
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Ringkasan
Tutorial ini adalah ikhtisar tentang batasan dan regularizer yang disediakan oleh library TensorFlow Lattice (TFL). Di sini kami menggunakan estimator kalengan TFL pada kumpulan data sintetis, tetapi perhatikan bahwa semua yang ada dalam tutorial ini juga dapat dilakukan dengan model yang dibuat dari lapisan TFL Keras.
Sebelum melanjutkan, pastikan runtime Anda telah menginstal semua paket yang diperlukan (seperti yang diimpor dalam sel kode di bawah).
Mempersiapkan
Menginstal paket TF Lattice:
pip install -q tensorflow-lattice
Mengimpor paket yang dibutuhkan:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Nilai default yang digunakan dalam panduan ini:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Dataset Pelatihan untuk Peringkat Restoran
Bayangkan skenario yang disederhanakan di mana kita ingin menentukan apakah pengguna akan mengklik hasil pencarian restoran atau tidak. Tugasnya adalah memprediksi rasio klik-tayang (RKT) yang diberikan fitur input:
- Nilai rata-rata (
avg_rating): fitur numerik dengan nilai-nilai dalam rentang [1,5]. - Jumlah ulasan (
num_reviews): fitur numerik dengan nilai maksimal 200, yang kita gunakan sebagai ukuran trendiness. - Dollar rating (
dollar_rating): fitur kategoris dengan nilai-nilai string pada set { "D", "DD", "DDD", "DDDD"}.
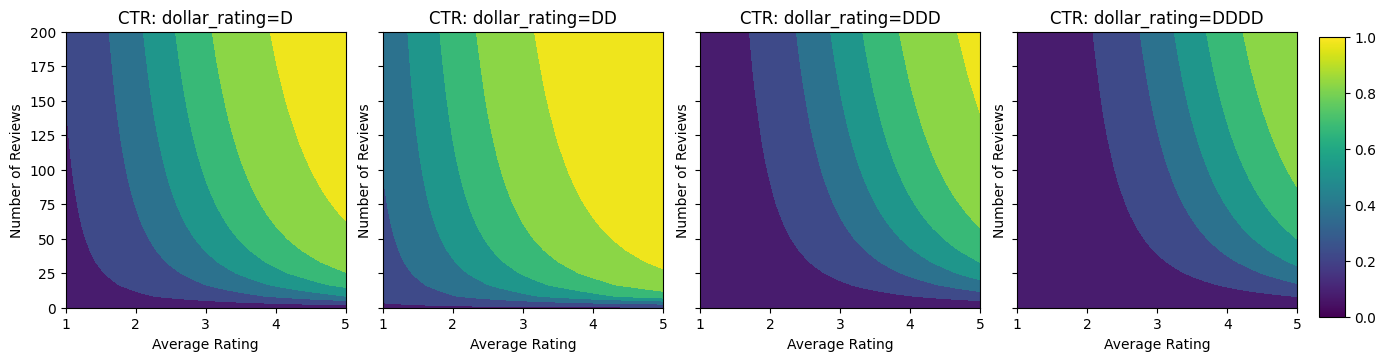
Di sini kami membuat kumpulan data sintetis di mana RKT sebenarnya diberikan oleh rumus:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
di mana \(b(\cdot)\) diterjemahkan masing-masing dollar_rating ke nilai dasar:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Rumus ini mencerminkan pola pengguna yang khas. misalnya dengan segala hal lain yang diperbaiki, pengguna lebih memilih restoran dengan peringkat bintang yang lebih tinggi, dan restoran "\$\$" akan menerima lebih banyak klik daripada "\$", diikuti oleh "\$\$\$" dan "\$\$\$ \"$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Mari kita lihat kontur plot dari fungsi CTR ini.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Mempersiapkan Data
Sekarang kita perlu membuat kumpulan data sintetis kita. Kami mulai dengan membuat set data simulasi restoran dan fitur-fiturnya.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
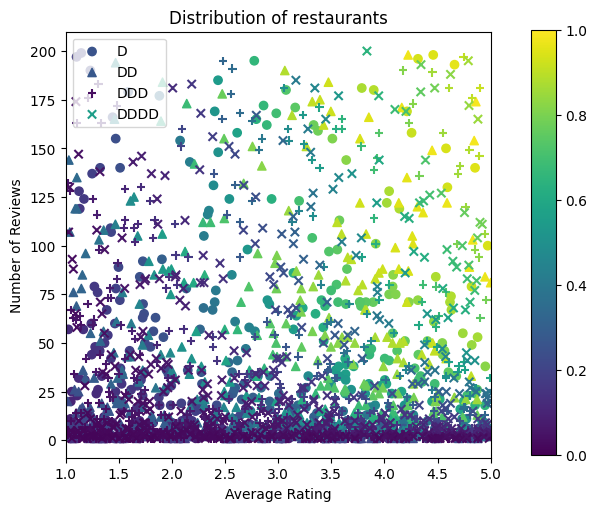
Mari kita buat set data pelatihan, validasi, dan pengujian. Saat sebuah restoran dilihat di hasil pencarian, kami dapat merekam keterlibatan pengguna (klik atau tidak klik) sebagai titik sampel.
Dalam praktiknya, pengguna sering kali tidak melihat semua hasil pencarian. Ini berarti bahwa pengguna kemungkinan hanya akan melihat restoran yang sudah dianggap "baik" oleh model peringkat yang digunakan saat ini. Akibatnya, restoran "baik" lebih sering terkesan dan terwakili secara berlebihan dalam kumpulan data pelatihan. Saat menggunakan lebih banyak fitur, set data pelatihan dapat memiliki celah besar di bagian "buruk" dari ruang fitur.
Ketika model digunakan untuk pemeringkatan, model tersebut sering dievaluasi pada semua hasil yang relevan dengan distribusi yang lebih seragam yang tidak terwakili dengan baik oleh dataset pelatihan. Model yang fleksibel dan rumit mungkin gagal dalam kasus ini karena kelebihan titik data yang terwakili secara berlebihan dan dengan demikian kurang dapat digeneralisasikan. Kami menangani masalah ini dengan menerapkan pengetahuan domain untuk menambahkan kendala bentuk yang memandu model untuk membuat prediksi yang wajar ketika tidak bisa mengambilnya dari dataset pelatihan.
Dalam contoh ini, kumpulan data pelatihan sebagian besar terdiri dari interaksi pengguna dengan restoran yang bagus dan populer. Dataset pengujian memiliki distribusi yang seragam untuk mensimulasikan pengaturan evaluasi yang dibahas di atas. Perhatikan bahwa kumpulan data pengujian tersebut tidak akan tersedia dalam pengaturan masalah yang sebenarnya.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Mendefinisikan input_fns yang digunakan untuk pelatihan dan evaluasi:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Memasang Gradient Boosted Trees
Mari kita mulai dengan hanya dua fitur: avg_rating dan num_reviews .
Kami membuat beberapa fungsi tambahan untuk merencanakan dan menghitung validasi dan metrik pengujian.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Kami dapat memasukkan pohon keputusan yang didorong gradien TensorFlow pada set data:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

Meskipun model telah menangkap bentuk umum RKT sebenarnya dan memiliki metrik validasi yang layak, model ini memiliki perilaku kontra-intuitif di beberapa bagian ruang input: perkiraan RKT menurun seiring dengan peningkatan peringkat rata-rata atau jumlah ulasan. Hal ini disebabkan kurangnya titik sampel di area yang tidak tercakup dengan baik oleh dataset pelatihan. Model tidak memiliki cara untuk menyimpulkan perilaku yang benar hanya dari data.
Untuk mengatasi masalah ini, kami menerapkan batasan bentuk bahwa model harus menghasilkan nilai yang meningkat secara monoton sehubungan dengan peringkat rata-rata dan jumlah ulasan. Nanti kita akan melihat bagaimana menerapkan ini di TFL.
Memasang DNN
Kita dapat mengulangi langkah yang sama dengan pengklasifikasi DNN. Kita dapat mengamati pola yang serupa: tidak memiliki titik sampel yang cukup dengan sejumlah kecil ulasan menghasilkan ekstrapolasi yang tidak masuk akal. Perhatikan bahwa meskipun metrik validasi lebih baik daripada solusi pohon, metrik pengujian jauh lebih buruk.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Batasan Bentuk
TensorFlow Lattice (TFL) berfokus pada penerapan batasan bentuk untuk melindungi perilaku model di luar data pelatihan. Batasan bentuk ini diterapkan pada lapisan TFL Keras. Rincian mereka dapat ditemukan dalam kertas JMLR kami .
Dalam tutorial ini kami menggunakan TF kaleng estimator untuk menutupi berbagai batasan bentuk, tetapi perhatikan bahwa semua langkah ini dapat dilakukan dengan model yang dibuat dari lapisan TFL Keras.
Seperti halnya estimator TensorFlow lainnya, TFL kaleng estimator menggunakan kolom fitur untuk menentukan format input dan menggunakan input_fn pelatihan untuk lulus dalam data. Menggunakan estimator kalengan TFL juga membutuhkan:
- model config: mendefinisikan arsitektur Model dan bentuk kendala per-fitur dan regularizers.
- analisis fitur input_fn: a TF input_fn lewat data untuk TFL inisialisasi.
Untuk deskripsi yang lebih menyeluruh, silakan merujuk ke tutorial estimator kalengan atau dokumen API.
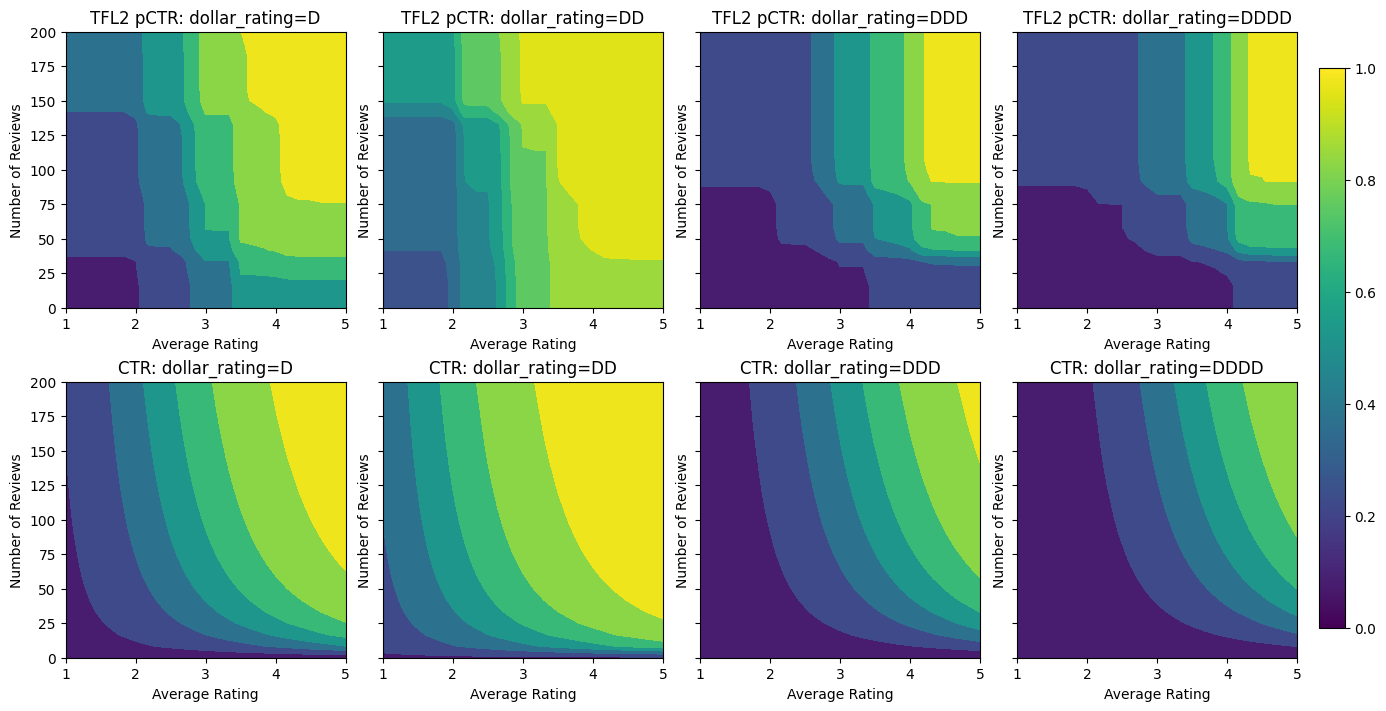
Monotonisitas
Kami pertama-tama mengatasi masalah monotonisitas dengan menambahkan kendala bentuk monotonisitas ke kedua fitur.
Untuk menginstruksikan TFL untuk menegakkan kendala bentuk, kita tentukan kendala dalam konfigurasi fitur. Kode berikut menunjukkan bagaimana kita bisa membutuhkan output untuk menjadi monoton meningkat sehubungan dengan baik num_reviews dan avg_rating dengan menetapkan monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

Menggunakan CalibratedLatticeConfig menciptakan sebuah classifier kaleng yang pertama berlaku kalibrator untuk setiap input (fungsi linear sepotong-bijaksana untuk fitur numerik) diikuti oleh lapisan kisi untuk non-linear sekering fitur dikalibrasi. Kita dapat menggunakan tfl.visualization untuk memvisualisasikan model. Secara khusus, plot berikut menunjukkan dua kalibrator terlatih yang termasuk dalam pengklasifikasi kalengan.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

Dengan penambahan batasan, estimasi CTR akan selalu meningkat seiring dengan peningkatan rata-rata rating atau peningkatan jumlah ulasan. Ini dilakukan dengan memastikan bahwa kalibrator dan kisi-kisinya monoton.
Pengembalian yang berkurang
Semakin berkurang berarti bahwa gain marjinal meningkatkan nilai fitur tertentu akan berkurang karena kita meningkatkan nilai. Dalam kasus kami, kami berharap bahwa num_reviews fitur mengikuti pola ini, sehingga kita dapat mengkonfigurasi kalibrator yang sesuai. Perhatikan bahwa kita dapat menguraikan hasil yang semakin berkurang menjadi dua kondisi yang cukup:
- kalibrator meningkat secara monoton, dan
- kalibrator cekung.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
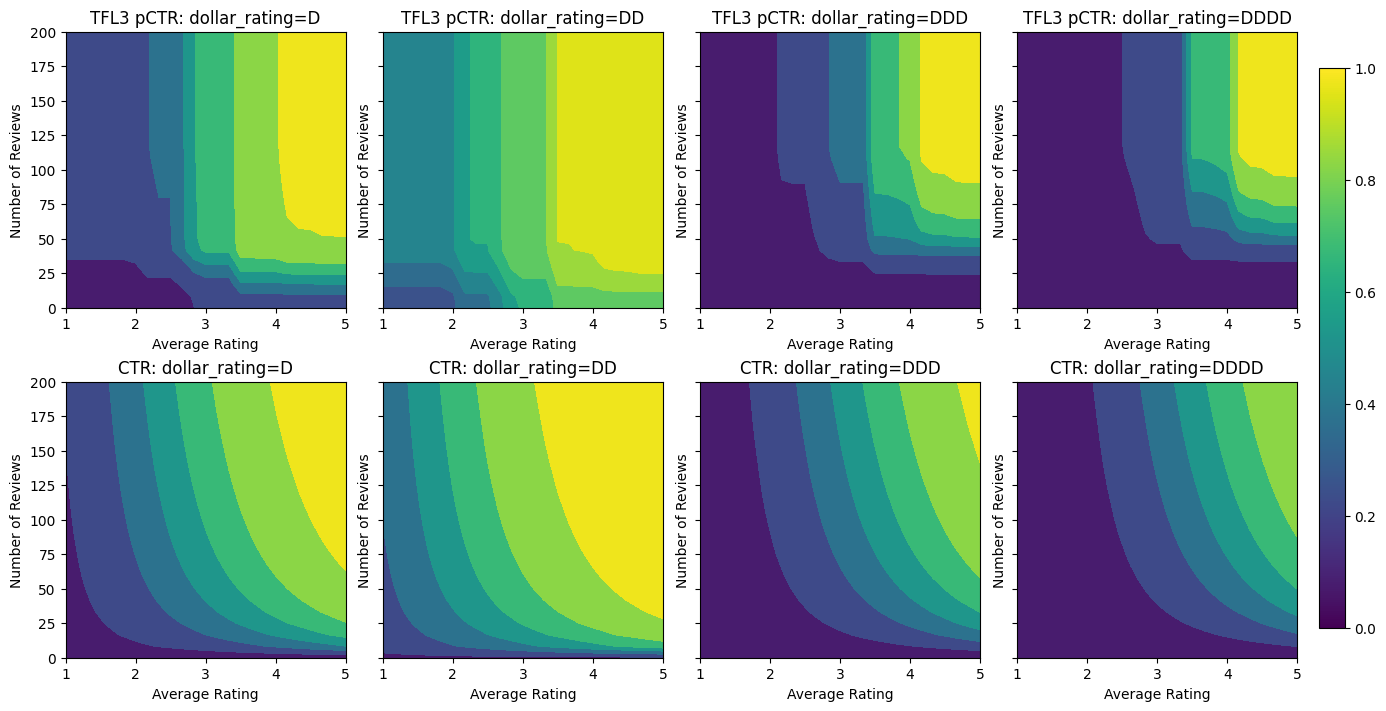

Perhatikan bagaimana metrik pengujian meningkat dengan menambahkan batasan cekung. Plot prediksi juga lebih menyerupai kebenaran dasar.
Batasan Bentuk 2D: Kepercayaan
Peringkat bintang 5 untuk restoran dengan hanya satu atau dua ulasan kemungkinan merupakan peringkat yang tidak dapat diandalkan (restoran mungkin tidak benar-benar bagus), sedangkan peringkat bintang 4 untuk restoran dengan ratusan ulasan jauh lebih dapat diandalkan (restoran tersebut kemungkinan bagus dalam hal ini). Kita dapat melihat bahwa jumlah ulasan sebuah restoran memengaruhi seberapa besar kepercayaan yang kita berikan pada peringkat rata-ratanya.
Kita dapat menggunakan batasan kepercayaan TFL untuk menginformasikan model bahwa nilai yang lebih besar (atau lebih kecil) dari satu fitur menunjukkan lebih banyak ketergantungan atau kepercayaan dari fitur lain. Hal ini dilakukan dengan menetapkan reflects_trust_in konfigurasi di config fitur.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

Plot berikut menyajikan fungsi kisi terlatih. Karena kendala kepercayaan, kami berharap bahwa nilai-nilai yang lebih besar dari dikalibrasi num_reviews akan memaksa kemiringan yang lebih tinggi sehubungan dengan dikalibrasi avg_rating , menghasilkan sebuah langkah yang lebih signifikan dalam output kisi.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
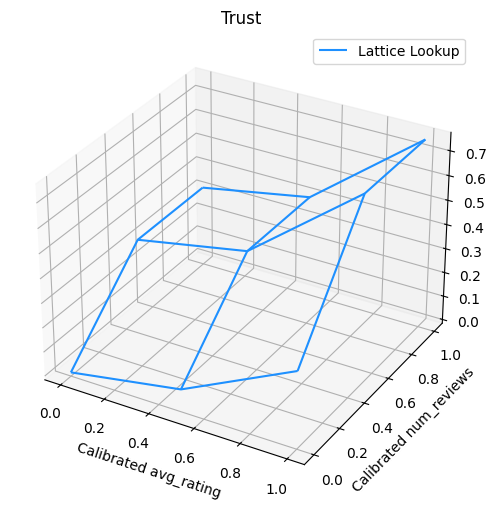
Kalibrator Penghalus
Mari sekarang kita lihat di kalibrator dari avg_rating . Meskipun meningkat secara monoton, perubahan kemiringannya tiba-tiba dan sulit untuk ditafsirkan. Itu menunjukkan kita mungkin ingin mempertimbangkan smoothing kalibrator ini menggunakan setup regularizer di regularizer_configs .
Di sini kita menerapkan wrinkle regularizer untuk mengurangi perubahan kelengkungan. Anda juga dapat menggunakan laplacian regularizer untuk meratakan kalibrator dan hessian regularizer untuk membuatnya lebih linear.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


Kalibrator sekarang mulus, dan perkiraan RKT keseluruhan lebih sesuai dengan kenyataan di lapangan. Hal ini tercermin baik dalam metrik pengujian dan dalam plot kontur.
Monotonisitas Parsial untuk Kalibrasi Kategoris
Sejauh ini kami hanya menggunakan dua fitur numerik dalam model. Di sini kita akan menambahkan fitur ketiga menggunakan lapisan kalibrasi kategoris. Sekali lagi kita mulai dengan menyiapkan fungsi pembantu untuk merencanakan dan menghitung metrik.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Untuk melibatkan fitur ketiga, dollar_rating , kita harus ingat bahwa fitur kategoris memerlukan perawatan yang sedikit berbeda di TFL, baik sebagai kolom fitur dan sebagai konfigurasi fitur. Di sini kami menerapkan batasan monotonisitas parsial bahwa output untuk restoran "DD" harus lebih besar dari restoran "D" ketika semua input lainnya diperbaiki. Hal ini dilakukan dengan menggunakan monotonicity pengaturan dalam konfigurasi fitur.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Kalibrator kategorikal ini menunjukkan preferensi keluaran model: DD > D > DDD > DDDD, yang konsisten dengan pengaturan kita. Perhatikan juga ada kolom untuk nilai yang hilang. Meskipun tidak ada fitur yang hilang dalam data pelatihan dan pengujian kami, model ini memberi kami imputasi untuk nilai yang hilang jika itu terjadi selama penyajian model hilir.
Di sini kami juga plot prediksi RKPT model ini dikondisikan pada dollar_rating . Perhatikan bahwa semua kendala yang kita butuhkan terpenuhi di setiap irisan.
Kalibrasi Keluaran
Untuk semua model TFL yang telah kita latih sejauh ini, lapisan kisi (ditunjukkan sebagai "Kisi" dalam grafik model) secara langsung mengeluarkan prediksi model. Terkadang kami tidak yakin apakah keluaran kisi harus diskalakan ulang untuk memancarkan keluaran model:
- fitur yang \(log\) jumlah sementara label tersebut penting.
- kisi dikonfigurasi untuk memiliki simpul yang sangat sedikit tetapi distribusi labelnya relatif rumit.
Dalam kasus tersebut, kita dapat menambahkan kalibrator lain antara keluaran kisi dan keluaran model untuk meningkatkan fleksibilitas model. Di sini mari kita tambahkan lapisan kalibrator dengan 5 titik kunci ke model yang baru saja kita buat. Kami juga menambahkan regularizer untuk kalibrator keluaran agar fungsi tetap lancar.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


Metrik dan plot pengujian akhir menunjukkan bagaimana menggunakan batasan akal sehat dapat membantu model menghindari perilaku tak terduga dan mengekstrapolasi lebih baik ke seluruh ruang input.
,| | | Lihat sumber di GitHub | |
Ringkasan
Tutorial ini adalah ikhtisar tentang batasan dan regularizer yang disediakan oleh library TensorFlow Lattice (TFL). Di sini kami menggunakan estimator kalengan TFL pada kumpulan data sintetis, tetapi perhatikan bahwa semua yang ada dalam tutorial ini juga dapat dilakukan dengan model yang dibuat dari lapisan TFL Keras.
Sebelum melanjutkan, pastikan runtime Anda telah menginstal semua paket yang diperlukan (seperti yang diimpor dalam sel kode di bawah).
Mempersiapkan
Menginstal paket TF Lattice:
pip install -q tensorflow-lattice
Mengimpor paket yang dibutuhkan:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Nilai default yang digunakan dalam panduan ini:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Dataset Pelatihan untuk Peringkat Restoran
Bayangkan skenario yang disederhanakan di mana kita ingin menentukan apakah pengguna akan mengklik hasil pencarian restoran atau tidak. Tugasnya adalah memprediksi rasio klik-tayang (RKT) yang diberikan fitur input:
- Nilai rata-rata (
avg_rating): fitur numerik dengan nilai-nilai dalam rentang [1,5]. - Jumlah ulasan (
num_reviews): fitur numerik dengan nilai maksimal 200, yang kita gunakan sebagai ukuran trendiness. - Dollar rating (
dollar_rating): fitur kategoris dengan nilai-nilai string pada set { "D", "DD", "DDD", "DDDD"}.
Di sini kami membuat kumpulan data sintetis di mana RKT sebenarnya diberikan oleh rumus:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
di mana \(b(\cdot)\) diterjemahkan masing-masing dollar_rating ke nilai dasar:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Rumus ini mencerminkan pola pengguna yang khas. misalnya dengan segala hal lain yang diperbaiki, pengguna lebih memilih restoran dengan peringkat bintang yang lebih tinggi, dan restoran "\$\$" akan menerima lebih banyak klik daripada "\$", diikuti oleh "\$\$\$" dan "\$\$\$ \"$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Mari kita lihat kontur plot dari fungsi CTR ini.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Mempersiapkan Data
Sekarang kita perlu membuat kumpulan data sintetis kita. Kami mulai dengan membuat set data simulasi restoran dan fitur-fiturnya.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
Mari kita buat set data pelatihan, validasi, dan pengujian. Saat sebuah restoran dilihat di hasil pencarian, kami dapat merekam keterlibatan pengguna (klik atau tidak klik) sebagai titik sampel.
Dalam praktiknya, pengguna sering kali tidak melihat semua hasil pencarian. Ini berarti bahwa pengguna kemungkinan hanya akan melihat restoran yang sudah dianggap "baik" oleh model peringkat yang digunakan saat ini. Akibatnya, restoran "baik" lebih sering terkesan dan terwakili secara berlebihan dalam kumpulan data pelatihan. Saat menggunakan lebih banyak fitur, set data pelatihan dapat memiliki celah besar di bagian "buruk" dari ruang fitur.
Ketika model digunakan untuk pemeringkatan, model tersebut sering dievaluasi pada semua hasil yang relevan dengan distribusi yang lebih seragam yang tidak terwakili dengan baik oleh dataset pelatihan. Model yang fleksibel dan rumit mungkin gagal dalam kasus ini karena kelebihan titik data yang terwakili secara berlebihan dan dengan demikian kurang dapat digeneralisasikan. Kami menangani masalah ini dengan menerapkan pengetahuan domain untuk menambahkan kendala bentuk yang memandu model untuk membuat prediksi yang wajar ketika tidak bisa mengambilnya dari dataset pelatihan.
Dalam contoh ini, kumpulan data pelatihan sebagian besar terdiri dari interaksi pengguna dengan restoran yang bagus dan populer. Dataset pengujian memiliki distribusi yang seragam untuk mensimulasikan pengaturan evaluasi yang dibahas di atas. Perhatikan bahwa kumpulan data pengujian tersebut tidak akan tersedia dalam pengaturan masalah yang sebenarnya.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
Mendefinisikan input_fns yang digunakan untuk pelatihan dan evaluasi:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Memasang Gradient Boosted Trees
Mari kita mulai dengan hanya dua fitur: avg_rating dan num_reviews .
Kami membuat beberapa fungsi tambahan untuk merencanakan dan menghitung validasi dan metrik pengujian.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Kami dapat memasukkan pohon keputusan yang didorong gradien TensorFlow pada set data:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
Meskipun model telah menangkap bentuk umum RKT sebenarnya dan memiliki metrik validasi yang layak, model ini memiliki perilaku kontra-intuitif di beberapa bagian ruang input: perkiraan RKT menurun seiring dengan peningkatan peringkat rata-rata atau jumlah ulasan. Hal ini disebabkan kurangnya titik sampel di area yang tidak tercakup dengan baik oleh dataset pelatihan. Model tidak memiliki cara untuk menyimpulkan perilaku yang benar hanya dari data.
Untuk mengatasi masalah ini, kami menerapkan batasan bentuk bahwa model harus menghasilkan nilai yang meningkat secara monoton sehubungan dengan peringkat rata-rata dan jumlah ulasan. Nanti kita akan melihat bagaimana menerapkan ini di TFL.
Memasang DNN
Kita dapat mengulangi langkah yang sama dengan pengklasifikasi DNN. Kita dapat mengamati pola yang serupa: tidak memiliki titik sampel yang cukup dengan sejumlah kecil ulasan menghasilkan ekstrapolasi yang tidak masuk akal. Perhatikan bahwa meskipun metrik validasi lebih baik daripada solusi pohon, metrik pengujian jauh lebih buruk.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
Batasan Bentuk
TensorFlow Lattice (TFL) berfokus pada penerapan batasan bentuk untuk melindungi perilaku model di luar data pelatihan. Batasan bentuk ini diterapkan pada lapisan TFL Keras. Rincian mereka dapat ditemukan dalam kertas JMLR kami .
Dalam tutorial ini kami menggunakan TF kaleng estimator untuk menutupi berbagai batasan bentuk, tetapi perhatikan bahwa semua langkah ini dapat dilakukan dengan model yang dibuat dari lapisan TFL Keras.
Seperti halnya estimator TensorFlow lainnya, TFL kaleng estimator menggunakan kolom fitur untuk menentukan format input dan menggunakan input_fn pelatihan untuk lulus dalam data. Menggunakan estimator kalengan TFL juga membutuhkan:
- model config: mendefinisikan arsitektur Model dan bentuk kendala per-fitur dan regularizers.
- analisis fitur input_fn: a TF input_fn lewat data untuk TFL inisialisasi.
Untuk deskripsi yang lebih menyeluruh, silakan merujuk ke tutorial estimator kalengan atau dokumen API.
Monotonisitas
Kami pertama-tama mengatasi masalah monotonisitas dengan menambahkan kendala bentuk monotonisitas ke kedua fitur.
Untuk menginstruksikan TFL untuk menegakkan kendala bentuk, kita tentukan kendala dalam konfigurasi fitur. Kode berikut menunjukkan bagaimana kita bisa membutuhkan output untuk menjadi monoton meningkat sehubungan dengan baik num_reviews dan avg_rating dengan menetapkan monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
Menggunakan CalibratedLatticeConfig menciptakan sebuah classifier kaleng yang pertama berlaku kalibrator untuk setiap input (fungsi linear sepotong-bijaksana untuk fitur numerik) diikuti oleh lapisan kisi untuk non-linear sekering fitur dikalibrasi. Kita dapat menggunakan tfl.visualization untuk memvisualisasikan model. Secara khusus, plot berikut menunjukkan dua kalibrator terlatih yang termasuk dalam pengklasifikasi kalengan.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
Dengan penambahan batasan, estimasi CTR akan selalu meningkat seiring dengan peningkatan rata-rata rating atau peningkatan jumlah ulasan. Ini dilakukan dengan memastikan bahwa kalibrator dan kisi-kisinya monoton.
Pengembalian yang berkurang
Semakin berkurang berarti bahwa gain marjinal meningkatkan nilai fitur tertentu akan berkurang karena kita meningkatkan nilai. Dalam kasus kami, kami berharap bahwa num_reviews fitur mengikuti pola ini, sehingga kita dapat mengkonfigurasi kalibrator yang sesuai. Perhatikan bahwa kita dapat menguraikan hasil yang semakin berkurang menjadi dua kondisi yang cukup:
- kalibrator meningkat secara monoton, dan
- kalibrator cekung.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
Perhatikan bagaimana metrik pengujian meningkat dengan menambahkan batasan cekung. Plot prediksi juga lebih menyerupai kebenaran dasar.
Batasan Bentuk 2D: Kepercayaan
Peringkat bintang 5 untuk restoran dengan hanya satu atau dua ulasan kemungkinan merupakan peringkat yang tidak dapat diandalkan (restoran mungkin tidak benar-benar bagus), sedangkan peringkat bintang 4 untuk restoran dengan ratusan ulasan jauh lebih dapat diandalkan (restoran tersebut kemungkinan bagus dalam hal ini). Kita dapat melihat bahwa jumlah ulasan sebuah restoran memengaruhi seberapa besar kepercayaan yang kita berikan pada peringkat rata-ratanya.
Kita dapat menggunakan batasan kepercayaan TFL untuk menginformasikan model bahwa nilai yang lebih besar (atau lebih kecil) dari satu fitur menunjukkan lebih banyak ketergantungan atau kepercayaan dari fitur lain. Hal ini dilakukan dengan menetapkan reflects_trust_in konfigurasi di config fitur.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
Plot berikut menyajikan fungsi kisi terlatih. Karena kendala kepercayaan, kami berharap bahwa nilai-nilai yang lebih besar dari dikalibrasi num_reviews akan memaksa kemiringan yang lebih tinggi sehubungan dengan dikalibrasi avg_rating , menghasilkan sebuah langkah yang lebih signifikan dalam output kisi.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Kalibrator Penghalus
Mari sekarang kita lihat di kalibrator dari avg_rating . Meskipun meningkat secara monoton, perubahan kemiringannya tiba-tiba dan sulit untuk ditafsirkan. Itu menunjukkan kita mungkin ingin mempertimbangkan smoothing kalibrator ini menggunakan setup regularizer di regularizer_configs .
Di sini kita menerapkan wrinkle regularizer untuk mengurangi perubahan kelengkungan. Anda juga dapat menggunakan laplacian regularizer untuk meratakan kalibrator dan hessian regularizer untuk membuatnya lebih linear.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
Kalibrator sekarang mulus, dan perkiraan RKT keseluruhan lebih sesuai dengan kenyataan di lapangan. Hal ini tercermin baik dalam metrik pengujian dan dalam plot kontur.
Monotonisitas Parsial untuk Kalibrasi Kategoris
Sejauh ini kami hanya menggunakan dua fitur numerik dalam model. Di sini kita akan menambahkan fitur ketiga menggunakan lapisan kalibrasi kategoris. Sekali lagi kita mulai dengan menyiapkan fungsi pembantu untuk merencanakan dan menghitung metrik.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Untuk melibatkan fitur ketiga, dollar_rating , kita harus ingat bahwa fitur kategoris memerlukan perawatan yang sedikit berbeda di TFL, baik sebagai kolom fitur dan sebagai konfigurasi fitur. Di sini kami menerapkan batasan monotonisitas parsial bahwa output untuk restoran "DD" harus lebih besar dari restoran "D" ketika semua input lainnya diperbaiki. Hal ini dilakukan dengan menggunakan monotonicity pengaturan dalam konfigurasi fitur.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
Kalibrator kategorikal ini menunjukkan preferensi keluaran model: DD > D > DDD > DDDD, yang konsisten dengan pengaturan kita. Perhatikan juga ada kolom untuk nilai yang hilang. Meskipun tidak ada fitur yang hilang dalam data pelatihan dan pengujian kami, model ini memberi kami imputasi untuk nilai yang hilang jika itu terjadi selama penyajian model hilir.
Di sini kami juga plot prediksi RKPT model ini dikondisikan pada dollar_rating . Perhatikan bahwa semua kendala yang kita butuhkan terpenuhi di setiap irisan.
Kalibrasi Keluaran
Untuk semua model TFL yang telah kita latih sejauh ini, lapisan kisi (ditunjukkan sebagai "Kisi" dalam grafik model) secara langsung mengeluarkan prediksi model. Terkadang kami tidak yakin apakah keluaran kisi harus diskalakan ulang untuk memancarkan keluaran model:
- fitur yang \(log\) jumlah sementara label tersebut penting.
- kisi dikonfigurasi untuk memiliki simpul yang sangat sedikit tetapi distribusi labelnya relatif rumit.
Dalam kasus tersebut, kita dapat menambahkan kalibrator lain antara keluaran kisi dan keluaran model untuk meningkatkan fleksibilitas model. Di sini mari kita tambahkan lapisan kalibrator dengan 5 titik kunci ke model yang baru saja kita buat. Kami juga menambahkan regularizer untuk kalibrator keluaran agar fungsi tetap lancar.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
Metrik dan plot pengujian akhir menunjukkan bagaimana menggunakan batasan akal sehat dapat membantu model menghindari perilaku tak terduga dan mengekstrapolasi lebih baik ke seluruh ruang input.