
يركز التعلم المنظم العصبي (NSL) على تدريب الشبكات العصبية العميقة من خلال الاستفادة من الإشارات المنظمة (عند توفرها) إلى جانب مدخلات الميزات. كما قدم بوي وآخرون. (WSDM'18) ، تُستخدم هذه الإشارات المنظمة لتنظيم تدريب الشبكة العصبية، مما يجبر النموذج على تعلم تنبؤات دقيقة (عن طريق تقليل الخسارة الخاضعة للإشراف)، مع الحفاظ في نفس الوقت على التشابه الهيكلي للمدخلات (عن طريق تقليل خسارة الجوار ، انظر الشكل أدناه). هذه التقنية عامة ويمكن تطبيقها على البنى العصبية التعسفية (مثل NNs ذات التغذية الأمامية، والشبكات العصبية التلافيفية، والشبكات العصبية المتكررة).
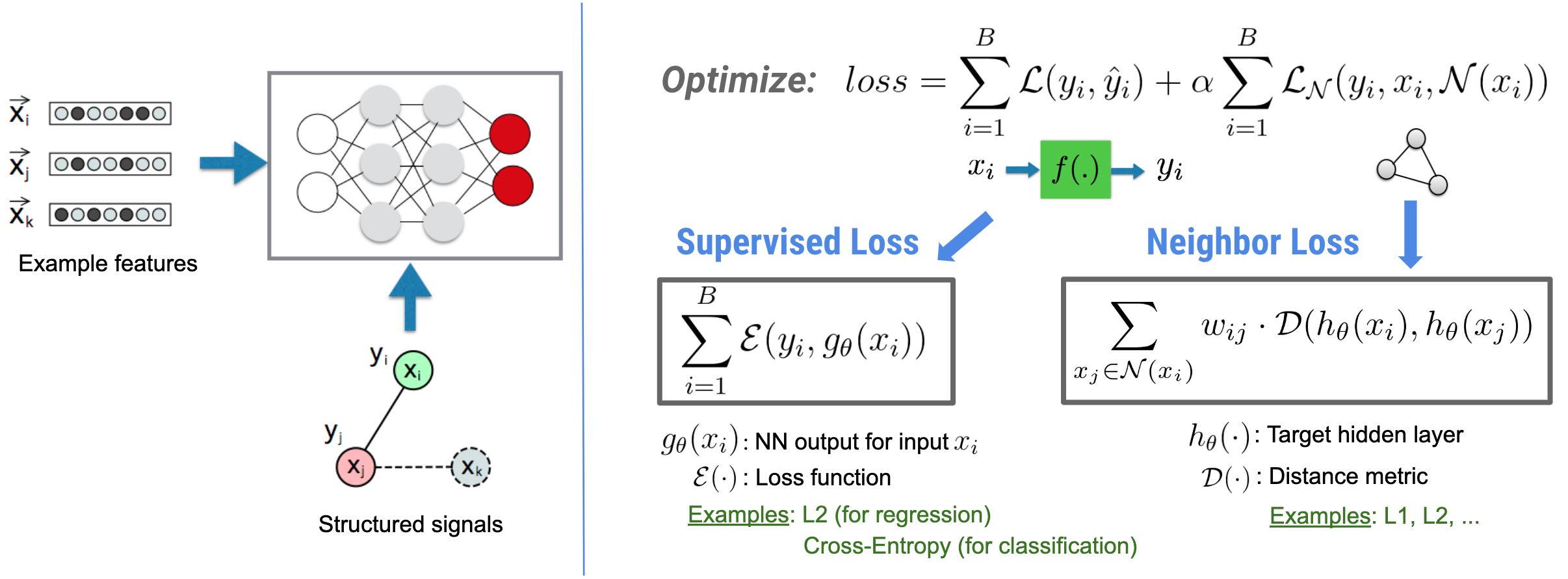
لاحظ أن معادلة خسارة الجوار المعممة مرنة ويمكن أن يكون لها أشكال أخرى إلى جانب الشكل الموضح أعلاه. على سبيل المثال، يمكننا أيضًا الاختيار\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ليكون الجار خسارة، وهو يحسب المسافة بين الحقيقة والأرض \(y_i\)والتنبؤ من الجار \(g_\theta(x_j)\). ويشيع استخدام هذا في التعلم التنافسي (Goodfellow et al., ICLR'15) . لذلك، يعمم NSL على تعلم الرسم البياني العصبي إذا تم تمثيل الجيران بشكل صريح من خلال رسم بياني، وعلى التعلم العدائي إذا تم تحفيز الجيران ضمنيًا عن طريق اضطراب الخصومة.
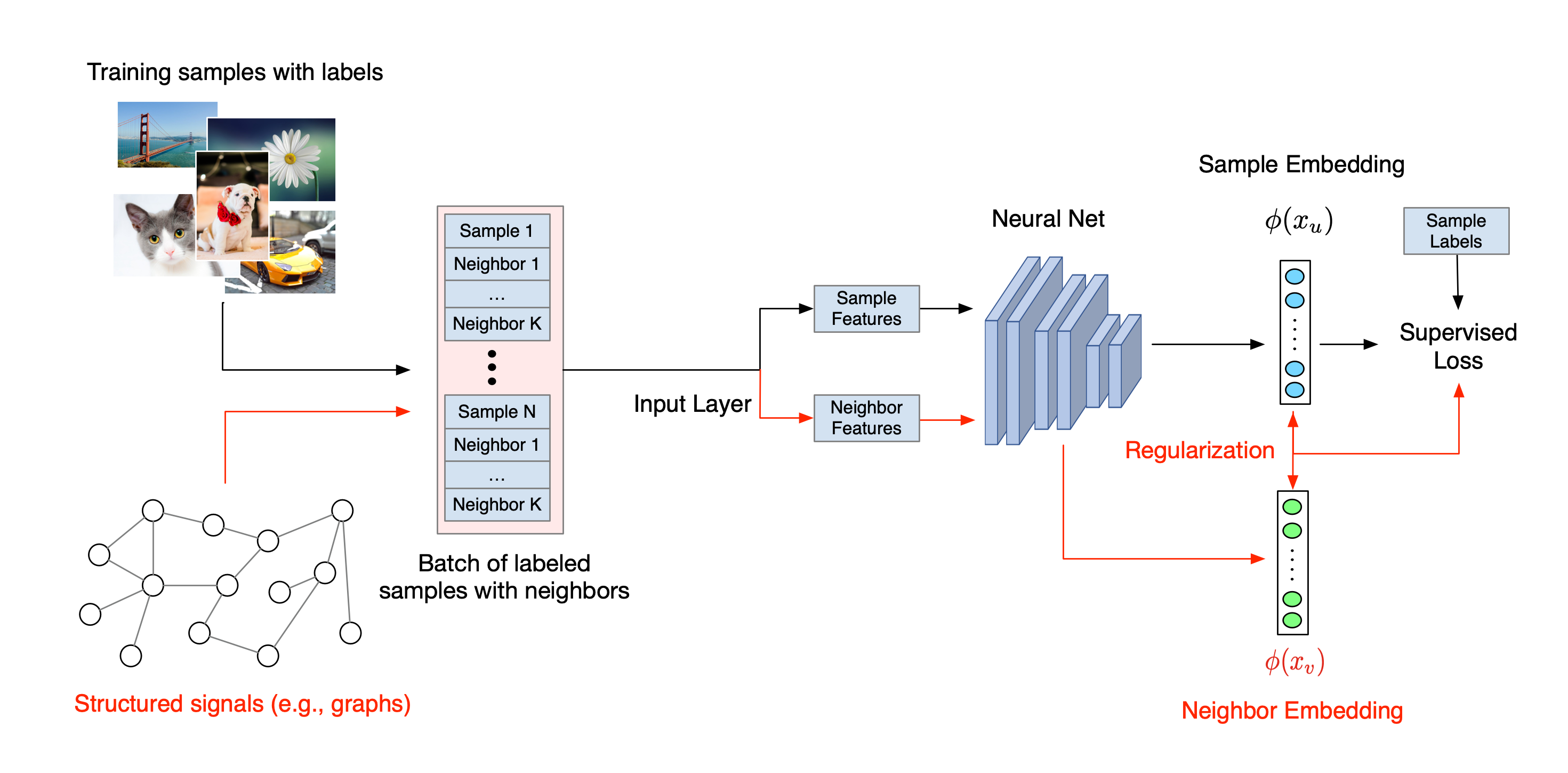
تم توضيح سير العمل الإجمالي للتعلم المنظم العصبي أدناه. تمثل الأسهم السوداء سير عمل التدريب التقليدي وتمثل الأسهم الحمراء سير العمل الجديد كما قدمته NSL للاستفادة من الإشارات المنظمة. أولاً، يتم تعزيز عينات التدريب لتشمل إشارات منظمة. عندما لا يتم توفير الإشارات المنظمة بشكل صريح، يمكن بناؤها أو تحفيزها (ينطبق هذا الأخير على التعلم التنافسي). بعد ذلك، يتم تغذية عينات التدريب المعززة (بما في ذلك العينات الأصلية والجيران المقابل لها) إلى الشبكة العصبية لحساب تضميناتها. يتم حساب المسافة بين تضمين العينة وتضمين جارتها واستخدامها كخسارة الجوار، والتي يتم التعامل معها كمصطلح تنظيم وإضافتها إلى الخسارة النهائية. بالنسبة للتنظيم الصريح القائم على الجوار، فإننا عادةً ما نحسب خسارة الجوار على أنها المسافة بين تضمين العينة وتضمين الجار. ومع ذلك، يمكن استخدام أي طبقة من الشبكة العصبية لحساب خسارة الجوار. من ناحية أخرى، بالنسبة للتسوية المستحثة القائمة على الجوار (الخصومة)، فإننا نحسب خسارة الجوار باعتبارها المسافة بين التنبؤ الناتج للجار الخصوم المستحث وتسمية الحقيقة الأرضية.
لماذا نستخدم خطاب الأمن القومي؟
يجلب NSL المزايا التالية:
- دقة أعلى : يمكن للإشارة (الإشارات) المنظمة بين العينات أن توفر معلومات لا تتوفر دائمًا في مدخلات الميزات؛ لذلك، فقد تبين أن نهج التدريب المشترك (مع كل من الإشارات والميزات المنظمة) يتفوق على العديد من الأساليب الحالية (التي تعتمد على التدريب مع الميزات فقط) في مجموعة واسعة من المهام، مثل تصنيف المستندات وتصنيف النوايا الدلالية ( Bui et al). .، WSDM'18 وكيبف وآخرون، ICLR'17 ).
- المتانة : أثبتت النماذج التي تم تدريبها باستخدام الأمثلة العدائية أنها قوية ضد الاضطرابات العدائية المصممة لتضليل تنبؤات النموذج أو تصنيفه ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). عندما يكون عدد عينات التدريب صغيرًا، فإن التدريب باستخدام الأمثلة المتعارضة يساعد أيضًا في تحسين دقة النموذج ( Tsipras et al., ICLR'19 ).
- مطلوب بيانات أقل مصنفة : يمكّن NSL الشبكات العصبية من تسخير كل من البيانات المصنفة وغير المسماة، مما يوسع نموذج التعلم ليشمل التعلم شبه الخاضع للإشراف . على وجه التحديد، يسمح NSL للشبكة بالتدريب باستخدام البيانات المصنفة كما هو الحال في الإعداد الخاضع للإشراف، وفي الوقت نفسه يدفع الشبكة لمعرفة تمثيلات مخفية مماثلة لـ "العينات المجاورة" التي قد تحتوي أو لا تحتوي على تسميات. أظهرت هذه التقنية وعدًا كبيرًا بتحسين دقة النموذج عندما تكون كمية البيانات الموسومة صغيرة نسبيًا ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
دروس خطوة بخطوة
للحصول على خبرة عملية في التعلم المنظم العصبي، لدينا برامج تعليمية تغطي سيناريوهات مختلفة حيث يمكن إعطاء الإشارات المنظمة أو إنشاؤها أو تحفيزها بشكل صريح. وهنا عدد قليل:
تنظيم الرسم البياني لتصنيف الوثائق باستخدام الرسوم البيانية الطبيعية . في هذا البرنامج التعليمي، نستكشف استخدام تنظيم الرسم البياني لتصنيف المستندات التي تشكل رسمًا بيانيًا طبيعيًا (عضويًا).
تنظيم الرسم البياني لتصنيف المشاعر باستخدام الرسوم البيانية المركبة . في هذا البرنامج التعليمي، نوضح استخدام تنظيم الرسم البياني لتصنيف مشاعر مراجعة الأفلام عن طريق إنشاء (توليف) إشارات منظمة.
التعلم التنافسي لتصنيف الصور . في هذا البرنامج التعليمي، نستكشف استخدام التعلم التنافسي (حيث يتم تحفيز الإشارات المنظمة) لتصنيف الصور التي تحتوي على أرقام رقمية.
يمكن العثور على المزيد من الأمثلة والبرامج التعليمية في دليل الأمثلة الخاص بمستودع GitHub الخاص بنا.
,يركز التعلم المنظم العصبي (NSL) على تدريب الشبكات العصبية العميقة من خلال الاستفادة من الإشارات المنظمة (عند توفرها) إلى جانب مدخلات الميزات. كما قدم بوي وآخرون. (WSDM'18) ، تُستخدم هذه الإشارات المنظمة لتنظيم تدريب الشبكة العصبية، مما يجبر النموذج على تعلم تنبؤات دقيقة (عن طريق تقليل الخسارة الخاضعة للإشراف)، مع الحفاظ في نفس الوقت على التشابه الهيكلي للمدخلات (عن طريق تقليل خسارة الجوار ، انظر الشكل أدناه). هذه التقنية عامة ويمكن تطبيقها على البنى العصبية التعسفية (مثل NNs ذات التغذية الأمامية، والشبكات العصبية التلافيفية، والشبكات العصبية المتكررة).
لاحظ أن معادلة خسارة الجوار المعممة مرنة ويمكن أن يكون لها أشكال أخرى إلى جانب الشكل الموضح أعلاه. على سبيل المثال، يمكننا أيضًا الاختيار\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ليكون الجار خسارة، وهو يحسب المسافة بين الحقيقة والأرض \(y_i\)والتنبؤ من الجار \(g_\theta(x_j)\). ويشيع استخدام هذا في التعلم التنافسي (Goodfellow et al., ICLR'15) . لذلك، يعمم NSL على تعلم الرسم البياني العصبي إذا تم تمثيل الجيران بشكل صريح من خلال رسم بياني، وعلى التعلم العدائي إذا تم تحفيز الجيران ضمنيًا عن طريق اضطراب الخصومة.
تم توضيح سير العمل الإجمالي للتعلم المنظم العصبي أدناه. تمثل الأسهم السوداء سير عمل التدريب التقليدي وتمثل الأسهم الحمراء سير العمل الجديد كما قدمته NSL للاستفادة من الإشارات المنظمة. أولاً، يتم تعزيز عينات التدريب لتشمل إشارات منظمة. عندما لا يتم توفير الإشارات المنظمة بشكل صريح، يمكن بناؤها أو تحفيزها (ينطبق هذا الأخير على التعلم التنافسي). بعد ذلك، يتم تغذية عينات التدريب المعززة (بما في ذلك العينات الأصلية والجيران المقابل لها) إلى الشبكة العصبية لحساب تضميناتها. يتم حساب المسافة بين تضمين العينة وتضمين جارتها واستخدامها كخسارة الجوار، والتي يتم التعامل معها كمصطلح تنظيم وإضافتها إلى الخسارة النهائية. بالنسبة للتنظيم الصريح القائم على الجوار، فإننا عادةً ما نحسب خسارة الجوار على أنها المسافة بين تضمين العينة وتضمين الجار. ومع ذلك، يمكن استخدام أي طبقة من الشبكة العصبية لحساب خسارة الجوار. من ناحية أخرى، بالنسبة للتسوية المستحثة القائمة على الجوار (الخصومة)، فإننا نحسب خسارة الجوار باعتبارها المسافة بين التنبؤ الناتج للجار الخصوم المستحث وتسمية الحقيقة الأرضية.
لماذا نستخدم خطاب الأمن القومي؟
يجلب NSL المزايا التالية:
- دقة أعلى : يمكن للإشارة (الإشارات) المنظمة بين العينات أن توفر معلومات لا تتوفر دائمًا في مدخلات الميزات؛ لذلك، فقد تبين أن نهج التدريب المشترك (مع كل من الإشارات والميزات المنظمة) يتفوق على العديد من الأساليب الحالية (التي تعتمد على التدريب مع الميزات فقط) في مجموعة واسعة من المهام، مثل تصنيف المستندات وتصنيف النوايا الدلالية ( Bui et al). .، WSDM'18 وكيبف وآخرون، ICLR'17 ).
- المتانة : أثبتت النماذج التي تم تدريبها باستخدام الأمثلة العدائية أنها قوية ضد الاضطرابات العدائية المصممة لتضليل تنبؤات النموذج أو تصنيفه ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). عندما يكون عدد عينات التدريب صغيرًا، فإن التدريب باستخدام الأمثلة المتعارضة يساعد أيضًا في تحسين دقة النموذج ( Tsipras et al., ICLR'19 ).
- مطلوب بيانات أقل مصنفة : يمكّن NSL الشبكات العصبية من تسخير كل من البيانات المصنفة وغير المسماة، مما يوسع نموذج التعلم ليشمل التعلم شبه الخاضع للإشراف . على وجه التحديد، يسمح NSL للشبكة بالتدريب باستخدام البيانات المصنفة كما هو الحال في الإعداد الخاضع للإشراف، وفي الوقت نفسه يدفع الشبكة لمعرفة تمثيلات مخفية مماثلة لـ "العينات المجاورة" التي قد تحتوي أو لا تحتوي على تسميات. أظهرت هذه التقنية وعدًا كبيرًا بتحسين دقة النموذج عندما تكون كمية البيانات الموسومة صغيرة نسبيًا ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
دروس خطوة بخطوة
للحصول على خبرة عملية في التعلم المنظم العصبي، لدينا برامج تعليمية تغطي سيناريوهات مختلفة حيث يمكن إعطاء الإشارات المنظمة أو إنشاؤها أو تحفيزها بشكل صريح. وهنا عدد قليل:
تنظيم الرسم البياني لتصنيف الوثائق باستخدام الرسوم البيانية الطبيعية . في هذا البرنامج التعليمي، نستكشف استخدام تنظيم الرسم البياني لتصنيف المستندات التي تشكل رسمًا بيانيًا طبيعيًا (عضويًا).
تنظيم الرسم البياني لتصنيف المشاعر باستخدام الرسوم البيانية المركبة . في هذا البرنامج التعليمي، نوضح استخدام تنظيم الرسم البياني لتصنيف مشاعر مراجعة الأفلام من خلال إنشاء (توليف) إشارات منظمة.
التعلم التنافسي لتصنيف الصور . في هذا البرنامج التعليمي، نستكشف استخدام التعلم التنافسي (حيث يتم تحفيز الإشارات المنظمة) لتصنيف الصور التي تحتوي على أرقام رقمية.
يمكن العثور على المزيد من الأمثلة والبرامج التعليمية في دليل الأمثلة الخاص بمستودع GitHub الخاص بنا.
,يركز التعلم المنظم العصبي (NSL) على تدريب الشبكات العصبية العميقة من خلال الاستفادة من الإشارات المنظمة (عند توفرها) إلى جانب مدخلات الميزات. كما قدم بوي وآخرون. (WSDM'18) ، تُستخدم هذه الإشارات المنظمة لتنظيم تدريب الشبكة العصبية، مما يجبر النموذج على تعلم تنبؤات دقيقة (عن طريق تقليل الخسارة الخاضعة للإشراف)، مع الحفاظ في نفس الوقت على التشابه الهيكلي للمدخلات (عن طريق تقليل خسارة الجوار ، انظر الشكل أدناه). هذه التقنية عامة ويمكن تطبيقها على البنى العصبية التعسفية (مثل الشبكات العصبية ذات التغذية الأمامية والشبكات العصبية التلافيفية والشبكات العصبية المتكررة).
لاحظ أن معادلة خسارة الجوار المعممة مرنة ويمكن أن يكون لها أشكال أخرى إلى جانب الشكل الموضح أعلاه. على سبيل المثال، يمكننا أيضًا الاختيار\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ليكون الجار خسارة، وهو يحسب المسافة بين الحقيقة والأرض \(y_i\)والتنبؤ من الجار \(g_\theta(x_j)\). ويشيع استخدام هذا في التعلم التنافسي (Goodfellow et al., ICLR'15) . لذلك، يعمم NSL على تعلم الرسم البياني العصبي إذا تم تمثيل الجيران بشكل صريح من خلال رسم بياني، وعلى التعلم العدائي إذا تم تحفيز الجيران ضمنيًا عن طريق اضطراب الخصومة.
تم توضيح سير العمل الإجمالي للتعلم المنظم العصبي أدناه. تمثل الأسهم السوداء سير عمل التدريب التقليدي وتمثل الأسهم الحمراء سير العمل الجديد كما قدمته NSL للاستفادة من الإشارات المنظمة. أولاً، يتم تعزيز عينات التدريب لتشمل إشارات منظمة. عندما لا يتم توفير الإشارات المنظمة بشكل صريح، يمكن بناؤها أو تحفيزها (ينطبق هذا الأخير على التعلم التنافسي). بعد ذلك، يتم تغذية عينات التدريب المعززة (بما في ذلك العينات الأصلية والجيران المقابل لها) إلى الشبكة العصبية لحساب تضميناتها. يتم حساب المسافة بين تضمين العينة وتضمين جارتها واستخدامها كخسارة الجوار، والتي يتم التعامل معها كمصطلح تنظيم وإضافتها إلى الخسارة النهائية. بالنسبة للتنظيم الصريح القائم على الجوار، فإننا عادةً ما نحسب خسارة الجوار على أنها المسافة بين تضمين العينة وتضمين الجار. ومع ذلك، يمكن استخدام أي طبقة من الشبكة العصبية لحساب خسارة الجوار. من ناحية أخرى، بالنسبة للتسوية المستحثة القائمة على الجوار (الخصومة)، فإننا نحسب خسارة الجوار باعتبارها المسافة بين التنبؤ الناتج للجار الخصوم المستحث وتسمية الحقيقة الأرضية.
لماذا نستخدم خطاب الأمن القومي؟
يجلب NSL المزايا التالية:
- دقة أعلى : يمكن للإشارة (الإشارات) المنظمة بين العينات أن توفر معلومات لا تتوفر دائمًا في مدخلات الميزات؛ لذلك، فقد تبين أن نهج التدريب المشترك (مع كل من الإشارات والميزات المنظمة) يتفوق على العديد من الأساليب الحالية (التي تعتمد على التدريب مع الميزات فقط) في مجموعة واسعة من المهام، مثل تصنيف المستندات وتصنيف النوايا الدلالية ( Bui et al). .، WSDM'18 وكيبف وآخرون، ICLR'17 ).
- المتانة : أثبتت النماذج التي تم تدريبها باستخدام الأمثلة العدائية أنها قوية ضد الاضطرابات العدائية المصممة لتضليل تنبؤات النموذج أو تصنيفه ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). عندما يكون عدد عينات التدريب صغيرًا، فإن التدريب باستخدام الأمثلة المتعارضة يساعد أيضًا في تحسين دقة النموذج ( Tsipras et al., ICLR'19 ).
- مطلوب بيانات أقل مصنفة : يمكّن NSL الشبكات العصبية من تسخير كل من البيانات المصنفة وغير المسماة، مما يوسع نموذج التعلم ليشمل التعلم شبه الخاضع للإشراف . على وجه التحديد، يسمح NSL للشبكة بالتدريب باستخدام البيانات المصنفة كما هو الحال في الإعداد الخاضع للإشراف، وفي الوقت نفسه يدفع الشبكة لمعرفة تمثيلات مخفية مماثلة لـ "العينات المجاورة" التي قد تحتوي أو لا تحتوي على تسميات. أظهرت هذه التقنية وعدًا كبيرًا بتحسين دقة النموذج عندما تكون كمية البيانات الموسومة صغيرة نسبيًا ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
دروس خطوة بخطوة
للحصول على خبرة عملية في التعلم المنظم العصبي، لدينا برامج تعليمية تغطي سيناريوهات مختلفة حيث يمكن إعطاء الإشارات المنظمة أو إنشاؤها أو تحفيزها بشكل صريح. وهنا عدد قليل:
تنظيم الرسم البياني لتصنيف الوثائق باستخدام الرسوم البيانية الطبيعية . في هذا البرنامج التعليمي، نستكشف استخدام تنظيم الرسم البياني لتصنيف المستندات التي تشكل رسمًا بيانيًا طبيعيًا (عضويًا).
تنظيم الرسم البياني لتصنيف المشاعر باستخدام الرسوم البيانية المركبة . في هذا البرنامج التعليمي، نوضح استخدام تنظيم الرسم البياني لتصنيف مشاعر مراجعة الأفلام عن طريق إنشاء (توليف) إشارات منظمة.
التعلم التنافسي لتصنيف الصور . في هذا البرنامج التعليمي، نستكشف استخدام التعلم التنافسي (حيث يتم تحفيز الإشارات المنظمة) لتصنيف الصور التي تحتوي على أرقام رقمية.
يمكن العثور على المزيد من الأمثلة والبرامج التعليمية في دليل الأمثلة الخاص بمستودع GitHub الخاص بنا.