
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
Алгоритмы машинного обучения обычно требуют больших вычислительных ресурсов. Таким образом, жизненно важно количественно оценить производительность вашего приложения машинного обучения, чтобы убедиться, что вы используете наиболее оптимизированную версию своей модели. Используйте профилировщик TensorFlow, чтобы профилировать выполнение вашего кода TensorFlow.
Настраивать
from datetime import datetime
from packaging import version
import os
TensorFlow Profiler требует последние версии TensorFlow и TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
Убедитесь, что TensorFlow имеет доступ к графическому процессору.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Обучите модель классификации изображений с помощью обратных вызовов TensorBoard
В этом уроке вы изучите возможности TensorFlow Profiler, захватив профиль производительности , полученный путем подготовки модели для классификации изображений в MNIST наборе данных .
Используйте наборы данных TensorFlow, чтобы импортировать данные обучения и разделить их на наборы для обучения и тестирования.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
Предварительно обработайте данные обучения и тестирования, нормализуя значения пикселей до значений от 0 до 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
Создайте модель классификации изображений с помощью Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Создайте обратный вызов TensorBoard для захвата профилей производительности и вызова его во время обучения модели.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
Использование профилировщика TensorFlow для профилирования эффективности обучения модели
Профилировщик TensorFlow встроен в TensorBoard. Загрузите TensorBoard с помощью магии Colab и запустите его. Просмотр профилей производительности, перейдя на вкладку Profile.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
Профиль производительности для этой модели аналогичен изображению ниже.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
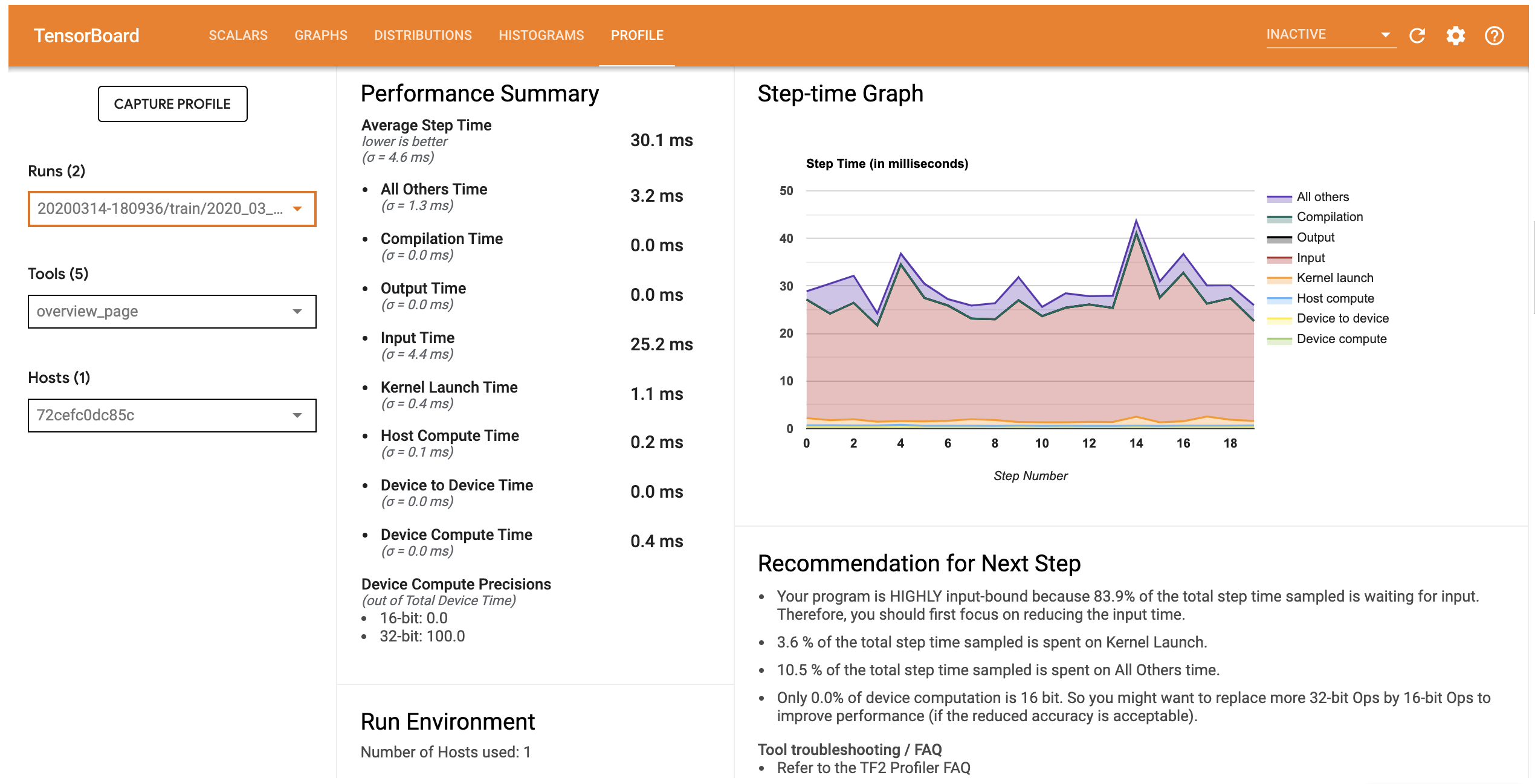
Вкладка профиля открывает страницу Обзора , который показывает вам резюме высокого уровня вашей работы модели. Глядя на График времени шага справа, вы можете увидеть, что модель сильно ограничена входными данными (т. Е. Она проводит много времени в круговой линии ввода данных). На странице «Обзор» также даются рекомендации по возможным следующим шагам, которые вы можете предпринять для оптимизации производительности вашей модели.
Для того, чтобы понять , где узкое место производительности происходит во входном трубопроводе, выберите Трассировку просмотр из инструментов выпадающих меню слева. Средство просмотра трассировки показывает временную шкалу различных событий, которые произошли в ЦП и ГП в течение периода профилирования.
Средство просмотра трассировки отображает несколько групп событий на вертикальной оси. Каждая группа событий имеет несколько горизонтальных дорожек, заполненных событиями трассировки. Дорожка - это временная шкала событий, выполняемых в потоке или потоке графического процессора. Отдельные события представляют собой цветные прямоугольные блоки на дорожках шкалы времени. Время движется слева направо. ОбзорТерминала события трассировки с помощью сочетания клавиш W (увеличение), S (уменьшение), (прокрутки слева) и A D (прокрутки справа).
Один прямоугольник представляет событие трассировки. Выберите значок курсора мыши на панели инструментов с плавающей (или с помощью сочетания клавиш 1 ) и щелкните событие трассировки для его анализа. Это отобразит информацию о событии, такую как время его начала и продолжительность.
Помимо щелчка, вы можете перетащить мышь, чтобы выбрать группу событий трассировки. Это даст вам список всех событий в этой области вместе со сводкой событий. Используйте M ключ для измерения продолжительности времени выбранных событий.
События трассировки собираются из:
- CPU: события CPU отображаются в группе событий с именем
/host:CPU. Каждая дорожка представляет собой поток ЦП. События ЦП включают события входного конвейера, события планирования операций (операций) графического процессора, события выполнения операций ЦП и т. Д. - GPU: события GPU отображаются в группах событий с приставкой
/device:GPU:. Каждая группа событий представляет один поток на графическом процессоре.
Узкие места в производительности отладки
Используйте средство просмотра трассировки, чтобы найти узкие места производительности в конвейере ввода. Изображение ниже - это снимок профиля производительности.
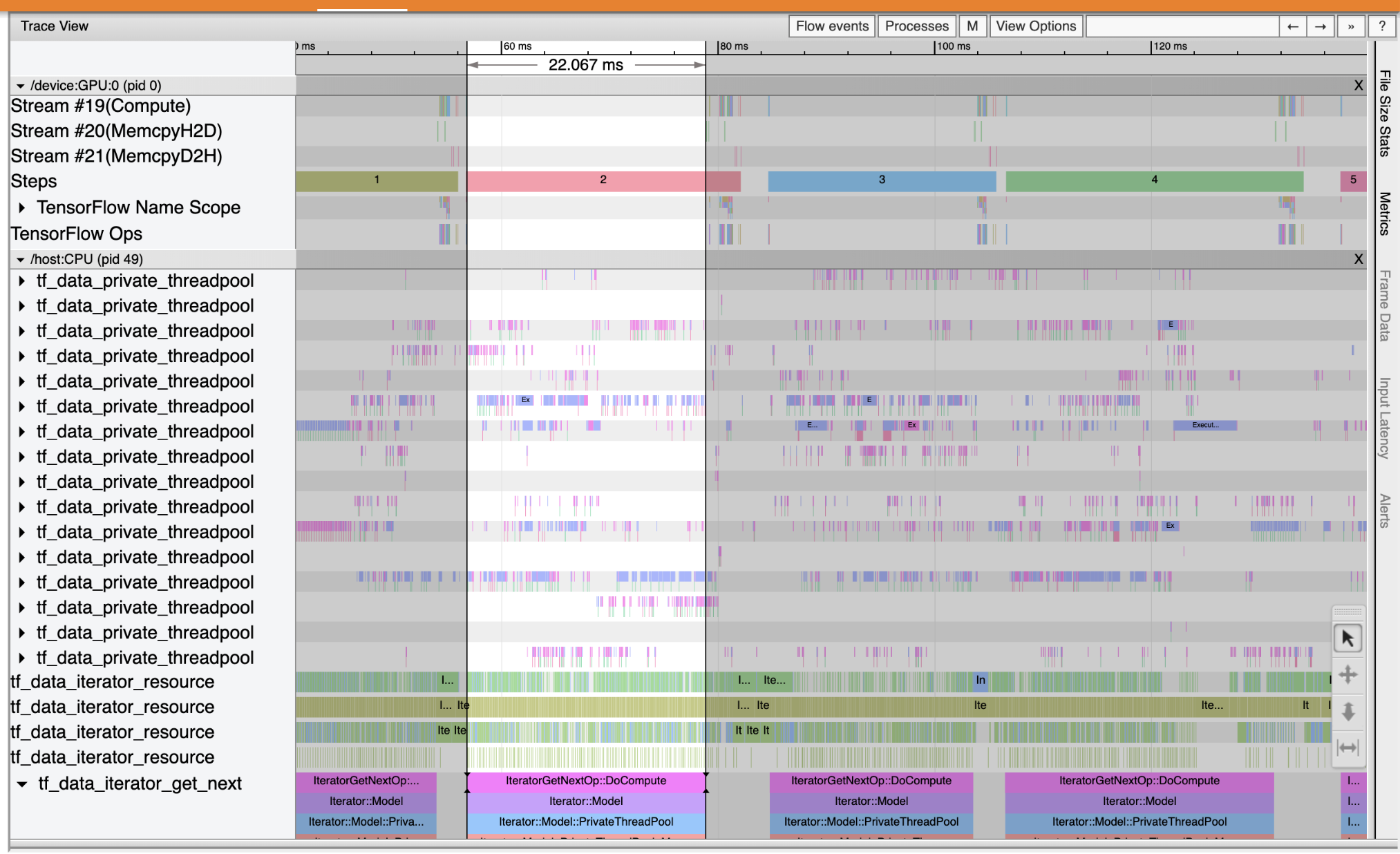
Глядя на следы событий, вы можете увидеть , что GPU является неактивным в то время как tf_data_iterator_get_next оп работает на процессоре. Эта операция отвечает за обработку входных данных и отправку их на графический процессор для обучения. Как правило, рекомендуется всегда держать устройство (GPU / TPU) активным.
Используйте tf.data API для оптимизации ввода трубопровода. В этом случае давайте кэшируем набор обучающих данных и предварительно выбираем данные, чтобы гарантировать, что данные всегда доступны для обработки графическим процессором. Смотрите здесь для более подробной информации об использовании tf.data для оптимизации входных трубопроводов.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Снова обучите модель и запишите профиль производительности, повторно используя предыдущий обратный вызов.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
Повторное запуск TensorBoard и откройте вкладку Профиль для наблюдения профиля производительности для обновленного входного трубопровода.
Профиль производительности для модели с оптимизированным входным конвейером аналогичен изображению ниже.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
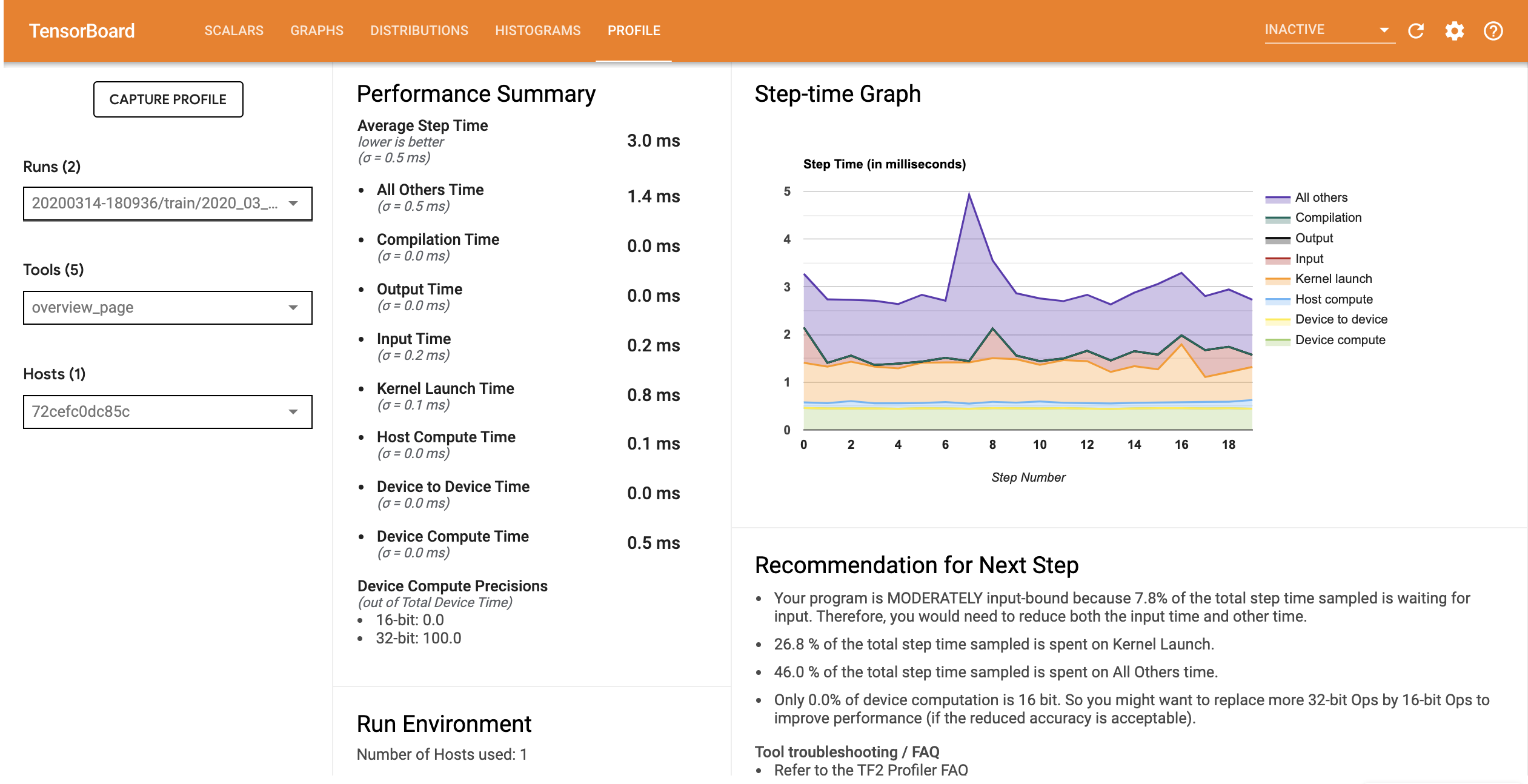
На странице обзора вы можете увидеть, что время среднего шага уменьшилось, как и время шага ввода. График времени шага также указывает на то, что модель больше не имеет жестких ограничений на ввод. Откройте средство просмотра трассировки, чтобы изучить события трассировки с помощью оптимизированного входного конвейера.
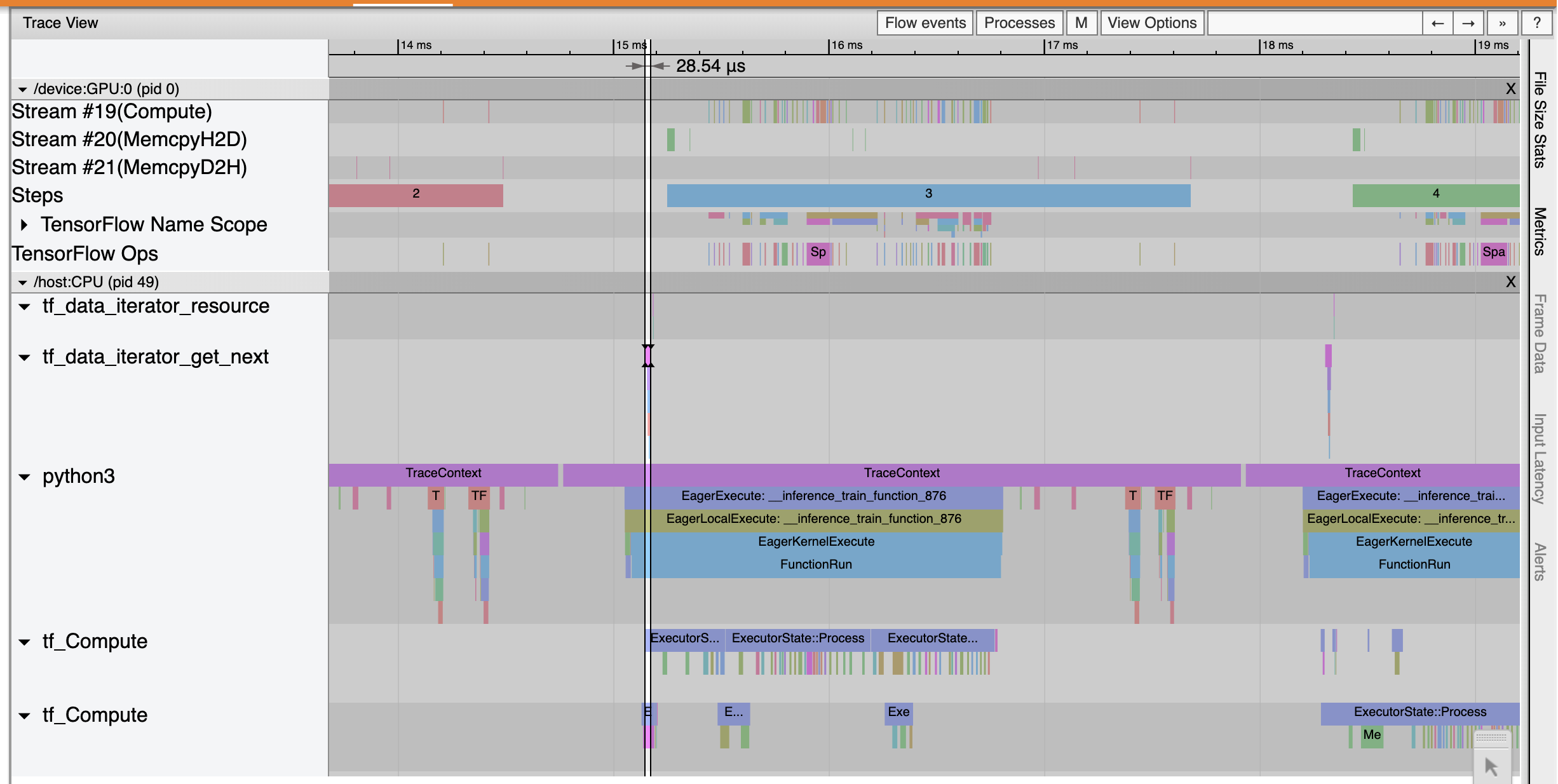
Показывает трассировки Смотрят , что tf_data_iterator_get_next цит выполняет гораздо быстрее. Таким образом, графический процессор получает постоянный поток данных для выполнения обучения и обеспечивает более эффективное использование за счет обучения модели.
Резюме
Используйте профилировщик TensorFlow для профилирования и отладки производительности обучения модели. Прочитайте руководство Profiler и смотреть профилирование производительности в TF 2 разговора с TensorFlow Dev Summit 2020 более узнать о TensorFlow Profiler.