
Edge デバイスではメモリや計算能力が限られていることがよくあります。モデルにさまざまな最適化を適用すると、これらの制約内で実行できるようになります。また、一部の最適化では、推論を加速するための専用ハードウェアを使用できます。
TensorFlow Lite と TensorFlow モデル最適化ツールキットは推論の最適化の複雑さを最小限に抑えるツールを提供します。
アプリ開発プロセス時に、モデルの最適化を検討することをお勧めします。このドキュメントでは、Edge ハードウェアへのデプロイのために TensorFlow モデルを最適化するためのいくつかのベストプラクティスについて概説します。
モデルを最適化する理由
モデルの最適化は、アプリ開発において以下の点で役に立ちます。
サイズ縮小
一部の形式の最適化は、モデルのサイズを縮小するために使用できます。小さいモデルには次の利点があります。
- 小さいストレージサイズ: モデルが小さいほど、ユーザーデバイスでのストレージ容量が少なくなります。たとえば、小さいモデルを使用する Android アプリは、ユーザーのモバイルデバイス上で使用するストレージ容量が少なくなります。
- 小さいダウンロードサイズ: モデルが小さいほど、ユーザーのデバイスにダウンロードするのに必要な時間と帯域幅が少なくなります。
- 少ないメモリ使用量: モデルが小さいほど、実行時に使用する RAM が少なくなります。メモリが解放されるので、アプリの他の部分がメモリを使用できるようになり、パフォーマンスと安定性が向上します。
量子化により、これらのすべてのケースでモデルのサイズを縮小できますが、精度が低下する可能性があります。プルーニングとクラスタリングは、モデルをより簡単に圧縮できるようにすることで、ダウンロード用のモデルのサイズを縮小します。
レイテンシ短縮
レイテンシは、モデルで単一の推論を実行するのにかかる時間です。一部の形式の最適化では、モデルを使用して推論を実行するために必要な計算量を減らすことができるため、レイテンシを短縮できます。また、レイテンシは消費電力に影響を与える可能性があります。
現在、量子化を使用して、推論中に発生する計算を単純化することにより、レイテンシを削減できます(精度が少々低下する場合があります)。
アクセラレータの互換性
Edge TPU などの一部のハードウェアアクセラレータは、正しく最適化されたモデルでは非常に高速に推論を実行します。
一般に、これらの種類のデバイスでは、モデルを特定の方法で量子化する必要があります。要件についての詳細は、各ハードウェアアクセラレータのドキュメントをご覧ください。
トレードオフ
最適化により、モデルの精度が変更する可能性があります。これは、アプリ開発プロセス中に考慮する必要があります。
精度の変更は、最適化される個々のモデルに依存するため、事前に予測することは困難です。一般に、サイズまたはレイテンシが最適化されたモデルでは、精度がわずかに低下します。アプリに応じては、これによりユーザーエクスペリエンスが影響される場合があります。まれに、特定のモデルでは最適化プロセスの結果として精度がやや向上する場合があります。
最適化の種類
TensorFlow Lite は現在、量子化、プルーニング、クラスタリングによる最適化をサポートしています。
これらは TensorFlow Lite と 互換性のあるモデル最適化手法のリソースである TensorFlow モデル最適化ツールキットに含まれています。
量子化
量子化は、モデルのパラメータを表すために使用される数値の精度を下げることで機能します。モデルの精度はデフォルトでは 32 ビットの浮動小数点数です。量子化より、モデルサイズが小さくなり、計算が高速になります。
TensorFlow Lite で使用できる量子化の種類は次のとおりです。
| 手法 | データ要件 | サイズ縮小 | 精度 | 対応ハードウェア |
|---|---|---|---|---|
| トレーニング後の float16 量子化 | データなし | 50% 以下 | 精度低下(ごくわずか) | CPU、GPU |
| トレーニング後のダイナミックレンジ量子化 | データなし | 75% 以下 | 精度低下(ごく少量) | CPU、GPU (Android) |
| トレーニング後の整数量子化 | ラベルなしの代表的なサンプル | 75% 以下 | 精度低下(少量) | CPU, GPU (Android)、EdgeTPU、Hexagon DSP |
| 量子化認識トレーニング | ラベル付けされたトレーニングデータ | 75% 以下 | 精度低下(ごく少量) | CPU, GPU (Android)、EdgeTPU、Hexagon DSP |
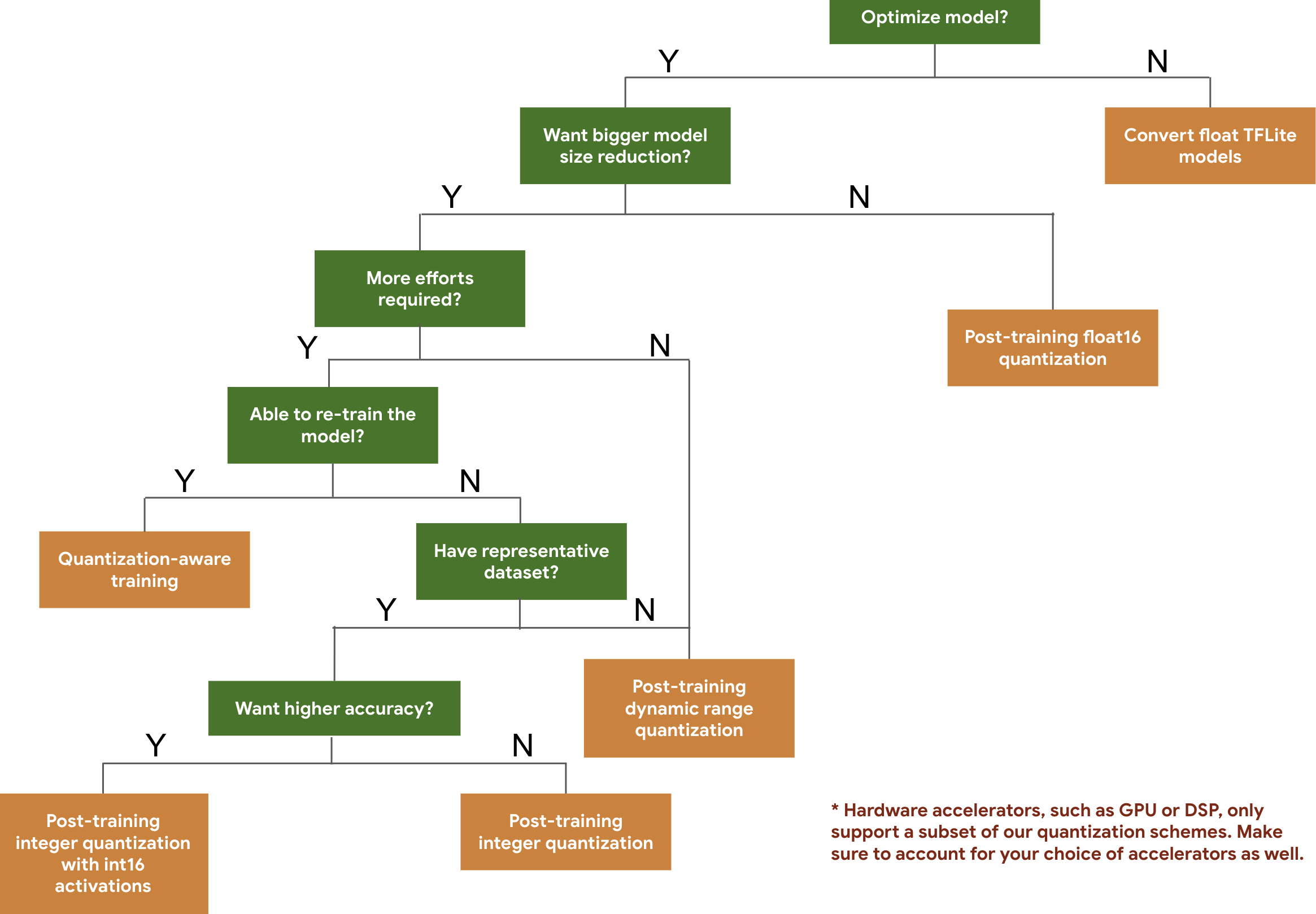
単純に期待されるモデルのサイズと精度の基づいて、モデルに使用する量子化スキームを選択するには、次の決定木を使用することができます。
以下は、いくつかのモデルでのトレーニング後の量子化および量子化認識トレーニングのレイテンシと精度の結果です。すべてのレイテンシ数は、1 つの大型コア CPU を使用する Pixel 2 デバイスで測定されます。ツールキットが改善されると、以下の数値も改善されます。
| Model | Top-1 Accuracy (Original) | Top-1 Accuracy (Post Training Quantized) | Top-1 Accuracy (Quantization Aware Training) | Latency (Original) (ms) | Latency (Post Training Quantized) (ms) | Latency (Quantization Aware Training) (ms) | Size (Original) (MB) | Size (Optimized) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | N/A | 3973 | 2868 | N/A | 178.3 | 44.9 |
int16 アクティベーションと int8 重みを使用した完全整数量子化
int16 アクティベーションによる量子化は、int16 アクティベーション、および、int8 重みを使用する完全整数の量子化スキームです。このモードでは、同様のモデルサイズの完全整数量子化スキームと比較して、int8 のアクティベーションと重みの両方が量子化モデルの精度を向上させることができます。アクティベーションが量子化に敏感な場合に推奨されます。
注意: 現在、この量子化スキームは TFLite の最適化されていないレファレンスカーネルの実装のみでしか利用できないため、デフォルトでは、int8 カーネルと比較してパフォーマンスが低下します。このモードのすべての利点は、現在、専用のハードウェアまたはカスタムソフトウェアを介してアクセスできます。
このモードから利益を得られるモデルの精度結果は以下のようになります。
| Model | Accuracy metric type | Accuracy (float32 activations) | Accuracy (int8 activations) | Accuracy (int16 activations) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (unrolled) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | Top-1 Accuracy | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | Top-1 Accuracy | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(Exact match) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
プルーニング
プルーニングは、予測への影響が小さいモデル内のパラメータを削除します。プルーニングされたモデルはディスク上では同じサイズで、ランタイムのレイテンシは同じですが、より効果的に圧縮できます。プルーニングはモデルのダウンロードサイズを縮小するための便利な手法です。
今後、TensorFlow Lite ではプルーニングされたモデルのレイテンシが低減される予定です。
クラスタリング
クラスタリングはモデル内の各レイヤーの重みを事前定義された数のクラスタにグループ化し、個々のクラスタに属する重みの重心値を共有します。これにより、モデル内の一意の重み値の数が減り、複雑さが軽減されます。
その結果、クラスタ化されたモデルをより効果的に圧縮でき、プルーニングと同様にデプロイメントにおける利点を提供します。
開発ワークフロー
まず、ホステッドモデルのモデルがアプリケーションで機能することを確認します。機能しない場合は、トレーニング後の量子化ツールから始めることをお勧めします。これはトレーニングデータを必要としないため、幅広く適用できます。
精度とレイテンシが不十分な場合やハードウェアアクセラレータのサポートが重要な場合は、量子化認識トレーニングが最適なオプションです。TensorFlow モデル最適化ツールキットで追加の最適化手法をご覧ください。