
참고: tf.debugging.experimental.enable_dump_debug_info()는 실험용 API이며 향후 변경될 수 있습니다.
때때로 TensorFlow 프로그램 중에 NaN과 관련된 치명적인 이벤트가 발생하여 모델 훈련 프로세스를 손상시킬 수 있습니다. 이러한 이벤트의 근본 원인은 비교적 크고 복잡한 모델일수록 명료하지 않은 경우가 많습니다. 이러한 형식의 모델 버그를 보다 쉽게 디버깅 할 수 있도록 TensorBoard 2.3+는 (TensorFlow 2.3+와 함께) Debugger V2라는 특수 대시보드를 제공합니다. 여기서는 TensorFlow로 작성된 신경망에서 NaN과 관련된 실제 버그를 해결하는 과정을 재현하여 이 도구를 사용하는 방법을 보여줍니다.
이 튜토리얼은 상대적으로 발생 빈도가 높은 NaN에 중점을 두고 있지만, 여기 설명된 기술은 복잡한 프로그램에서 런타임 텐서 형상 검사하기와 같은 다른 형식의 디버깅 활동에도 적용할 수 있습니다.
버그 관찰하기
디버깅할 TF2 프로그램의 소스 코드는 GitHub에서 찾아볼 수 있습니다. 예제 프로그램은 또한 tensorflow pip 패키지(버전 2.3+)로 패키징되며 다음을 통해 불러올 수 있습니다.
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
이 TF2 프로그램은 다중 레이어 인식(MLP)을 생성하고 MNIST 이미지를 인식하도록 훈련합니다. 이 예제는 의도적으로 TF2의 상위 수준의 API를 사용하여 사용자 정의 레이어 구조, 손실 함수 및 훈련 루프를 정의합니다. 더 유연하고 에러 발생율이 높은 API를 사용하는 것이 tf.keras처럼 사용하기는 더 쉽지만, 약간 덜 유연한 상위 수준의 API를 사용할 때보다 NaN 버그가 발생할 가능성이 더 높기 때문입니다.
이 프로그램은 각 훈련 단계 후에 테스트 정확성을 출력합니다. 콘솔을 보면 테스트 정확성이 첫 번째 단계 이후에 우연에 가까운 수준 (~0.1)에서 멈춘 것을 볼 수 있습니다. 이것은 결코 예상된 모델 훈련 동작이 아니며, 예상대로라면 단계가 증가함에 따라 정확성이 점차 1.0(100 %)에 접근해야 합니다.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
이 문제는 NaN 또는 무한대와 같은 수치적 불안정성으로 인해 발생하는 것으로 추측됩니다. 이것이 실제로 사실임을 확인하고 수치적 불안정성을 생성하는 TensorFlow 연산을 찾기 위해 Debugger V2로 버그가 있는 프로그램을 계측해 보겠습니다.
Debugger V2로 TensorFlow 코드 계측하기
tf.debugging.experimental.enable_dump_debug_info()는 Debugger V2의 API 진입점입니다. 한 줄의 코드로 TF2 프로그램을 계측합니다. 예를 들어, 프로그램 시작 부분에 다음 줄을 추가하면 디버그 정보가 /tmp/tfdbg2_logdir의 로그 디렉터리(logdir)에 기록됩니다. 디버그 정보는 TensorFlow 런타임의 다양한 측면을 다룹니다. TF2에는 eager 실행의 전체 내역, @tf.function에 의해 수행된 그래프 작성, 그래프 실행, 실행 이벤트에 의해 생성된 텐서값 및 해당 이벤트의 코드 위치(Python 스택 추적)가 포함됩니다. 풍부한 디버그 정보를 통해 사용자는 모호한 버그의 범위를 좁힐 수 있습니다.
tf.debugging.experimental.enable_dump_debug_info(
logdir="/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
tensor_debug_mode 인수는 Debugger V2가 각 eager 또는 in-graph 텐서에서 추출하는 정보를 제어합니다. 'FULL_HEALTH'는 각 부동 형식 텐서에 대한 다음 정보를 캡처하는 모드입니다(예: 일반적으로 표시되는 float32 및 덜 일반적인 bfloat16 dtype).
- DType
- 순위(Rank)
- 총 요소 수
- 부동 형식 요소를 음의 유한 (
-), 영 (0), 양의 유한 (+), 음의 무한 (-∞), 양의 무한 (+∞) 및NaN범주로 분류
'FULL_HEALTH' 모드는 NaN 및 무한대와 관련된 버그를 디버깅하는 데 적합합니다. 지원되는 다른 tensor_debug_mode에 대해서는 아래를 참조하세요.
circular_buffer_size 인수는 logdir에 저장되는 텐서 이벤트의 수를 제어합니다. 기본값은 1000으로, 계측된 TF2 프로그램이 끝나기 전에 마지막 1000개의 텐서만 디스크에 저장됩니다. 이 기본 동작은 디버그 데이터의 완전성을 희생하여 디버거 오버헤드를 줄입니다. 이 경우와 같이 완전성이 선호되는 경우, 인수를 음수값으로 설정하여 순환 버퍼를 비활성화할 수 있습니다(예: 여기서 -1).
debug_mnist_v2 예제는 명령줄 플래그를 전달하여 enable_dump_debug_info()를 불러옵니다. 이 디버깅 계측을 활성화한 상태에서 문제가 있는 TF2 프로그램을 다시 실행하려면 다음을 수행하세요.
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
TensorBoard에서 Debugger V2 GUI 시작하기
디버거 계측으로 프로그램을 실행하면 /tmp/tfdbg2_logdir에 logdir이 생성됩니다. TensorBoard를 시작하고 다음을 사용하여 logdir을 지정할 수 있습니다.
tensorboard --logdir /tmp/tfdbg2_logdir
웹 브라우저에서 http://localhost:6006의 TensorBoard 페이지로 이동합니다. 'Debugger V2' 플러그인은 기본적으로 활성화되어 다음과 같은 페이지를 표시합니다.
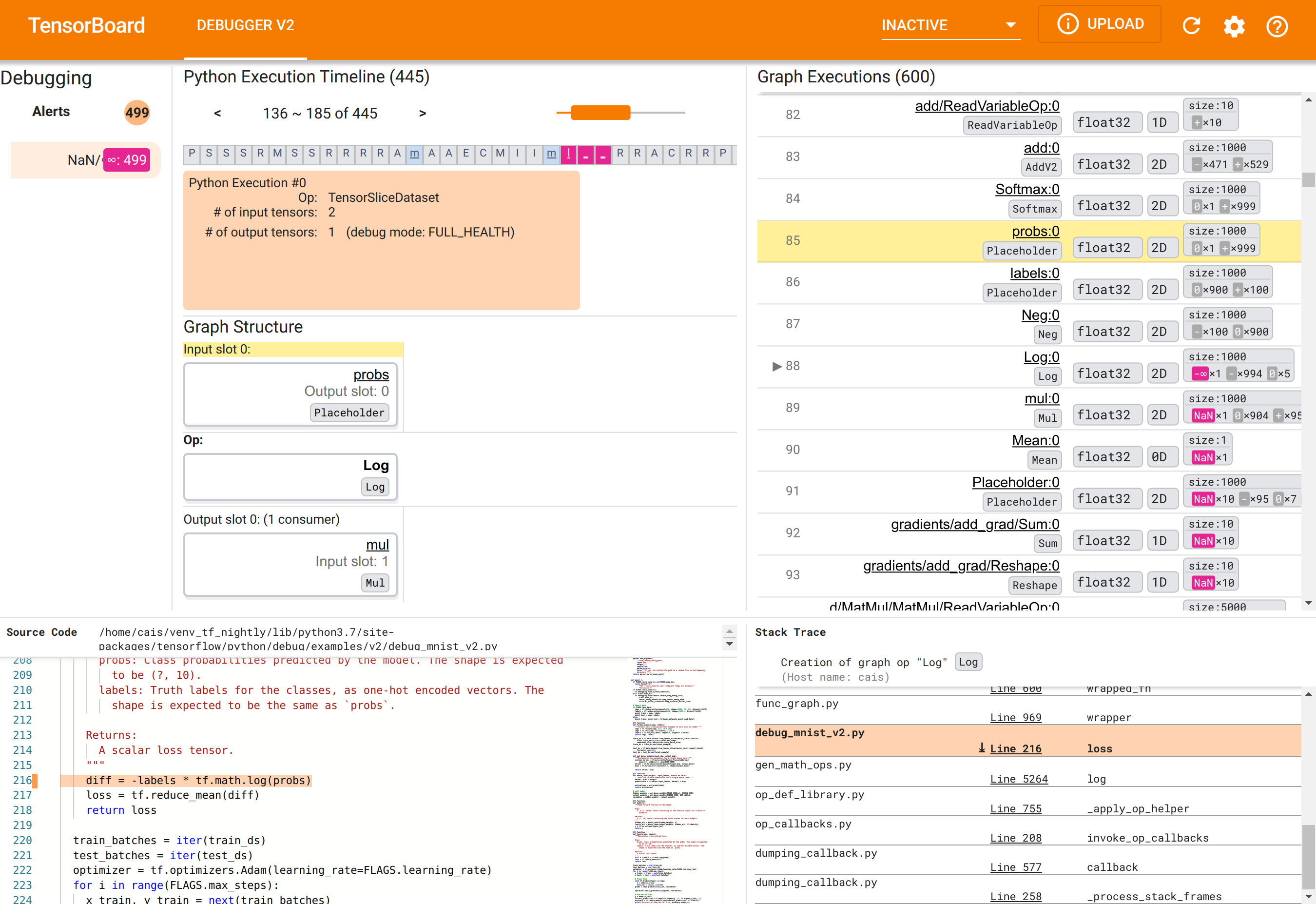
Debugger V2 GUI를 사용하여 NaN의 근본 원인 찾기
TensorBoard의 Debugger V2 GUI는 6개 섹션으로 구성됩니다.
- 경고: 이 왼쪽 상단 섹션에는 계측된 TensorFlow 프로그램의 디버그 데이터에서 디버거가 감지한 '경고' 이벤트 목록이 포함되어 있습니다. 각 경고는 주의가 필요한 특정 이상을 나타냅니다. 예제의 경우, 이 섹션에 눈에 띄는 선홍색으로 499개의 NaN/∞ 이벤트가 강조 표시되어 있습니다. 이것은 내부 텐서값에 NaN 및/또는 무한대가 존재하기 때문에 모델이 학습하지 못한다는 추측을 확인시켜주는 증거입니다. 곧 이러한 경고에 대해 자세히 살펴 보겠습니다.
- Python 실행 타임라인: 상단 중간 섹션의 상단 절반입니다. ops 및 그래프의 eager 실행에 대한 전체 기록을 제공합니다. 타임라인의 각 상자는 op 또는 그래프 이름의 첫 글자로 표시됩니다(예: 'TensorSliceDataset' op의 경우 'T', '모델'
tf.function의 경우 'm'). 타임라인 위의 탐색 버튼과 스크롤바를 사용하여 위 타임라인을 탐색할 수 있습니다. - 그래프 실행: GUI의 오른쪽 상단에 있는 이 섹션은 디버깅 작업의 중심이 될 것입니다. 여기에는 그래프 내에서 계산된 모든 부동 dtype 텐서의 기록이 포함됩니다(예:
@tf-function에 의해 컴파일됨). - 그래프 구조(중간 상단 섹션의 하단 절반), 소스 코드(왼쪽 하단 섹션) 및 스택 추적(오른쪽 하단 섹션)은 처음에 비어 있으며, 해당 내용은 GUI와 상호 작용할 때 채워질 것입니다. 이 3개의 섹션은 디버깅 작업에서도 중요한 역할을 합니다.
UI 구성에 대해 알아봤으니, 다음 단계를 수행하여 NaN이 나타나는 이유를 파악해 보겠습니다. 먼저 경고 섹션에서 NaN/∞ 경고를 클릭합니다. 그러면 그래프 실행 섹션에서 600개의 그래프 텐서 목록이 자동으로 스크롤되고 Log (자연 로그) op에 의해 생성된 'Log:0'이라는 이름의 텐서인 #88에 초점이 맞춰집니다. 뚜렷한 선홍색으로 2D float32 텐서의 1000개 요소 중 -∞ 요소가 강조 표시됩니다. 이것은 NaN 또는 무한대를 포함하는 TF2 프로그램 런타임 기록의 첫 번째 텐서로, 이 전에 계산된 텐서는 NaN 또는 ∞를 포함하지 않거나 나중에 계산된 많은 (사실 대부분의) 텐서는 NaN을 포함합니다. 그래프 실행 목록을 위아래로 스크롤하여 이를 확인할 수 있습니다. 이 관찰은 Log op가 TF2 프로그램의 수치적 불안정성의 원인이라는 강력한 힌트를 제공합니다.
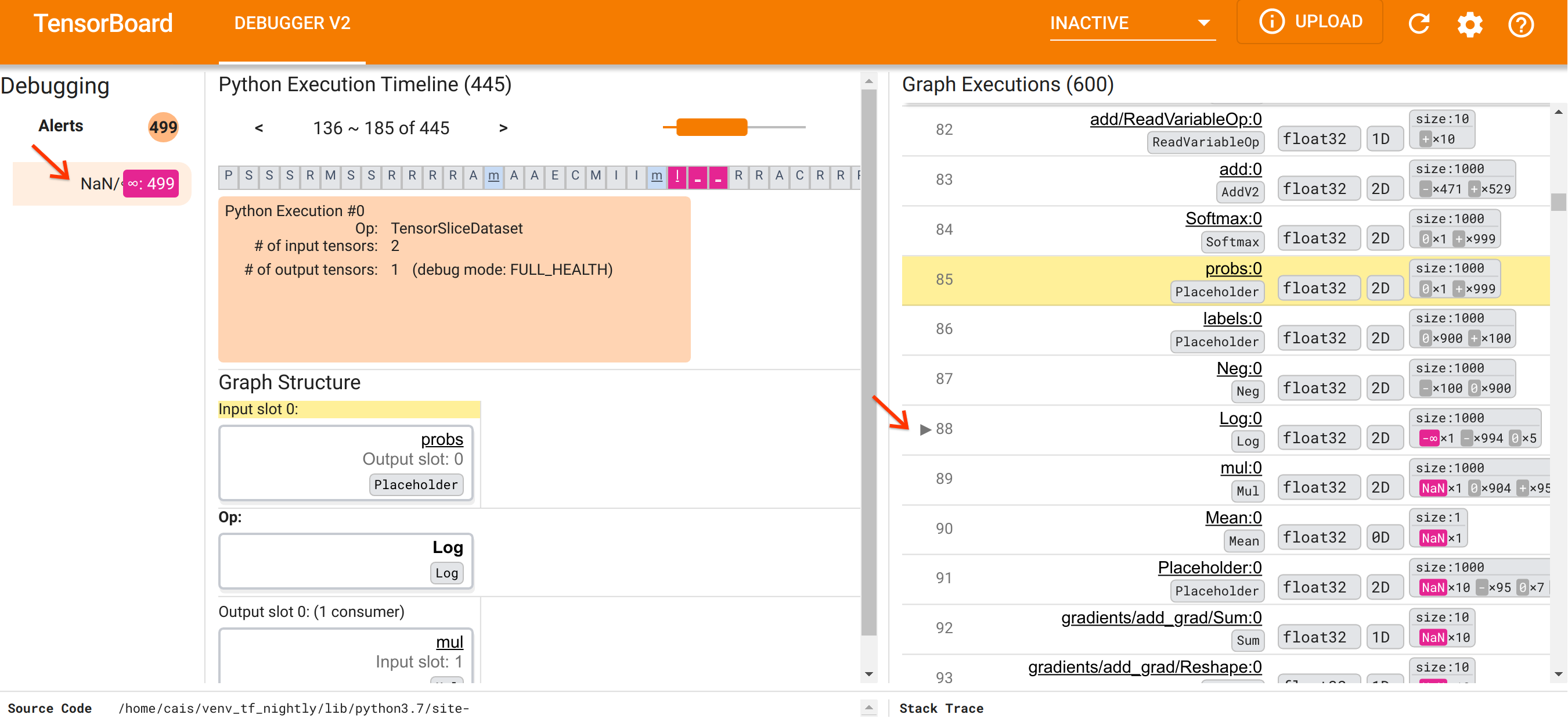
이 Log op는 왜 -∞를 뱉어낼까요? 이 질문에 답하려면 op에 대한 입력을 검토해야 합니다. 텐서의 이름('Log:0')을 클릭하면 그래프 구조 섹션의 TensorFlow 그래프에서 Log op의 주변에 대한 간단하지만 유익한 시각화 자료가 표시됩니다. 정보는 위쪽에서 아래쪽 방향으로 흐르도록 되어 있으며, op 자체는 중간에 볼드체로 표시됩니다. 바로 위에 Placeholder op가 Log op에 대한 유일한 입력을 제공하는 것을 볼 수 있습니다. 그래프 실행 목록에서 이 로짓 Placeholder에 의해 생성된 텐서는 어디에 있을까요? 노란색 배경색을 시각 자료로 사용하면 logits:0 텐서가 Log:0 텐서보다 두 행 위, 즉 85행에 있음을 알 수 있습니다.

85행에 있는 'logits:0' 텐서의 수치 분석을 자세히 살펴보면 소비자 Log:0가 -∞를 생성하는 이유를 알 수 있습니다. 'logits:0'의 1000개 요소 중 값이 0인 요소는 한 개입니다. -∞는 0의 자연 로그를 계산한 결과인 것이죠! Log op가 양의 입력에만 노출되도록 할 수 있다면 NaN/∞이 발생하는 것을 방지할 수 있습니다. 이것은 Placeholder 로짓 텐서에 클리핑(예: tf.clip_by_value() 사용)을 적용하여 달성할 수 있습니다.
버그 해결에 가까워지고 있지만 아직 남은 단계가 있습니다. 수정 사항을 적용하려면 Python 소스 코드에서 Log op 및 해당 Placeholder 입력이 시작된 위치를 알아야 합니다. Debugger V2는 그래프 ops 및 실행 이벤트의 소스를 추적하기 위한 최고 수준의 지원을 제공합니다. 그래프 실행에서 Log:0 텐서를 클릭했을 때 스택 추적 섹션이 Log op 생성의 원래 스택 추적으로 채워졌습니다. 스택 추적은 TensorFlow 내부 코드(예: gen_math_ops.py 및 dumping_callback.py)의 많은 프레임을 포함하기 때문에 다소 크며 대부분의 디버깅 작업에서는 무시해도 됩니다. 여기서 주목할 프레임은 debug_mnist_v2.py의 216행입니다(즉, 실제로 디버깅하려는 Python 파일). 'Line 204'를 클릭하면 소스 코드 섹션에 해당하는 코드 줄이 표시됩니다.
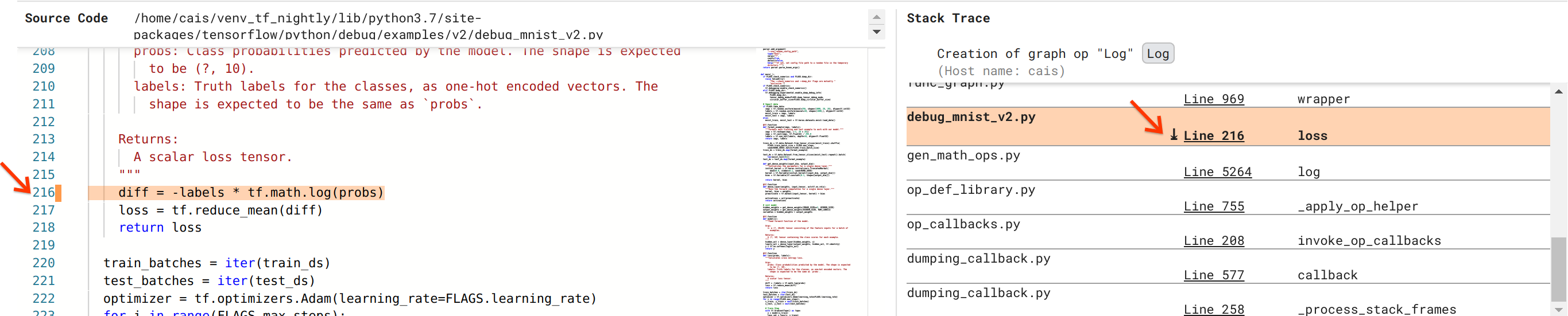
드디어 로짓 입력에서 문제가 있는 Log op를 생성한 소스 코드로 이어집니다. 이것은 @tf.function으로 데코레이팅된 사용자 정의 범주형 교차 엔트로피 손실 함수이므로, TensorFlow 그래프로 변환됩니다. Placeholder op 'logits'는 손실 함수의 첫 번째 입력 인수에 해당합니다. Log op는 tf.math.log() API 호출로 생성됩니다.
이 버그에 대한 값 클리핑 수정은 다음과 같습니다.
diff = -(labels *
tf.clip_by_value(tf.math.log(logits), 1e-6, 1.))
이 TF2 프로그램의 수치적 불안정성을 해결하고 MLP가 성공적으로 훈련되도록 합니다. 수치적 불안정성을 수정하는 또 다른 방법은 tf.keras.losses.CategoricalCrossentropy를 사용하는 것입니다.
이것으로 TF2 모델 버그 관찰에서 버그를 수정하는 코드 변경에 이르는 여정을 마무리합니다. 이 과정에서 텐서값의 수치 요약 및 ops, 텐서, 원래 소스 코드 간의 관련성을 포함하여 계측된 TF2 프로그램의 eager 및 그래프 실행 기록에 대한 완전한 가시성을 제공하는 Debugger V2 도구의 도움을 받았습니다.
Debugger V2의 하드웨어 호환성
Debugger V2는 CPU 및 GPU를 포함한 주류 훈련 하드웨어를 지원합니다. tf.distributed.MirroredStrategy를 사용한 다중 GPU 훈련도 지원됩니다. TPU 지원은 아직 초기 단계이며, 다음 코드를 호출한 다음,
tf.config.set_soft_device_placement(True)
enable_dump_debug_info()를 호출해야 합니다. TPU에도 다른 제한이 있을 수 있습니다. Debugger V2 사용에 문제가 발생하면 GitHub 문제 페이지에서 버그를 신고해 주세요.
Debugger V2의 API 호환성
Debugger V2는 비교적 낮은 수준의 TensorFlow 소프트웨어 스택에서 적용되므로 tf.keras, tf.data 및 TensorFlow의 비교적 낮은 수준 위에 빌드된 기타 API와 호환됩니다. Debugger V2는 또한 TF1과 역호환되지만 TF1 프로그램에 의해 생성된 디버그 logdir에 대한 Eager 실행 타임라인은 비어 있을 것입니다.
API 사용 팁
이 디버깅 API에 관해 자주 묻는 질문 중 하나는 TensorFlow 코드에서 enable_dump_debug_info()를 호출하는 줄을 어디에 삽입해야 하는지입니다. 일반적으로 API는 TF2 프로그램에서 가능한 빨리 호출해야 하며, 가급적이면 Python 가져오기 줄 이후와 그래프 빌드 및 실행이 시작되기 전에 불러와야 합니다. 이렇게 하면 모델과 훈련을 지원하는 모든 ops 및 그래프를 모두 포괄할 수 있습니다.
현재 지원되는 tensor_debug_mode는 NO_TENSOR, CURT_HEALTH, CONCISE_HEALTH, FULL_HEALTH 및 SHAPE입니다. 각 텐서에서 추출된 정보의 양과 디버깅된 프로그램에 대한 성능 오버헤드가 다릅니다. enable_dump_debug_info() 설명서의 args 섹션을 참조하세요.
성능 오버헤드
디버깅 API는 계측된 TensorFlow 프로그램에 성능 오버헤드를 도입합니다. 오버헤드는 tensor_debug_mode, 하드웨어 형식, 계측된 TensorFlow 프로그램의 특성에 따라 다릅니다. 참조 사항으로, GPU에서 NO_TENSOR 모드는 배치 크기 64에서 Transformer 모델을 훈련하는 동안 15%의 오버헤드를 추가합니다. 다른 tensor_debug_mode의 오버헤드 비율은 더 높습니다. CURT_HEALTH, CONCISE_HEALTH, FULL_HEALTH 및 SHAPE 모드의 경우, 약 50%입니다. CPU에서는 오버헤드가 약간 낮습니다. TPU에서는 현재 오버헤드가 더 높습니다.
다른 TensorFlow 디버깅 API와의 관계
TensorFlow는 디버깅을 위한 기타 도구와 API를 제공합니다. API 문서 페이지의 tf.debugging.* 네임스페이스에서 이러한 API를 찾아볼 수 있습니다. 이러한 API 중에서 가장 자주 사용되는 것은 tf.print()입니다. 언제 Debugger V2를 사용해야 하고 tf.print()를 대신 사용해야 할까요? tf.print()는 다음과 같은 경우에 편리합니다.
- 출력할 텐서를 정확히 알고 있다.
tf.print()문을 삽입할 소스 코드의 정확한 위치를 알고 있다.- 그러한 텐서의 수가 너무 크지 않다.
여러 개의 텐서값 검사하기, TensorFlow의 내부 코드에 의해 생성된 텐서값 검사하기, 상기 수치 불안정성의 원인 검색하기 등 다른 경우에는 Debugger V2가 더 빠른 디버깅 방법을 제공합니다. 또한 Debugger V2는 eager 및 그래프 텐서를 검사하는 획일화된 접근 방식을 제공합니다. 또한 tf.print() 의 기능을 넘어서는 그래프 구조 및 코드 위치에 대한 정보를 제공합니다.
∞ 및 NaN과 관련된 문제를 디버깅하는 데 사용할 수 있는 또 다른 API는 tf.debugging.enable_check_numerics()입니다. enable_dump_debug_info()와 달리 enable_check_numerics()는 디스크에 디버그 정보를 저장하지 않습니다. 대신 TensorFlow 런타임 중에 ∞ 및 NaN을 모니터링하고 어떤 op든 이러한 잘못된 숫자 값을 생성하는 즉시 원본 코드 위치에서 오류를 발생시킵니다. enable_dump_debug_info()에 비해 성능 오버헤드가 낮지만 프로그램 실행 기록의 전체 추적을 제공하지 않으며 Debugger V2와 같은 그래픽 사용자 인터페이스와 함께 제공되지 않습니다.