
Penggunaan prosesor khusus seperti GPU, NPU, atau DSP untuk akselerasi perangkat keras dapat meningkatkan kinerja inferensi secara signifikan (dalam beberapa kasus, inferensi hingga 10x lebih cepat) dan pengalaman pengguna aplikasi Android Anda yang mendukung ML. Namun, mengingat beragamnya perangkat keras dan driver yang mungkin dimiliki pengguna Anda, memilih konfigurasi akselerasi perangkat keras yang optimal untuk setiap perangkat pengguna dapat menjadi suatu tantangan. Selain itu, mengaktifkan konfigurasi yang salah pada perangkat dapat menciptakan pengalaman pengguna yang buruk karena latensi yang tinggi atau, dalam beberapa kasus yang jarang terjadi, kesalahan runtime atau masalah akurasi yang disebabkan oleh ketidakcocokan perangkat keras.
Layanan Akselerasi untuk Android adalah API yang membantu Anda memilih konfigurasi akselerasi perangkat keras yang optimal untuk perangkat pengguna tertentu dan model .tflite Anda, sekaligus meminimalkan risiko kesalahan runtime atau masalah akurasi.
Layanan Akselerasi mengevaluasi berbagai konfigurasi akselerasi pada perangkat pengguna dengan menjalankan benchmark inferensi internal menggunakan model TensorFlow Lite Anda. Uji coba ini biasanya selesai dalam beberapa detik, bergantung pada model Anda. Anda dapat menjalankan tolok ukur satu kali pada setiap perangkat pengguna sebelum waktu inferensi, menyimpan hasilnya dalam cache, dan menggunakannya selama inferensi. Tolok ukur ini sudah tidak lagi dalam proses; yang meminimalkan risiko kerusakan pada aplikasi Anda.
Berikan model Anda, sampel data, dan hasil yang diharapkan (input dan output "emas") dan Layanan Akselerasi akan menjalankan tolok ukur inferensi TFLite internal untuk memberi Anda rekomendasi perangkat keras.
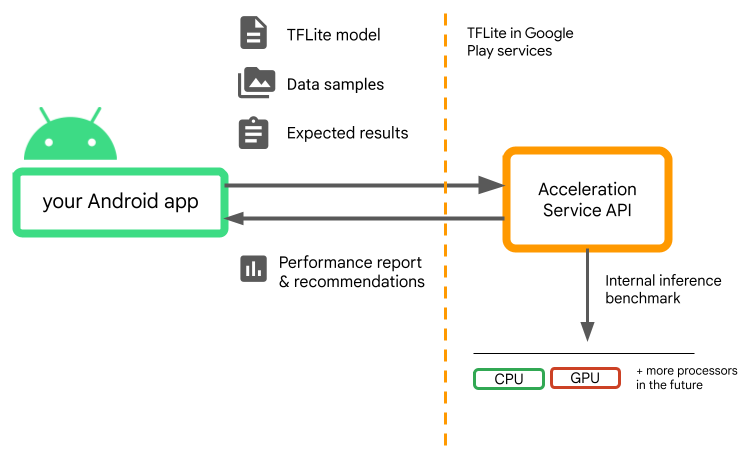
Layanan Akselerasi adalah bagian dari tumpukan ML khusus Android dan berfungsi dengan TensorFlow Lite di layanan Google Play .
Tambahkan dependensi ke proyek Anda
Tambahkan dependensi berikut ke file build.gradle aplikasi Anda:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.0.0-beta01"
Acceleration Service API berfungsi dengan TensorFlow Lite di Layanan Google Play . Jika Anda belum menggunakan runtime TensorFlow Lite yang disediakan melalui Layanan Play, Anda perlu memperbarui dependensi Anda.
Cara menggunakan API Layanan Akselerasi
Untuk menggunakan Layanan Akselerasi, mulailah dengan membuat konfigurasi akselerasi yang ingin Anda evaluasi untuk model Anda (misalnya GPU dengan OpenGL). Kemudian buat konfigurasi validasi dengan model Anda, beberapa data sampel, dan keluaran model yang diharapkan. Terakhir, panggil validateConfig() untuk meneruskan konfigurasi akselerasi dan konfigurasi validasi Anda.

Buat konfigurasi akselerasi
Konfigurasi akselerasi adalah representasi konfigurasi perangkat keras yang diterjemahkan ke dalam delegasi selama waktu eksekusi. Layanan Akselerasi kemudian akan menggunakan konfigurasi ini secara internal untuk melakukan inferensi pengujian.
Saat ini layanan akselerasi memungkinkan Anda mengevaluasi konfigurasi GPU (dikonversi menjadi delegasi GPU selama waktu eksekusi) dengan GpuAccelerationConfig dan inferensi CPU (dengan CpuAccelerationConfig ). Kami berupaya mendukung lebih banyak delegasi untuk mengakses perangkat keras lain di masa depan.
Konfigurasi akselerasi GPU
Buat konfigurasi akselerasi GPU sebagai berikut:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Anda harus menentukan apakah model Anda menggunakan kuantisasi dengan setEnableQuantizedInference() atau tidak.
Konfigurasi akselerasi CPU
Buat akselerasi CPU sebagai berikut:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Gunakan metode setNumThreads() untuk menentukan jumlah thread yang ingin Anda gunakan untuk mengevaluasi inferensi CPU.
Buat konfigurasi validasi
Konfigurasi validasi memungkinkan Anda menentukan bagaimana Anda ingin Layanan Akselerasi mengevaluasi inferensi. Anda akan menggunakannya untuk lulus:
- sampel masukan,
- keluaran yang diharapkan,
- logika validasi akurasi.
Pastikan untuk memberikan sampel masukan yang menurut Anda memiliki performa bagus untuk model Anda (juga dikenal sebagai sampel “emas”).
Buat ValidationConfig dengan CustomValidationConfig.Builder sebagai berikut:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Tentukan jumlah sampel emas dengan setBatchSize() . Teruskan masukan sampel emas Anda menggunakan setGoldenInputs() . Berikan keluaran yang diharapkan untuk masukan yang diteruskan dengan setGoldenOutputs() .
Anda dapat menentukan waktu inferensi maksimum dengan setInferenceTimeoutMillis() (5000 ms secara default). Jika inferensi memakan waktu lebih lama dari waktu yang Anda tentukan, konfigurasi akan ditolak.
Secara opsional, Anda juga dapat membuat AccuracyValidator khusus sebagai berikut:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Pastikan untuk menentukan logika validasi yang sesuai untuk kasus penggunaan Anda.
Perhatikan bahwa jika data validasi sudah tertanam dalam model Anda, Anda dapat menggunakan EmbeddedValidationConfig .
Hasilkan keluaran validasi
Keluaran emas bersifat opsional dan selama Anda memberikan masukan emas, Layanan Akselerasi dapat menghasilkan keluaran emas secara internal. Anda juga dapat menentukan konfigurasi akselerasi yang digunakan untuk menghasilkan keluaran emas ini dengan memanggil setGoldenConfig() :
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Validasi konfigurasi Akselerasi
Setelah Anda membuat konfigurasi akselerasi dan konfigurasi validasi, Anda dapat mengevaluasinya untuk model Anda.
Pastikan runtime TensorFlow Lite dengan Layanan Play diinisialisasi dengan benar dan delegasi GPU tersedia untuk perangkat dengan menjalankan:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Buat instance AccelerationService dengan memanggil AccelerationService.create() .
Anda kemudian dapat memvalidasi konfigurasi akselerasi untuk model Anda dengan memanggil validateConfig() :
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
Anda juga dapat memvalidasi beberapa konfigurasi dengan memanggil validateConfigs() dan meneruskan objek Iterable<AccelerationConfig> sebagai parameter.
validateConfig() akan mengembalikan Task< ValidatedAccelerationConfigResult > dari Api Tugas layanan Google Play yang mengaktifkan tugas asinkron.
Untuk mendapatkan hasil dari panggilan validasi, tambahkan callback addOnSuccessListener() .
Gunakan konfigurasi yang divalidasi di juru bahasa Anda
Setelah memeriksa apakah ValidatedAccelerationConfigResult yang dikembalikan dalam callback valid, Anda dapat menyetel konfigurasi yang divalidasi sebagai konfigurasi akselerasi untuk juru bahasa yang memanggil interpreterOptions.setAccelerationConfig() .
Cache konfigurasi
Konfigurasi akselerasi optimal untuk model Anda kemungkinan besar tidak akan berubah di perangkat. Jadi, setelah Anda menerima konfigurasi akselerasi yang memuaskan, Anda harus menyimpannya di perangkat dan membiarkan aplikasi Anda mengambilnya dan menggunakannya untuk membuat InterpreterOptions selama sesi berikutnya alih-alih menjalankan validasi lain. Metode serialize() dan deserialize() di ValidatedAccelerationConfigResult membuat proses penyimpanan dan pengambilan menjadi lebih mudah.
Contoh aplikasi
Untuk meninjau integrasi Layanan Akselerasi di tempat, lihat contoh aplikasi .
Keterbatasan
Layanan Akselerasi saat ini memiliki batasan berikut:
- Hanya konfigurasi akselerasi CPU dan GPU yang didukung saat ini,
- Ini hanya mendukung TensorFlow Lite di layanan Google Play dan Anda tidak dapat menggunakannya jika Anda menggunakan versi paket TensorFlow Lite,
- Itu tidak mendukung Pustaka Tugas TensorFlow Lite karena Anda tidak dapat langsung menginisialisasi
BaseOptionsdengan objekValidatedAccelerationConfigResult. - Acceleration Service SDK hanya mendukung API level 22 ke atas.
Peringatan
Harap tinjau peringatan berikut dengan cermat, terutama jika Anda berencana menggunakan SDK ini dalam produksi:
Sebelum keluar dari Beta dan merilis versi stabil untuk Acceleration Service API, kami akan menerbitkan SDK baru yang mungkin memiliki beberapa perbedaan dari versi Beta saat ini. Untuk terus menggunakan Layanan Akselerasi, Anda perlu bermigrasi ke SDK baru ini dan mengirimkan pembaruan ke aplikasi Anda tepat waktu. Tidak melakukan hal ini dapat menyebabkan kerusakan karena SDK Beta mungkin tidak lagi kompatibel dengan layanan Google Play setelah beberapa waktu.
Tidak ada jaminan bahwa fitur tertentu dalam Acceleration Service API atau API secara keseluruhan akan tersedia secara umum. Ini mungkin tetap dalam versi Beta tanpa batas waktu, dihentikan, atau digabungkan dengan fitur lain ke dalam paket yang dirancang untuk audiens pengembang tertentu. Beberapa fitur dengan Acceleration Service API atau seluruh API itu sendiri pada akhirnya mungkin tersedia secara umum, namun tidak ada jadwal pasti untuk hal ini.
Syarat dan privasi
Ketentuan Layanan
Penggunaan Acceleration Service API tunduk pada Persyaratan Layanan Google API .
Selain itu, API Layanan Akselerasi saat ini masih dalam versi beta dan, oleh karena itu, dengan menggunakannya, Anda mengetahui potensi masalah yang diuraikan di bagian Peringatan di atas dan mengakui bahwa Layanan Akselerasi mungkin tidak selalu berfungsi sebagaimana ditentukan.
Pribadi
Saat Anda menggunakan API Layanan Akselerasi, pemrosesan data masukan (misalnya gambar, video, teks) sepenuhnya dilakukan di perangkat, dan Layanan Akselerasi tidak mengirimkan data tersebut ke server Google . Hasilnya, Anda dapat menggunakan API kami untuk memproses data masukan yang tidak boleh keluar dari perangkat.
API Layanan Akselerasi dapat menghubungi server Google dari waktu ke waktu untuk menerima hal-hal seperti perbaikan bug, model yang diperbarui, dan informasi kompatibilitas akselerator perangkat keras. Acceleration Service API juga mengirimkan metrik tentang performa dan pemanfaatan API di aplikasi Anda ke Google. Google menggunakan data metrik ini untuk mengukur kinerja, melakukan debug, memelihara dan meningkatkan API, serta mendeteksi penyalahgunaan atau penyalahgunaan, sebagaimana dijelaskan lebih lanjut dalam Kebijakan Privasi kami.
Anda bertanggung jawab untuk memberi tahu pengguna aplikasi Anda tentang pemrosesan data metrik Layanan Akselerasi yang dilakukan Google sebagaimana diwajibkan oleh hukum yang berlaku.
Data yang kami kumpulkan mencakup hal-hal berikut:
- Informasi perangkat (seperti pabrikan, model, versi dan versi OS) dan akselerator perangkat keras ML yang tersedia (GPU dan DSP). Digunakan untuk diagnostik dan analisis penggunaan.
- Informasi aplikasi (nama paket/id bundel, versi aplikasi). Digunakan untuk diagnostik dan analisis penggunaan.
- Konfigurasi API (seperti format dan resolusi gambar). Digunakan untuk diagnostik dan analisis penggunaan.
- Jenis peristiwa (seperti inisialisasi, pengunduhan model, pembaruan, pengoperasian, deteksi). Digunakan untuk diagnostik dan analisis penggunaan.
- Kode kesalahan. Digunakan untuk diagnostik.
- Metrik kinerja. Digunakan untuk diagnostik.
- Pengidentifikasi per instalasi yang tidak secara unik mengidentifikasi pengguna atau perangkat fisik. Digunakan untuk pengoperasian konfigurasi jarak jauh dan analisis penggunaan.
- Alamat IP pengirim permintaan jaringan. Digunakan untuk diagnostik konfigurasi jarak jauh. Alamat IP yang dikumpulkan disimpan sementara.
Dukungan dan umpan balik
Anda dapat memberikan masukan dan mendapatkan dukungan melalui TensorFlow Issue Tracker. Silakan laporkan masalah dan permintaan dukungan menggunakan template masalah untuk TensorFlow Lite di layanan Google Play.