
Tổng quat
Tính năng chính của TensorBoard là GUI tương tác của nó. Tuy nhiên, người dùng đôi khi muốn lập trình đọc các bản ghi dữ liệu lưu trữ trong TensorBoard, cho các mục đích như thực hiện sau hoc phân tích và tạo ra hình ảnh tùy chỉnh của dữ liệu log.
TensorBoard 2.3 hỗ trợ trường hợp sử dụng này với tensorboard.data.experimental.ExperimentFromDev() . Nó cho phép truy cập chương trình đối với TensorBoard của log vô hướng . Trang này trình bày cách sử dụng cơ bản của API mới này.
Cài đặt
Để sử dụng API chương trình, chắc chắn rằng bạn cài đặt pandas cùng tensorboard .
Chúng tôi sẽ sử dụng matplotlib và seaborn cho lô tùy chỉnh trong hướng dẫn này, nhưng bạn có thể chọn công cụ ưa thích của bạn để phân tích và hình dung DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Đang tải vô hướng TensorBoard như một pandas.DataFrame
Khi một logdir TensorBoard đã được tải lên TensorBoard.dev, nó trở nên những gì chúng ta gọi là một thử nghiệm. Mỗi thử nghiệm có một ID duy nhất, có thể được tìm thấy trong URL TensorBoard.dev của thử nghiệm. Đối với cuộc biểu tình của chúng tôi dưới đây, chúng tôi sẽ sử dụng một thí nghiệm TensorBoard.dev tại địa chỉ: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df là một pandas.DataFrame có chứa tất cả các bản ghi vô hướng của thí nghiệm.
Các cột của DataFrame là:
-
run: mỗi lần chạy tương ứng với một thư mục con của logdir gốc. Trong thử nghiệm này, mỗi lần chạy là từ quá trình huấn luyện hoàn chỉnh mạng nơ-ron tích hợp (CNN) trên tập dữ liệu MNIST với một loại trình tối ưu hóa nhất định (một siêu tham số huấn luyện). ĐâyDataFramechứa nhiều chạy như vậy, tương ứng với chạy đào tạo lặp đi lặp lại dưới loại ưu khác nhau. -
tag: điều này mô tả những gìvaluetrong các phương tiện cùng hàng, có nghĩa là, những gì số liệu giá trị đại diện ở hàng. Trong thí nghiệm này, chúng tôi chỉ có hai thẻ duy nhất:epoch_accuracyvàepoch_lossvề tính chính xác và mất số liệu tương ứng. -
step: Đây là một con số đó phản ánh thứ tự nối tiếp của dòng tương ứng trong hoạt động của mình. Dưới đâystepthực sự đề cập đến số kỷ nguyên. Nếu bạn muốn để có được những timestamps ngoài cácstepgiá trị, bạn có thể sử dụng đối số từ khóainclude_wall_time=Truekhi gọiget_scalars(). -
value: Đây là giá trị số thực tế quan tâm. Như đã trình bày ở trên, mỗivalueđặc biệt nàyDataFramehoặc là một sự mất mát hoặc độ chính xác, tùy thuộc vàotagcủa hàng.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Nhận DataFrame xoay vòng (dạng rộng)
Trong thí nghiệm của chúng tôi, hai thẻ ( epoch_loss và epoch_accuracy ) có mặt tại cùng một tập hợp các bước trong mỗi lần chạy. Điều này làm cho nó có thể để có được một "rộng hình thức" DataFrame trực tiếp từ get_scalars() bằng cách sử dụng các pivot=True tranh cãi từ khóa. Các rộng hình thức DataFrame có tất cả các thẻ của nó bao gồm như là cột của DataFrame, đó là thuận tiện hơn để làm việc với trong một số trường hợp trong đó có một này.
Tuy nhiên, hãy cẩn thận rằng nếu điều kiện của việc có bộ đồng phục của các giá trị bước qua tất cả các thẻ trong tất cả các lần chạy không được đáp ứng, sử dụng pivot=True sẽ dẫn đến một lỗi.
dfw = experiment.get_scalars(pivot=True)
dfw
Chú ý rằng thay vì một cột "giá trị" duy nhất, rộng hình thức DataFrame bao gồm hai thẻ (số liệu) như cột của nó một cách rõ ràng: epoch_accuracy và epoch_loss .
Lưu DataFrame dưới dạng CSV
pandas.DataFrame có khả năng tương tác tốt với CSV . Bạn có thể lưu trữ nó dưới dạng tệp CSV cục bộ và tải lại sau. Ví dụ:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Thực hiện trực quan hóa tùy chỉnh và phân tích thống kê
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
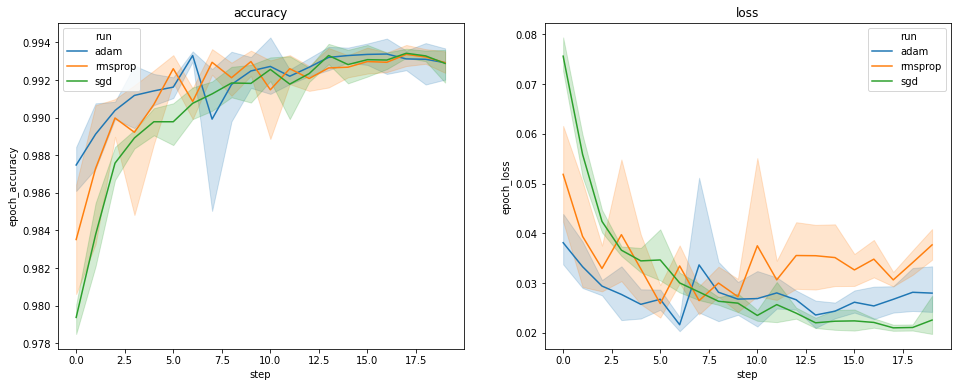
Các biểu đồ ở trên hiển thị các khóa thời gian về độ chính xác của xác thực và mất xác nhận. Mỗi đường cong hiển thị giá trị trung bình trên 5 lần chạy dưới một loại trình tối ưu hóa. Nhờ có một built-in tính năng của seaborn.lineplot() , mỗi đường cong cũng hiển thị ± 1 độ lệch chuẩn xung quanh giá trị trung bình, mang đến cho chúng ta một cảm giác rõ ràng về sự thay đổi trong các đường cong và tầm quan trọng của sự khác biệt giữa ba loại ưu. Hình ảnh hóa sự thay đổi này chưa được hỗ trợ trong GUI của TensorBoard.
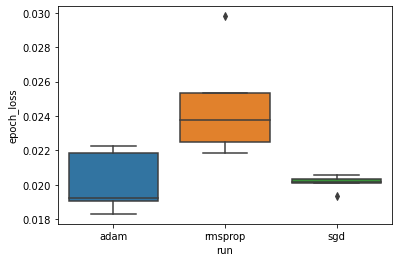
Chúng tôi muốn nghiên cứu giả thuyết rằng tổn thất xác thực tối thiểu khác biệt đáng kể ở mười hai trình tối ưu hóa "adam", "rmsprop" và "sgd". Vì vậy, chúng tôi trích xuất một DataFrame để giảm thiểu mất xác thực trong mỗi trình tối ưu hóa.
Sau đó, chúng tôi thực hiện một sơ đồ để hình dung sự khác biệt trong các tổn thất xác thực tối thiểu.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Do đó, với mức ý nghĩa 0,05, phân tích của chúng tôi xác nhận giả thuyết của chúng tôi rằng tổn thất xác thực tối thiểu cao hơn đáng kể (tức là tệ hơn) trong trình tối ưu hóa rmsprop so với hai trình tối ưu hóa khác có trong thử nghiệm của chúng tôi.
Nói tóm lại, hướng dẫn này cung cấp một ví dụ về làm thế nào để truy cập dữ liệu vô hướng như panda.DataFrame s từ TensorBoard.dev. Nó thể hiện các loại phân tích linh hoạt và mạnh mẽ và trực quan, bạn có thể làm với các DataFrame s.