3 i MP4A są również obsługiwane przez AudioIOTensor z automatycznego wykrywania formatu pliku.
AudioIOTensor jest lazy tak obciążony tylko kształtu, dtype, a częstotliwość próbkowania jest pokazany na początku. Kształt AudioIOTensor jest reprezentowane [samples, channels] , co oznacza, że klip audio załadowany jest mono kanałowy 28979 próbek w int16 .
Zawartość klipu audio będą odczytywane tylko w razie potrzeby, albo poprzez przekształcenie AudioIOTensor do Tensor przez to_tensor() , albo chociaż krojenia. Krojenie jest szczególnie przydatne, gdy potrzebna jest tylko niewielka część dużego klipu audio:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
Dźwięk może być odtwarzany przez:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
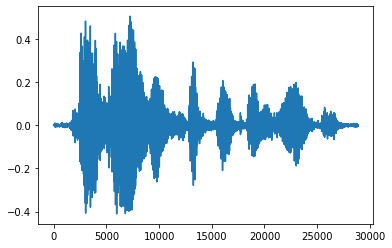
Bardziej wygodne jest przekonwertowanie tensora na liczby zmiennoprzecinkowe i pokazanie klipu audio na wykresie:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
Przytnij hałas
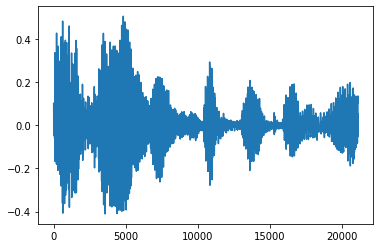
Czasami ma to sens, aby przyciąć hałas z dźwiękiem, które mogą być wykonywane przez API tfio.audio.trim . Zwracane z API parę [start, stop] położenia segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
Zanikanie i zanikanie
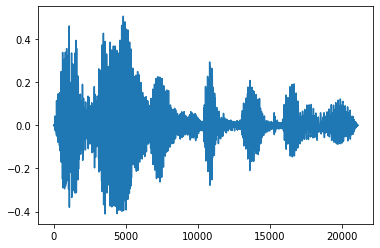
Jedną z przydatnych technik inżynierii dźwięku jest zanikanie, które stopniowo zwiększa lub zmniejsza sygnały audio. Można to zrobić poprzez tfio.audio.fade . tfio.audio.fade obsługuje różne kształty zanika, takie jak linear , logarithmic lub exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
Spektrogram
Zaawansowane przetwarzanie dźwięku często działa na zmiany częstotliwości w czasie. W tensorflow-io przebiegu mogą być przekształcone w spektrogramie przez tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
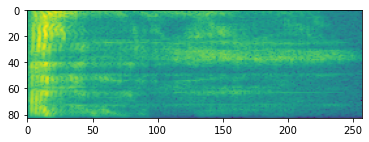
Możliwe są również dodatkowe przekształcenia na różne skale:
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
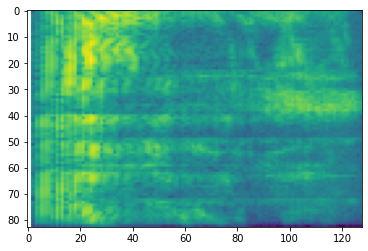
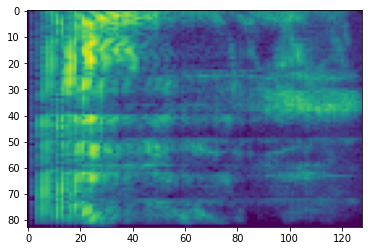
Rozszerzenie specyfikacji
Oprócz wyżej wymienionych API przygotowanie danych i wspomagania, tensorflow-io pakiet zawiera również zaawansowane rozszerzonych spektrogramem, najbardziej szczególnie częstotliwości i czasu Maskowanie omówione SpecAugment: (. Park et al, 2019) to prosta metoda Dane Augmentation do automatycznego rozpoznawania mowy .
Maskowanie częstotliwości
Maskowanie częstotliwości, kanały częstotliwości [f0, f0 + f) są maskowane w którym f jest wybrane z rozkładu równomiernego od 0 do maski częstotliwości parametr F i f0 jest wybrany spośród (0, ν − f) , gdzie ν oznacza liczbę kanały częstotliwości.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
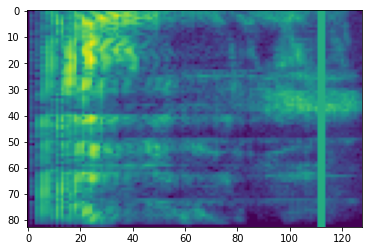
Maskowanie czasu
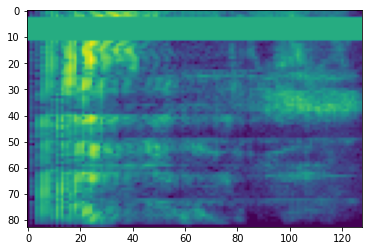
W czasie maskowania t kolejnych etapów czasowych [t0, t0 + t) są maskowane w którym t jest wybrane z rozkładu równomiernego od 0 do maski odstępie czasu T i t0 jest wybrany spośród [0, τ − t) , gdzie τ jest kroki czasowe.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>