
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | | |
ملخص
يستعرض هذا يصنف دفتر الفيلم كما إيجابية أو سلبية باستخدام نص المراجعة. وهذا مثال للتصنيف ثنائي، وهو نوع مهم وقابلة للتطبيق على نطاق واسع من مشكلة تعلم الآلة.
سوف نوضح استخدام تنظيم الرسم البياني في هذا الكمبيوتر الدفتري من خلال إنشاء رسم بياني من المدخلات المحددة. الوصفة العامة لبناء نموذج منظم للرسم البياني باستخدام إطار عمل التعلم المهيكل العصبي (NSL) عندما لا يحتوي الإدخال على رسم بياني واضح كما يلي:
- إنشاء حفلات الزفاف لكل عينة نصية في الإدخال. ويمكن القيام بذلك باستخدام نماذج المدربين قبل مثل word2vec ، دوار ، بيرت الخ
- أنشئ رسمًا بيانيًا بناءً على عمليات التضمين هذه باستخدام مقياس تشابه مثل المسافة "L2" ومسافة "جيب التمام" وما إلى ذلك. تتوافق العقد في الرسم البياني مع العينات والحواف في الرسم البياني تتوافق مع التشابه بين أزواج من العينات.
- قم بإنشاء بيانات التدريب من الرسم البياني المركب أعلاه وعينة الميزات. ستحتوي بيانات التدريب الناتجة على ميزات الجوار بالإضافة إلى ميزات العقدة الأصلية.
- قم بإنشاء شبكة عصبية كنموذج أساسي باستخدام واجهة برمجة تطبيقات Keras المتسلسلة أو الوظيفية أو الفرعية.
- قم بلف النموذج الأساسي بفئة غلاف GraphRegularization ، التي يتم توفيرها بواسطة إطار عمل NSL ، لإنشاء نموذج رسم بياني Keras جديد. سيتضمن هذا النموذج الجديد خسارة تنظيم الرسم البياني كمصطلح التنظيم في هدف التدريب الخاص به.
- تدريب وتقييم نموذج Keras للرسم البياني.
متطلبات
- قم بتثبيت حزمة التعلم المهيكل العصبي.
- تثبيت tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
التبعيات والواردات
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
مجموعة بيانات IMDB
و بيانات IMDB يحتوي على النص من 50000 يستعرض الفيلم من قاعدة بيانات الأفلام على الإنترنت . يتم تقسيم هذه إلى 25000 مراجعة للتدريب و 25000 مراجعة للاختبار. ومتوازنة تدريب واختبار مجموعات، وهذا يعني أنها تحتوي على عدد متساو من الاستعراضات إيجابية وسلبية.
في هذا البرنامج التعليمي ، سنستخدم إصدارًا مُعالجًا مسبقًا من مجموعة بيانات IMDB.
قم بتنزيل مجموعة بيانات IMDB المجهزة مسبقًا
تأتي مجموعة بيانات IMDB معبأة مع TensorFlow. لقد تمت معالجتها مسبقًا بحيث تم تحويل المراجعات (تسلسل الكلمات) إلى متواليات من الأعداد الصحيحة ، حيث يمثل كل عدد صحيح كلمة معينة في القاموس.
الكود التالي يقوم بتنزيل مجموعة بيانات IMDB (أو يستخدم نسخة مخبأة إذا كان قد تم تنزيلها بالفعل):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
حجة num_words=10000 يحافظ على أعلى 10،000 أكثر الكلمات تكرارا في بيانات التدريب. يتم تجاهل الكلمات النادرة للحفاظ على حجم المفردات في متناول اليد.
استكشف البيانات
دعنا نتوقف لحظة لفهم تنسيق البيانات. تأتي مجموعة البيانات مُجهزة مسبقًا: كل مثال عبارة عن مجموعة من الأعداد الصحيحة التي تمثل كلمات مراجعة الفيلم. كل تصنيف عبارة عن قيمة عدد صحيح إما 0 أو 1 ، حيث يمثل 0 مراجعة سلبية و 1 مراجعة إيجابية.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
تم تحويل نص المراجعات إلى أعداد صحيحة ، حيث يمثل كل عدد صحيح كلمة معينة في القاموس. إليك ما تبدو عليه المراجعة الأولى:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
قد تختلف أطوال مراجعات الأفلام. يوضح الكود أدناه عدد الكلمات في المراجعة الأولى والثانية. نظرًا لأن مدخلات الشبكة العصبية يجب أن تكون بنفس الطول ، فسنحتاج إلى حل هذا لاحقًا.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
تحويل الأعداد الصحيحة إلى كلمات
قد يكون من المفيد معرفة كيفية تحويل الأعداد الصحيحة إلى النص المقابل. سننشئ هنا دالة مساعدة للاستعلام عن كائن قاموس يحتوي على عدد صحيح لتعيين السلسلة:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
الآن يمكننا استخدام decode_review وظيفة لعرض النص الاستعراض الأول:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
إنشاء الرسم البياني
يتضمن إنشاء الرسم البياني إنشاء زخارف لعينات نصية ثم استخدام وظيفة التشابه لمقارنة الزخارف.
قبل المضي قدمًا ، نقوم أولاً بإنشاء دليل لتخزين القطع الأثرية التي تم إنشاؤها بواسطة هذا البرنامج التعليمي.
mkdir -p /tmp/imdb
إنشاء نماذج لحفلات الزفاف
سوف نستخدم pretrained التضمينات دوارة لخلق التضمينات في tf.train.Example تنسيق كل عينة في المدخلات. وسوف تخزين التضمينات مما أدى إلى TFRecord شكل جنبا إلى جنب مع ميزة إضافية يمثل معرف من كل عينة. هذا مهم وسيسمح لنا بمطابقة عينات من التضمينات مع العقد المقابلة في الرسم البياني لاحقًا.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
أنشئ رسمًا بيانيًا
الآن بعد أن أصبح لدينا عينات من عمليات التضمين ، سنستخدمها لبناء رسم بياني للتشابه ، أي أن العقد في هذا الرسم البياني سوف تتوافق مع العينات وستتوافق الحواف في هذا الرسم البياني مع التشابه بين أزواج العقد.
يوفر التعلم المهيكل العصبي مكتبة بناء الرسم البياني لإنشاء رسم بياني بناءً على نماذج من التضمينات. ويستخدم التشابه جيب التمام كمقياس لمقارنة التشابه التضمينات وحواف بناء بينهما. كما يسمح لنا بتحديد حد التشابه ، والذي يمكن استخدامه لتجاهل الحواف غير المتشابهة من الرسم البياني النهائي. في هذا المثال ، باستخدام 0.99 كحد أدنى للتشابه و 12345 كبذرة عشوائية ، ينتهي بنا الأمر برسم بياني به 429.415 حافة ثنائية الاتجاه. هنا نستخدمه دعم باني الرسم البياني لل الحساسة للمحلة التجزئة (LSH) لتسريع بناء الرسم البياني. للحصول على تفاصيل حول كيفية استخدام الدعم LSH باني الرسم البياني، راجع build_graph_from_config ثائق API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
يتم تمثيل كل حافة ثنائية الاتجاه بحافتين موجهتين في ملف TSV الناتج ، بحيث يحتوي هذا الملف على 429.415 * 2 = 858.830 سطرًا إجماليًا:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
ميزات العينة
ونحن إنشاء ميزات عينة لمشكلتنا باستخدام tf.train.Example شكل وتستمر لهم في TFRecord الشكل. ستتضمن كل عينة الميزات الثلاث التالية:
- معرف: معرف عقدة من العينة.
- كلمات: لائحة int64 تحتوي على كلمة معرفات.
- التسمية: A المفرد int64 تحديد الفئة المستهدفة من هذا الاستعراض.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
زيادة بيانات التدريب باستخدام الرسم البياني للجيران
نظرًا لأن لدينا ميزات العينة والرسم البياني المركب ، يمكننا إنشاء بيانات التدريب المعززة للتعلم المهيكل العصبي. يوفر إطار عمل NSL مكتبة لدمج الرسم البياني وميزات العينة لإنتاج بيانات التدريب النهائية لتنظيم الرسم البياني. ستشمل بيانات التدريب الناتجة ميزات العينة الأصلية بالإضافة إلى ميزات جيرانهم المناظرين.
في هذا البرنامج التعليمي ، نأخذ في الاعتبار الحواف غير الموجهة ونستخدم 3 جيران كحد أقصى لكل عينة لزيادة بيانات التدريب مع جيران الرسم البياني.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
نموذج القاعدة
نحن الآن جاهزون لبناء نموذج أساسي بدون تنظيم الرسم البياني. من أجل بناء هذا النموذج ، يمكننا إما استخدام الزخارف التي تم استخدامها في بناء الرسم البياني ، أو يمكننا أن نتعلم زخارف جديدة بالاشتراك مع مهمة التصنيف. لغرض هذا الكمبيوتر الدفتري ، سنفعل هذا الأخير.
المتغيرات العالمية
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Hyperparameters
سوف نستخدم مثيل HParams إلى inclue مختلف hyperparameters والثوابت المستخدمة للتدريب والتقييم. نصف بإيجاز كل منهم أدناه:
num_classes: هناك 2 الطبقات - الإيجابية والسلبية.
max_seq_length: هذا هو الحد الأقصى لعدد الكلمات تعتبر من كل استعراض الفيلم في هذا المثال.
vocab_size: هذا هو حجم المفردات النظر في هذا المثال.
distance_type: هذه هي المسافة متري تستخدم لتنظيم العينة مع جيرانها.
graph_regularization_multiplier: يتحكم هذا الوزن النسبي لمصطلح الرسم البياني تسوية في فقدان وظيفة الكلية.
num_neighbors: عدد من الدول المجاورة تستخدم لتنظيم الرسم البياني. هذه القيمة يجب أن تكون أقل من أو يساوي إلى
max_nbrsالحجة المستخدمة أعلاه عند استدعاءnsl.tools.pack_nbrs.num_fc_units: عدد الوحدات في طبقة مرتبطة ارتباطا كاملا من الشبكة العصبية.
train_epochs: عدد العهود التدريب.
حجم دفعة تستخدم للتدريب والتقييم: batch_size.
eval_steps: عدد دفعات لعملية قبل اعتبار تقييم كامل. إذا تم تعيين إلى
None، يتم تقييم جميع الحالات في مجموعة الاختبار.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
تحضير البيانات
المراجعات - مصفوفات الأعداد الصحيحة - يجب تحويلها إلى موترات قبل إدخالها في الشبكة العصبية. يمكن إجراء هذا التحويل بطريقتين:
تحويل صفائف إلى ناقلات
0الصورة و1مما يدل حدوث كلمة، مشابهة لترميز واحد الساخنة. على سبيل المثال، وتسلسل[3, 5]سيصبح10000ناقلات الأبعاد هذا هو كل الأصفار باستثناء مؤشرات3و5، والتي هي منها. ثم، وجعل هذه الطبقة الأولى في شبكتنا واحدDenseالطبقات التي يمكن التعامل مع العائمة بيانات المتجه نقطة. هذا النهج هو مكثفة للذاكرة، على الرغم من تتطلبnum_words * num_reviewsحجم المصفوفة.بدلا من ذلك، يمكننا وحة صفائف بحيث يصبح لديهم كل نفس الطول، ثم خلق موتر عدد صحيح من الشكل
max_length * num_reviews. يمكننا استخدام طبقة التضمين القادرة على التعامل مع هذا الشكل باعتباره الطبقة الأولى في شبكتنا.
في هذا البرنامج التعليمي ، سوف نستخدم الطريقة الثانية.
منذ يستعرض الفيلم يجب أن يكون طول نفس، وسوف نستخدم pad_sequence وظيفة محددة أدناه لتوحيد أطوال.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
بناء النموذج
يتم إنشاء الشبكة العصبية عن طريق تكديس الطبقات - وهذا يتطلب قرارين معماريين رئيسيين:
- كم عدد الطبقات لاستخدامها في النموذج؟
- عدد الوحدات خفية لاستخدامها في كل طبقة؟
في هذا المثال ، تتكون بيانات الإدخال من مجموعة من فهارس الكلمات. التسميات المطلوب توقعها هي إما 0 أو 1.
سنستخدم LSTM ثنائي الاتجاه كنموذج أساسي لدينا في هذا البرنامج التعليمي.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
يتم تكديس الطبقات بشكل متسلسل بشكل فعال لبناء المصنف:
- الطبقة الأولى هي
Inputالطبقة التي تأخذ المفردات المشفرة صحيح. - الطبقة التالية هي
Embeddingطبقة، والتي تأخذ المفردات المشفرة عدد صحيح ويبدو حتى ناقلات تضمين لكل كلمة المؤشر. يتم تعلم هذه النواقل باعتبارها نموذج القطارات. تضيف المتجهات بعدًا إلى صفيف الإخراج. الأبعاد الناتجة:(batch, sequence, embedding). - بعد ذلك ، تقوم طبقة LSTM ثنائية الاتجاه بإرجاع متجه إخراج بطول ثابت لكل مثال.
- يتم إيصاله هذا متجه الانتاج ذات طول ثابت من خلال مرتبطة ارتباطا كاملا (
Denseطبقة) مع 64 وحدة المخفية. - الطبقة الأخيرة متصلة بكثافة مع عقدة خرج واحدة. باستخدام
sigmoidوظيفة التنشيط، هذه القيمة هي تطفو بين 0 و 1، وهو ما يمثل احتمال، أو مستوى الثقة.
الوحدات المخفية
النموذج أعلاه اثنين المتوسطة طبقات أو "مخفية"، بين المدخلات والمخرجات، وباستثناء Embedding طبقة. عدد النواتج (الوحدات أو العقد أو الخلايا العصبية) هو بُعد المساحة التمثيلية للطبقة. بمعنى آخر ، مقدار الحرية المسموح به للشبكة عند تعلم تمثيل داخلي.
إذا كان النموذج يحتوي على المزيد من الوحدات المخفية (مساحة تمثيل ذات أبعاد أعلى) ، و / أو طبقات أكثر ، فيمكن للشبكة أن تتعلم تمثيلات أكثر تعقيدًا. ومع ذلك ، فإنه يجعل الشبكة أكثر تكلفة من الناحية الحسابية وقد يؤدي إلى تعلم أنماط غير مرغوب فيها - أنماط تعمل على تحسين الأداء على بيانات التدريب ولكن ليس على بيانات الاختبار. وهذا ما يسمى overfitting.
وظيفة الخسارة والمحسن
يحتاج النموذج إلى وظيفة خسارة ومحسن للتدريب. منذ هذه مشكلة تصنيف الثنائية ونموذج مخرجات احتمال (طبقة وحدة واحدة مع تفعيل السيني)، ونحن سوف تستخدم binary_crossentropy وظيفة الخسارة.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
إنشاء مجموعة التحقق من الصحة
عند التدريب ، نريد التحقق من دقة النموذج في البيانات التي لم يرها من قبل. إنشاء مجموعة التحقق من خلال وضع ما عدا جزء صغير من بيانات التدريب الأصلية. (لماذا لا تستخدم مجموعة الاختبار الآن؟ هدفنا هو تطوير وضبط نموذجنا باستخدام بيانات التدريب فقط ، ثم استخدام بيانات الاختبار مرة واحدة فقط لتقييم دقتنا).
في هذا البرنامج التعليمي ، نأخذ ما يقرب من 10٪ من عينات التدريب الأولية (10٪ من 25000) كبيانات معنونة للتدريب والباقي كبيانات تحقق من الصحة. نظرًا لأن تقسيم التدريب / الاختبار الأولي كان 50/50 (25000 عينة لكل منهما) ، فإن تقسيم التدريب / التحقق من الصحة / الاختبار الفعال لدينا الآن هو 5/45/50.
لاحظ أنه تم بالفعل تجميع "train_dataset" وتعديله عشوائيًا.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
تدريب النموذج
تدريب النموذج على دفعات صغيرة. أثناء التدريب ، راقب فقد النموذج ودقته في مجموعة التحقق من الصحة:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
قم بتقييم النموذج
الآن ، دعنا نرى كيف يعمل النموذج. سيتم إرجاع قيمتين. الخسارة (رقم يمثل خطأنا ، والقيم الأقل هي الأفضل) والدقة.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
قم بإنشاء رسم بياني للدقة / الخسارة بمرور الوقت
model.fit() ترجع History الكائن الذي يحتوي على القاموس مع كل ما حدث أثناء التدريب:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
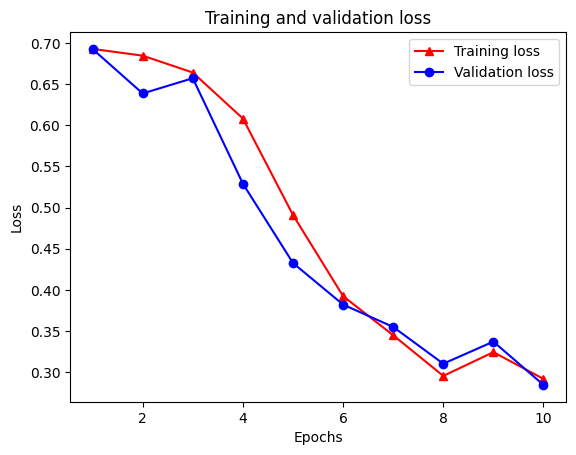
هناك أربعة إدخالات: واحد لكل مقياس يتم مراقبته أثناء التدريب والتحقق من الصحة. يمكننا استخدام هذه لتخطيط فقدان التدريب والتحقق من الصحة للمقارنة ، بالإضافة إلى دقة التدريب والتحقق من الصحة:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
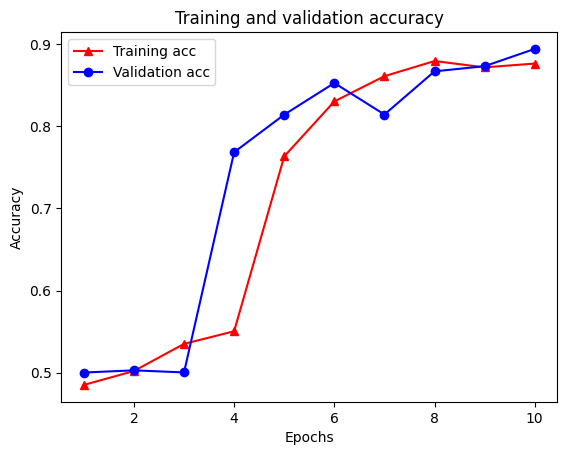
لاحظ فقدان التدريب تتناقص مع كل عصر والتدريب وزيادة دقة مع كل عصر. هذا متوقع عند استخدام تحسين النسب المتدرج - يجب أن يقلل الكمية المرغوبة في كل تكرار.
تسوية الرسم البياني
نحن الآن جاهزون لتجربة تنظيم الرسم البياني باستخدام النموذج الأساسي الذي أنشأناه أعلاه. سوف نستخدم GraphRegularization فئة المجمع التي تقدمها إطار التعلم العصبية الهيكلية للالتفاف على قاعدة (ثنائية LSTM) نموذج لتشمل الرسم البياني تسوية. تتشابه بقية خطوات تدريب وتقييم النموذج المنظم للرسم البياني مع النموذج الأساسي.
إنشاء نموذج رسم بياني منظم
لتقييم الفائدة المتزايدة لتسوية الرسم البياني ، سننشئ مثيل نموذج أساسي جديد. وذلك لأن model تم بالفعل تدريب لبضعة التكرار، وسوف إعادة استخدام هذا النموذج مدربة على إنشاء نموذج تنظيما الرسم البياني لا تكون المقارنة عادلة لل model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
تدريب النموذج
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
قم بتقييم النموذج
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
قم بإنشاء رسم بياني للدقة / الخسارة بمرور الوقت
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
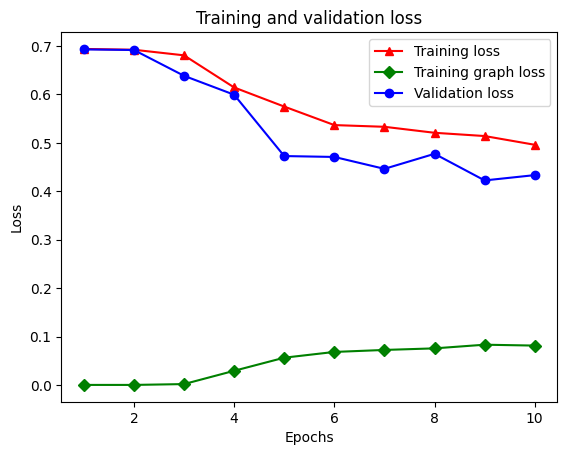
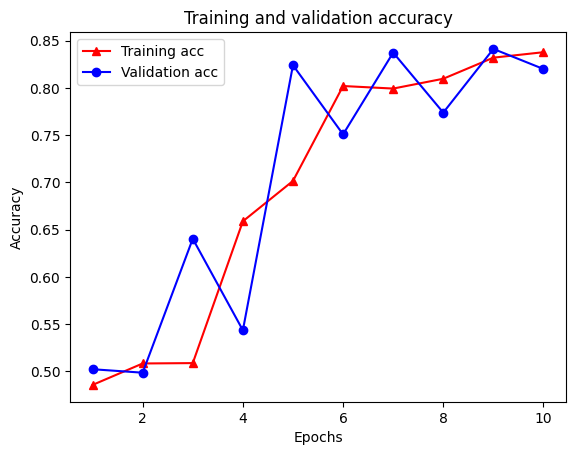
هناك خمسة إدخالات إجمالاً في القاموس: فقدان التدريب ، دقة التدريب ، فقدان الرسم البياني للتدريب ، فقدان التحقق من الصحة ، ودقة التحقق من الصحة. يمكننا رسمها جميعًا معًا للمقارنة. لاحظ أن فقدان الرسم البياني يتم حسابه فقط أثناء التدريب.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
قوة التعلم شبه الخاضع للإشراف
يمكن أن يكون التعلم شبه الخاضع للإشراف وبشكل أكثر تحديدًا ، تنظيم الرسم البياني في سياق هذا البرنامج التعليمي ، قويًا حقًا عندما تكون كمية بيانات التدريب صغيرة. يتم تعويض نقص بيانات التدريب من خلال الاستفادة من التشابه بين عينات التدريب ، وهو أمر غير ممكن في التعلم التقليدي الخاضع للإشراف.
نحدد نسبة إشراف كنسبة من تدريب عينات لعدد من العينات التي تشمل التدريب، والمصادقة، وعينات الاختبار. في هذا الكمبيوتر الدفتري ، استخدمنا نسبة إشراف قدرها 0.05 (أي 5٪ من البيانات المصنفة) لتدريب كل من النموذج الأساسي ونموذج الرسم البياني المنتظم. نوضح تأثير نسبة الإشراف على دقة النموذج في الخلية أدناه.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
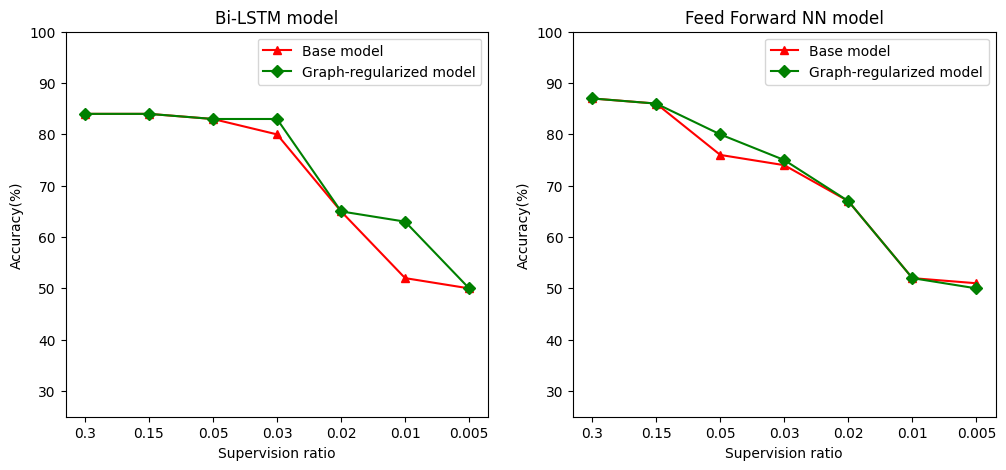
يمكن ملاحظة أنه مع انخفاض نسبة التشعب ، تقل دقة النموذج أيضًا. هذا صحيح لكل من النموذج الأساسي والنموذج المنظم للرسم البياني ، بغض النظر عن بنية النموذج المستخدمة. ومع ذلك ، لاحظ أن نموذج الرسم البياني المنظم يعمل بشكل أفضل من النموذج الأساسي لكل من البنى. على وجه الخصوص، لنموذج ثنائي LSTM، عندما تكون نسبة الإشراف هو 0.01، ودقة نموذج تنظيما الرسم البياني هو ~ 20٪ أعلى من نموذج القاعدة. هذا في المقام الأول بسبب التعلم شبه الخاضع للإشراف لنموذج الرسم البياني المنظم ، حيث يتم استخدام التشابه الهيكلي بين عينات التدريب بالإضافة إلى عينات التدريب نفسها.
استنتاج
لقد أظهرنا استخدام تنظيم الرسم البياني باستخدام إطار عمل التعلم المهيكل العصبي (NSL) حتى عندما لا يحتوي الإدخال على رسم بياني واضح. لقد نظرنا في مهمة تصنيف المشاعر لمراجعات أفلام IMDB التي قمنا بتجميع رسم بياني للتشابه بناءً على مراجعة حفلات الزفاف. نحن نشجع المستخدمين على إجراء المزيد من التجارب من خلال تغيير المعلمات الفائقة ، ومقدار الإشراف ، وباستخدام بنيات نموذجية مختلفة.