ML yang fleksibel, terkontrol, dan dapat diinterpretasikan dengan model berbasis kisi
import numpy as np import tensorflow as tf import tensorflow_lattice as tfl model = tf.keras.models.Sequential() model.add( tfl.layers.ParallelCombination([ # Monotonic piece-wise linear calibration with bounded output tfl.layers.PWLCalibration( monotonicity='increasing', input_keypoints=np.linspace(1., 5., num=20), output_min=0.0, output_max=1.0), # Diminishing returns tfl.layers.PWLCalibration( monotonicity='increasing', convexity='concave', input_keypoints=np.linspace(0., 200., num=20), output_min=0.0, output_max=2.0), # Partially monotonic categorical calibration: calib(0) <= calib(1) tfl.layers.CategoricalCalibration( num_buckets=4, output_min=0.0, output_max=1.0, monotonicities=[(0, 1)]), ])) model.add( tfl.layers.Lattice( lattice_sizes=[2, 3, 2], monotonicities=['increasing', 'increasing', 'increasing'], # Trust: model is more responsive to input 0 if input 1 increases edgeworth_trusts=(0, 1, 'positive'))) model.compile(...)
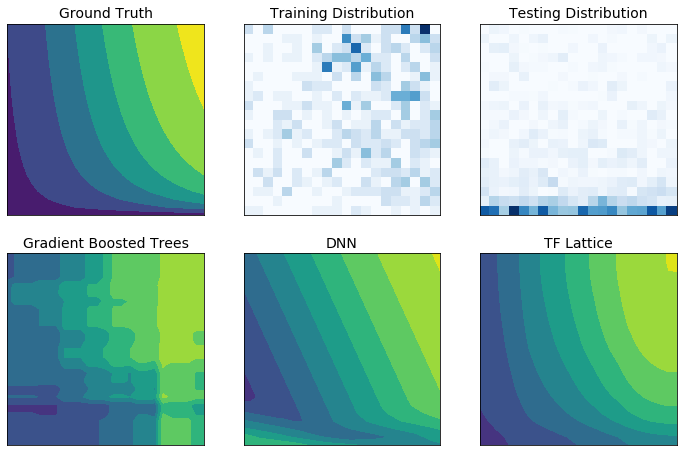
TensorFlow Lattice adalah perpustakaan yang mengimplementasikan model berbasis kisi yang dibatasi dan dapat diinterpretasikan. Pustaka memungkinkan Anda memasukkan pengetahuan domain ke dalam proses pembelajaran melalui batasan bentuk yang masuk akal atau berdasarkan kebijakan. Hal ini dilakukan dengan menggunakan kumpulan lapisan Keras yang dapat memenuhi batasan seperti monotonisitas, konveksitas, dan cara fitur berinteraksi. Perpustakaan juga menyediakan pengaturan model premade yang mudah.
Dengan TF Lattice Anda dapat menggunakan pengetahuan domain untuk melakukan ekstrapolasi dengan lebih baik ke bagian ruang masukan yang tidak tercakup dalam kumpulan data pelatihan. Hal ini membantu menghindari perilaku model yang tidak terduga ketika distribusi penyajian berbeda dari distribusi pelatihan.