

कोई ऑडियो क्या दर्शाता है, इसकी पहचान करने के कार्य को ऑडियो वर्गीकरण कहा जाता है। एक ऑडियो वर्गीकरण मॉडल को विभिन्न ऑडियो घटनाओं को पहचानने के लिए प्रशिक्षित किया जाता है। उदाहरण के लिए, आप एक मॉडल को तीन अलग-अलग घटनाओं का प्रतिनिधित्व करने वाली घटनाओं को पहचानने के लिए प्रशिक्षित कर सकते हैं: ताली बजाना, उंगली चटकाना और टाइपिंग। TensorFlow Lite अनुकूलित पूर्व-प्रशिक्षित मॉडल प्रदान करता है जिन्हें आप अपने मोबाइल एप्लिकेशन में तैनात कर सकते हैं। यहां TensorFlow का उपयोग करके ऑडियो वर्गीकरण के बारे में अधिक जानें।
निम्न छवि एंड्रॉइड पर ऑडियो वर्गीकरण मॉडल का आउटपुट दिखाती है।
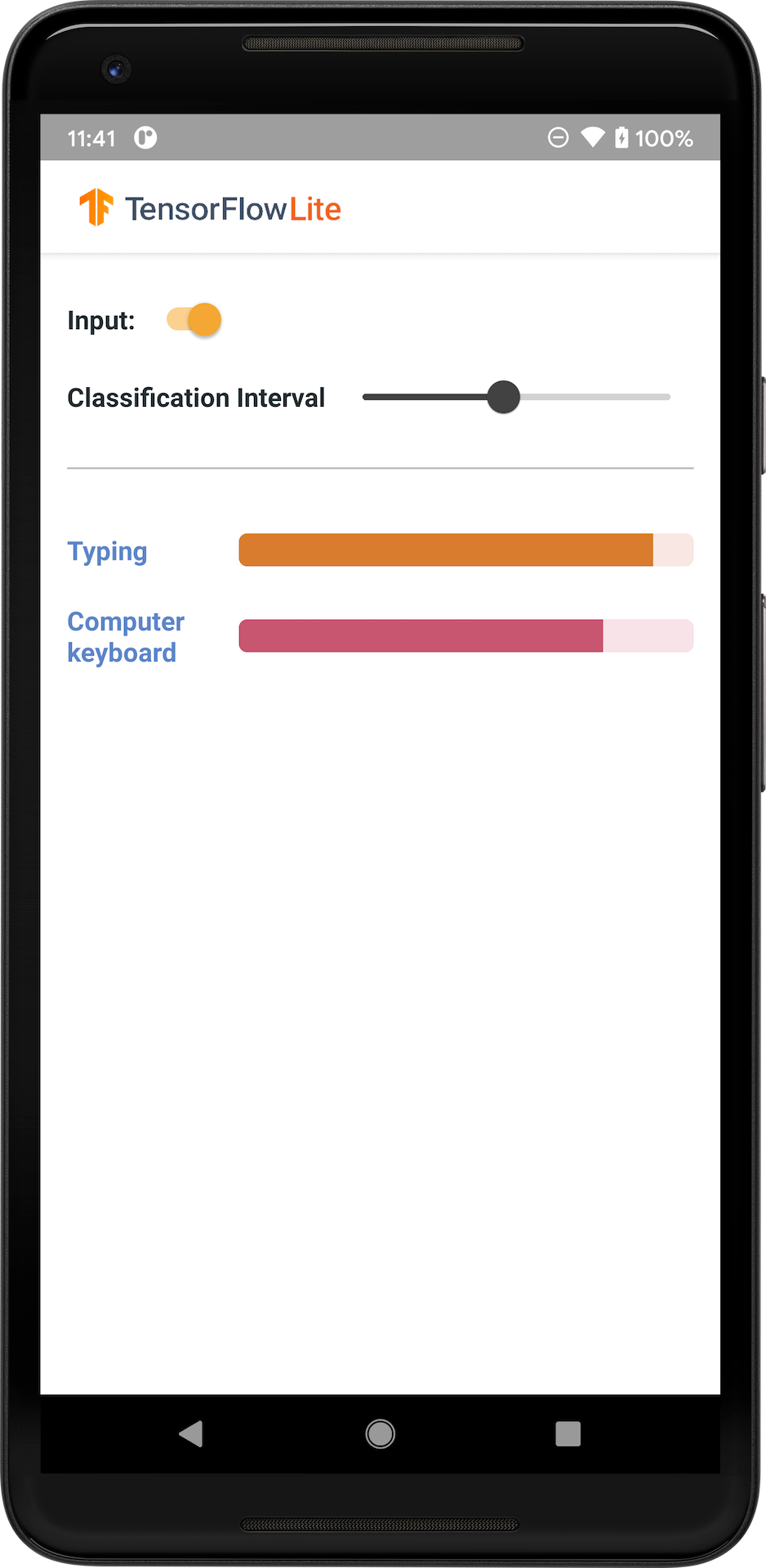
शुरू हो जाओ
यदि आप TensorFlow Lite में नए हैं और Android के साथ काम कर रहे हैं, तो हम निम्नलिखित उदाहरण अनुप्रयोगों की खोज करने की सलाह देते हैं जो आरंभ करने में आपकी सहायता कर सकते हैं।
आप कोड की कुछ पंक्तियों में ऑडियो वर्गीकरण मॉडल को एकीकृत करने के लिए टेन्सरफ्लो लाइट टास्क लाइब्रेरी से आउट-ऑफ-बॉक्स एपीआई का लाभ उठा सकते हैं। आप TensorFlow Lite सपोर्ट लाइब्रेरी का उपयोग करके अपनी स्वयं की कस्टम अनुमान पाइपलाइन भी बना सकते हैं।
नीचे दिया गया Android उदाहरण TFLite टास्क लाइब्रेरी का उपयोग करके कार्यान्वयन को दर्शाता है
यदि आप Android/iOS के अलावा किसी अन्य प्लेटफ़ॉर्म का उपयोग कर रहे हैं, या यदि आप पहले से ही TensorFlow Lite API से परिचित हैं, तो स्टार्टर मॉडल और सहायक फ़ाइलें डाउनलोड करें (यदि लागू हो)।
TensorFlow हब से स्टार्टर मॉडल डाउनलोड करें
मॉडल वर्णन
YAMNet एक ऑडियो इवेंट क्लासिफायरियर है जो ऑडियो तरंग को इनपुट के रूप में लेता है और ऑडियोसेट ऑन्टोलॉजी से 521 ऑडियो इवेंट में से प्रत्येक के लिए स्वतंत्र भविष्यवाणी करता है। मॉडल MobileNet v1 आर्किटेक्चर का उपयोग करता है और ऑडियोसेट कॉर्पस का उपयोग करके प्रशिक्षित किया गया था। यह मॉडल मूल रूप से टेन्सरफ्लो मॉडल गार्डन में जारी किया गया था, जहां मॉडल स्रोत कोड, मूल मॉडल चेकपॉइंट और अधिक विस्तृत दस्तावेज़ीकरण है।
यह काम किस प्रकार करता है
YAMNet मॉडल के दो संस्करण हैं जिन्हें TFLite में परिवर्तित किया गया है:
YAMNet मूल ऑडियो वर्गीकरण मॉडल है, गतिशील इनपुट आकार के साथ, ट्रांसफर लर्निंग, वेब और मोबाइल परिनियोजन के लिए उपयुक्त है। इसका आउटपुट भी अधिक जटिल है।
YAMNet/वर्गीकरण एक सरल निश्चित लंबाई फ्रेम इनपुट (15600 नमूने) के साथ एक परिमाणित संस्करण है और 521 ऑडियो इवेंट कक्षाओं के लिए स्कोर का एक एकल वेक्टर लौटाता है।
इनपुट
मॉडल 15600 लंबाई के 1-डी float32 टेंसर या न्यूमपी ऐरे को स्वीकार करता है जिसमें 0.975 सेकंड का वेवफॉर्म होता है जिसे [-1.0, +1.0] रेंज में मोनो 16 किलोहर्ट्ज़ नमूनों के रूप में दर्शाया जाता है।
आउटपुट
मॉडल आकार (1, 521) का 2-डी float32 टेंसर लौटाता है जिसमें ऑडियोसेट ऑन्टोलॉजी में 521 वर्गों में से प्रत्येक के लिए अनुमानित स्कोर शामिल हैं जो YAMNet द्वारा समर्थित हैं। स्कोर टेंसर के कॉलम इंडेक्स (0-520) को YAMNet क्लास मैप का उपयोग करके संबंधित ऑडियोसेट क्लास नाम पर मैप किया जाता है, जो मॉडल फ़ाइल में पैक की गई संबंधित फ़ाइल yamnet_label_list.txt के रूप में उपलब्ध है। उपयोग के लिए नीचे देखें.
उपयुक्त उपयोग
YAMNet का उपयोग किया जा सकता है
- एक स्टैंड-अलोन ऑडियो इवेंट क्लासिफायरियर के रूप में जो विभिन्न प्रकार के ऑडियो इवेंट में उचित आधार रेखा प्रदान करता है।
- एक उच्च स्तरीय फीचर एक्सट्रैक्टर के रूप में: YAMNet के 1024-डी एम्बेडिंग आउटपुट का उपयोग किसी अन्य मॉडल की इनपुट सुविधाओं के रूप में किया जा सकता है जिसे किसी विशेष कार्य के लिए थोड़ी मात्रा में डेटा पर प्रशिक्षित किया जा सकता है। यह बहुत अधिक लेबल किए गए डेटा की आवश्यकता के बिना और एक बड़े मॉडल को शुरू से अंत तक प्रशिक्षित किए बिना तुरंत विशेष ऑडियो क्लासिफायर बनाने की अनुमति देता है।
- एक गर्मजोशी भरी शुरुआत के रूप में: YAMNet मॉडल पैरामीटर का उपयोग एक बड़े मॉडल के हिस्से को आरंभ करने के लिए किया जा सकता है जो तेजी से फाइन-ट्यूनिंग और मॉडल अन्वेषण की अनुमति देता है।
सीमाएँ
- YAMNet के क्लासिफायर आउटपुट को कक्षाओं में कैलिब्रेट नहीं किया गया है, इसलिए आप आउटपुट को सीधे संभावनाओं के रूप में नहीं मान सकते हैं। किसी भी दिए गए कार्य के लिए, आपको संभवतः कार्य-विशिष्ट डेटा के साथ अंशांकन करने की आवश्यकता होगी जो आपको उचित प्रति-वर्ग स्कोर सीमा और स्केलिंग निर्दिष्ट करने की सुविधा देता है।
- YAMNet को लाखों YouTube वीडियो पर प्रशिक्षित किया गया है और हालांकि ये बहुत विविध हैं, फिर भी औसत YouTube वीडियो और किसी भी कार्य के लिए अपेक्षित ऑडियो इनपुट के बीच एक डोमेन बेमेल हो सकता है। आपको अपने द्वारा बनाए गए किसी भी सिस्टम में YAMNet को प्रयोग योग्य बनाने के लिए कुछ मात्रा में फ़ाइन-ट्यूनिंग और कैलिब्रेशन करने की अपेक्षा करनी चाहिए।
मॉडल अनुकूलन
प्रदान किए गए पूर्व-प्रशिक्षित मॉडलों को 521 विभिन्न ऑडियो कक्षाओं का पता लगाने के लिए प्रशिक्षित किया जाता है। कक्षाओं की पूरी सूची के लिए, मॉडल रिपॉजिटरी में लेबल फ़ाइल देखें।
आप किसी मॉडल को मूल सेट में नहीं मौजूद कक्षाओं को पहचानने के लिए फिर से प्रशिक्षित करने के लिए ट्रांसफर लर्निंग नामक तकनीक का उपयोग कर सकते हैं। उदाहरण के लिए, आप एकाधिक पक्षी गीतों का पता लगाने के लिए मॉडल को फिर से प्रशिक्षित कर सकते हैं। ऐसा करने के लिए, आपको प्रत्येक नए लेबल के लिए प्रशिक्षण ऑडियो के एक सेट की आवश्यकता होगी जिसे आप प्रशिक्षित करना चाहते हैं। अनुशंसित तरीका TensorFlow Lite मॉडल मेकर लाइब्रेरी का उपयोग करना है जो कोड की कुछ पंक्तियों में कस्टम डेटासेट का उपयोग करके TensorFlow Lite मॉडल को प्रशिक्षित करने की प्रक्रिया को सरल बनाता है। यह आवश्यक प्रशिक्षण डेटा और समय की मात्रा को कम करने के लिए ट्रांसफर लर्निंग का उपयोग करता है। आप ट्रांसफ़र लर्निंग के उदाहरण के रूप में ऑडियो पहचान के लिए ट्रांसफ़र लर्निंग से भी सीख सकते हैं।
आगे पढ़ना और संसाधन
ऑडियो वर्गीकरण से संबंधित अवधारणाओं के बारे में अधिक जानने के लिए निम्नलिखित संसाधनों का उपयोग करें: