
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Trong các featurization hướng dẫn chúng tôi kết hợp nhiều tính năng vào các mô hình của chúng tôi, nhưng các mô hình chỉ gồm một lớp nhúng. Chúng ta có thể thêm các lớp dày đặc hơn vào các mô hình của mình để tăng sức biểu đạt của chúng.
Nói chung, các mô hình sâu hơn có khả năng học các mẫu phức tạp hơn các mô hình nông hơn. Ví dụ, chúng tôi mô hình sử dụng kết hợp id người dùng và timestamps đến sở thích người dùng mô hình tại một thời điểm nào. Một mô hình nông (ví dụ, một lớp nhúng duy nhất) chỉ có thể tìm hiểu các mối quan hệ đơn giản nhất giữa các tính năng đó và phim: một bộ phim nhất định được yêu thích nhất vào khoảng thời gian phát hành và một người dùng nhất định thường thích phim kinh dị hơn phim hài. Để nắm bắt các mối quan hệ phức tạp hơn, chẳng hạn như sở thích của người dùng phát triển theo thời gian, chúng tôi có thể cần một mô hình sâu hơn với nhiều lớp dày đặc xếp chồng lên nhau.
Tất nhiên, các mô hình phức tạp cũng có những nhược điểm của chúng. Đầu tiên là chi phí tính toán, vì các mô hình lớn hơn yêu cầu nhiều bộ nhớ hơn và nhiều tính toán hơn để phù hợp và phục vụ. Thứ hai là yêu cầu về nhiều dữ liệu hơn: nói chung, cần nhiều dữ liệu đào tạo hơn để tận dụng các mô hình sâu hơn. Với nhiều tham số hơn, các mô hình sâu có thể trang bị quá mức hoặc thậm chí chỉ cần ghi nhớ các ví dụ đào tạo thay vì học một hàm có thể tổng quát hóa. Cuối cùng, việc đào tạo các mô hình sâu hơn có thể khó hơn và cần phải cẩn thận hơn trong việc lựa chọn các cài đặt như chính quy hóa và tỷ lệ học tập.
Tìm một kiến trúc tốt cho một hệ thống recommender thực thế giới là một nghệ thuật phức tạp, đòi hỏi phải có trực giác tốt và cẩn thận hyperparameter chỉnh . Ví dụ: các yếu tố như chiều sâu và chiều rộng của mô hình, chức năng kích hoạt, tốc độ học tập và trình tối ưu hóa có thể thay đổi hoàn toàn hiệu suất của mô hình. Các lựa chọn mô hình còn phức tạp hơn bởi thực tế là các chỉ số đánh giá ngoại tuyến tốt có thể không tương ứng với hiệu suất trực tuyến tốt và việc lựa chọn những gì cần tối ưu hóa thường quan trọng hơn việc lựa chọn chính mô hình.
Tuy nhiên, nỗ lực xây dựng và tinh chỉnh các mô hình lớn hơn thường được đền đáp. Trong hướng dẫn này, chúng tôi sẽ minh họa cách xây dựng mô hình truy xuất sâu bằng cách sử dụng TensorFlow Recommenders. Chúng tôi sẽ làm điều này bằng cách xây dựng các mô hình phức tạp hơn dần dần để xem điều này ảnh hưởng như thế nào đến hiệu suất của mô hình.
Sơ bộ
Đầu tiên chúng tôi nhập các gói cần thiết.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
Trong hướng dẫn này chúng tôi sẽ sử dụng các mô hình từ các hướng dẫn featurization để tạo embeddings. Do đó, chúng tôi sẽ chỉ sử dụng các tính năng id người dùng, dấu thời gian và tiêu đề phim.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Chúng tôi cũng thực hiện một số công việc dọn phòng để chuẩn bị các từ vựng nổi bật.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
Định nghĩa mô hình
Mô hình truy vấn
Chúng tôi bắt đầu với mô hình sử dụng quy định tại hướng dẫn featurization như lớp đầu tiên của mô hình của chúng tôi, có nhiệm vụ chuyển đổi ví dụ đầu vào thô thành embeddings tính năng.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
Việc xác định các mô hình sâu hơn sẽ yêu cầu chúng ta xếp chồng các lớp chế độ lên trên đầu vào đầu tiên này. Một chồng lớp hẹp dần dần, được phân tách bằng một hàm kích hoạt, là một mẫu phổ biến:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
Vì sức mạnh biểu đạt của mô hình tuyến tính sâu không lớn hơn mô hình tuyến tính nông, chúng tôi sử dụng kích hoạt ReLU cho tất cả trừ lớp ẩn cuối cùng. Lớp ẩn cuối cùng không sử dụng bất kỳ chức năng kích hoạt nào: sử dụng chức năng kích hoạt sẽ giới hạn không gian đầu ra của các lần nhúng cuối cùng và có thể tác động tiêu cực đến hiệu suất của mô hình. Ví dụ: nếu ReLU được sử dụng trong lớp chiếu, tất cả các thành phần trong nhúng đầu ra sẽ là không âm.
Chúng tôi sẽ thử một cái gì đó tương tự ở đây. Để dễ dàng thử nghiệm với các độ sâu khác nhau, hãy xác định một mô hình có độ sâu (và chiều rộng) được xác định bởi một tập hợp các tham số của phương thức khởi tạo.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Các layer_sizes tham số cho chúng ta chiều sâu và chiều rộng của mô hình. Chúng tôi có thể thay đổi nó để thử nghiệm với các mô hình nông hơn hoặc sâu hơn.
Người mẫu ứng cử viên
Chúng ta có thể áp dụng cách tiếp cận tương tự cho mô hình phim. Một lần nữa, chúng ta bắt đầu với MovieModel từ featurization hướng dẫn:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
Và mở rộng nó với các lớp ẩn:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Mô hình kết hợp
Với cả hai QueryModel và CandidateModel xác định, chúng ta có thể đặt cùng một mô hình kết hợp và thực hiện các tổn thất và số liệu luận lý của chúng tôi. Để làm cho mọi thứ trở nên đơn giản, chúng tôi sẽ thực thi rằng cấu trúc mô hình giống nhau trên các mô hình truy vấn và ứng viên.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
Đào tạo người mẫu
Chuẩn bị dữ liệu
Đầu tiên, chúng tôi chia dữ liệu thành tập huấn luyện và tập thử nghiệm.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
Mô hình nông
Chúng tôi đã sẵn sàng để thử mô hình nông, đầu tiên của mình!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
Điều này mang lại cho chúng tôi độ chính xác hàng đầu trong khoảng 0,27. Chúng tôi có thể sử dụng điều này làm điểm tham chiếu để đánh giá các mô hình sâu hơn.
Mô hình sâu hơn
Điều gì về một mô hình sâu hơn với hai lớp?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
Độ chính xác ở đây là 0,29, tốt hơn một chút so với mô hình nông.
Chúng ta có thể vẽ các đường cong độ chính xác xác thực để minh họa điều này:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
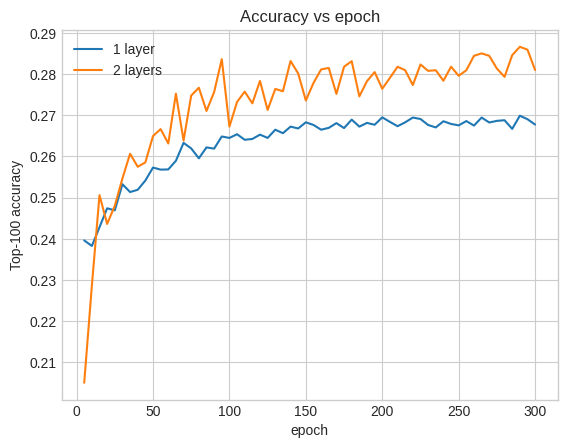
Ngay từ đầu trong quá trình đào tạo, mô hình lớn hơn đã dẫn đầu rõ ràng và ổn định so với mô hình nông, cho thấy rằng việc thêm chiều sâu sẽ giúp mô hình nắm bắt được các mối quan hệ nhiều sắc thái hơn trong dữ liệu.
Tuy nhiên, các mô hình thậm chí sâu hơn không nhất thiết phải tốt hơn. Mô hình sau mở rộng độ sâu thành ba lớp:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
Trên thực tế, chúng tôi không thấy sự cải thiện so với mô hình nông:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
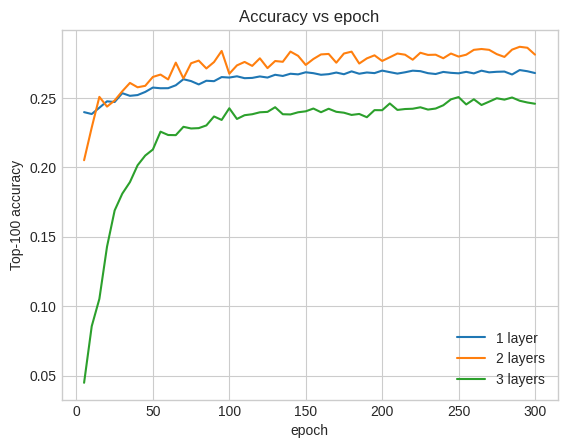
Đây là một minh họa tốt về thực tế rằng các mô hình sâu hơn và lớn hơn, mặc dù có khả năng hoạt động tốt hơn, thường yêu cầu điều chỉnh rất cẩn thận. Ví dụ, trong suốt hướng dẫn này, chúng tôi đã sử dụng một tỷ lệ học tập cố định, duy nhất. Các lựa chọn thay thế có thể cho kết quả rất khác và đáng để khám phá.
Với sự điều chỉnh thích hợp và đủ dữ liệu, nỗ lực xây dựng các mô hình lớn hơn và sâu hơn trong nhiều trường hợp là rất xứng đáng: các mô hình lớn hơn có thể dẫn đến những cải tiến đáng kể về độ chính xác của dự đoán.
Bước tiếp theo
Trong hướng dẫn này, chúng tôi đã mở rộng mô hình truy xuất của mình với các lớp dày đặc và các chức năng kích hoạt. Để xem làm thế nào để tạo ra một mô hình có thể thực hiện nhiệm vụ không chỉ thu hồi mà còn nhiệm vụ đánh giá, hãy xem các hướng dẫn đa nhiệm .