
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Khi xây dựng mô hình máy học tập, bạn cần phải chọn khác nhau siêu tham số , chẳng hạn như tỷ lệ bỏ học trong một lớp hoặc tỷ lệ học. Những quyết định này tác động đến các chỉ số của mô hình, chẳng hạn như độ chính xác. Do đó, một bước quan trọng trong quy trình học máy là xác định các siêu tham số tốt nhất cho vấn đề của bạn, thường liên quan đến thử nghiệm. Quá trình này được gọi là "Tối ưu hóa siêu tham số" hoặc "Điều chỉnh siêu tham số".
Bảng điều khiển HParams trong TensorBoard cung cấp một số công cụ để trợ giúp quá trình xác định thử nghiệm tốt nhất hoặc bộ siêu tham số hứa hẹn nhất.
Hướng dẫn này sẽ tập trung vào các bước sau:
- Thiết lập thử nghiệm và tóm tắt HParams
- Adapt TensorFlow chạy để ghi các siêu tham số và chỉ số
- Bắt đầu chạy và ghi lại tất cả chúng trong một thư mục mẹ
- Hình dung kết quả trong bảng điều khiển HParams của TensorBoard
Bắt đầu bằng cách cài đặt TF 2.0 và tải phần mở rộng máy tính xách tay TensorBoard:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
Nhập TensorFlow và plugin TensorBoard HParams:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
Tải FashionMNIST bộ dữ liệu và quy mô nó:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. Thiết lập thử nghiệm và tóm tắt thử nghiệm HParams
Thử nghiệm với ba siêu tham số trong mô hình:
- Số lượng đơn vị trong lớp dày đặc đầu tiên
- Tỷ lệ bỏ học ở lớp bỏ học
- Trình tối ưu hóa
Liệt kê các giá trị để thử và ghi lại cấu hình thử nghiệm vào TensorBoard. Bước này là tùy chọn: bạn có thể cung cấp thông tin miền để cho phép lọc chính xác hơn các siêu tham số trong giao diện người dùng và bạn có thể chỉ định số liệu nào sẽ được hiển thị.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
Nếu bạn chọn để bỏ qua bước này, bạn có thể sử dụng một chữ chuỗi bất cứ nơi nào bạn nếu không sẽ sử dụng một HParam giá trị: ví dụ, hparams['dropout'] thay vì hparams[HP_DROPOUT] .
2. Adapt TensorFlow chạy để ghi các siêu tham số và chỉ số
Mô hình sẽ khá đơn giản: hai lớp dày đặc với một lớp bỏ rơi giữa chúng. Mã đào tạo sẽ trông quen thuộc, mặc dù các siêu tham số không còn được mã hóa cứng nữa. Thay vào đó, các siêu được cung cấp trong một hparams từ điển và sử dụng trong suốt các chức năng đào tạo:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
Đối với mỗi lần chạy, ghi lại một bản tóm tắt hparams với các siêu tham số và độ chính xác cuối cùng:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
Khi đào tạo các mô hình Keras, bạn có thể sử dụng các lệnh gọi lại thay vì viết trực tiếp:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. Bắt đầu chạy và ghi lại tất cả chúng trong một thư mục mẹ
Giờ đây, bạn có thể thử nhiều thử nghiệm, huấn luyện mỗi thử nghiệm với một bộ siêu tham số khác nhau.
Để đơn giản hơn, hãy sử dụng tìm kiếm lưới: thử tất cả các kết hợp của các tham số rời rạc và chỉ giới hạn dưới và giới hạn trên của tham số có giá trị thực. Đối với các tình huống phức tạp hơn, có thể hiệu quả hơn nếu chọn ngẫu nhiên từng giá trị siêu tham số (đây được gọi là tìm kiếm ngẫu nhiên). Có nhiều phương pháp tiên tiến hơn có thể được sử dụng.
Chạy một vài thử nghiệm, sẽ mất vài phút:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. Hình dung kết quả trong plugin HParams của TensorBoard
Bảng điều khiển HParams hiện có thể được mở. Khởi động TensorBoard và nhấp vào "HParams" ở trên cùng.
%tensorboard --logdir logs/hparam_tuning

Ngăn bên trái của bảng điều khiển cung cấp các khả năng lọc đang hoạt động trên tất cả các chế độ xem trong bảng điều khiển HParams:
- Lọc siêu tham số / chỉ số nào được hiển thị trong trang tổng quan
- Lọc các giá trị siêu tham số / chỉ số nào được hiển thị trong trang tổng quan
- Lọc trạng thái chạy (đang chạy, thành công, ...)
- Sắp xếp theo siêu tham số / số liệu trong chế độ xem bảng
- Số lượng nhóm phiên sẽ hiển thị (hữu ích cho hiệu suất khi có nhiều thử nghiệm)
Bảng điều khiển HParams có ba chế độ xem khác nhau, với nhiều thông tin hữu ích khác nhau:
- Bảng Xem danh sách chạy, siêu tham số của họ, và số liệu của họ.
- Các Parallel Tọa Xem thấy mỗi lần chạy như một dòng đi qua một trục cho mỗi hyperparemeter và số liệu. Nhấp và kéo chuột trên bất kỳ trục nào để đánh dấu một vùng sẽ chỉ đánh dấu các đường chạy đi qua nó. Điều này có thể hữu ích để xác định nhóm siêu tham số nào là quan trọng nhất. Bản thân các trục có thể được sắp xếp lại bằng cách kéo chúng.
- Scatter Lô Xem show lô so sánh từng hyperparameter / metric với từng chỉ số. Điều này có thể giúp xác định các mối tương quan. Nhấp và kéo để chọn một vùng trong một ô cụ thể và đánh dấu các phiên đó trên các ô khác.
Có thể nhấp vào một hàng trong bảng, một đường tọa độ song song và một thị trường biểu đồ phân tán để xem biểu đồ của các chỉ số như một chức năng của các bước đào tạo cho phiên đó (mặc dù trong hướng dẫn này chỉ sử dụng một bước cho mỗi lần chạy).
Để khám phá thêm các khả năng của bảng điều khiển HParams, hãy tải xuống một bộ nhật ký được tạo trước với nhiều thử nghiệm hơn:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
Xem các nhật ký này trong TensorBoard:
%tensorboard --logdir logs/hparam_demo
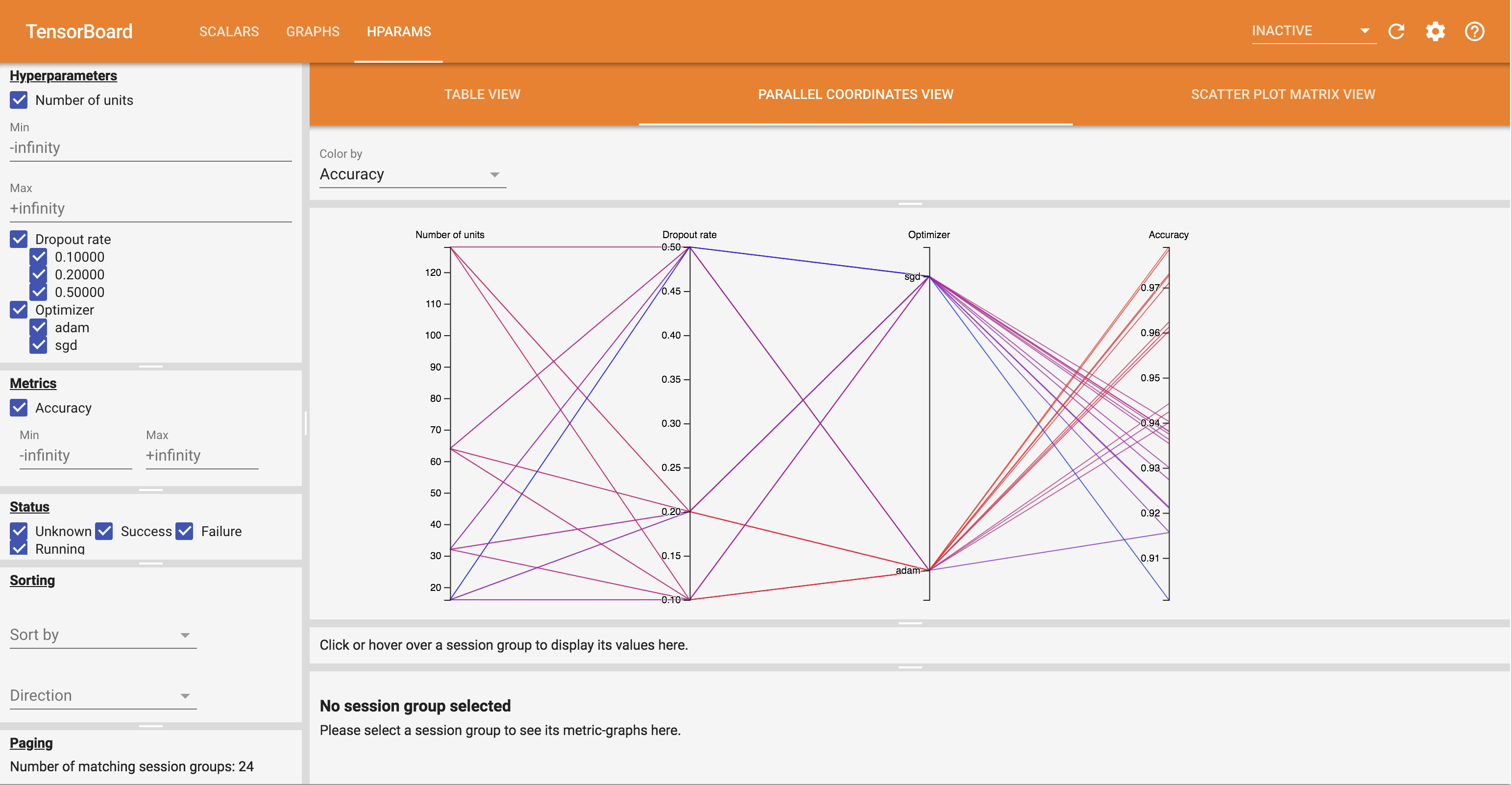
Bạn có thể thử các chế độ xem khác nhau trong bảng điều khiển HParams.
Ví dụ: bằng cách đi tới chế độ xem tọa độ song song và nhấp và kéo trên trục chính xác, bạn có thể chọn các lần chạy với độ chính xác cao nhất. Khi những lần chạy này đi qua 'adam' trong trục trình tối ưu hóa, bạn có thể kết luận rằng 'adam' hoạt động tốt hơn 'sgd' trong các thử nghiệm này.