
Peristiwa bencana yang melibatkan NaN terkadang dapat terjadi selama program TensorFlow sehingga melumpuhkan proses pelatihan model. Akar penyebab kejadian seperti ini seringkali tidak jelas, terutama untuk model dengan ukuran dan kompleksitas yang tidak sepele. Untuk mempermudah men-debug bug model jenis ini, TensorBoard 2.3+ (bersama dengan TensorFlow 2.3+) menyediakan dasbor khusus yang disebut Debugger V2. Di sini kami mendemonstrasikan cara menggunakan alat ini dengan mengatasi bug nyata yang melibatkan NaN di jaringan neural yang ditulis di TensorFlow.
Teknik yang diilustrasikan dalam tutorial ini dapat diterapkan pada jenis aktivitas debugging lainnya seperti memeriksa bentuk tensor waktu proses dalam program yang kompleks. Tutorial ini berfokus pada NaN karena frekuensi kemunculannya yang relatif tinggi.
Mengamati bug
Kode sumber program TF2 yang akan kami debug tersedia di GitHub . Contoh program juga dikemas ke dalam paket tensorflow pip (versi 2.3+) dan dapat dipanggil dengan:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Program TF2 ini menciptakan persepsi multi-layer (MLP) dan melatihnya untuk mengenali gambar MNIST . Contoh ini sengaja menggunakan API tingkat rendah TF2 untuk mendefinisikan konstruksi lapisan khusus, fungsi kerugian, dan loop pelatihan, karena kemungkinan bug NaN lebih tinggi ketika kita menggunakan API yang lebih fleksibel namun lebih rawan kesalahan ini dibandingkan ketika kita menggunakan API yang lebih mudah. -untuk digunakan tetapi API tingkat tinggi yang sedikit kurang fleksibel seperti tf.keras .
Program ini mencetak akurasi tes setelah setiap langkah pelatihan. Kita dapat melihat di konsol bahwa akurasi pengujian terhenti pada tingkat peluang yang hampir sama (~0,1) setelah langkah pertama. Hal ini tentu saja bukan perilaku yang diharapkan dari pelatihan model: kami memperkirakan akurasi akan secara bertahap mendekati 1,0 (100%) seiring dengan meningkatnya langkah.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Dugaan yang masuk akal adalah bahwa masalah ini disebabkan oleh ketidakstabilan numerik, seperti NaN atau tak terhingga. Namun, bagaimana kami memastikan bahwa hal ini benar-benar terjadi dan bagaimana kami menemukan operasi TensorFlow (op) yang bertanggung jawab menyebabkan ketidakstabilan numerik? Untuk menjawab pertanyaan ini, mari lengkapi program buggy dengan Debugger V2.
Menginstrumentasikan kode TensorFlow dengan Debugger V2
tf.debugging.experimental.enable_dump_debug_info() adalah titik masuk API Debugger V2. Ini melengkapi program TF2 dengan satu baris kode. Misalnya, menambahkan baris berikut di dekat awal program akan menyebabkan informasi debug ditulis ke direktori log (logdir) di /tmp/tfdbg2_logdir. Informasi debug mencakup berbagai aspek runtime TensorFlow. Di TF2, ini mencakup riwayat lengkap eksekusi yang bersemangat, pembuatan grafik yang dilakukan oleh @tf.function , eksekusi grafik, nilai tensor yang dihasilkan oleh peristiwa eksekusi, serta lokasi kode (jejak tumpukan Python) dari peristiwa tersebut . Kekayaan informasi debug memungkinkan pengguna mempersempit bug yang tidak jelas.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
Argumen tensor_debug_mode mengontrol informasi apa yang diekstraksi Debugger V2 dari setiap tensor yang bersemangat atau dalam grafik. “FULL_HEALTH” adalah mode yang menangkap informasi berikut tentang setiap tensor tipe mengambang (misalnya, tipe float32 yang umum terlihat dan tipe d bfloat16 yang kurang umum):
- Tipe D
- Pangkat
- Jumlah total elemen
- Perincian elemen tipe mengambang ke dalam kategori berikut: berhingga negatif (
-), nol (0), berhingga positif (+), tak terhingga negatif (-∞), tak terhingga positif (+∞), danNaN.
Mode “FULL_HEALTH” cocok untuk men-debug bug yang melibatkan NaN dan infinity. Lihat di bawah untuk tensor_debug_mode lain yang didukung.
Argumen circular_buffer_size mengontrol berapa banyak peristiwa tensor yang disimpan ke logdir. Defaultnya adalah 1000, yang menyebabkan hanya 1000 tensor terakhir sebelum akhir program TF2 yang diinstrumentasi disimpan ke disk. Perilaku default ini mengurangi overhead debugger dengan mengorbankan kelengkapan data debug. Jika kelengkapan lebih disukai, seperti dalam kasus ini, kita dapat menonaktifkan buffer melingkar dengan menetapkan argumen ke nilai negatif (misalnya, -1 di sini).
Contoh debug_mnist_v2 memanggil enable_dump_debug_info() dengan meneruskan tanda baris perintah ke sana. Untuk menjalankan kembali program TF2 kami yang bermasalah dengan instrumentasi debugging ini diaktifkan, lakukan:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Memulai GUI Debugger V2 di TensorBoard
Menjalankan program dengan instrumentasi debugger akan membuat logdir di /tmp/tfdbg2_logdir. Kita dapat memulai TensorBoard dan mengarahkannya ke logdir dengan:
tensorboard --logdir /tmp/tfdbg2_logdir
Di browser web, navigasikan ke halaman TensorBoard di http://localhost:6006. Plugin “Debugger V2” tidak aktif secara default, jadi pilih plugin tersebut dari menu “Plugin tidak aktif” di kanan atas. Setelah dipilih, tampilannya akan seperti berikut:
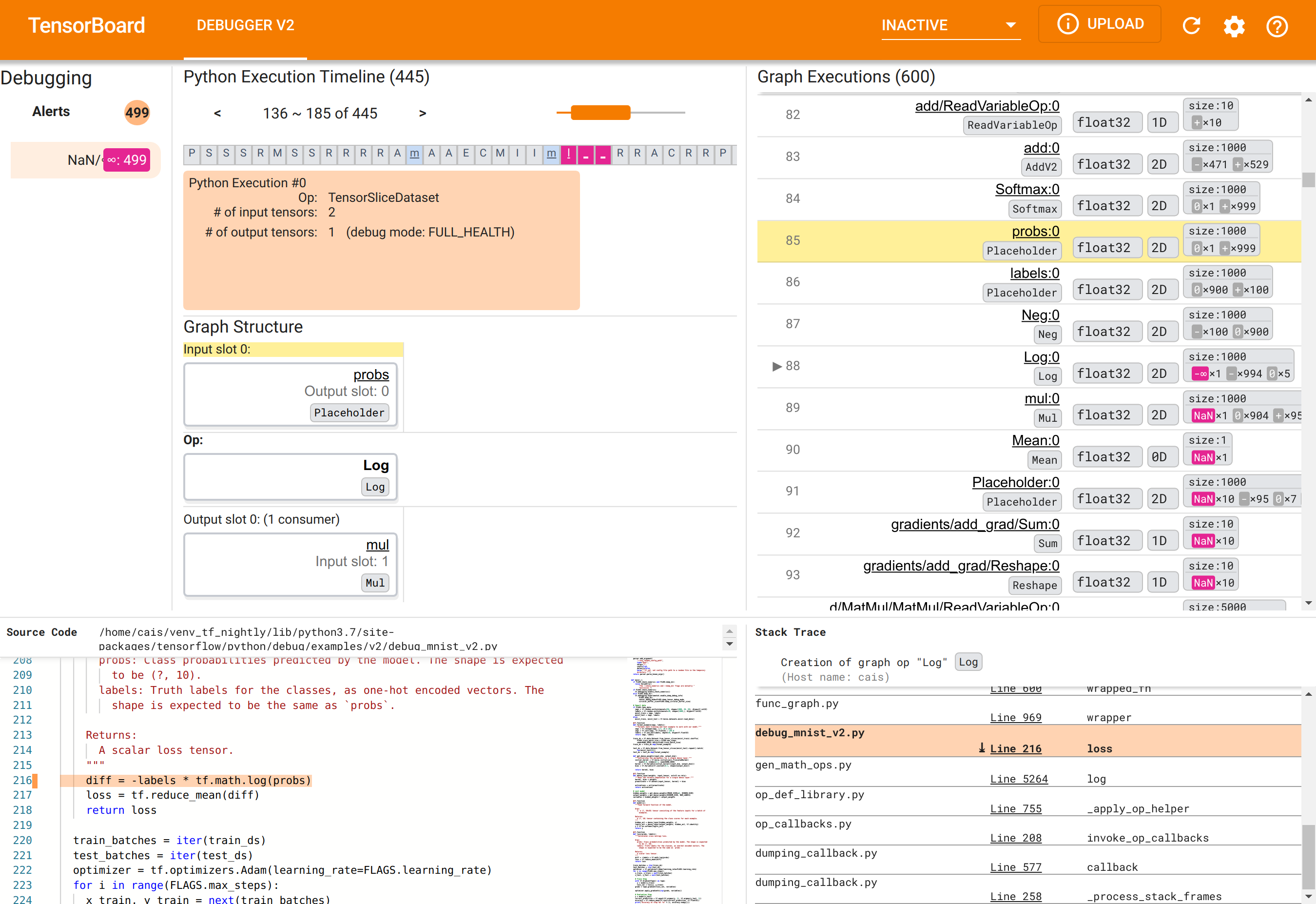
Menggunakan GUI Debugger V2 untuk menemukan akar penyebab NaNs
GUI Debugger V2 di TensorBoard disusun menjadi enam bagian:
- Peringatan : Bagian kiri atas ini berisi daftar peristiwa “peringatan” yang terdeteksi oleh debugger dalam data debug dari program TensorFlow yang diinstrumentasi. Setiap peringatan menunjukkan anomali tertentu yang memerlukan perhatian. Dalam kasus kami, bagian ini menyoroti 499 NaN/∞ peristiwa dengan warna merah jambu-merah yang menonjol. Hal ini menegaskan kecurigaan kami bahwa model gagal belajar karena adanya NaN dan/atau ketidakterbatasan dalam nilai tensor internalnya. Kami akan segera menyelidiki peringatan ini.
- Garis Waktu Eksekusi Python : Ini adalah bagian atas dari bagian menengah atas. Ini menyajikan sejarah lengkap eksekusi operasi dan grafik yang penuh semangat. Setiap kotak garis waktu ditandai dengan huruf awal operasi atau nama grafik (misalnya, “T” untuk operasi “TensorSliceDataset”, “m” untuk “model”
tf.function). Kita dapat menavigasi timeline ini dengan menggunakan tombol navigasi dan scrollbar di atas timeline. - Eksekusi Grafik : Terletak di sudut kanan atas GUI, bagian ini akan menjadi pusat tugas debugging kita. Ini berisi riwayat semua tensor tipe d mengambang yang dihitung di dalam grafik (yaitu, dikompilasi oleh
@tf-functions). - Struktur Grafik (bagian bawah bagian tengah atas), Kode Sumber (bagian kiri bawah), dan Stack Trace (bagian kanan bawah) awalnya kosong. Kontennya akan terisi saat kita berinteraksi dengan GUI. Ketiga bagian ini juga akan memainkan peran penting dalam tugas debugging kita.
Setelah berorientasi pada organisasi UI, mari kita lakukan langkah-langkah berikut untuk memahami alasan munculnya NaN. Pertama, klik peringatan NaN/∞ di bagian Peringatan. Ini secara otomatis menggulir daftar 600 tensor grafik di bagian Eksekusi Grafik dan berfokus pada #88, yang merupakan tensor bernama Log:0 yang dihasilkan oleh operasi Log (logaritma natural). Warna merah jambu-merah menonjol menyoroti elemen -∞ di antara 1000 elemen tensor float32 2D. Ini adalah tensor pertama dalam riwayat runtime program TF2 yang berisi NaN atau tak terhingga: tensor yang dihitung sebelumnya tidak berisi NaN atau ∞; banyak (pada kenyataannya, sebagian besar) tensor yang dihitung setelahnya mengandung NaN. Kami dapat mengonfirmasi hal ini dengan menggulir ke atas dan ke bawah daftar Eksekusi Grafik. Pengamatan ini memberikan petunjuk kuat bahwa operasi Log adalah sumber ketidakstabilan numerik dalam program TF2 ini.
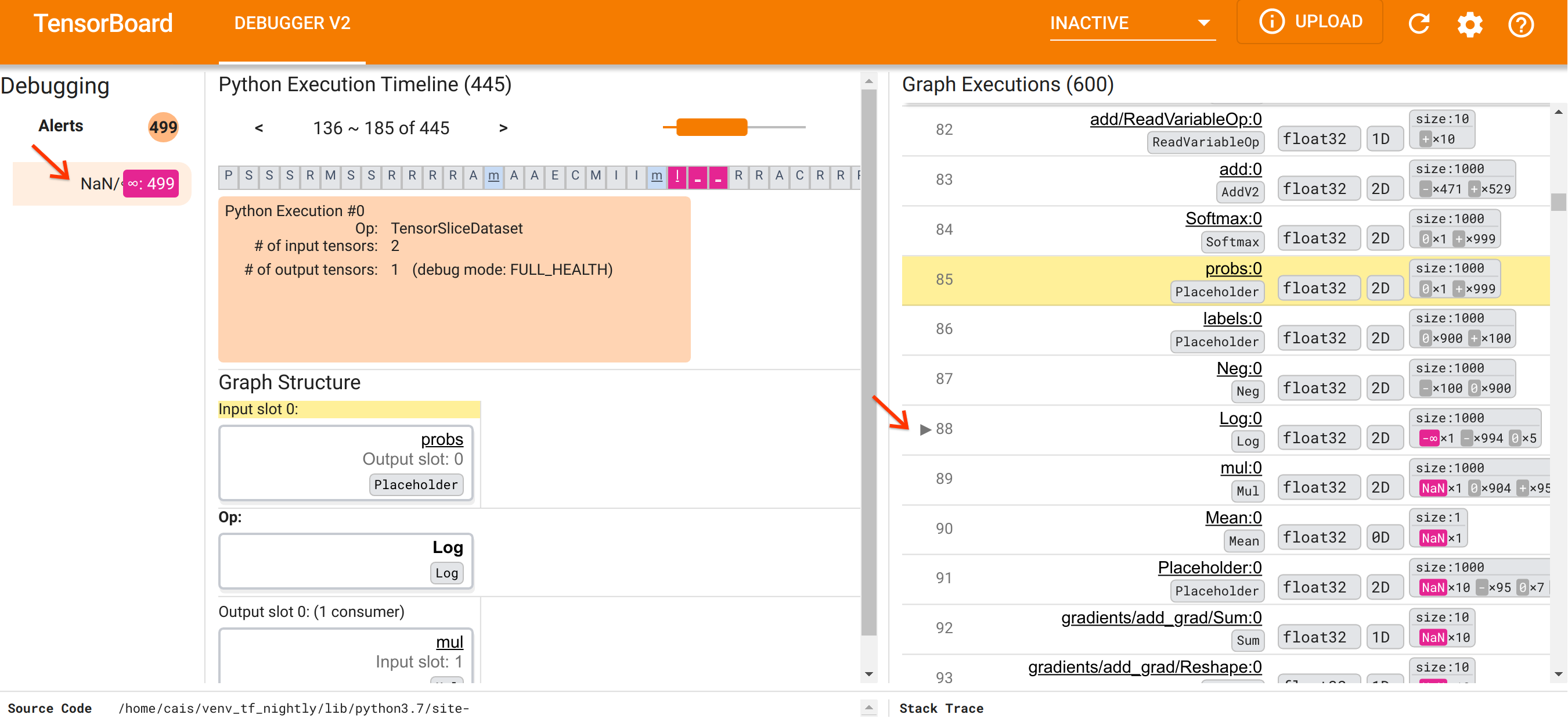
Mengapa operasi Log ini mengeluarkan -∞? Menjawab pertanyaan itu memerlukan pemeriksaan masukan ke operasi. Mengklik nama tensor ( Log:0 ) akan menampilkan visualisasi sederhana namun informatif dari sekitar operasi Log dalam grafik TensorFlow di bagian Struktur Grafik. Perhatikan arah arus informasi dari atas ke bawah. Operasinya sendiri ditampilkan dalam huruf tebal di tengah. Tepat di atasnya, kita dapat melihat operasi Placeholder yang menyediakan satu-satunya masukan ke operasi Log . Di manakah tensor yang dihasilkan oleh Placeholder probs ini dalam daftar Eksekusi Grafik? Dengan menggunakan warna background kuning sebagai alat bantu visual, kita dapat melihat bahwa tensor probs:0 berada tiga baris di atas tensor Log:0 yaitu pada baris 85.
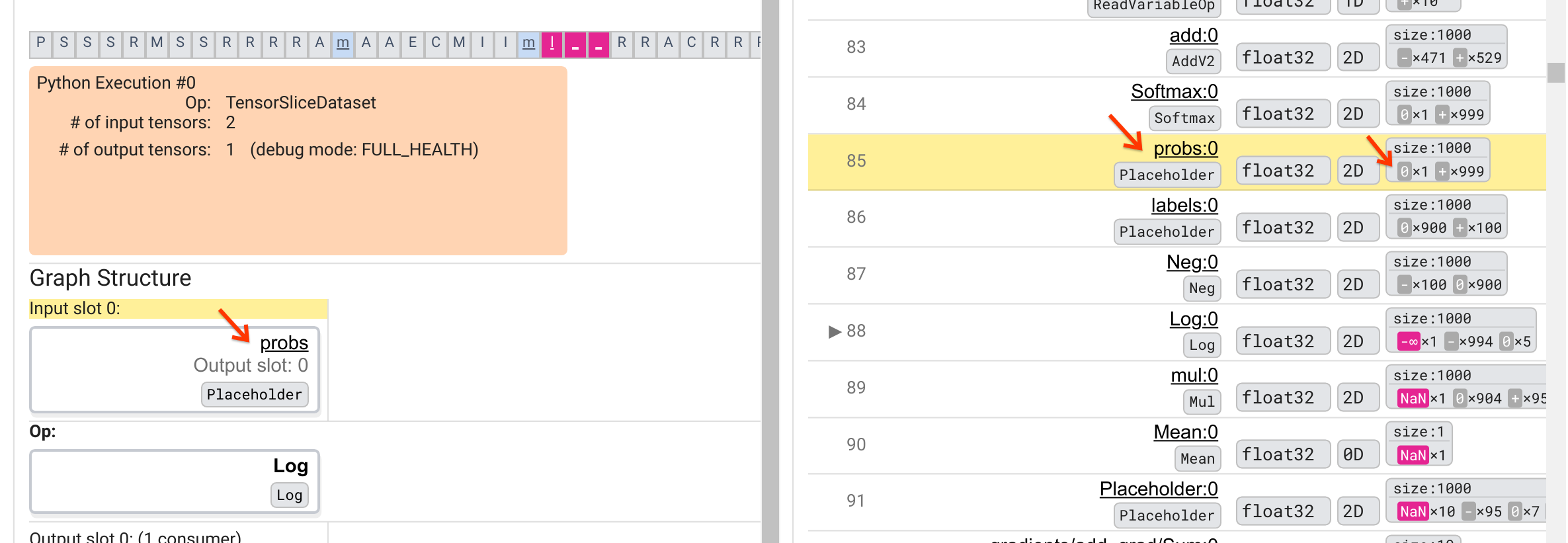
Melihat lebih dekat pada perincian numerik dari tensor probs:0 di baris 85 mengungkapkan mengapa konsumennya Log:0 menghasilkan -∞: Di antara 1000 elemen probs:0 , satu elemen memiliki nilai 0. -∞ adalah hasil perhitungan logaritma natural 0! Jika kita dapat memastikan bahwa operasi Log hanya terkena input positif, kita akan dapat mencegah terjadinya NaN/∞. Hal ini dapat dicapai dengan menerapkan kliping (misalnya, dengan menggunakan tf.clip_by_value() ) pada tensor probs Placeholder.
Kami semakin dekat untuk memecahkan bug tersebut, namun belum sepenuhnya selesai. Untuk menerapkan perbaikan, kita perlu mengetahui dari mana dalam kode sumber Python operasi Log dan input Placeholdernya berasal. Debugger V2 memberikan dukungan kelas satu untuk menelusuri operasi grafik dan peristiwa eksekusi ke sumbernya. Saat kami mengklik tensor Log:0 di Graph Executions, bagian Stack Trace diisi dengan pelacakan tumpukan asli dari pembuatan operasi Log . Pelacakan tumpukan agak besar karena mencakup banyak bingkai dari kode internal TensorFlow (misalnya, gen_math_ops.py dan dumping_callback.py), yang dapat kita abaikan dengan aman untuk sebagian besar tugas proses debug. Kerangka yang menarik adalah Baris 216 dari debug_mnist_v2.py (yaitu, file Python yang sebenarnya kami coba debug). Mengklik “Baris 216” menampilkan tampilan baris kode yang sesuai di bagian Kode Sumber.
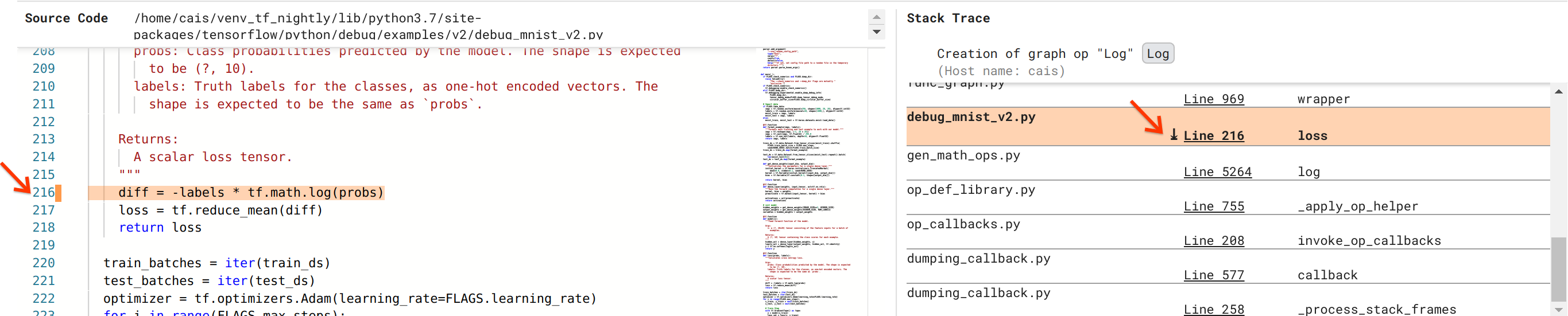
Ini akhirnya membawa kita ke kode sumber yang membuat operasi Log bermasalah dari masukan probs . Ini adalah fungsi kerugian lintas entropi kategoris khusus kami yang dihiasi dengan @tf.function dan karenanya diubah menjadi grafik TensorFlow. probs operasi Placeholder sesuai dengan argumen masukan pertama ke fungsi kerugian. Operasi Log dibuat dengan panggilan API tf.math.log().
Perbaikan pemotongan nilai pada bug ini akan terlihat seperti:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Ini akan mengatasi ketidakstabilan numerik dalam program TF2 ini dan menyebabkan MLP berhasil berlatih. Pendekatan lain yang mungkin untuk memperbaiki ketidakstabilan numerik adalah dengan menggunakan tf.keras.losses.CategoricalCrossentropy .
Ini mengakhiri perjalanan kita dari mengamati bug model TF2 hingga menghasilkan perubahan kode yang memperbaiki bug tersebut, dibantu oleh alat Debugger V2, yang memberikan visibilitas penuh ke dalam riwayat eksekusi yang bersemangat dan grafik dari program TF2 yang diinstrumentasi, termasuk ringkasan numeriknya. nilai tensor dan hubungan antara operasi, tensor, dan kode sumber aslinya.
Kompatibilitas perangkat keras Debugger V2
Debugger V2 mendukung perangkat keras pelatihan utama termasuk CPU dan GPU. Pelatihan multi-GPU dengan tf.distributed.MirroredStrategy juga didukung. Dukungan untuk TPU masih dalam tahap awal dan memerlukan panggilan telepon
tf.config.set_soft_device_placement(True)
sebelum menelepon enable_dump_debug_info() . Mungkin ada batasan lain pada TPU juga. Jika Anda mengalami masalah saat menggunakan Debugger V2, harap laporkan bug di halaman masalah GitHub kami.
Kompatibilitas API Debugger V2
Debugger V2 diimplementasikan pada tumpukan perangkat lunak TensorFlow tingkat yang relatif rendah, dan karenanya kompatibel dengan tf.keras , tf.data , dan API lain yang dibangun di atas tingkat TensorFlow yang lebih rendah. Debugger V2 juga kompatibel dengan TF1, meskipun Timeline Eksekusi Eager akan kosong untuk logdir debug yang dihasilkan oleh program TF1.
Kiat penggunaan API
Pertanyaan yang sering diajukan tentang API debugging ini adalah di mana dalam kode TensorFlow seseorang harus memasukkan panggilan ke enable_dump_debug_info() . Biasanya, API harus dipanggil sedini mungkin dalam program TF2 Anda, sebaiknya setelah baris impor Python dan sebelum pembuatan dan eksekusi grafik dimulai. Hal ini akan memastikan cakupan penuh dari semua operasi dan grafik yang mendukung model Anda dan pelatihannya.
Tensor_debug_modes yang didukung saat ini adalah: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH , dan SHAPE . Mereka bervariasi dalam jumlah informasi yang diekstraksi dari setiap tensor dan overhead kinerja untuk program yang di-debug. Silakan lihat bagian args pada dokumentasi enable_dump_debug_info() .
Overhead kinerja
API debugging menyebabkan overhead performa pada program TensorFlow yang diinstrumentasi. Biaya overhead bervariasi berdasarkan tensor_debug_mode , jenis perangkat keras, dan sifat program TensorFlow yang diinstrumentasi. Sebagai titik referensi, pada GPU, mode NO_TENSOR menambahkan 15% overhead selama pelatihan model Transformer dengan ukuran batch 64. Persen overhead untuk tensor_debug_mode lainnya lebih tinggi: sekitar 50% untuk CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH dan SHAPE mode. Pada CPU, overhead-nya sedikit lebih rendah. Di TPU, biaya overhead saat ini lebih tinggi.
Kaitannya dengan API debugging TensorFlow lainnya
Perhatikan bahwa TensorFlow menawarkan alat dan API lain untuk proses debug. Anda dapat menelusuri API tersebut di bawah tf.debugging.* di halaman dokumen API. Di antara API tersebut yang paling sering digunakan adalah tf.print() . Kapan sebaiknya seseorang menggunakan Debugger V2 dan kapan tf.print() sebaiknya digunakan? tf.print() berguna jika terjadi
- kita tahu persis tensor mana yang harus dicetak,
- kita tahu di mana tepatnya di kode sumber untuk memasukkan pernyataan
tf.print()tersebut, - jumlah tensor tersebut tidak terlalu banyak.
Untuk kasus lain (misalnya, memeriksa banyak nilai tensor, memeriksa nilai tensor yang dihasilkan oleh kode internal TensorFlow, dan mencari asal mula ketidakstabilan numerik seperti yang kami tunjukkan di atas), Debugger V2 menyediakan cara debugging yang lebih cepat. Selain itu, Debugger V2 memberikan pendekatan terpadu untuk memeriksa tensor bersemangat dan grafik. Ini juga memberikan informasi tentang struktur grafik dan lokasi kode, yang berada di luar kemampuan tf.print() .
API lain yang dapat digunakan untuk men-debug masalah yang melibatkan ∞ dan NaN adalah tf.debugging.enable_check_numerics() . Berbeda dengan enable_dump_debug_info() , enable_check_numerics() tidak menyimpan informasi debug pada disk. Sebaliknya, ia hanya memonitor ∞ dan NaN selama runtime TensorFlow dan melakukan kesalahan dengan lokasi kode asal segera setelah operasi apa pun menghasilkan nilai numerik yang buruk. Ini memiliki overhead kinerja yang lebih rendah dibandingkan dengan enable_dump_debug_info() , tetapi tidak memberikan jejak lengkap riwayat eksekusi program dan tidak dilengkapi dengan antarmuka pengguna grafis seperti Debugger V2.