
| | |  Lihat sumber di GitHub Lihat sumber di GitHub |
Rekomendasi yang dipersonalisasi banyak digunakan untuk berbagai kasus penggunaan pada perangkat seluler, seperti pengambilan konten media, saran produk belanja, dan rekomendasi aplikasi berikutnya. Jika Anda tertarik untuk memberikan rekomendasi yang dipersonalisasi dalam aplikasi Anda dengan tetap menghormati privasi pengguna, kami sarankan untuk mempelajari contoh dan perangkat berikut.
Memulai
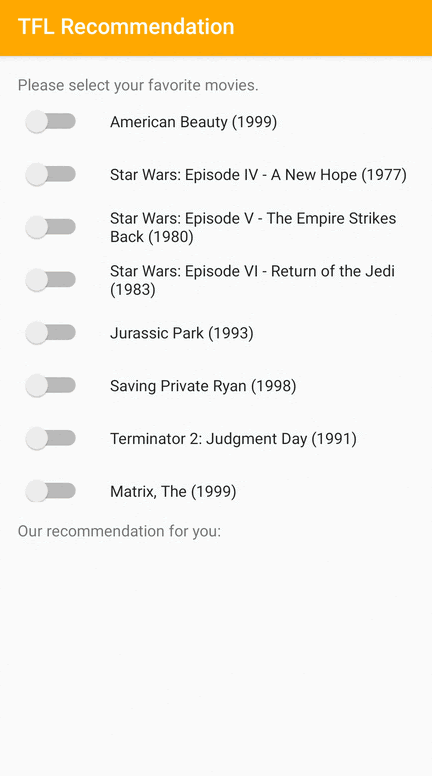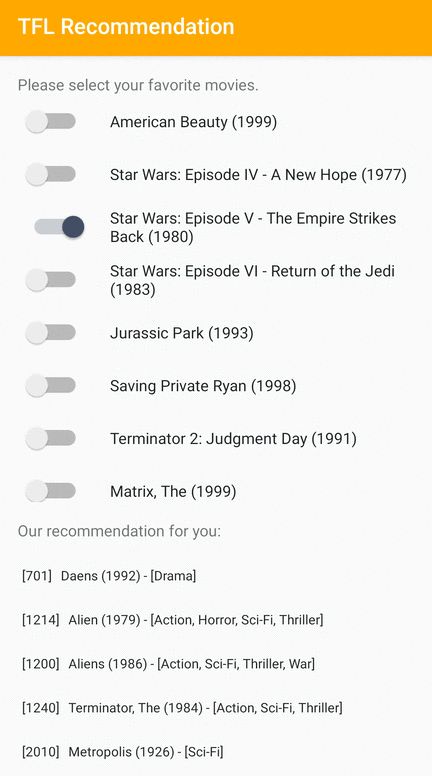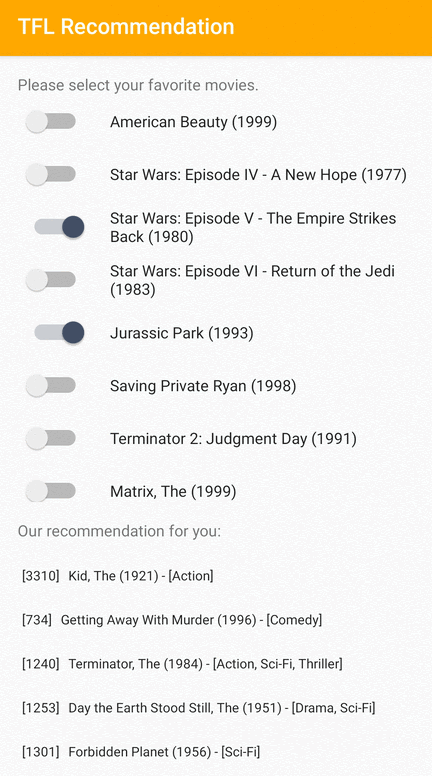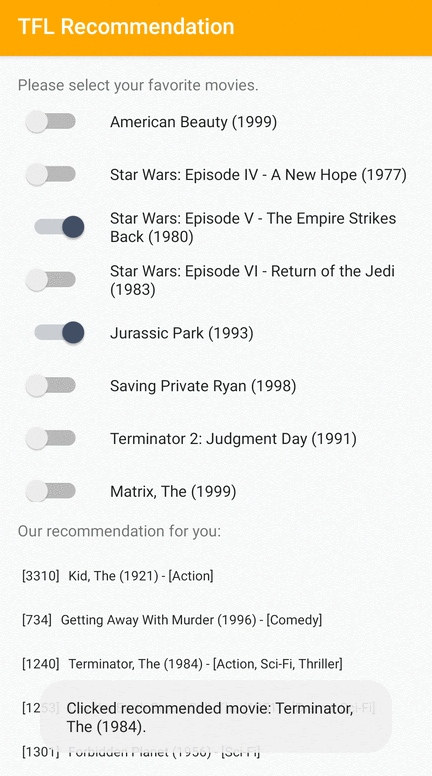
Kami menyediakan contoh aplikasi TensorFlow Lite yang menunjukkan cara merekomendasikan item yang relevan kepada pengguna di Android.
Jika Anda menggunakan platform selain Android, atau sudah familiar dengan TensorFlow Lite API, Anda dapat mendownload model rekomendasi awal kami.
Kami juga menyediakan skrip pelatihan di Github untuk melatih model Anda sendiri dengan cara yang dapat dikonfigurasi.
Memahami arsitektur model
Kami memanfaatkan arsitektur model encoder ganda, dengan encoder konteks untuk mengkodekan riwayat pengguna berurutan dan encoder label untuk mengkodekan kandidat rekomendasi yang diprediksi. Kesamaan antara konteks dan pengkodean label digunakan untuk mewakili kemungkinan bahwa kandidat yang diprediksi memenuhi kebutuhan pengguna.
Tiga teknik pengkodean riwayat pengguna berurutan yang berbeda disediakan dengan basis kode ini:
- Encoder bag-of-words (BOW): rata-rata penyematan aktivitas pengguna tanpa mempertimbangkan urutan konteks.
- Encoder jaringan saraf konvolusional (CNN): menerapkan beberapa lapisan jaringan saraf konvolusional untuk menghasilkan pengkodean konteks.
- Encoder jaringan saraf berulang (RNN): menerapkan jaringan saraf berulang untuk menyandikan urutan konteks.
Untuk memodelkan setiap aktivitas pengguna, kita dapat menggunakan ID item aktivitas (berbasis ID), atau beberapa fitur item (berbasis fitur), atau kombinasi keduanya. Model berbasis fitur yang memanfaatkan banyak fitur untuk mengkodekan perilaku pengguna secara kolektif. Dengan basis kode ini, Anda dapat membuat model berbasis ID atau berbasis fitur dengan cara yang dapat dikonfigurasi.
Setelah pelatihan, model TensorFlow Lite akan diekspor yang dapat langsung memberikan prediksi K teratas di antara kandidat rekomendasi.
Gunakan data pelatihan Anda
Selain model yang dilatih, kami menyediakan toolkit sumber terbuka di GitHub untuk melatih model dengan data Anda sendiri. Anda dapat mengikuti tutorial ini untuk mempelajari cara menggunakan toolkit dan menerapkan model terlatih dalam aplikasi seluler Anda.
Silakan ikuti tutorial ini untuk menerapkan teknik yang sama yang digunakan di sini untuk melatih model rekomendasi menggunakan kumpulan data Anda sendiri.
Contoh
Sebagai contoh, kami melatih model rekomendasi dengan pendekatan berbasis ID dan berbasis fitur. Model berbasis ID hanya menggunakan ID film sebagai masukan, dan model berbasis fitur menggunakan ID film dan ID genre film sebagai masukan. Silakan temukan contoh input dan output berikut.
masukan
ID film konteks:
- Raja Singa (ID: 362)
- Cerita Mainan (ID: 1)
- (dan banyak lagi)
ID genre film konteks:
- Animasi (ID: 15)
- Anak-anak (ID: 9)
- Musikal (ID: 13)
- Animasi (ID: 15)
- Anak-anak (ID: 9)
- Komedi (ID: 2)
- (dan banyak lagi)
Keluaran:
- ID film yang direkomendasikan:
- Cerita Mainan 2 (ID: 3114)
- (dan banyak lagi)
Tolok ukur kinerja
Angka tolok ukur kinerja dihasilkan dengan alat yang dijelaskan di sini .
| Nama model | Ukuran Model | Perangkat | CPU |
|---|---|---|---|
| rekomendasi (ID film sebagai masukan) | 0,52 Mb | Piksel 3 | 0,09 md* |
| Piksel 4 | 0,05 md* | ||
| rekomendasi (ID film dan genre film sebagai masukan) | 1,3 Mb | Piksel 3 | 0,13 md* |
| Piksel 4 | 0,06 md* |
* 4 benang digunakan.
Gunakan data pelatihan Anda
Selain model yang dilatih, kami menyediakan toolkit sumber terbuka di GitHub untuk melatih model dengan data Anda sendiri. Anda dapat mengikuti tutorial ini untuk mempelajari cara menggunakan toolkit dan menerapkan model terlatih dalam aplikasi seluler Anda.
Silakan ikuti tutorial ini untuk menerapkan teknik yang sama yang digunakan di sini untuk melatih model rekomendasi menggunakan kumpulan data Anda sendiri.
Tips untuk penyesuaian model dengan data Anda
Model terlatih yang terintegrasi dalam aplikasi demo ini dilatih dengan kumpulan data MovieLens , Anda mungkin ingin mengubah konfigurasi model berdasarkan data Anda sendiri, seperti ukuran kosakata, penyematan dim, dan panjang konteks masukan. Berikut beberapa tipnya:
Panjang konteks masukan: Panjang konteks masukan terbaik bervariasi menurut kumpulan data. Kami menyarankan untuk memilih panjang konteks masukan berdasarkan seberapa banyak peristiwa label berkorelasi dengan kepentingan jangka panjang vs konteks jangka pendek.
Pemilihan jenis encoder: kami menyarankan memilih jenis encoder berdasarkan panjang konteks input. Encoder bag-of-words bekerja dengan baik untuk panjang konteks masukan yang pendek (misalnya <10), encoder CNN dan RNN menghadirkan lebih banyak kemampuan peringkasan untuk panjang konteks masukan yang panjang.
Menggunakan fitur dasar untuk merepresentasikan item atau aktivitas pengguna dapat meningkatkan performa model, mengakomodasi item baru dengan lebih baik, kemungkinan memperkecil ruang penyematan sehingga mengurangi konsumsi memori dan lebih ramah pada perangkat.