
Thư viện Xếp hạng TensorFlow giúp bạn xây dựng khả năng mở rộng học tập để xếp hạng các mô hình học máy bằng cách sử dụng các phương pháp và kỹ thuật đã được thiết lập tốt từ nghiên cứu gần đây. Mô hình xếp hạng lấy danh sách các mục tương tự, chẳng hạn như các trang web và tạo danh sách được tối ưu hóa cho các mục đó, ví dụ: có liên quan nhất đến các trang ít liên quan nhất. Các mô hình học cách xếp hạng có ứng dụng trong tìm kiếm, trả lời câu hỏi, hệ thống gợi ý và hệ thống đối thoại. Bạn có thể sử dụng thư viện này để tăng tốc xây dựng mô hình xếp hạng cho ứng dụng của mình bằng API Keras . Thư viện Xếp hạng cũng cung cấp các tiện ích quy trình làm việc để giúp bạn dễ dàng mở rộng quy mô triển khai mô hình để hoạt động hiệu quả với các tập dữ liệu lớn bằng cách sử dụng các chiến lược xử lý phân tán.
Tổng quan này cung cấp bản tóm tắt ngắn gọn về việc phát triển các mô hình học tập để xếp hạng với thư viện này, giới thiệu một số kỹ thuật nâng cao được thư viện hỗ trợ và thảo luận về các tiện ích quy trình làm việc được cung cấp để hỗ trợ xử lý phân tán cho các ứng dụng xếp hạng.
Phát triển việc học cách xếp hạng các mô hình
Xây dựng mô hình với thư viện TensorFlow Xếp hạng thực hiện theo các bước chung sau:
- Chỉ định chức năng tính điểm bằng cách sử dụng các lớp Keras (
tf.keras.layers) - Xác định số liệu bạn muốn sử dụng để đánh giá, chẳng hạn như
tfr.keras.metrics.NDCGMetric - Chỉ định một hàm mất mát, chẳng hạn như
tfr.keras.losses.SoftmaxLoss - Biên dịch mô hình bằng
tf.keras.Model.compile()và huấn luyện nó bằng dữ liệu của bạn
Hướng dẫn Đề xuất phim sẽ hướng dẫn bạn những kiến thức cơ bản về xây dựng mô hình học cách xếp hạng với thư viện này. Hãy xem phần Hỗ trợ xếp hạng phân tán để biết thêm thông tin về cách xây dựng mô hình xếp hạng quy mô lớn.
Kỹ thuật xếp hạng nâng cao
Thư viện Xếp hạng TensorFlow cung cấp hỗ trợ áp dụng các kỹ thuật xếp hạng nâng cao được nghiên cứu và triển khai bởi các nhà nghiên cứu và kỹ sư của Google. Các phần sau đây cung cấp thông tin tổng quan về một số kỹ thuật này và cách bắt đầu sử dụng chúng trong ứng dụng của bạn.
Thứ tự đầu vào danh sách BERT
Thư viện Xếp hạng cung cấp cách triển khai TFR-BERT, một kiến trúc tính điểm kết hợp BERT với mô hình LTR để tối ưu hóa thứ tự đầu vào danh sách. Để làm ví dụ ứng dụng của phương pháp này, hãy xem xét một truy vấn và danh sách n tài liệu mà bạn muốn xếp hạng theo truy vấn này. Thay vì học cách biểu diễn BERT được tính điểm độc lập trên các cặp <query, document> , mô hình LTR áp dụng tổn thất xếp hạng để cùng học cách biểu diễn BERT nhằm tối đa hóa tiện ích của toàn bộ danh sách được xếp hạng đối với các nhãn sự thật cơ bản. Hình dưới đây minh họa kỹ thuật này:
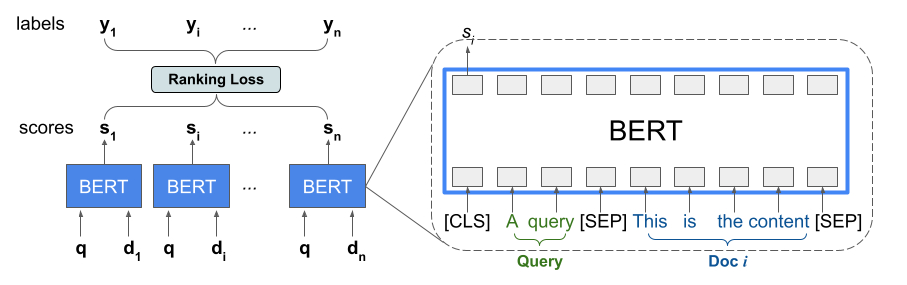
Cách tiếp cận này làm phẳng danh sách các tài liệu để xếp hạng theo phản hồi của một truy vấn thành danh sách các bộ dữ liệu <query, document> . Các bộ dữ liệu này sau đó được đưa vào mô hình ngôn ngữ được đào tạo trước BERT. Sau đó, các đầu ra BERT gộp cho toàn bộ danh sách tài liệu sẽ được tinh chỉnh chung với một trong những tổn thất xếp hạng chuyên biệt có trong Xếp hạng TensorFlow.
Kiến trúc này có thể mang lại những cải tiến đáng kể về hiệu suất của mô hình ngôn ngữ được huấn luyện trước, tạo ra hiệu suất tiên tiến cho một số tác vụ xếp hạng phổ biến, đặc biệt khi kết hợp nhiều mô hình ngôn ngữ được huấn luyện trước. Để biết thêm thông tin về kỹ thuật này, hãy xem nghiên cứu liên quan. Bạn có thể bắt đầu bằng cách triển khai đơn giản trong mã ví dụ Xếp hạng TensorFlow.
Mô hình phụ gia tổng quát xếp hạng thần kinh (GAM)
Đối với một số hệ thống xếp hạng, chẳng hạn như đánh giá khả năng đủ điều kiện cho vay, nhắm mục tiêu quảng cáo hoặc hướng dẫn điều trị y tế, tính minh bạch và khả năng giải thích là những cân nhắc quan trọng. Việc áp dụng các Mô hình phụ gia tổng quát (GAM) với các hệ số trọng số được hiểu rõ có thể giúp mô hình xếp hạng của bạn dễ hiểu và dễ hiểu hơn.
GAM đã được nghiên cứu rộng rãi với các nhiệm vụ hồi quy và phân loại, nhưng cách áp dụng chúng vào ứng dụng xếp hạng vẫn chưa rõ ràng. Ví dụ: trong khi GAM có thể được áp dụng đơn giản để lập mô hình từng mục riêng lẻ trong danh sách, thì việc lập mô hình cả tương tác giữa các mục và bối cảnh mà các mục này được xếp hạng là một vấn đề khó khăn hơn. Xếp hạng TensorFlow cung cấp cách triển khai GAM xếp hạng thần kinh , một phần mở rộng của các mô hình cộng tổng quát được thiết kế cho các bài toán xếp hạng. Việc triển khai GAM Xếp hạng TensorFlow cho phép bạn thêm trọng số cụ thể vào các tính năng của mô hình của mình.
Hình minh họa sau đây về hệ thống xếp hạng khách sạn sử dụng mức độ liên quan, giá cả và khoảng cách làm các đặc điểm xếp hạng chính. Mô hình này áp dụng kỹ thuật GAM để cân nhắc các kích thước này một cách khác nhau, dựa trên bối cảnh thiết bị của người dùng. Ví dụ: nếu truy vấn đến từ điện thoại, khoảng cách sẽ được coi trọng hơn, giả sử người dùng đang tìm kiếm một khách sạn gần đó.
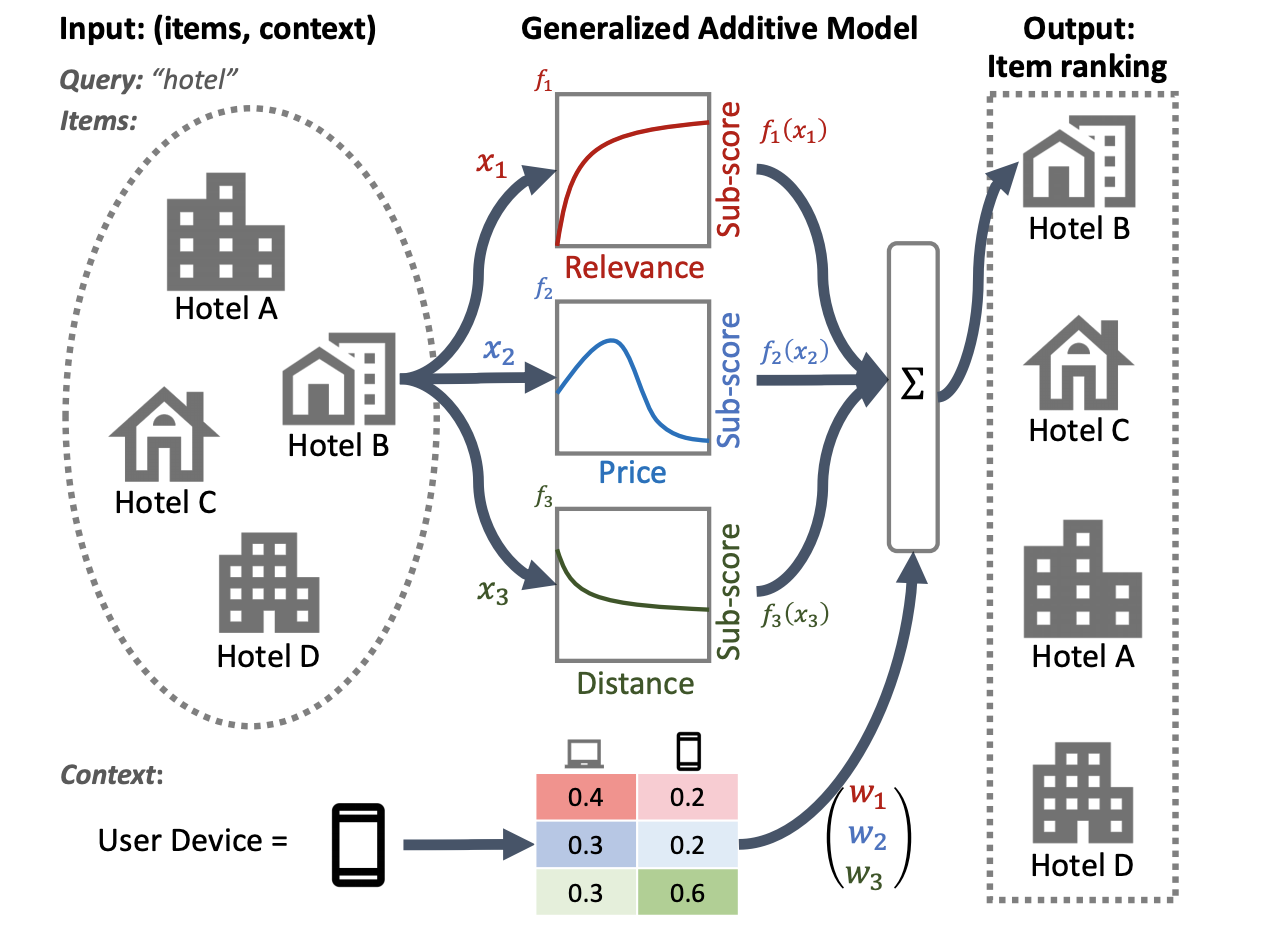
Để biết thêm thông tin về cách sử dụng GAM với mô hình xếp hạng, hãy xem nghiên cứu liên quan. Bạn có thể bắt đầu triển khai mẫu kỹ thuật này trong mã ví dụ Xếp hạng TensorFlow.
Hỗ trợ xếp hạng phân phối
Xếp hạng TensorFlow được thiết kế để xây dựng các hệ thống xếp hạng quy mô lớn từ đầu đến cuối: bao gồm xử lý dữ liệu, xây dựng mô hình, đánh giá và triển khai sản xuất. Nó có thể xử lý các tính năng dày đặc và thưa thớt không đồng nhất, mở rộng quy mô lên tới hàng triệu điểm dữ liệu và được thiết kế để hỗ trợ đào tạo phân tán cho các ứng dụng xếp hạng quy mô lớn.
Thư viện cung cấp kiến trúc quy trình xếp hạng được tối ưu hóa, để tránh mã soạn sẵn lặp đi lặp lại và tạo ra các giải pháp phân tán có thể áp dụng từ việc đào tạo mô hình xếp hạng của bạn đến phục vụ nó. Quy trình xếp hạng hỗ trợ hầu hết các chiến lược phân tán của TensorFlow, bao gồm MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy và ParameterServerStrategy . Đường dẫn xếp hạng có thể xuất mô hình xếp hạng đã được huấn luyện ở định dạng tf.saved_model , hỗ trợ một số chữ ký đầu vào. Ngoài ra, đường dẫn Xếp hạng cung cấp các lệnh gọi lại hữu ích, bao gồm hỗ trợ trực quan hóa dữ liệu TensorBoard và BackupAndRestore để giúp khôi phục sau các lỗi trong thời gian dài hoạt động đào tạo.
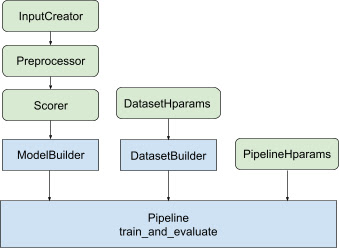
Thư viện xếp hạng hỗ trợ xây dựng triển khai đào tạo phân tán bằng cách cung cấp một tập hợp các lớp tfr.keras.pipeline , lấy trình tạo mô hình, trình tạo dữ liệu và siêu tham số làm đầu vào. Lớp tfr.keras.ModelBuilder dựa trên Keras cho phép bạn tạo một mô hình để xử lý phân tán và hoạt động với các lớp InputCreator, Preprocessor và Scorer có thể mở rộng:
Các lớp quy trình Xếp hạng TensorFlow cũng hoạt động với DatasetBuilder để thiết lập dữ liệu đào tạo, có thể kết hợp các siêu tham số . Cuối cùng, bản thân đường ống có thể bao gồm một tập hợp các siêu tham số làm đối tượng PipelineHparams .
Bắt đầu xây dựng các mô hình xếp hạng phân tán bằng cách sử dụng hướng dẫn Xếp hạng phân tán .