
Việc sử dụng các bộ xử lý chuyên dụng như GPU, NPU hoặc DSP để tăng tốc phần cứng có thể cải thiện đáng kể hiệu suất suy luận (suy luận nhanh hơn tới 10 lần trong một số trường hợp) và trải nghiệm người dùng của ứng dụng Android hỗ trợ ML của bạn. Tuy nhiên, do có nhiều loại phần cứng và trình điều khiển mà người dùng của bạn có thể có, việc chọn cấu hình tăng tốc phần cứng tối ưu cho thiết bị của mỗi người dùng có thể là một thách thức. Hơn nữa, việc bật cấu hình sai trên thiết bị có thể tạo ra trải nghiệm người dùng kém do độ trễ cao hoặc trong một số trường hợp hiếm hoi là lỗi thời gian chạy hoặc sự cố về độ chính xác do không tương thích phần cứng.
Dịch vụ tăng tốc dành cho Android là một API giúp bạn chọn cấu hình tăng tốc phần cứng tối ưu cho một thiết bị người dùng nhất định và kiểu .tflite của bạn, đồng thời giảm thiểu rủi ro về lỗi thời gian chạy hoặc các vấn đề về độ chính xác.
Dịch vụ tăng tốc đánh giá các cấu hình tăng tốc khác nhau trên thiết bị người dùng bằng cách chạy điểm chuẩn suy luận nội bộ với mô hình TensorFlow Lite của bạn. Quá trình chạy thử này thường hoàn tất sau vài giây, tùy thuộc vào kiểu máy của bạn. Bạn có thể chạy điểm chuẩn một lần trên mọi thiết bị của người dùng trước thời gian suy luận, lưu kết quả vào bộ nhớ đệm và sử dụng kết quả đó trong quá trình suy luận. Những điểm chuẩn này đã hết quy trình; giúp giảm thiểu nguy cơ xảy ra sự cố cho ứng dụng của bạn.
Cung cấp mô hình, mẫu dữ liệu và kết quả mong đợi của bạn (đầu vào và đầu ra "vàng") và Dịch vụ tăng tốc sẽ chạy điểm chuẩn suy luận TFLite nội bộ để cung cấp cho bạn các đề xuất phần cứng.
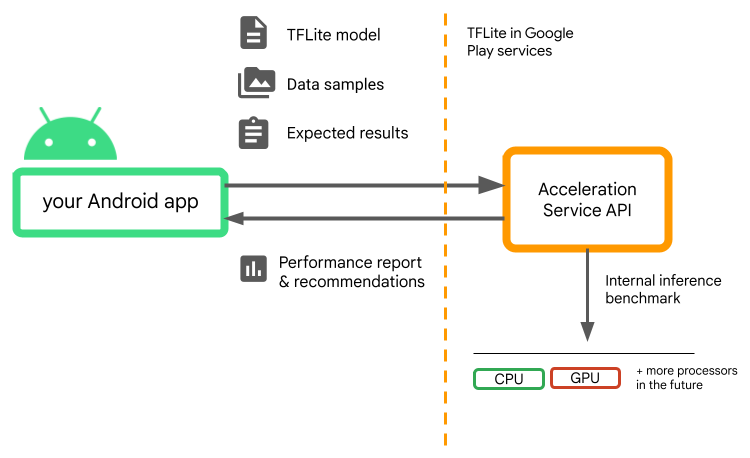
Dịch vụ tăng tốc là một phần trong ngăn xếp ML tùy chỉnh của Android và hoạt động với TensorFlow Lite trong các dịch vụ của Google Play .
Thêm các phần phụ thuộc vào dự án của bạn
Thêm các phần phụ thuộc sau vào tệp build.gradle của ứng dụng của bạn:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.0.0-beta01"
API dịch vụ tăng tốc hoạt động với TensorFlow Lite trong Dịch vụ của Google Play . Nếu bạn chưa sử dụng thời gian chạy TensorFlow Lite được cung cấp qua Dịch vụ Play, bạn sẽ cần cập nhật các phần phụ thuộc của mình.
Cách sử dụng API dịch vụ tăng tốc
Để sử dụng Dịch vụ tăng tốc, hãy bắt đầu bằng cách tạo cấu hình tăng tốc mà bạn muốn đánh giá cho mô hình của mình (ví dụ: GPU có OpenGL). Sau đó, tạo cấu hình xác thực với mô hình của bạn, một số dữ liệu mẫu và đầu ra mô hình dự kiến. Cuối cùng, hãy gọi validateConfig() để chuyển cả cấu hình tăng tốc và cấu hình xác thực của bạn.

Tạo cấu hình tăng tốc
Cấu hình tăng tốc là sự thể hiện của cấu hình phần cứng được dịch sang các đại biểu trong thời gian thực hiện. Sau đó, Dịch vụ tăng tốc sẽ sử dụng các cấu hình này trong nội bộ để thực hiện các suy luận kiểm tra.
Hiện tại, dịch vụ tăng tốc cho phép bạn đánh giá cấu hình GPU (được chuyển đổi thành đại biểu GPU trong thời gian thực thi) bằng suy luận GpuAccelerationConfig và CPU (với CpuAccelerationConfig ). Chúng tôi đang nỗ lực hỗ trợ nhiều đại biểu hơn truy cập vào phần cứng khác trong tương lai.
Cấu hình tăng tốc GPU
Tạo cấu hình tăng tốc GPU như sau:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Bạn phải chỉ định xem mô hình của mình có đang sử dụng lượng tử hóa với setEnableQuantizedInference() hay không.
Cấu hình tăng tốc CPU
Tạo khả năng tăng tốc CPU như sau:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Sử dụng phương thức setNumThreads() để xác định số lượng luồng bạn muốn sử dụng để đánh giá suy luận của CPU.
Tạo cấu hình xác thực
Cấu hình xác thực cho phép bạn xác định cách bạn muốn Dịch vụ tăng tốc đánh giá các suy luận. Bạn sẽ sử dụng chúng để vượt qua:
- mẫu đầu vào,
- kết quả dự kiến,
- logic xác nhận độ chính xác.
Đảm bảo cung cấp các mẫu đầu vào mà bạn mong đợi mô hình của mình hoạt động tốt (còn được gọi là mẫu “vàng”).
Tạo một ValidationConfig với CustomValidationConfig.Builder như sau:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Chỉ định số lượng mẫu vàng bằng setBatchSize() . Chuyển đầu vào của các mẫu vàng của bạn bằng cách sử dụng setGoldenInputs() . Cung cấp đầu ra dự kiến cho đầu vào được truyền bằng setGoldenOutputs() .
Bạn có thể xác định thời gian suy luận tối đa bằng setInferenceTimeoutMillis() (5000 ms theo mặc định). Nếu quá trình suy luận mất nhiều thời gian hơn thời gian bạn xác định, cấu hình sẽ bị từ chối.
Theo tùy chọn, bạn cũng có thể tạo AccuracyValidator tùy chỉnh như sau:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Đảm bảo xác định logic xác thực phù hợp với trường hợp sử dụng của bạn.
Lưu ý rằng nếu dữ liệu xác thực đã được nhúng trong mô hình của bạn, bạn có thể sử dụng EmbeddedValidationConfig .
Tạo đầu ra xác thực
Đầu ra vàng là tùy chọn và miễn là bạn cung cấp đầu vào vàng, Dịch vụ tăng tốc có thể tạo ra các đầu ra vàng trong nội bộ. Bạn cũng có thể xác định cấu hình tăng tốc được sử dụng để tạo ra các đầu ra vàng này bằng cách gọi setGoldenConfig() :
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Xác thực cấu hình tăng tốc
Khi bạn đã tạo cấu hình tăng tốc và cấu hình xác thực, bạn có thể đánh giá chúng cho mô hình của mình.
Đảm bảo rằng thời gian chạy TensorFlow Lite với Dịch vụ Play được khởi tạo đúng cách và đại biểu GPU có sẵn cho thiết bị bằng cách chạy:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Khởi tạo AccelerationService bằng cách gọi AccelerationService.create() .
Sau đó, bạn có thể xác thực cấu hình tăng tốc cho mô hình của mình bằng cách gọi validateConfig() :
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
Bạn cũng có thể xác thực nhiều cấu hình bằng cách gọi validateConfigs() và truyền đối tượng Iterable<AccelerationConfig> làm tham số.
validateConfig() sẽ trả về Task< ValidatedAccelerationConfigResult > từ Api nhiệm vụ của dịch vụ Google Play để cho phép thực hiện các tác vụ không đồng bộ.
Để nhận kết quả từ lệnh gọi xác thực, hãy thêm lệnh gọi lại addOnSuccessListener() .
Sử dụng cấu hình đã được xác thực trong trình thông dịch của bạn
Sau khi kiểm tra xem ValidatedAccelerationConfigResult được trả về trong lệnh gọi lại có hợp lệ hay không, bạn có thể đặt cấu hình đã được xác thực làm cấu hình tăng tốc cho trình thông dịch của mình đang gọi interpreterOptions.setAccelerationConfig() .
Bộ nhớ đệm cấu hình
Cấu hình tăng tốc tối ưu cho kiểu máy của bạn khó có thể thay đổi trên thiết bị. Vì vậy, sau khi nhận được cấu hình tăng tốc vừa ý, bạn nên lưu trữ cấu hình đó trên thiết bị và để ứng dụng của bạn truy xuất cấu hình đó cũng như sử dụng nó để tạo InterpreterOptions trong các phiên tiếp theo thay vì chạy một xác thực khác. Các phương thức serialize() và deserialize() trong ValidatedAccelerationConfigResult giúp quá trình lưu trữ và truy xuất dễ dàng hơn.
Ứng dụng mẫu
Để xem xét việc tích hợp tại chỗ của Dịch vụ tăng tốc, hãy xem ứng dụng mẫu .
Hạn chế
Dịch vụ tăng tốc hiện có những hạn chế sau:
- Hiện tại chỉ hỗ trợ cấu hình tăng tốc CPU và GPU,
- Nó chỉ hỗ trợ TensorFlow Lite trong các dịch vụ của Google Play và bạn không thể sử dụng nó nếu bạn đang sử dụng phiên bản đi kèm của TensorFlow Lite,
- Nó không hỗ trợ Thư viện tác vụ TensorFlow Lite vì bạn không thể khởi tạo trực tiếp
BaseOptionsbằng đối tượngValidatedAccelerationConfigResult. - SDK dịch vụ tăng tốc chỉ hỗ trợ API cấp 22 trở lên.
Hãy cẩn thận
Vui lòng xem lại cẩn thận những lưu ý sau, đặc biệt nếu bạn dự định sử dụng SDK này trong sản xuất:
Trước khi thoát Beta và phát hành phiên bản ổn định cho API dịch vụ tăng tốc, chúng tôi sẽ xuất bản SDK mới có thể có một số khác biệt so với phiên bản Beta hiện tại. Để tiếp tục sử dụng Dịch vụ tăng tốc, bạn sẽ cần di chuyển sang SDK mới này và cập nhật kịp thời cho ứng dụng của mình. Không làm như vậy có thể gây ra sự cố vì SDK Beta có thể không còn tương thích với các dịch vụ của Google Play sau một thời gian.
Không có gì đảm bảo rằng một tính năng cụ thể trong API Dịch vụ tăng tốc hoặc toàn bộ API sẽ khả dụng rộng rãi. Nó có thể vẫn ở bản Beta vô thời hạn, bị tắt hoặc được kết hợp với các tính năng khác thành các gói được thiết kế cho đối tượng nhà phát triển cụ thể. Một số tính năng với API dịch vụ tăng tốc hoặc toàn bộ API cuối cùng có thể được cung cấp rộng rãi nhưng không có lịch trình cố định cho việc này.
Điều khoản và quyền riêng tư
Điều khoản dịch vụ
Việc sử dụng API dịch vụ tăng tốc phải tuân theo Điều khoản dịch vụ của API Google .
Ngoài ra, API Dịch vụ tăng tốc hiện đang ở giai đoạn thử nghiệm và do đó, khi sử dụng API này, bạn thừa nhận các vấn đề tiềm ẩn được nêu trong phần Hãy cẩn thận ở trên và thừa nhận rằng Dịch vụ tăng tốc có thể không phải lúc nào cũng hoạt động như đã chỉ định.
Sự riêng tư
Khi bạn sử dụng API Dịch vụ tăng tốc, việc xử lý dữ liệu đầu vào (ví dụ: hình ảnh, video, văn bản) diễn ra hoàn toàn trên thiết bị và Dịch vụ tăng tốc không gửi dữ liệu đó đến máy chủ Google . Do đó, bạn có thể sử dụng API của chúng tôi để xử lý dữ liệu đầu vào không nên rời khỏi thiết bị.
API dịch vụ tăng tốc đôi khi có thể liên hệ với máy chủ Google để nhận những nội dung như sửa lỗi, mô hình cập nhật và thông tin về khả năng tương thích của trình tăng tốc phần cứng. API dịch vụ tăng tốc cũng gửi số liệu về hiệu suất và mức sử dụng API trong ứng dụng của bạn tới Google. Google sử dụng dữ liệu số liệu này để đo lường hiệu suất, gỡ lỗi, duy trì và cải thiện API cũng như phát hiện hành vi sử dụng sai hoặc lạm dụng, như được mô tả thêm trong Chính sách quyền riêng tư của chúng tôi.
Bạn có trách nhiệm thông báo cho người dùng ứng dụng của mình về việc Google xử lý dữ liệu số liệu Dịch vụ tăng tốc theo yêu cầu của luật hiện hành.
Dữ liệu chúng tôi thu thập bao gồm:
- Thông tin thiết bị (chẳng hạn như nhà sản xuất, kiểu máy, phiên bản hệ điều hành và bản dựng) và các bộ tăng tốc phần cứng ML có sẵn (GPU và DSP). Được sử dụng để chẩn đoán và phân tích sử dụng.
- Thông tin ứng dụng (tên gói/id gói, phiên bản ứng dụng). Được sử dụng để chẩn đoán và phân tích sử dụng.
- Cấu hình API (chẳng hạn như định dạng và độ phân giải hình ảnh). Được sử dụng để chẩn đoán và phân tích sử dụng.
- Loại sự kiện (chẳng hạn như khởi tạo, tải xuống mô hình, cập nhật, chạy, phát hiện). Được sử dụng để chẩn đoán và phân tích sử dụng.
- Mã lỗi. Được sử dụng để chẩn đoán.
- Chỉ số hiệu suất. Được sử dụng để chẩn đoán.
- Giá trị nhận dạng mỗi lần cài đặt không nhận dạng duy nhất người dùng hoặc thiết bị vật lý. Được sử dụng để vận hành cấu hình từ xa và phân tích sử dụng.
- Địa chỉ IP của người gửi yêu cầu mạng. Được sử dụng để chẩn đoán cấu hình từ xa. Địa chỉ IP đã thu thập được giữ lại tạm thời.
Hỗ trợ và phản hồi
Bạn có thể cung cấp phản hồi và nhận hỗ trợ thông qua Trình theo dõi sự cố TensorFlow. Vui lòng báo cáo sự cố và yêu cầu hỗ trợ bằng cách sử dụng mẫu sự cố dành cho TensorFlow Lite trong các dịch vụ của Google Play.