
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
기계 학습에서 무언가를 개선하려면 종종 측정할 수 있어야 합니다. TensorBoard는 기계 학습 워크플로 중에 필요한 측정 및 시각화를 제공하기 위한 도구입니다. 손실 및 정확도와 같은 실험 메트릭을 추적하고, 모델 그래프를 시각화하고, 임베딩을 저차원 공간에 투영하는 등의 작업을 수행할 수 있습니다.
이 빠른 시작에서는 TensorBoard를 빠르게 시작하는 방법을 보여줍니다. 이 웹 사이트의 나머지 가이드는 여기에 포함되지 않은 특정 기능에 대한 자세한 내용을 제공합니다.
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
은 Using MNIST의 예와 같은 데이터 세트를 상기 데이터 정규화 10 개 등급으로 영상을 분류하기위한 간단한 Keras 모델을 생성하는 함수를 작성.
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Keras Model.fit()과 함께 TensorBoard 사용
Keras의와 훈련 때 Model.fit () 추가하는 tf.keras.callbacks.TensorBoard 콜백 보장하지만 로그가 생성되고 저장됩니다. 또한, 활성화 히스토그램 연산마다 이포 histogram_freq=1 (이는 기본적으로 꺼져)
다른 훈련 실행을 쉽게 선택할 수 있도록 타임스탬프가 지정된 하위 디렉터리에 로그를 배치합니다.
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
명령줄을 통해 또는 노트북 환경 내에서 TensorBoard를 시작합니다. 두 인터페이스는 일반적으로 동일합니다. 노트북에서 사용 %tensorboard 라인 마법을. 명령줄에서 "%" 없이 동일한 명령을 실행합니다.
%tensorboard --logdir logs/fit
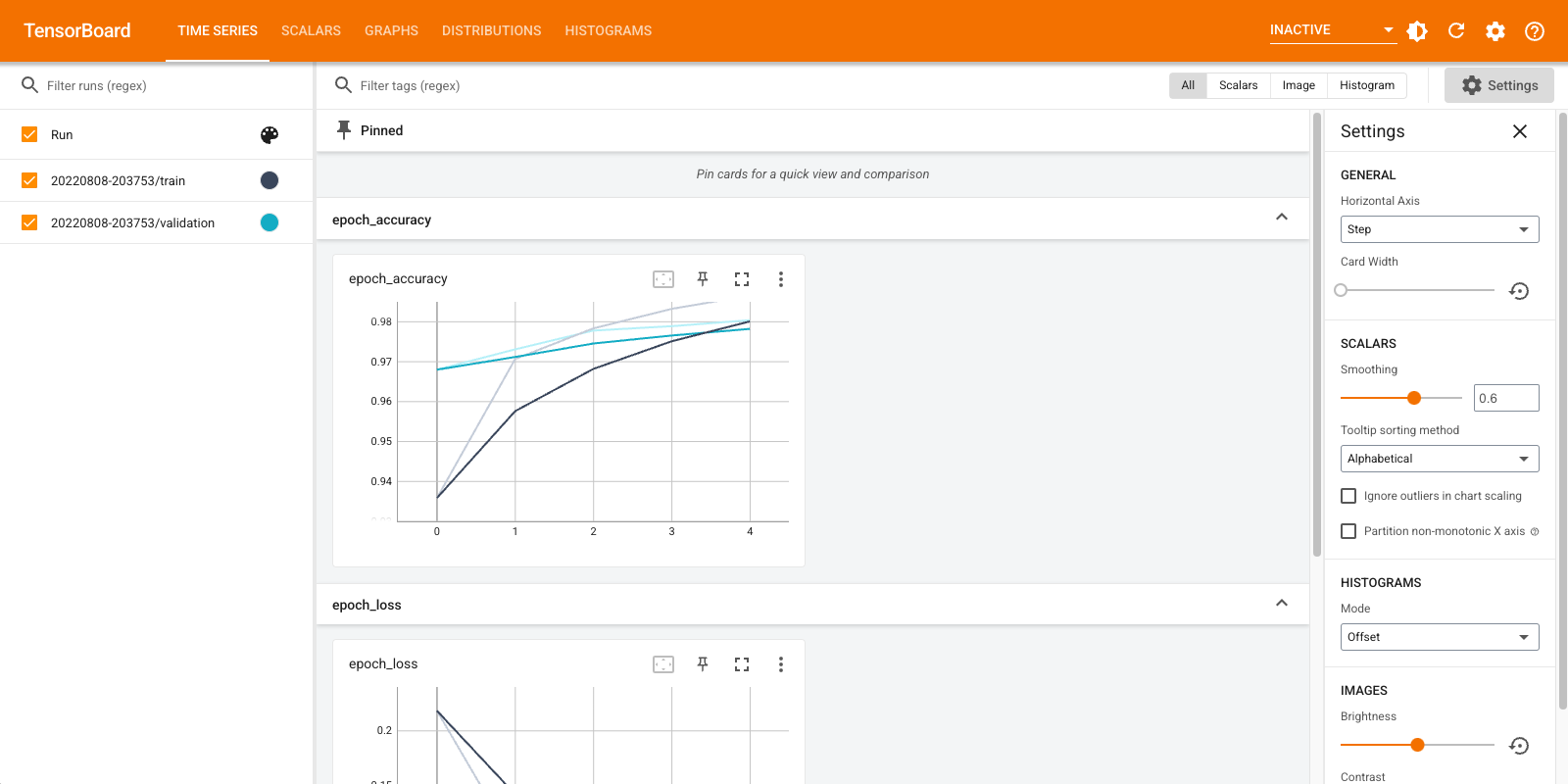
표시된 대시보드에 대한 간략한 개요(상단 탐색 모음의 탭):
- 스칼라 대시 보드 쇼는 어떻게 손실 측정은 모든 시대로 변경합니다. 이를 사용하여 훈련 속도, 학습률 및 기타 스칼라 값을 추적할 수도 있습니다.
- 그래프 대시 보드는 모델을 시각화하는 데 도움이됩니다. 이 경우 레이어의 Keras 그래프가 표시되어 올바르게 빌드되었는지 확인할 수 있습니다.
- 분포 및 히스토그램 대시 보드는 시간이 지남에 텐서의 분포를 보여줍니다. 이는 가중치와 편향을 시각화하고 예상한 방식으로 변경되고 있는지 확인하는 데 유용할 수 있습니다.
다른 유형의 데이터를 기록하면 추가 TensorBoard 플러그인이 자동으로 활성화됩니다. 예를 들어, Keras TensorBoard 콜백을 사용하면 이미지와 임베딩도 기록할 수 있습니다. 오른쪽 상단의 "비활성" 드롭다운을 클릭하여 TensorBoard에서 사용할 수 있는 다른 플러그인을 확인할 수 있습니다.
다른 방법과 함께 TensorBoard 사용
같은 방식으로 훈련 때 tf.GradientTape() 를 사용 tf.summary 필요한 정보를 기록한다.
에 위와 동일한 데이터 집합을 사용하지만, 변환 tf.data.Dataset 기능을 일괄 처리의 활용 :
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
훈련 코드는 다음과 고급 빠른 시작 자습서를하지만 쇼는 어떻게 TensorBoard에 통계를 기록 할 수 있습니다. 손실 및 최적화 프로그램 선택:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
훈련 중 값을 누적하고 어느 시점에서든 기록하는 데 사용할 수 있는 상태 저장 메트릭을 만듭니다.
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
훈련 및 테스트 함수를 정의합니다.
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
다른 로그 디렉토리의 디스크에 요약을 쓰도록 요약 작성자를 설정합니다.
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
훈련을 시작합니다. 사용 tf.summary.scalar() 디스크에 요약을 작성하는 요약 작가의 범위 내에서 테스트 / 훈련 기간 동안 측정 (손실과 정확성)을 기록 할 수 있습니다. 기록할 측정항목과 기록 빈도를 제어할 수 있습니다. 다른 tf.summary 기능은 다른 종류의 데이터를 기록 할 수 있습니다.
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
TensorBoard를 다시 엽니다. 이번에는 새 로그 디렉토리를 가리킵니다. TensorBoard를 시작하여 교육이 진행되는 동안 모니터링할 수도 있습니다.
%tensorboard --logdir logs/gradient_tape
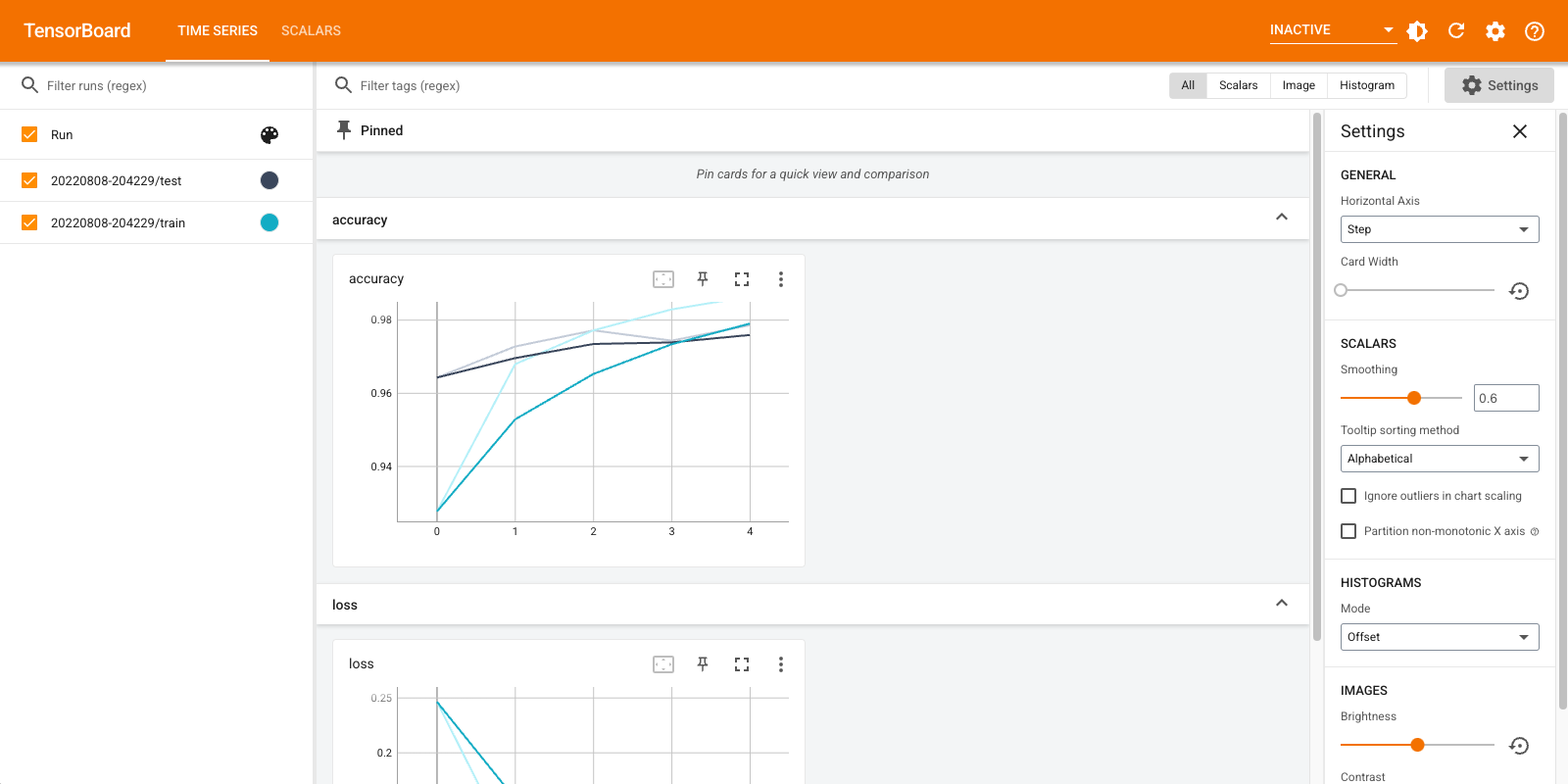
그게 다야! 이제 Keras 콜백을 통해 통해 모두 TensorBoard를 사용하는 방법을 보았다 tf.summary 이상의 사용자 정의 시나리오.
TensorBoard.dev: ML 실험 결과 호스팅 및 공유
TensorBoard.dev은 당신이 당신의 TensorBoard 로그를 업로드하고 더 나은 재현성과 협업을 활성화 할 수 있습니다 등이 학술 논문의 모든 사람, 블로그 게시물, 소셜 미디어와 함께 공유 할 수있는 고유 주소를 얻을 수있는 무료 공공 서비스입니다.
TensorBoard.dev를 사용하려면 다음 명령어를 실행하세요.
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
이 호출은 느낌표 접두사를 사용하는 주 ( ! ) 쉘이 아닌 %의 접두사 (호출 할 % colab 마법을 호출을). 명령줄에서 이 명령을 호출할 때 접두사는 필요하지 않습니다.
예를 보려면 여기 .
TensorBoard.dev을 사용하는 방법에 대한 자세한 내용은 참조 https://tensorboard.dev/#get-started을