
कभी-कभी TensorFlow कार्यक्रम के दौरान NaN s से जुड़ी विनाशकारी घटनाएं घटित हो सकती हैं, जो मॉडल प्रशिक्षण प्रक्रियाओं को बाधित कर सकती हैं। ऐसी घटनाओं का मूल कारण अक्सर अस्पष्ट होता है, विशेषकर गैर-तुच्छ आकार और जटिलता वाले मॉडलों के लिए। इस प्रकार के मॉडल बग को डीबग करना आसान बनाने के लिए, TensorBoard 2.3+ (TensorFlow 2.3+ के साथ) Debugger V2 नामक एक विशेष डैशबोर्ड प्रदान करता है। यहां हम प्रदर्शित करते हैं कि TensorFlow में लिखे तंत्रिका नेटवर्क में NaN से जुड़े वास्तविक बग के माध्यम से काम करके इस उपकरण का उपयोग कैसे किया जाए।
इस ट्यूटोरियल में बताई गई तकनीकें अन्य प्रकार की डिबगिंग गतिविधियों पर लागू होती हैं जैसे कि जटिल कार्यक्रमों में रनटाइम टेंसर आकृतियों का निरीक्षण करना। यह ट्यूटोरियल NaN की अपेक्षाकृत उच्च आवृत्ति के कारण उन पर केंद्रित है।
बग का अवलोकन करना
जिस TF2 प्रोग्राम को हम डिबग करेंगे उसका सोर्स कोड GitHub पर उपलब्ध है। उदाहरण प्रोग्राम को टेंसरफ्लो पिप पैकेज (संस्करण 2.3+) में भी पैक किया गया है और इसे इसके द्वारा लागू किया जा सकता है:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
यह TF2 प्रोग्राम एक मल्टी-लेयर परसेप्शन (MLP) बनाता है और इसे MNIST छवियों को पहचानने के लिए प्रशिक्षित करता है। यह उदाहरण कस्टम लेयर निर्माण, हानि फ़ंक्शन और प्रशिक्षण लूप को परिभाषित करने के लिए जानबूझकर टीएफ 2 के निम्न-स्तरीय एपीआई का उपयोग करता है, क्योंकि जब हम आसान का उपयोग करते हैं तो इस अधिक लचीले लेकिन अधिक त्रुटि-प्रवण एपीआई का उपयोग करते समय NaN बग की संभावना अधिक होती है। -उपयोग के लिए लेकिन थोड़ा कम लचीला उच्च-स्तरीय एपीआई जैसे कि tf.keras ।
प्रोग्राम प्रत्येक प्रशिक्षण चरण के बाद एक परीक्षण सटीकता प्रिंट करता है। हम कंसोल में देख सकते हैं कि पहले चरण के बाद परीक्षण सटीकता निकट-संभावना स्तर (~0.1) पर अटक जाती है। निश्चित रूप से मॉडल प्रशिक्षण से इस तरह व्यवहार करने की अपेक्षा नहीं की जाती है: हम उम्मीद करते हैं कि कदम बढ़ने के साथ सटीकता धीरे-धीरे 1.0 (100%) तक पहुंच जाएगी।
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
एक शिक्षित अनुमान यह है कि यह समस्या संख्यात्मक अस्थिरता, जैसे NaN या अनंत के कारण होती है। हालाँकि, हम इसकी पुष्टि कैसे करें कि यह वास्तव में मामला है और हम संख्यात्मक अस्थिरता उत्पन्न करने के लिए TensorFlow ऑपरेशन (ऑप) को कैसे जिम्मेदार पाते हैं? इन सवालों का जवाब देने के लिए, आइए डिबगर V2 के साथ बग्गी प्रोग्राम को इंस्ट्रूमेंट करें।
डिबगर V2 के साथ TensorFlow कोड को इंस्ट्रुमेंट करना
tf.debugging.experimental.enable_dump_debug_info() डिबगर V2 का एपीआई प्रवेश बिंदु है। यह कोड की एक पंक्ति के साथ एक TF2 प्रोग्राम तैयार करता है। उदाहरण के लिए, प्रोग्राम की शुरुआत के पास निम्नलिखित पंक्ति जोड़ने से डिबग जानकारी लॉग निर्देशिका (लॉगडीआईआर) में /tmp/tfdbg2_logdir पर लिखी जाएगी। डिबग जानकारी TensorFlow रनटाइम के विभिन्न पहलुओं को शामिल करती है। TF2 में, इसमें उत्सुक निष्पादन का पूरा इतिहास, @tf.function द्वारा निष्पादित ग्राफ निर्माण, ग्राफ़ का निष्पादन, निष्पादन घटनाओं द्वारा उत्पन्न टेंसर मान, साथ ही उन घटनाओं के कोड स्थान (पायथन स्टैक ट्रेस) शामिल हैं। . डिबग जानकारी की समृद्धि उपयोगकर्ताओं को अस्पष्ट बगों पर ध्यान केंद्रित करने में सक्षम बनाती है।
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
tensor_debug_mode तर्क यह नियंत्रित करता है कि डिबगर V2 प्रत्येक उत्सुक या इन-ग्राफ़ टेंसर से कौन सी जानकारी निकालता है। "FULL_HEALTH" एक ऐसा मोड है जो प्रत्येक फ्लोटिंग-टाइप टेंसर के बारे में निम्नलिखित जानकारी कैप्चर करता है (उदाहरण के लिए, आमतौर पर देखा जाने वाला फ्लोट32 और कम आम bfloat16 dtype):
- डीटाइप
- पद
- तत्वों की कुल संख्या
- निम्नलिखित श्रेणियों में फ़्लोटिंग-प्रकार के तत्वों का टूटना: नकारात्मक परिमित (
-), शून्य (0), सकारात्मक परिमित (+), नकारात्मक अनंत (-∞), सकारात्मक अनंत (+∞), औरNaN।
"FULL_HEALTH" मोड NaN और अनंत से जुड़े बग को डीबग करने के लिए उपयुक्त है। अन्य समर्थित tensor_debug_mode के लिए नीचे देखें।
circular_buffer_size तर्क नियंत्रित करता है कि लॉगडिर में कितने टेंसर इवेंट सहेजे गए हैं। यह 1000 पर डिफॉल्ट करता है, जिसके कारण इंस्ट्रूमेंटेड TF2 प्रोग्राम के अंत से पहले केवल अंतिम 1000 टेंसर को डिस्क पर सहेजा जा सकता है। यह डिफ़ॉल्ट व्यवहार डिबग-डेटा पूर्णता का त्याग करके डिबगर ओवरहेड को कम करता है। यदि पूर्णता को प्राथमिकता दी जाती है, जैसा कि इस मामले में है, तो हम तर्क को नकारात्मक मान पर सेट करके सर्कुलर बफर को अक्षम कर सकते हैं (उदाहरण के लिए, यहां -1)।
Debug_mnist_v2 उदाहरण कमांड-लाइन फ़्लैग पास करके enable_dump_debug_info() आमंत्रित करता है। इस डिबगिंग उपकरण सक्षम होने के साथ हमारे समस्याग्रस्त TF2 प्रोग्राम को फिर से चलाने के लिए, यह करें:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
TensorBoard में डिबगर V2 GUI प्रारंभ करना
डिबगर इंस्ट्रूमेंटेशन के साथ प्रोग्राम चलाने से /tmp/tfdbg2_logdir पर एक लॉगडिर बनता है। हम TensorBoard शुरू कर सकते हैं और इसे लॉगडिर पर इंगित कर सकते हैं:
tensorboard --logdir /tmp/tfdbg2_logdir
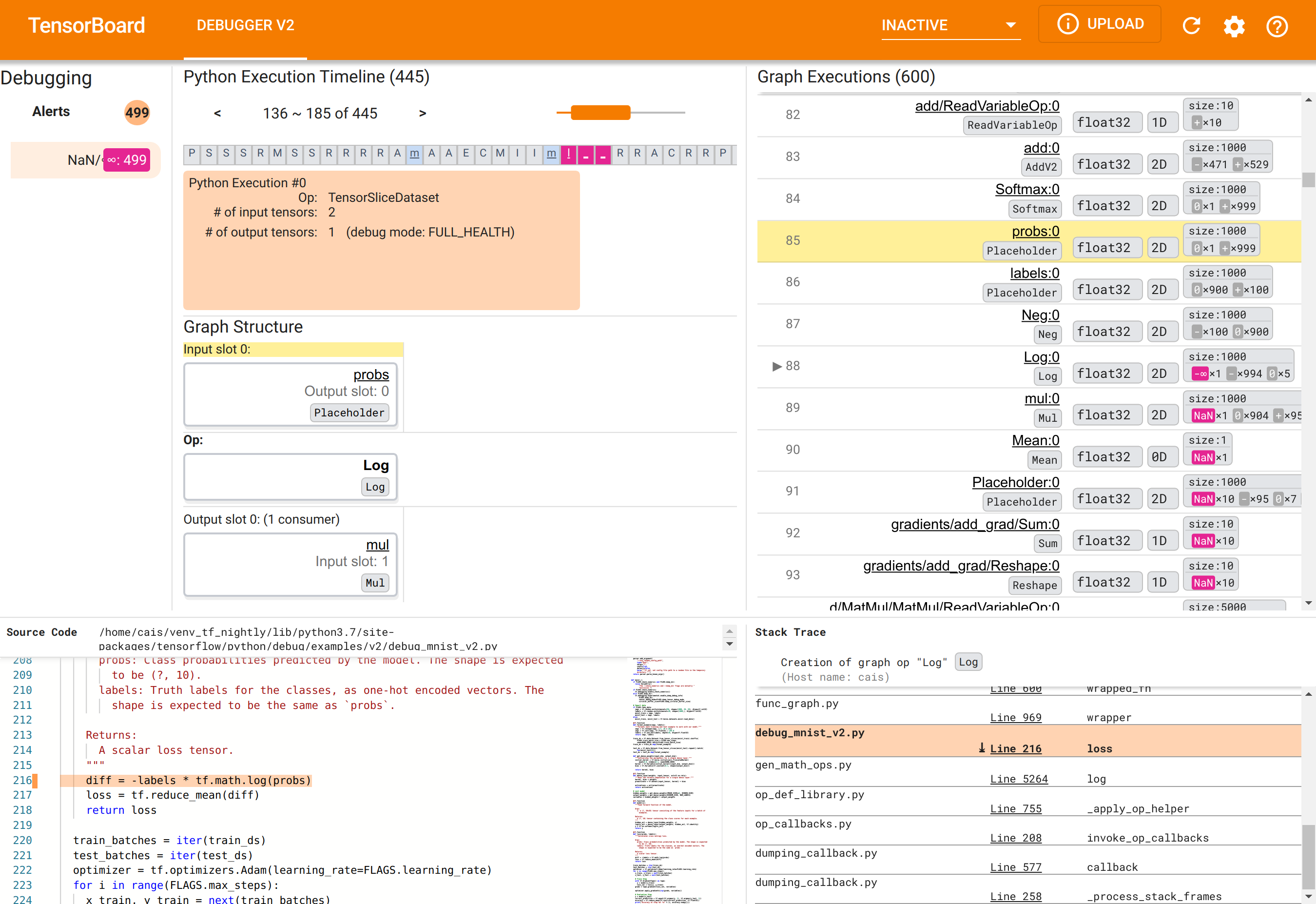
वेब ब्राउज़र में, http://localhost:6006 पर TensorBoard के पेज पर जाएँ। "डीबगर V2" प्लगइन डिफ़ॉल्ट रूप से निष्क्रिय होगा, इसलिए इसे शीर्ष दाईं ओर "निष्क्रिय प्लगइन्स" मेनू से चुनें। एक बार चयनित होने पर, इसे निम्नलिखित जैसा दिखना चाहिए:
NaNs का मूल कारण खोजने के लिए डिबगर V2 GUI का उपयोग करना
TensorBoard में डिबगर V2 GUI को छह खंडों में व्यवस्थित किया गया है:
- अलर्ट : इस शीर्ष-बाएँ अनुभाग में इंस्ट्रूमेंटेड टेन्सरफ्लो प्रोग्राम से डिबग डेटा में डिबगर द्वारा पता लगाए गए "अलर्ट" घटनाओं की एक सूची है। प्रत्येक चेतावनी एक निश्चित विसंगति को इंगित करती है जिस पर ध्यान देने की आवश्यकता है। हमारे मामले में, यह खंड प्रमुख गुलाबी-लाल रंग के साथ 499 NaN/∞ घटनाओं को उजागर करता है। यह हमारे संदेह की पुष्टि करता है कि मॉडल अपने आंतरिक टेंसर मानों में NaN और/या अनन्तताओं की उपस्थिति के कारण सीखने में विफल रहता है। हम शीघ्र ही इन चेतावनियों पर गहराई से विचार करेंगे।
- पायथन एक्ज़ीक्यूशन टाइमलाइन : यह शीर्ष-मध्य भाग का ऊपरी आधा भाग है। यह ऑप्स और ग्राफ़ के उत्सुकतापूर्वक निष्पादन का पूरा इतिहास प्रस्तुत करता है। टाइमलाइन के प्रत्येक बॉक्स को ऑप या ग्राफ़ के नाम के प्रारंभिक अक्षर द्वारा चिह्नित किया जाता है (उदाहरण के लिए, "TensorSliceDataset" op के लिए "T", "मॉडल"
tf.functionके लिए "m")। हम नेविगेशन बटन और टाइमलाइन के ऊपर स्क्रॉलबार का उपयोग करके इस टाइमलाइन को नेविगेट कर सकते हैं। - ग्राफ़ निष्पादन : जीयूआई के शीर्ष-दाएं कोने पर स्थित, यह अनुभाग हमारे डिबगिंग कार्य के लिए केंद्रीय होगा। इसमें ग्राफ़ के अंदर गणना किए गए सभी फ़्लोटिंग-डीटाइप टेंसर का इतिहास शामिल है (यानी,
@tf-functions द्वारा संकलित)। - ग्राफ़ संरचना (शीर्ष-मध्य अनुभाग का निचला भाग), स्रोत कोड (निचला-बाएँ अनुभाग), और स्टैक ट्रेस (निचला-दायाँ अनुभाग) प्रारंभ में खाली हैं। जब हम GUI के साथ इंटरैक्ट करेंगे तो उनकी सामग्री पॉप्युलेट हो जाएगी। ये तीन अनुभाग हमारे डिबगिंग कार्य में भी महत्वपूर्ण भूमिका निभाएंगे।
यूआई के संगठन के लिए खुद को उन्मुख करने के बाद, आइए NaN क्यों दिखाई दिए इसकी तह तक जाने के लिए निम्नलिखित कदम उठाएं। सबसे पहले, अलर्ट अनुभाग में NaN/∞ अलर्ट पर क्लिक करें। यह स्वचालित रूप से ग्राफ़ निष्पादन अनुभाग में 600 ग्राफ़ टेंसरों की सूची को स्क्रॉल करता है और #88 पर ध्यान केंद्रित करता है, जो Log (प्राकृतिक लघुगणक) ऑप द्वारा उत्पन्न Log:0 नामक एक टेंसर है। एक प्रमुख गुलाबी-लाल रंग 2डी फ्लोट32 टेंसर के 1000 तत्वों में से एक -∞ तत्व को उजागर करता है। यह TF2 प्रोग्राम के रनटाइम इतिहास में पहला टेंसर है जिसमें कोई NaN या अनंत शामिल है: इससे पहले गणना किए गए टेंसर में NaN या ∞ शामिल नहीं है; बाद में गणना किए गए कई (वास्तव में, अधिकांश) टेंसरों में NaN होते हैं। हम ग्राफ़ निष्पादन सूची को ऊपर और नीचे स्क्रॉल करके इसकी पुष्टि कर सकते हैं। यह अवलोकन एक मजबूत संकेत प्रदान करता है कि Log ऑप इस TF2 प्रोग्राम में संख्यात्मक अस्थिरता का स्रोत है।
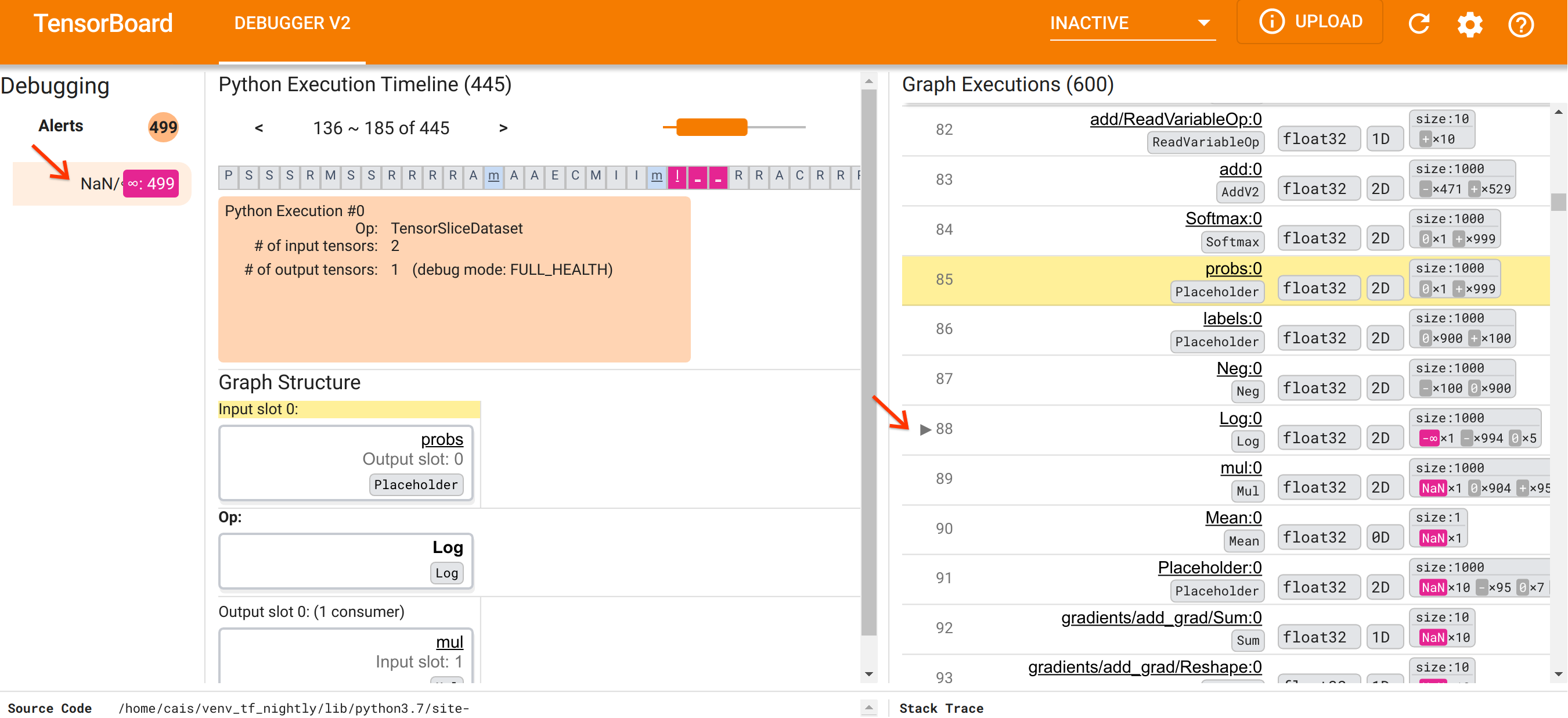
यह Log ऑप -∞ क्यों उगलता है? उस प्रश्न का उत्तर देने के लिए ऑप में इनपुट की जांच करना आवश्यक है। टेंसर के नाम ( Log:0 ) पर क्लिक करने से ग्राफ़ संरचना अनुभाग में इसके टेंसरफ्लो ग्राफ़ में Log ऑप के आसपास का एक सरल लेकिन सूचनात्मक दृश्य सामने आता है। सूचना प्रवाह की ऊपर से नीचे की दिशा पर ध्यान दें। ऑप को बीच में बोल्ड में दिखाया गया है। इसके ठीक ऊपर, हम देख सकते हैं कि प्लेसहोल्डर ऑप Log ऑप को एकमात्र इनपुट प्रदान करता है। ग्राफ़ निष्पादन सूची में इस probs प्लेसहोल्डर द्वारा उत्पन्न टेंसर कहाँ है? दृश्य सहायता के रूप में पीले पृष्ठभूमि रंग का उपयोग करके, हम देख सकते हैं कि probs:0 टेंसर Log:0 टेंसर से तीन पंक्तियाँ ऊपर है, यानी पंक्ति 85 में।
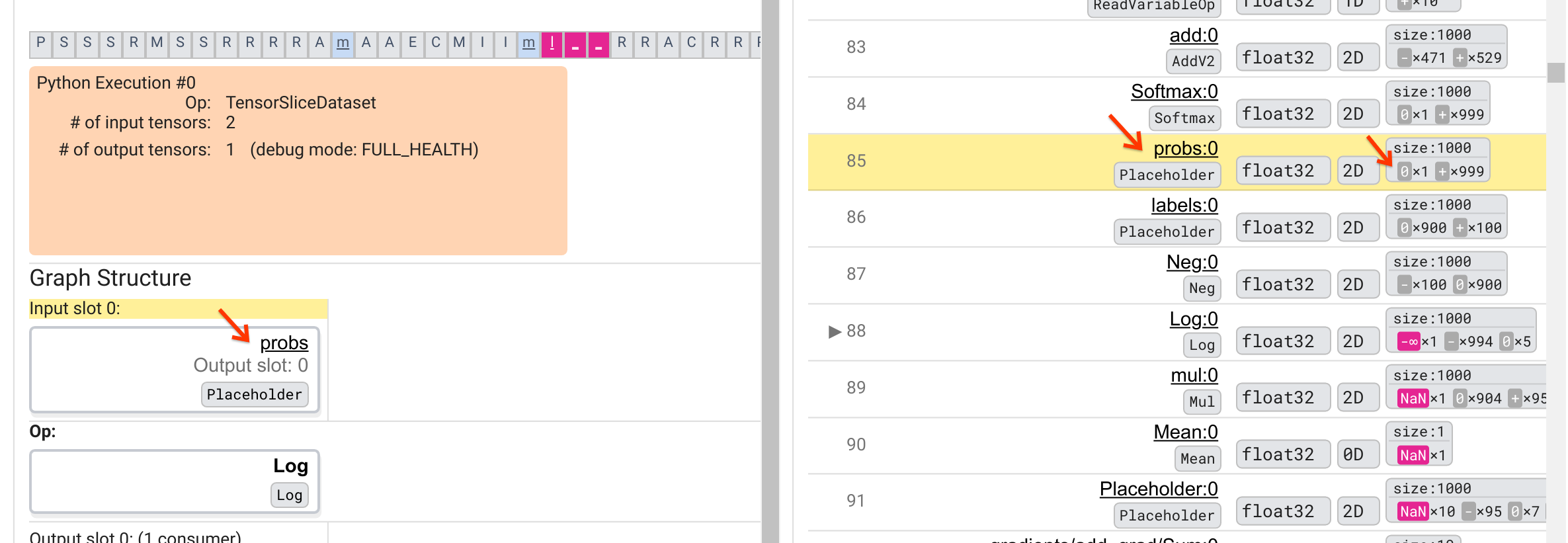
पंक्ति 85 में probs:0 टेंसर के संख्यात्मक विश्लेषण पर अधिक ध्यान से देखने से पता चलता है कि इसका उपभोक्ता Log:0 एक -∞ क्यों उत्पन्न करता है: probs:0 के 1000 तत्वों में से, एक तत्व का मान 0 है। -∞ है 0 के प्राकृतिक लघुगणक की गणना का परिणाम! यदि हम किसी तरह यह सुनिश्चित कर सकें कि Log ऑप केवल सकारात्मक इनपुट के संपर्क में आए, तो हम NaN/∞ को होने से रोक पाएंगे। इसे प्लेसहोल्डर probs टेंसर पर क्लिपिंग लागू करके (उदाहरण के लिए, tf.clip_by_value() का उपयोग करके) प्राप्त किया जा सकता है।
हम बग को सुलझाने के करीब पहुंच रहे हैं, लेकिन अभी तक पूरा नहीं हुआ है। सुधार को लागू करने के लिए, हमें यह जानना होगा कि पायथन स्रोत कोड में Log ऑप और उसके प्लेसहोल्डर इनपुट की उत्पत्ति कहां से हुई। डिबगर V2 ग्राफ़ ऑप्स और निष्पादन घटनाओं को उनके स्रोत पर ट्रेस करने के लिए प्रथम श्रेणी का समर्थन प्रदान करता है। जब हमने ग्राफ़ निष्पादन में Log:0 टेंसर पर क्लिक किया, तो स्टैक ट्रेस अनुभाग Log ऑप के निर्माण के मूल स्टैक ट्रेस से भर गया था। स्टैक ट्रेस कुछ हद तक बड़ा है क्योंकि इसमें TensorFlow के आंतरिक कोड (उदाहरण के लिए, gen_math_ops.py और Dumping_callback.py) से कई फ़्रेम शामिल हैं, जिन्हें हम अधिकांश डिबगिंग कार्यों के लिए सुरक्षित रूप से अनदेखा कर सकते हैं। रुचि का फ्रेम debug_mnist_v2.py की पंक्ति 216 है (यानी, पायथन फ़ाइल जिसे हम वास्तव में डीबग करने का प्रयास कर रहे हैं)। "लाइन 216" पर क्लिक करने से सोर्स कोड अनुभाग में कोड की संबंधित लाइन का दृश्य सामने आता है।
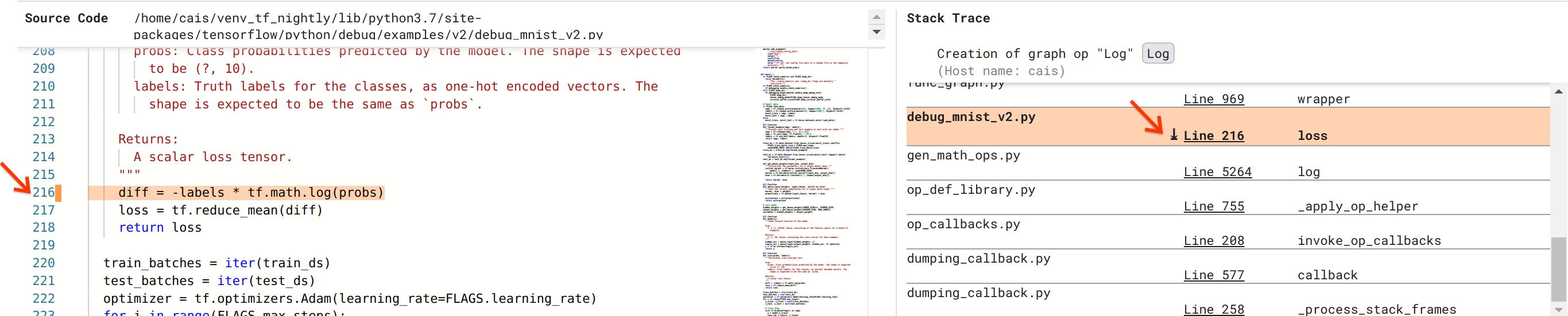
यह अंततः हमें उस स्रोत कोड पर लाता है जिसने इसके probs इनपुट से समस्याग्रस्त Log ऑप बनाया है। यह हमारा कस्टम श्रेणीबद्ध क्रॉस-एन्ट्रॉपी लॉस फ़ंक्शन है जिसे @tf.function से सजाया गया है और इसलिए इसे TensorFlow ग्राफ़ में परिवर्तित किया गया है। प्लेसहोल्डर ऑप probs हानि फ़ंक्शन के पहले इनपुट तर्क से मेल खाता है। Log ऑप tf.math.log() API कॉल के साथ बनाया गया है।
इस बग का वैल्यू-क्लिपिंग फिक्स कुछ इस तरह दिखेगा:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
यह इस TF2 प्रोग्राम में संख्यात्मक अस्थिरता को हल करेगा और MLP को सफलतापूर्वक प्रशिक्षित करने का कारण बनेगा। संख्यात्मक अस्थिरता को ठीक करने का एक अन्य संभावित तरीका tf.keras.losses.CategoricalCrossentropy का उपयोग करना है।
यह TF2 मॉडल बग को देखने से लेकर बग को ठीक करने वाले कोड परिवर्तन के साथ आने तक की हमारी यात्रा का समापन करता है, जो कि डिबगर V2 टूल की सहायता से होता है, जो संख्यात्मक सारांश सहित इंस्ट्रूमेंटेड TF2 प्रोग्राम के उत्सुक और ग्राफ़ निष्पादन इतिहास में पूर्ण दृश्यता प्रदान करता है। टेन्सर मूल्यों और ऑप्स, टेन्सर और उनके मूल स्रोत कोड के बीच संबंध।
डिबगर V2 की हार्डवेयर अनुकूलता
डिबगर V2 सीपीयू और जीपीयू सहित मुख्यधारा प्रशिक्षण हार्डवेयर का समर्थन करता है। tf.distributed.MirroredStrategy के साथ मल्टी-जीपीयू प्रशिक्षण भी समर्थित है। टीपीयू के लिए समर्थन अभी भी प्रारंभिक चरण में है और इसके लिए कॉलिंग की आवश्यकता है
tf.config.set_soft_device_placement(True)
enable_dump_debug_info() कॉल करने से पहले। टीपीयू पर इसकी अन्य सीमाएँ भी हो सकती हैं। यदि आपको डिबगर V2 का उपयोग करने में समस्या आती है, तो कृपया हमारे GitHub समस्या पृष्ठ पर बग की रिपोर्ट करें।
डिबगर V2 की एपीआई संगतता
डिबगर V2 को TensorFlow के सॉफ़्टवेयर स्टैक के अपेक्षाकृत निम्न स्तर पर लागू किया गया है, और इसलिए यह tf.keras , tf.data और TensorFlow के निचले स्तरों के शीर्ष पर निर्मित अन्य API के साथ संगत है। डिबगर V2 भी TF1 के साथ बैकवर्ड संगत है, हालाँकि TF1 प्रोग्राम द्वारा उत्पन्न डिबग लॉगडिर के लिए उत्सुक निष्पादन समयरेखा खाली होगी।
एपीआई उपयोग युक्तियाँ
इस डिबगिंग एपीआई के बारे में अक्सर पूछा जाने वाला प्रश्न यह है कि TensorFlow कोड में किसी को enable_dump_debug_info() पर कॉल कहाँ सम्मिलित करनी चाहिए। आमतौर पर, एपीआई को आपके TF2 प्रोग्राम में जितनी जल्दी हो सके कॉल किया जाना चाहिए, अधिमानतः पायथन आयात लाइनों के बाद और ग्राफ निर्माण और निष्पादन शुरू होने से पहले। यह आपके मॉडल और उसके प्रशिक्षण को शक्ति प्रदान करने वाले सभी ऑप्स और ग्राफ़ की पूर्ण कवरेज सुनिश्चित करेगा।
वर्तमान में समर्थित Tensor_debug_modes हैं: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH , और SHAPE । वे प्रत्येक टेंसर से निकाली गई जानकारी की मात्रा और डिबग किए गए प्रोग्राम के ओवरहेड प्रदर्शन में भिन्न होते हैं। कृपया enable_dump_debug_info() के दस्तावेज़ के args अनुभाग को देखें।
प्रदर्शन ओवरहेड
डिबगिंग एपीआई इंस्ट्रूमेंटेड टेन्सरफ्लो प्रोग्राम में प्रदर्शन ओवरहेड का परिचय देता है। ओवरहेड tensor_debug_mode , हार्डवेयर प्रकार और इंस्ट्रूमेंटेड TensorFlow प्रोग्राम की प्रकृति के अनुसार भिन्न होता है। एक संदर्भ बिंदु के रूप में, GPU पर, NO_TENSOR मोड बैच आकार 64 के तहत एक ट्रांसफार्मर मॉडल के प्रशिक्षण के दौरान 15% ओवरहेड जोड़ता है। अन्य Tensor_debug_modes के लिए प्रतिशत ओवरहेड अधिक है: CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH और SHAPE के लिए लगभग 50% मोड. सीपीयू पर, ओवरहेड थोड़ा कम है। टीपीयू पर, ओवरहेड वर्तमान में अधिक है।
अन्य TensorFlow डिबगिंग API से संबंध
ध्यान दें कि TensorFlow डिबगिंग के लिए अन्य टूल और API प्रदान करता है। आप एपीआई डॉक्स पेज पर tf.debugging.* नेमस्पेस के तहत ऐसे एपीआई ब्राउज़ कर सकते हैं। इन एपीआई में सबसे अधिक इस्तेमाल किया जाने वाला tf.print() है। किसी को डिबगर V2 का उपयोग कब करना चाहिए और इसके बजाय tf.print() उपयोग कब करना चाहिए? ऐसे मामले में tf.print() सुविधाजनक है
- हम ठीक-ठीक जानते हैं कि कौन सा टेंसर प्रिंट करना है,
- हम जानते हैं कि स्रोत कोड में वास्तव में उन
tf.print()कथनों को कहाँ सम्मिलित करना है, - ऐसे टेंसरों की संख्या बहुत बड़ी नहीं है।
अन्य मामलों के लिए (उदाहरण के लिए, कई टेंसर मानों की जांच करना, टेंसरफ्लो के आंतरिक कोड द्वारा उत्पन्न टेंसर मूल्यों की जांच करना, और संख्यात्मक अस्थिरता की उत्पत्ति की खोज करना, जैसा कि हमने ऊपर दिखाया है), डीबगर V2 डिबगिंग का एक तेज़ तरीका प्रदान करता है। इसके अलावा, डिबगर V2 उत्सुक और ग्राफ़ टेंसरों के निरीक्षण के लिए एक एकीकृत दृष्टिकोण प्रदान करता है। यह अतिरिक्त रूप से ग्राफ़ संरचना और कोड स्थानों के बारे में जानकारी प्रदान करता है, जो tf.print() की क्षमता से परे हैं।
एक अन्य एपीआई जिसका उपयोग ∞ और NaN से जुड़े मुद्दों को डीबग करने के लिए किया जा सकता है वह है tf.debugging.enable_check_numerics() । enable_dump_debug_info() के विपरीत, enable_check_numerics() डिस्क पर डिबग जानकारी सहेजता नहीं है। इसके बजाय, यह केवल TensorFlow रनटाइम के दौरान ∞ और NaN की निगरानी करता है और जैसे ही कोई ऑप ऐसे खराब संख्यात्मक मान उत्पन्न करता है, तो मूल कोड स्थान में त्रुटियां हो जाती हैं। enable_dump_debug_info() की तुलना में इसका प्रदर्शन ओवरहेड कम है, लेकिन यह प्रोग्राम के निष्पादन इतिहास का पूरा पता लगाने में सक्षम नहीं है और डीबगर V2 जैसे ग्राफिकल यूजर इंटरफेस के साथ नहीं आता है।