
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
In questo esempio esplorerai il risultato di McClean, 2019 che afferma che non qualsiasi struttura di rete neurale quantistica funzionerà bene quando si tratta di apprendimento. In particolare vedrai che una certa grande famiglia di circuiti quantistici casuali non servono come buone reti neurali quantistiche, perché hanno gradienti che svaniscono quasi ovunque. In questo esempio non verranno addestrati modelli per un problema di apprendimento specifico, ma ci si concentrerà invece sul problema più semplice della comprensione dei comportamenti dei gradienti.
Impostare
pip install tensorflow==2.7.0
Installa TensorFlow Quantum:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Ora importa TensorFlow e le dipendenze del modulo:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. Riepilogo
Circuiti quantistici casuali con molti blocchi simili a questo (\(R_{P}(\theta)\) è una rotazione casuale di Pauli):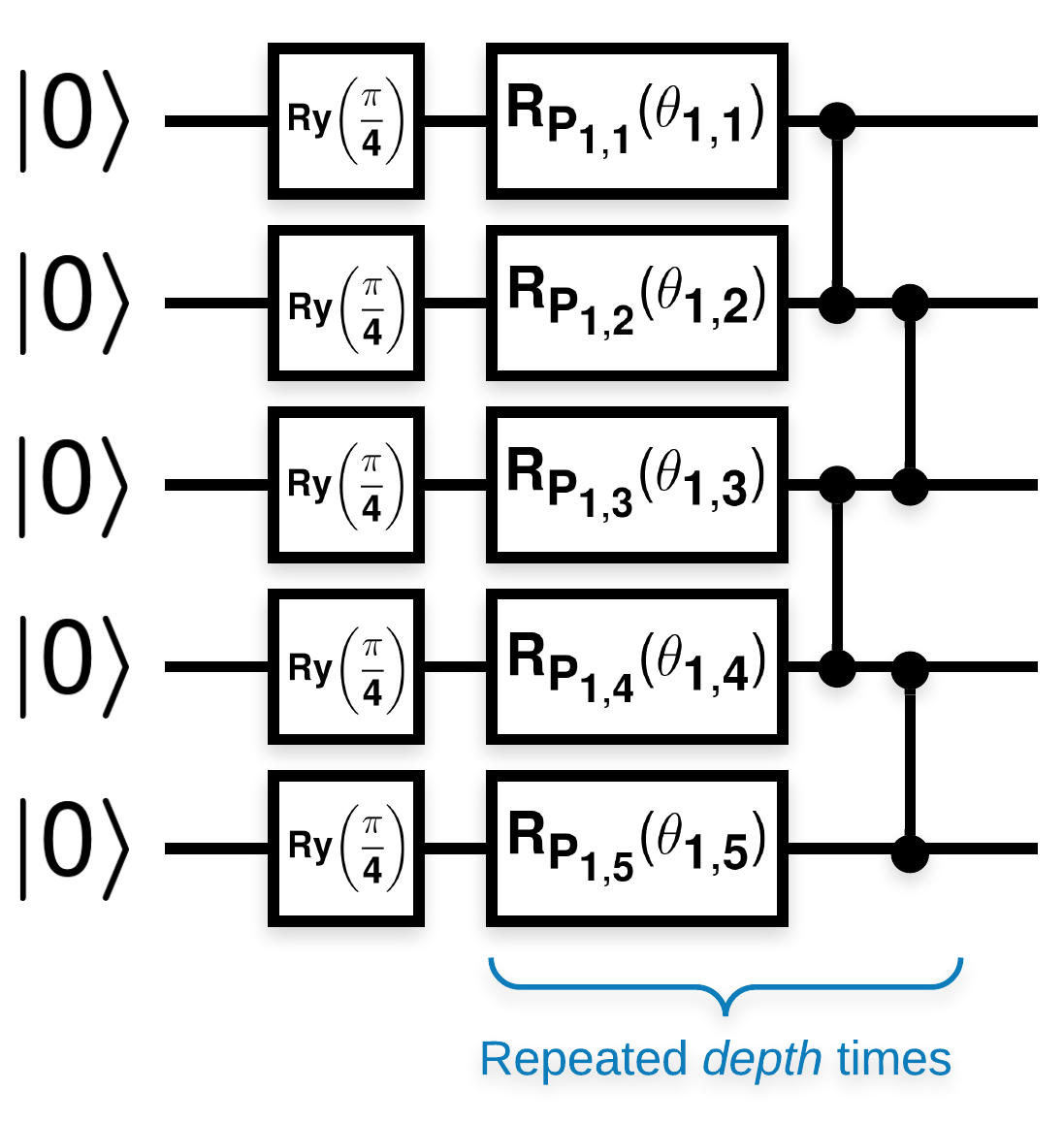
Laddove se \(f(x)\) è definito come il valore atteso wrt \(Z_{a}Z_{b}\) per qualsiasi qubit \(a\) e \(b\), allora c'è un problema che \(f'(x)\) ha una media molto vicina a 0 e non varia molto. Vedrai questo qui sotto:
2. Generazione di circuiti casuali
La costruzione della carta è semplice da seguire. Quanto segue implementa una semplice funzione che genera un circuito quantistico casuale, a volte indicato come rete neurale quantistica (QNN), con la profondità data su un insieme di qubit:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
Gli autori studiano il gradiente di un singolo parametro \(\theta_{1,1}\). Procediamo inserendo un sympy.Symbol nel circuito in cui sarebbe \(\theta_{1,1}\) . Poiché gli autori non analizzano le statistiche per altri simboli nel circuito, sostituiamoli con valori casuali ora anziché in seguito.
3. Esecuzione dei circuiti
Genera alcuni di questi circuiti insieme a un osservabile per verificare l'affermazione che i gradienti non variano molto. Innanzitutto, genera un batch di circuiti casuali. Scegli un osservabile ZZ casuale e calcola in batch i gradienti e la varianza utilizzando TensorFlow Quantum.
3.1 Calcolo della varianza batch
Scriviamo una funzione di supporto che calcola la varianza del gradiente di un dato osservabile su un batch di circuiti:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 Configurazione ed esecuzione
Scegli il numero di circuiti casuali da generare insieme alla loro profondità e alla quantità di qubit su cui dovrebbero agire. Quindi traccia i risultati.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
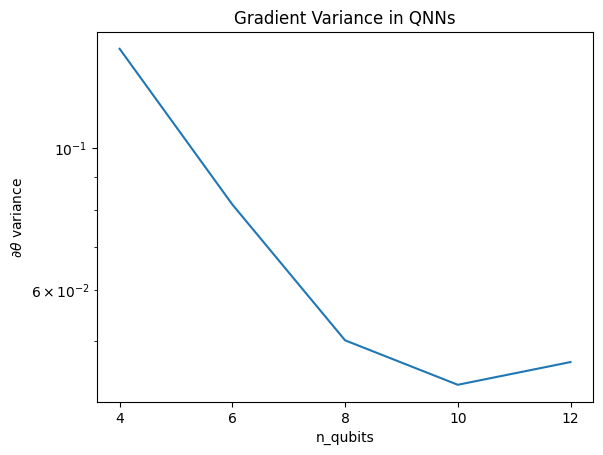
Questa trama mostra che per i problemi di apprendimento automatico quantistico, non puoi semplicemente indovinare un QNN ansatz casuale e sperare per il meglio. Una certa struttura deve essere presente nel circuito del modello in modo che i gradienti varino al punto in cui può avvenire l'apprendimento.
4. Euristica
Un'interessante euristica di Grant, 2019, consente di iniziare molto vicino al casuale, ma non del tutto. Utilizzando gli stessi circuiti di McClean et al., gli autori propongono una tecnica di inizializzazione diversa per i parametri di controllo classici per evitare plateau sterili. La tecnica di inizializzazione avvia alcuni livelli con parametri di controllo totalmente casuali, ma, nei livelli immediatamente successivi, scegli parametri in modo tale che la trasformazione iniziale effettuata dai primi livelli venga annullata. Gli autori chiamano questo un blocco di identità .
Il vantaggio di questa euristica è che modificando un solo parametro, tutti gli altri blocchi al di fuori del blocco corrente rimarranno l'identità e il segnale del gradiente arriva molto più forte di prima. Ciò consente all'utente di scegliere quali variabili e blocchi modificare per ottenere un forte segnale di gradiente. Questa euristica non impedisce all'utente di cadere in un altopiano sterile durante la fase di addestramento (e limita un aggiornamento completamente simultaneo), ma garantisce solo che puoi iniziare al di fuori di un altopiano.
4.1 Nuova costruzione QNN
Ora costruisci una funzione per generare QNN di blocco di identità. Questa implementazione è leggermente diversa da quella del documento. Per ora, osserva il comportamento del gradiente di un singolo parametro in modo che sia coerente con McClean et al, quindi è possibile apportare alcune semplificazioni.
Per generare un blocco di identità e addestrare il modello, in genere è necessario \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) e non \(U1(\theta_1) U1(\theta_1)^{\dagger}\). Inizialmente \(\theta_{1a}\) e \(\theta_{1b}\) sono gli stessi angoli ma vengono appresi indipendentemente. Altrimenti, otterrai sempre l'identità anche dopo l'allenamento. La scelta del numero di blocchi di identità è empirica. Più profondo è il blocco, minore è la varianza al centro del blocco. Ma all'inizio e alla fine del blocco, la varianza dei gradienti dei parametri dovrebbe essere ampia.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 Confronto
Qui puoi vedere che l'euristica aiuta a evitare che la varianza del gradiente svanisca più rapidamente:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
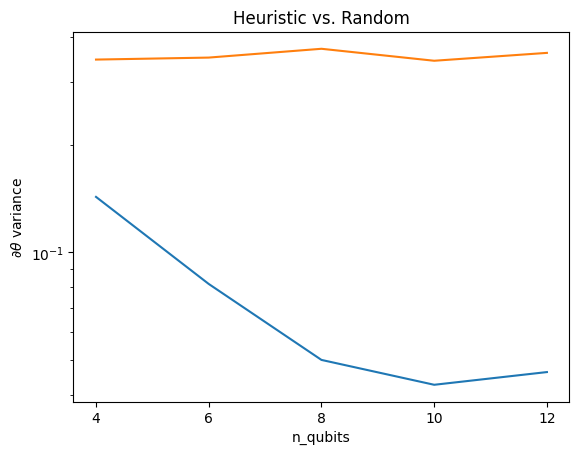
Questo è un grande miglioramento nell'ottenere segnali di gradiente più forti da QNN (quasi) casuali.