
개요
TensorBoard의 주요 기능은 대화형 GUI입니다. 그러나 사용자는 사후 분석을 수행하고 로그 데이터의 사용자 지정 시각화를 만드는 등의 목적으로 TensorBoard에 저장된 데이터 로그를 프로그래밍 방식으로 읽고 싶어하는 경우가 있습니다.
TensorBoard 2.3은 tensorboard.data.experimental.ExperimentFromDev()로 이 사용 사례를 지원하여 TensorBoard의 스칼라 로그에 프로그래밍 방식으로 액세스할 수 있습니다. 이 페이지는 이 새로운 API의 기본 사용법을 보여줍니다.
참고:
- 이 API는 API 네임스페이스에 반영된 대로 아직 실험 단계에 있습니다. 이는 API가 향후 변경될 수 있음을 의미합니다.
- 현재 이 기능은 TensorBoard를 유지하고 공유하기 위한 무료 호스팅 서비스인 TensorBoard.dev에 업로드된 logdir만 지원합니다. 로컬에 저장된 TensorBoard logdir에 대한 지원은 향후 추가될 예정입니다. 간단히 말해,
tensorboard dev upload --logdir<logdir>한 줄의 명령으로 로컬 파일 시스템의 TensorBoard logdir을 TensorBoard.dev에 업로드할 수 있습니다. 자세한 내용은 tensorboard.dev의 설명서를 참조하세요.
설정
프로그래밍 방식 API를 사용하려면 tensorboard와 함께 pandas를 설치해야 합니다.
이 튜토리얼에서는 사용자 정의 플롯에 matplotlib 및 seaborn을 사용하지만, 선호하는 도구를 선택하여 DataFrame을 분석하고 시각화할 수 있습니다.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
TensorBoard 스칼라를 pandas.DataFrame로 로드하기
Once a TensorBoard logdir has been uploaded to TensorBoard.dev, it becomes what we refer to as an experiment. Each experiment has a unique ID, which can be found in the TensorBoard.dev URL of the experiment. For our demonstration below, we will use a TensorBoard.dev experiment at: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df는 실험의 모든 스칼라 로그를 포함하는 pandas.DataFrame입니다.
DataFrame의 열은 다음과 같습니다.
run: 각 실행은 원래 logdir의 하위 디렉토리에 해당합니다. 이 실험에서 각 실행은 주어진 옵티마이저 형식(훈련 하이퍼 매개변수)을 사용하여 MNIST 데이터세트에 대한 컨본루셔널 신경망(CNN)의 완전한 훈련에서 나온 것입니다. 이DataFrame에는 여러 옵티마이저 형식에서 반복되는 훈련 실행에 해당하는 여러 실행이 포함됩니다.tag: 같은 행의value가 의미하며, 즉 값이 행에서 나타내는 메트릭을 설명합니다. 이 실험에는 정확성 및 손실 메트릭에 대해 각각epoch_accuracy및epoch_loss라는 두 개의 고유 태그만 있습니다.step: 실행에서 해당 행의 일련 순서를 반영하는 숫자입니다. 여기서step은 실제로 epoch 번호를 나타냅니다.step값 외에도 타임스탬프를 얻으려면get_scalars()를 호출할 때 키워드 인수include_wall_time=True를 사용할 수 있습니다.value: 주목할 실제 숫자 값입니다. 위에서 설명한 것처럼, 이 특정DataFrame의 각value는 행의tag에 따라 손실 또는 정확성입니다.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
피벗된 (와이드 형식) DataFrame 가져오기
실험에서 두 태그(epoch_loss 및 epoch_accuracy)는 각 실행에서 같은 단계 세트에 있습니다. 이렇게 하면 pivot=True 키워드 인수를 사용하여 get_scalars()에서 직접 '와이드 형식' DataFrame을 가져올 수 있습니다. 와이드 형식의 DataFrame에는 모든 태그가 DataFrame의 열로 포함되어 있으므로 경우에 따라 해당 사례처럼 처리하는 것이 더 편리하기도 합니다.
그러나 모든 실행에서 모든 태그에 대해 균일한 단계 값 세트를 갖는 조건이 충족되지 않는 경우, pivot=True를 사용하면 오류가 발생합니다.
dfw = experiment.get_scalars(pivot=True)
dfw
Notice that instead of a single "value" column, the wide-form DataFrame includes the two tags (metrics) as its columns explicitly: epoch_accuracy and epoch_loss.
DataFrame을 CSV로 저장하기
pandas.DataFrame has good interoperability with CSV. You can store it as a local CSV file and load it back later. For example:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
사용자 정의 시각화 및 통계 분석 수행하기
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
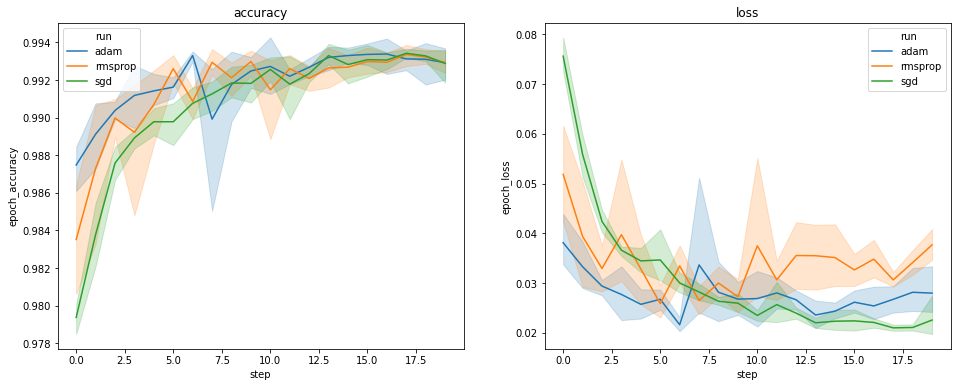
위의 플롯은 검증 정확성과 검증 손실의 시간 과정을 보여줍니다. 각 곡선은 옵티마이저 형식에서 5회 실행의 평균을 보여줍니다. seaborn.lineplot()의 내장 기능 덕분에 각 곡선은 평균 주위에 ±1 표준 편차를 표시하므로 이러한 곡선의 변동성과 3가지 옵티마이저 형식 간의 중요한 차이를 명확하게 알 수 있습니다. 변동성의 시각화는 아직 TensorBoard의 GUI에서 지원되지 않습니다.
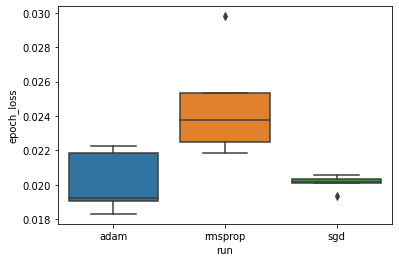
최소 검증 손실이 'adam', 'rmsprop' 및 'sgd' 옵티마이저 간에 크게 다르다는 가설을 연구하려고 합니다. 따라서 각 옵티마이저에서 최소 검증 손실을 위해 DataFrame을 추출합니다.
그런 다음 최소 검증 손실의 차이를 시각화하기 위해 상자 그림을 만듭니다.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
따라서 0.05의 유의 수준에서 분석은 최소 검증 손실이 실험에 포함 된 다른 두 옵티마이저에 비해 rmsprop 옵티마이저에서 훨씬 더 높다는 (즉, 더 나쁘다는) 가설을 확인합니다.
요약하면, 이 튜토리얼에서는 TensorBoard.dev에서 panda.DataFrame으로 스칼라 데이터에 액세스하는 방법의 예를 제공합니다. DataFrame으로 수행할 수 있는 유연하고 강력한 분석 및 시각화를 보여줍니다.