
В этом руководстве показано, как использовать инструменты, доступные в профилировщике TensorFlow, для отслеживания производительности ваших моделей TensorFlow. Вы узнаете, как понять, как ваша модель работает на хосте (ЦП), устройстве (ГП) или на комбинации хоста и устройства(ов).
Профилирование помогает понять потребление аппаратных ресурсов (времени и памяти) различными операциями TensorFlow (ops) в вашей модели, устранить узкие места в производительности и, в конечном итоге, ускорить выполнение модели.
В этом руководстве вы узнаете, как установить профилировщик, различные доступные инструменты, различные режимы сбора данных о производительности профилировщиком, а также некоторые рекомендации по оптимизации производительности модели.
Если вы хотите профилировать производительность вашей модели на Cloud TPU, обратитесь к руководству Cloud TPU .
Установите необходимые компоненты профилировщика и графического процессора.
Установите плагин Profiler для TensorBoard с помощью pip. Обратите внимание, что для профилировщика требуются последние версии TensorFlow и TensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
Для профилирования на графическом процессоре необходимо:
- Соответствуйте драйверам графического процессора NVIDIA® и требованиям CUDA® Toolkit, указанным в требованиях к программному обеспечению для поддержки графического процессора TensorFlow .
Убедитесь, что интерфейс инструментов профилирования NVIDIA® CUDA® (CUPTI) существует по пути:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Если в вашем пути нет CUPTI, добавьте его установочный каталог к переменной среды $LD_LIBRARY_PATH , выполнив:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Затем снова запустите приведенную выше команду ldconfig чтобы убедиться, что библиотека CUPTI найдена.
Решить проблемы с привилегиями
При запуске профилирования с помощью CUDA® Toolkit в среде Docker или Linux вы можете столкнуться с проблемами, связанными с недостаточными привилегиями CUPTI ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Перейдите в Документацию разработчика NVIDIA , чтобы узнать больше о том, как можно решить эти проблемы в Linux.
Чтобы решить проблемы с привилегиями CUPTI в среде Docker, запустите
docker run option '--privileged=true'
Инструменты профилировщика
Получите доступ к профилировщику на вкладке «Профиль» в TensorBoard, которая появляется только после того, как вы захватили некоторые данные модели.
В Profiler имеется набор инструментов, помогающих в анализе производительности:
- Обзорная страница
- Анализатор входного трубопровода
- Статистика TensorFlow
- Средство просмотра трассировки
- Статистика ядра графического процессора
- Инструмент профиля памяти
- Средство просмотра модулей
Обзорная страница
Страница обзора предоставляет представление верхнего уровня о том, как ваша модель работала во время запуска профиля. На странице показана агрегированная страница обзора для вашего хоста и всех устройств, а также некоторые рекомендации по повышению эффективности обучения вашей модели. Вы также можете выбрать отдельные хосты в раскрывающемся списке «Хост».
На странице обзора данные отображаются следующим образом:
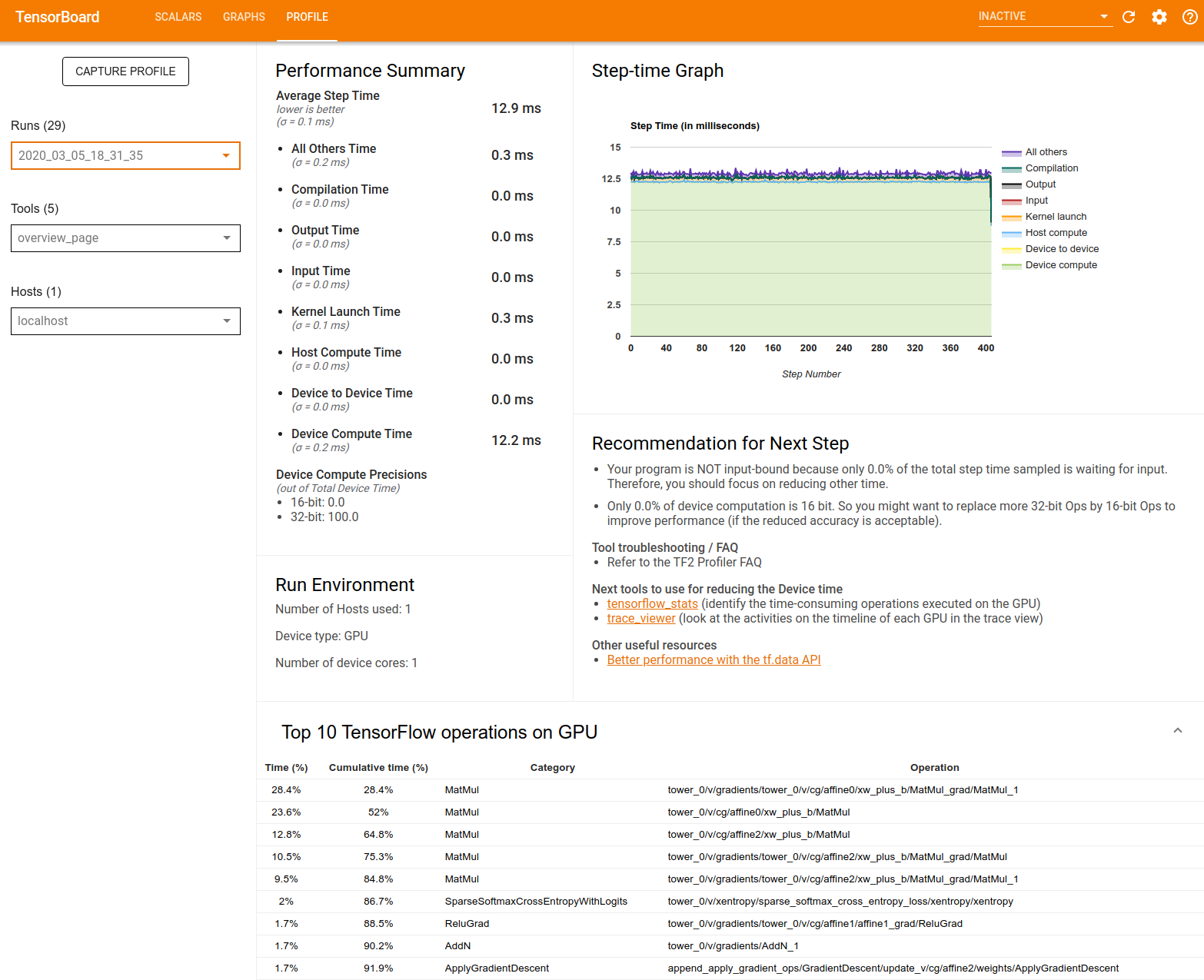
Сводная информация о производительности : отображает общую сводную информацию о производительности вашей модели. Обзор производительности состоит из двух частей:
Разбивка по времени шага: среднее время шага разбивается на несколько категорий того, на что тратится время:
- Компиляция: время, потраченное на компиляцию ядер.
- Ввод: время, потраченное на чтение входных данных.
- Выход: время, потраченное на чтение выходных данных.
- Запуск ядра: время, потраченное хостом на запуск ядер.
- Время вычислений хоста.
- Время связи между устройствами.
- Время вычислений на устройстве.
- Все остальные, включая накладные расходы Python.
Точность вычислений устройства. Сообщает процент времени вычислений устройства, в котором используются 16- и 32-битные вычисления.
График времени шага : отображает график времени шага устройства (в миллисекундах) по всем выбранным шагам. Каждый шаг разбит на несколько категорий (разных цветов), на которые тратится время. Красная область соответствует части времени, в течение которого устройства простаивали в ожидании входных данных от хоста. Зеленая область показывает, сколько времени устройство фактически работало.
Топ-10 операций TensorFlow на устройстве (например, графическом процессоре) : отображает операции на устройстве, которые выполнялись дольше всего.
В каждой строке отображается собственное время операции (в процентах времени, затраченное на все операции), совокупное время, категория и имя.
Среда выполнения : отображает общую сводку среды выполнения модели, включая:
- Количество используемых хостов.
- Тип устройства (GPU/TPU).
- Количество ядер устройства.
Рекомендация для следующего шага : сообщает, когда модель привязана к входным данным, и рекомендует инструменты, которые можно использовать для обнаружения и устранения узких мест в производительности модели.
Анализатор входного конвейера
Когда программа TensorFlow считывает данные из файла, она начинается с верхней части графа TensorFlow конвейерным способом. Процесс чтения разделен на несколько последовательно соединенных этапов обработки данных, где выход одного этапа является входом для следующего. Эта система чтения данных называется входным конвейером .
Типичный конвейер чтения записей из файлов состоит из следующих этапов:
- Чтение файлов.
- Предварительная обработка файлов (опционально).
- Передача файлов с хоста на устройство.
Неэффективный конвейер ввода может серьезно замедлить работу вашего приложения. Приложение считается привязанным к вводу , если оно проводит значительную часть времени во входном конвейере. Используйте информацию, полученную от анализатора входного конвейера, чтобы понять, где входной конвейер неэффективен.
Анализатор входного конвейера немедленно сообщает вам, привязана ли ваша программа к вводу, и проводит анализ на стороне устройства и хоста для устранения узких мест производительности на любом этапе входного конвейера.
Ознакомьтесь с руководством по производительности конвейера ввода, чтобы получить рекомендации по оптимизации конвейеров ввода данных.
Панель входного конвейера
Чтобы открыть анализатор входного конвейера, выберите «Профиль» , затем выберите input_pipeline_analyzer в раскрывающемся списке «Инструменты» .
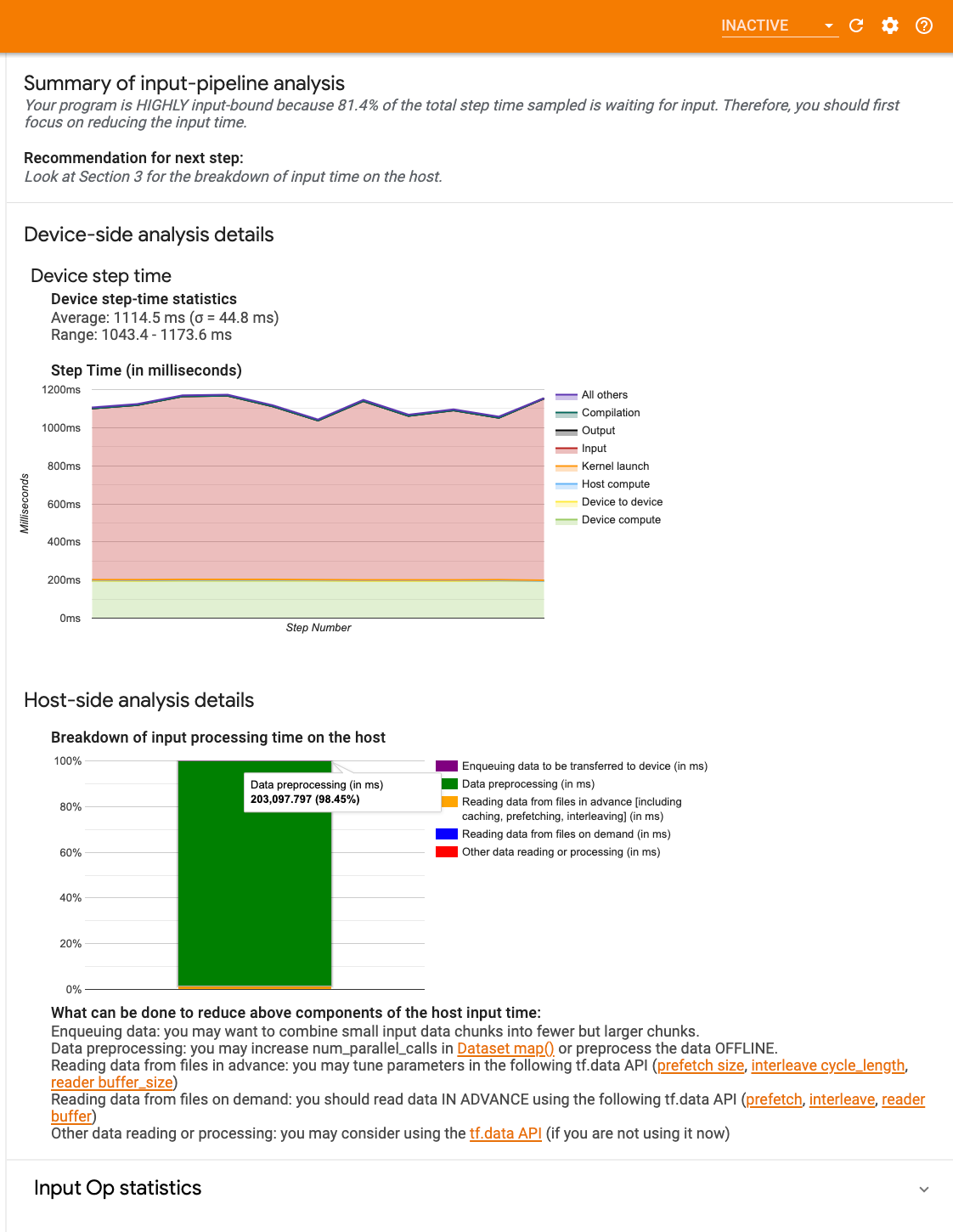
Панель управления содержит три раздела:
- Сводка : суммирует весь конвейер ввода с информацией о том, привязано ли ваше приложение к вводу, и если да, то насколько.
- Анализ на стороне устройства : отображает подробные результаты анализа на стороне устройства, включая время шага устройства и диапазон времени, затрачиваемого устройством на ожидание входных данных по ядрам на каждом этапе.
- Анализ на стороне хоста : показывает подробный анализ на стороне хоста, включая разбивку времени обработки ввода на хосте.
Сводка входного конвейера
Сводка сообщает, привязана ли ваша программа к вводу, показывая процент времени устройства, потраченного на ожидание ввода от хоста. Если вы используете стандартный инструментированный конвейер ввода, инструмент сообщает, на что тратится большая часть времени обработки ввода.
Анализ на стороне устройства
Анализ на стороне устройства дает представление о времени, потраченном на устройстве по сравнению с хостом, а также о том, сколько времени устройство потратило на ожидание входных данных от хоста.
- График зависимости времени шага от номера шага : отображает график времени шага устройства (в миллисекундах) по всем выбранным шагам. Каждый шаг разбит на несколько категорий (разных цветов), на которые тратится время. Красная область соответствует части времени, в течение которого устройства простаивали в ожидании входных данных от хоста. Зеленая область показывает, сколько времени устройство фактически работало.
- Статистика времени шага : сообщает среднее значение, стандартное отклонение и диапазон ([минимум, максимум]) времени шага устройства.
Анализ на стороне хоста
Анализ на стороне хоста сообщает о разбивке времени обработки ввода (времени, затраченного на операции API tf.data ) на хосте по нескольким категориям:
- Чтение данных из файлов по требованию : время, потраченное на чтение данных из файлов без кэширования, предварительной выборки и чередования.
- Предварительное чтение данных из файлов : время, потраченное на чтение файлов, включая кэширование, предварительную выборку и чередование.
- Предварительная обработка данных : время, потраченное на операции предварительной обработки, такие как распаковка изображения.
- Постановка данных в очередь для передачи на устройство : время, потраченное на помещение данных в очередь подачи перед передачей данных на устройство.
Разверните «Статистика операций ввода» , чтобы просмотреть статистику для отдельных операций ввода и их категорий с разбивкой по времени выполнения.
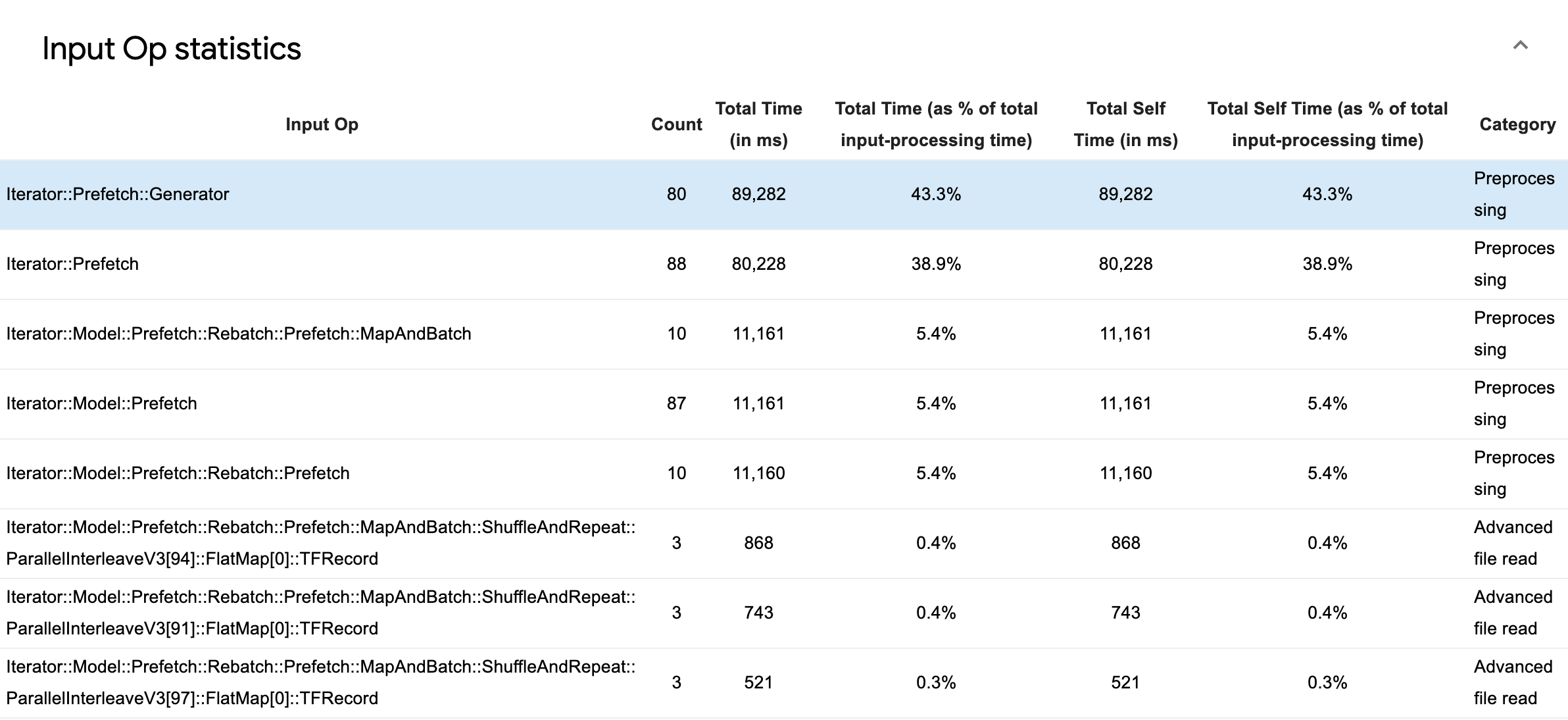
Появится таблица исходных данных, в которой каждая запись содержит следующую информацию:
- Input Op : показывает имя операции TensorFlow для входной операции.
- Count : показывает общее количество экземпляров выполнения операций за период профилирования.
- Общее время (в мс) : показывает совокупную сумму времени, затраченного на каждый из этих экземпляров.
- Общее время % : показывает общее время, затраченное на операцию, как долю от общего времени, затраченного на обработку ввода.
- Общее время на себя (в мс) : показывает совокупную сумму времени, затраченного на каждый из этих экземпляров. Здесь собственное время измеряет время, проведенное внутри тела функции, исключая время, проведенное в вызываемой функции.
- Общее время на себя, % . Показывает общее время, затраченное на обработку ввода, как долю от общего времени, затраченного на обработку ввода.
- Категория . Показывает категорию обработки входной операции.
Статистика TensorFlow
Инструмент TensorFlow Stats отображает производительность каждой операции TensorFlow (op), которая выполняется на хосте или устройстве во время сеанса профилирования.
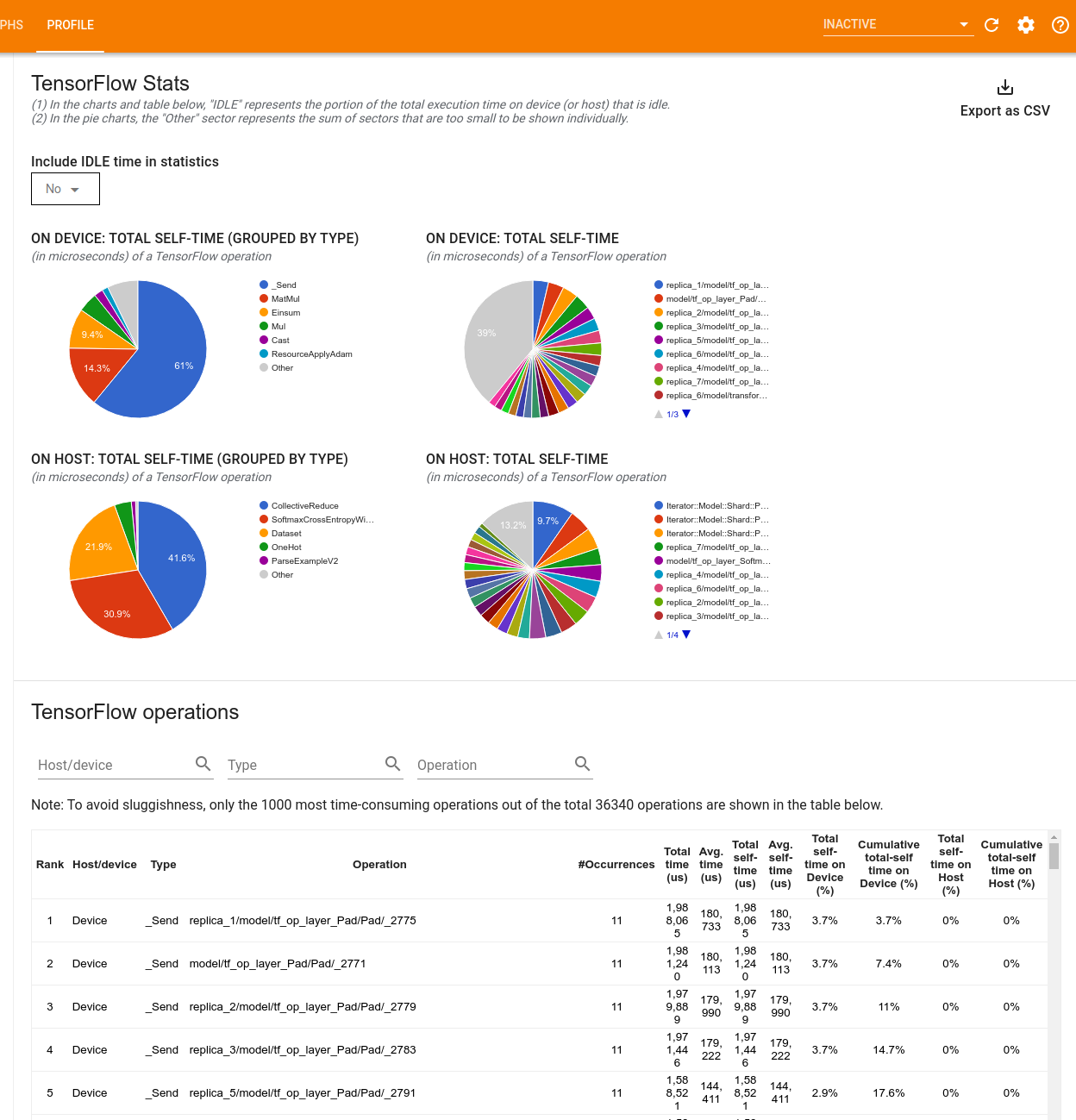
Инструмент отображает информацию о производительности на двух панелях:
На верхней панели отображается до четырех круговых диаграмм:
- Распределение времени самовыполнения каждой операции на хосте.
- Распределение времени самовыполнения каждого типа операций на хосте.
- Распределение времени самовыполнения каждой операции на устройстве.
- Распределение времени самовыполнения каждого типа операций на устройстве.
На нижней панели отображается таблица, в которой представлены данные об операциях TensorFlow с одной строкой для каждой операции и одним столбцом для каждого типа данных (отсортируйте столбцы, щелкнув заголовок столбца). Нажмите кнопку «Экспортировать как CSV» в правой части верхней панели, чтобы экспортировать данные из этой таблицы в файл CSV.
Обратите внимание, что:
Если какие-либо операции имеют дочерние операции:
- Общее «накопленное» время операции включает время, проведенное внутри дочерних операций.
- Общее «собственное» время операции не включает время, проведенное внутри дочерних операций.
Если операция выполняется на хосте:
- Процент общего времени, проведенного на устройстве в результате операции, будет равен 0.
- Совокупный процент общего времени, проведенного на устройстве до этой операции включительно, будет равен 0.
Если на устройстве выполняется операция:
- Процент общего времени, затраченного на эту операцию на хосте, будет равен 0.
- Совокупный процент общего времени на хосте до этой операции включительно будет равен 0.
Вы можете включить или исключить время простоя в круговых диаграммах и таблицах.
Просмотрщик трассировки
Средство просмотра трассировки отображает временную шкалу, на которой показаны:
- Длительность операций, выполняемых вашей моделью TensorFlow.
- Какая часть системы (хост или устройство) выполнила операцию. Обычно хост выполняет операции ввода, предварительно обрабатывает обучающие данные и передает их на устройство, в то время как устройство выполняет фактическое обучение модели.
Средство просмотра трассировки позволяет выявить проблемы с производительностью вашей модели, а затем предпринять шаги для их устранения. Например, на высоком уровне вы можете определить, занимает ли большую часть времени ввод данных или обучение модели. Детализируя, вы можете определить, какие операции выполняются дольше всего. Обратите внимание, что средство просмотра трассировки ограничено 1 миллионом событий на устройство.
Интерфейс просмотра трассировки
Когда вы открываете средство просмотра трассировки, оно отображает ваш последний запуск:
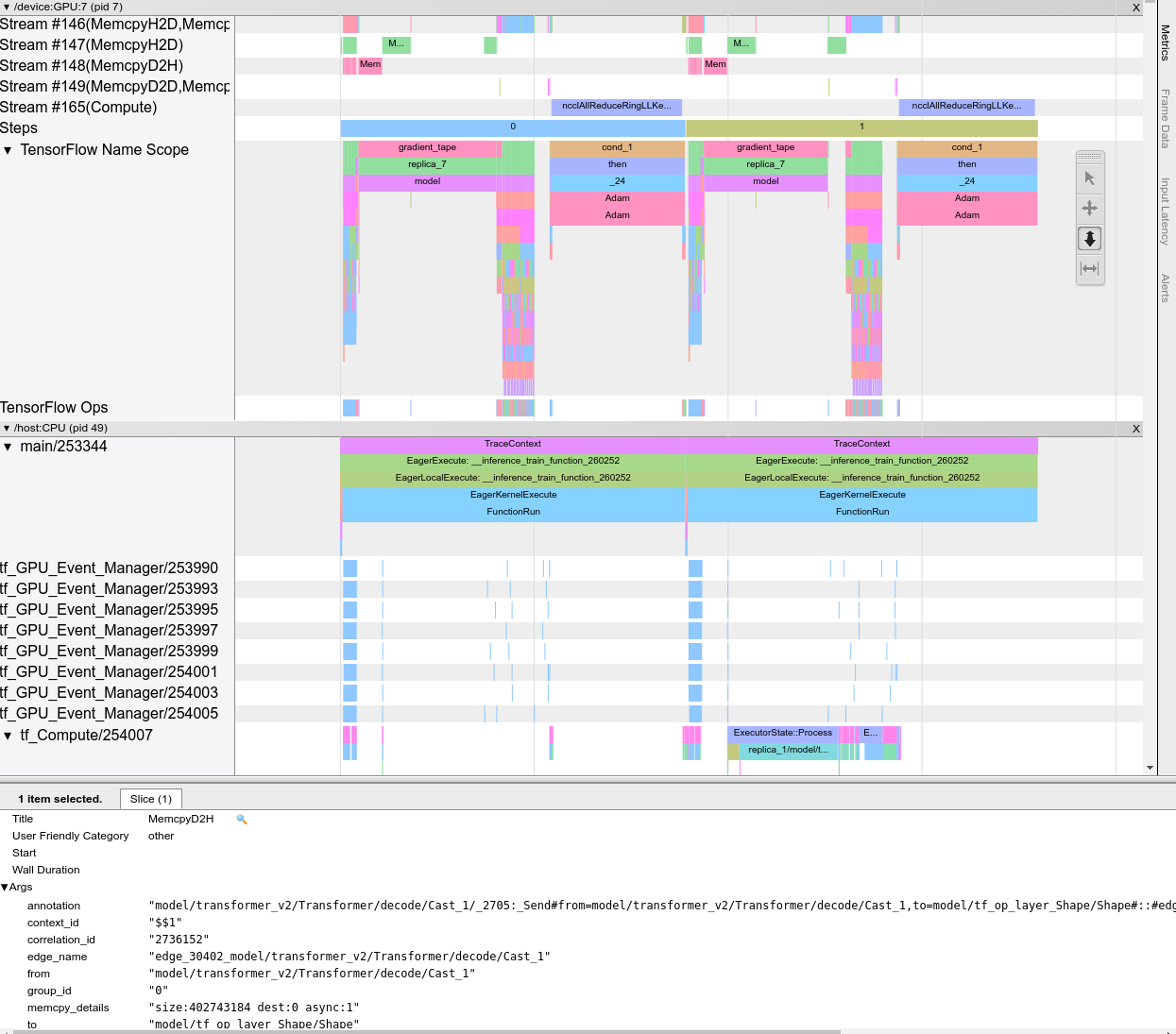
Этот экран содержит следующие основные элементы:
- Панель временной шкалы : показывает операции, выполненные устройством и хостом с течением времени.
- Панель сведений : отображает дополнительную информацию для операций, выбранных на панели «Временная шкала».
Панель «Таймлайн» содержит следующие элементы:
- Верхняя панель : содержит различные вспомогательные элементы управления.
- Ось времени : показывает время относительно начала трассы.
- Метки разделов и дорожек : каждый раздел содержит несколько дорожек и имеет треугольник слева, который можно щелкнуть, чтобы развернуть или свернуть раздел. Для каждого обрабатывающего элемента в системе имеется один раздел.
- Селектор инструментов : содержит различные инструменты для взаимодействия со средством просмотра трасс, такие как масштабирование, панорамирование, выбор и синхронизация. Используйте инструмент «Время», чтобы отметить временной интервал.
- События : они показывают время, в течение которого выполнялась операция, или продолжительность метасобытий, таких как этапы обучения.
Разделы и треки
Средство просмотра трассировки содержит следующие разделы:
- Один раздел для каждого узла устройства , помеченный номером чипа устройства и узла устройства внутри чипа (например,
/device:GPU:0 (pid 0)). Каждый раздел узла устройства содержит следующие треки:- Шаг : показывает продолжительность этапов обучения, которые выполнялись на устройстве.
- TensorFlow Ops : показывает операции, выполненные на устройстве.
- XLA Ops : показывает операции XLA (операции), которые выполнялись на устройстве, если XLA является используемым компилятором (каждая операция TensorFlow преобразуется в одну или несколько операций XLA. Компилятор XLA преобразует операции XLA в код, который выполняется на устройстве).
- Один раздел для потоков, выполняемых на процессоре хост-машины, с надписью «Host Threads» . Раздел содержит по одной дорожке для каждого потока ЦП. Обратите внимание, что вы можете игнорировать информацию, отображаемую рядом с метками разделов.
События
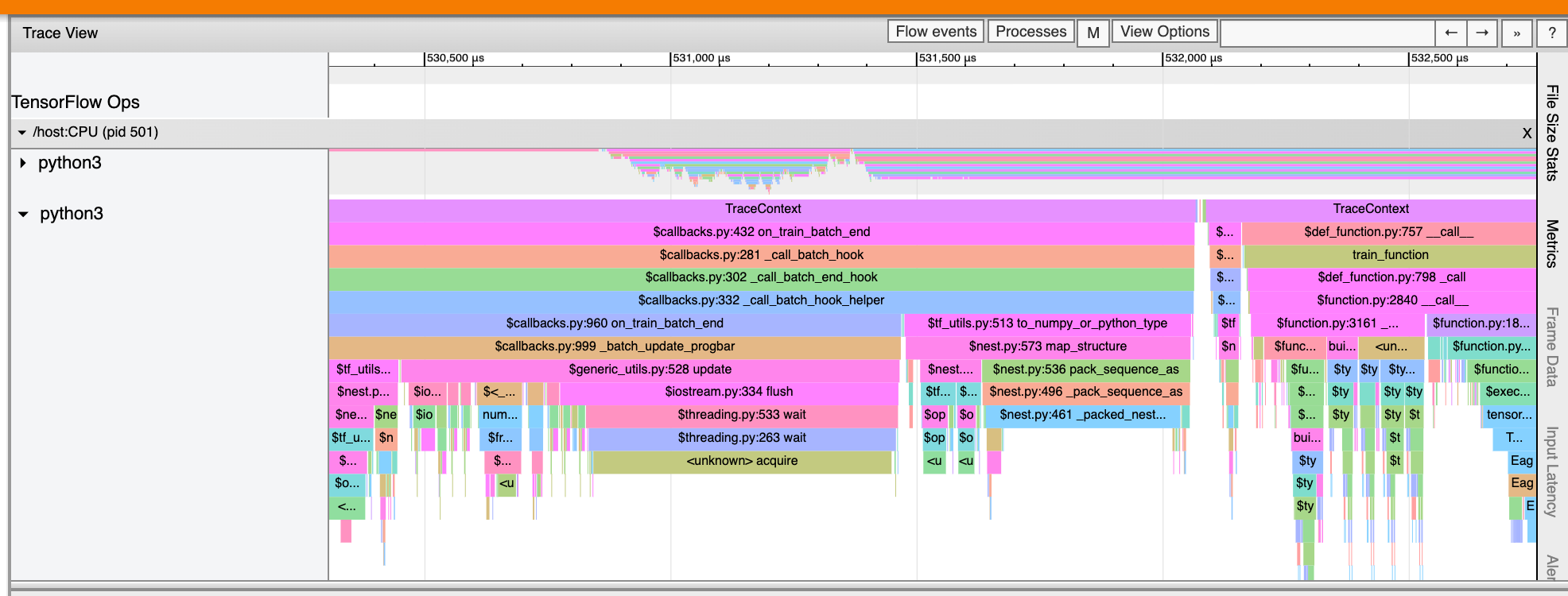
События на временной шкале отображаются разными цветами; сами цвета не имеют конкретного значения.
Средство просмотра трассировки также может отображать трассировки вызовов функций Python в вашей программе TensorFlow. Если вы используете API tf.profiler.experimental.start , вы можете включить трассировку Python, используя ProfilerOptions с именемnametuple при запуске профилирования. Альтернативно, если вы используете режим выборки для профилирования, вы можете выбрать уровень трассировки, используя раскрывающиеся параметры в диалоговом окне «Захват профиля» .
Статистика ядра графического процессора
Этот инструмент показывает статистику производительности и исходную операцию для каждого ядра с графическим ускорением.
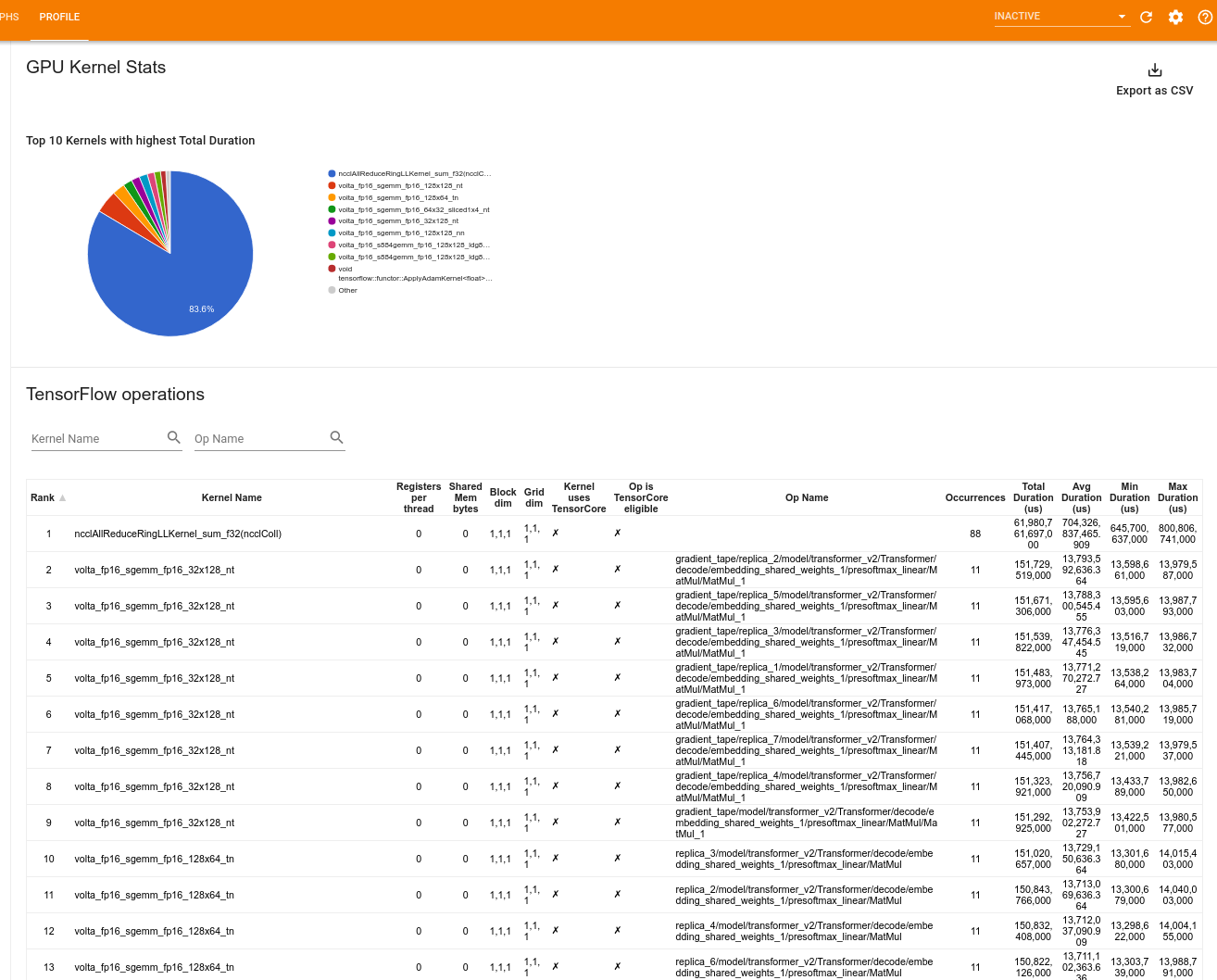
Инструмент отображает информацию на двух панелях:
В верхней панели отображается круговая диаграмма, на которой показаны ядра CUDA с наибольшим затраченным временем.
В нижней панели отображается таблица со следующими данными для каждой уникальной пары ядро-операция:
- Ранг в порядке убывания общего затраченного времени работы графического процессора, сгруппированного по паре операций ядра.
- Имя запущенного ядра.
- Количество регистров графического процессора, используемых ядром.
- Общий размер общей (статической + динамической) памяти, используемой в байтах.
- Размерность блока, выраженная как
blockDim.x, blockDim.y, blockDim.z. - Размеры сетки выражаются какgridDim.x
gridDim.x, gridDim.y, gridDim.z. - Имеет ли оператор право использовать тензорные ядра .
- Содержит ли ядро инструкции Tensor Core.
- Имя операции, запустившей это ядро.
- Число вхождений этой пары ядро-операция.
- Общее затраченное время графического процессора в микросекундах.
- Среднее затраченное время графического процессора в микросекундах.
- Минимальное затраченное время графического процессора в микросекундах.
- Максимальное затраченное время графического процессора в микросекундах.
Инструмент профиля памяти
Инструмент «Профиль памяти» отслеживает использование памяти вашего устройства в течение интервала профилирования. Вы можете использовать этот инструмент, чтобы:
- Отладка проблем нехватки памяти (OOM) путем определения пикового использования памяти и соответствующего выделения памяти для операций TensorFlow. Вы также можете отладить проблемы OOM, которые могут возникнуть при выполнении вывода мультиарендности .
- Отладка проблем с фрагментацией памяти.
Инструмент профиля памяти отображает данные в трех разделах:
- Сводка профиля памяти
- График временной шкалы памяти
- Таблица распределения памяти
Сводка профиля памяти
В этом разделе отображается общая сводка профиля памяти вашей программы TensorFlow, как показано ниже:
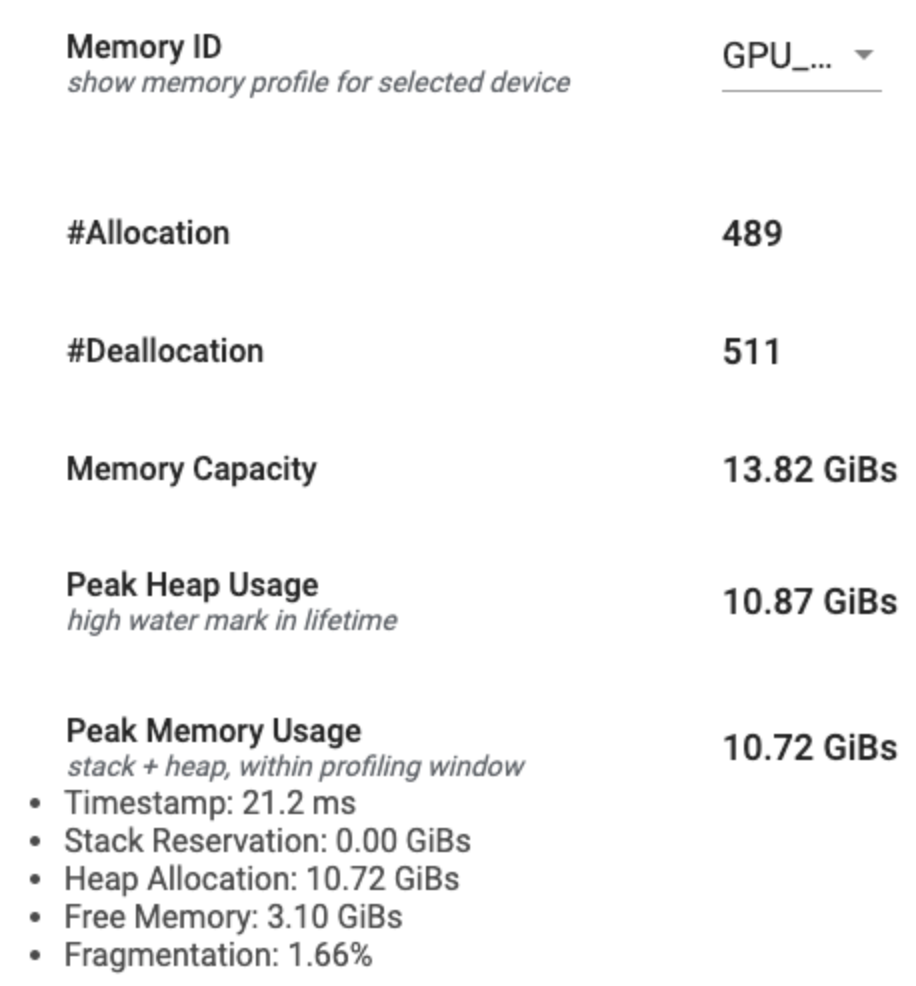
Сводная информация о профиле памяти состоит из шести полей:
- Идентификатор памяти : раскрывающийся список, в котором перечислены все доступные системы памяти устройства. В раскрывающемся списке выберите систему памяти, которую хотите просмотреть.
- #Allocation : количество выделений памяти, выполненных за интервал профилирования.
- #Deallocation : количество освобождений памяти за интервал профилирования.
- Емкость памяти : общая емкость (в ГиБ) выбранной вами системы памяти.
- Пиковое использование кучи : пиковое использование памяти (в ГиБах) с момента запуска модели.
- Пиковое использование памяти : пиковое использование памяти (в ГиБах) в интервале профилирования. Это поле содержит следующие подполя:
- Временная метка : временная отметка, когда на графике временной шкалы произошло пиковое использование памяти.
- Резервирование стека : объем памяти, зарезервированный в стеке (в ГиБ).
- Распределение кучи : объем памяти, выделенной в куче (в ГиБ).
- Свободная память : объем свободной памяти (в ГиБ). Емкость памяти — это сумма резервирования стека, распределения кучи и свободной памяти.
- Фрагментация : процент фрагментации (чем ниже, тем лучше). Он рассчитывается в процентах
(1 - Size of the largest chunk of free memory / Total free memory).
График временной шкалы памяти
В этом разделе отображается график использования памяти (в ГиБ) и процент фрагментации в зависимости от времени (в мс).
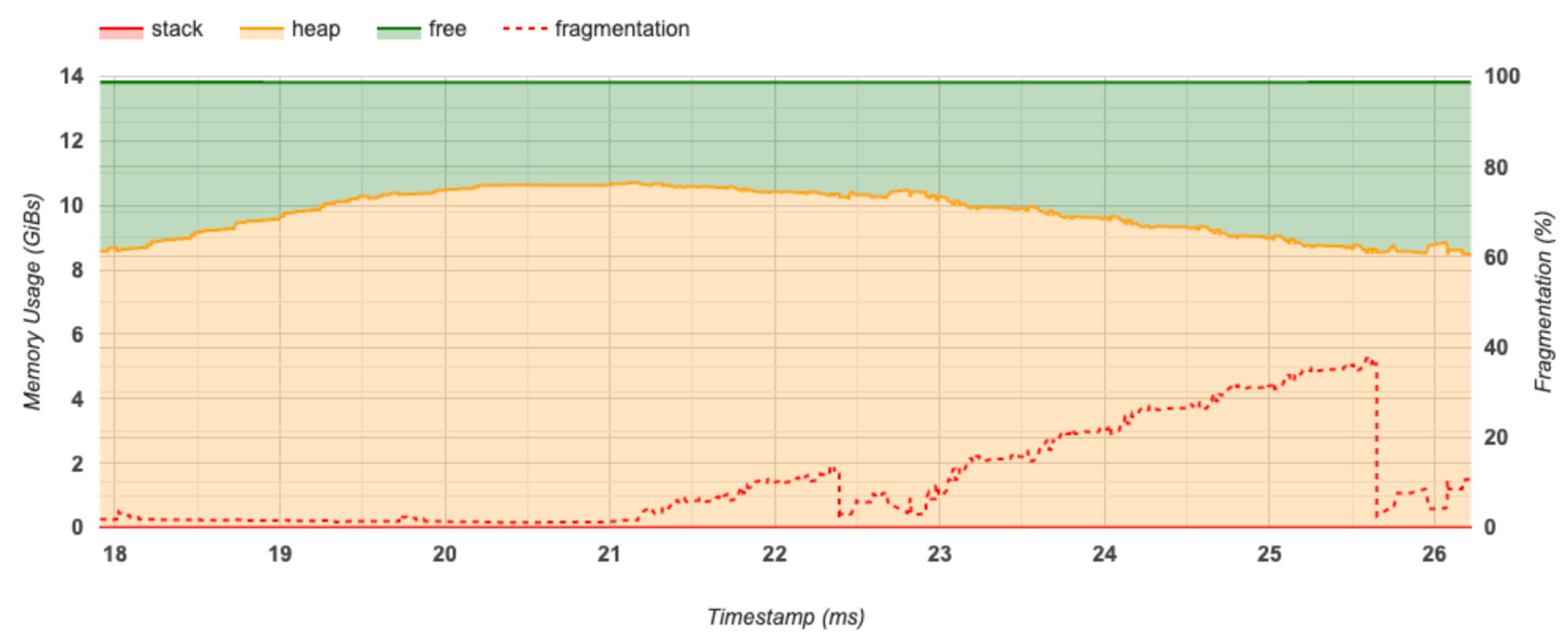
Ось X представляет временную шкалу (в мс) интервала профилирования. Ось Y слева представляет использование памяти (в ГиБ), а ось Y справа представляет процент фрагментации. В каждый момент времени по оси X общий объем памяти разбивается на три категории: стек (красный), куча (оранжевый) и свободный (зеленый). Наведите указатель мыши на определенную отметку времени, чтобы просмотреть подробную информацию о событиях выделения/освобождения памяти в этот момент, как показано ниже:
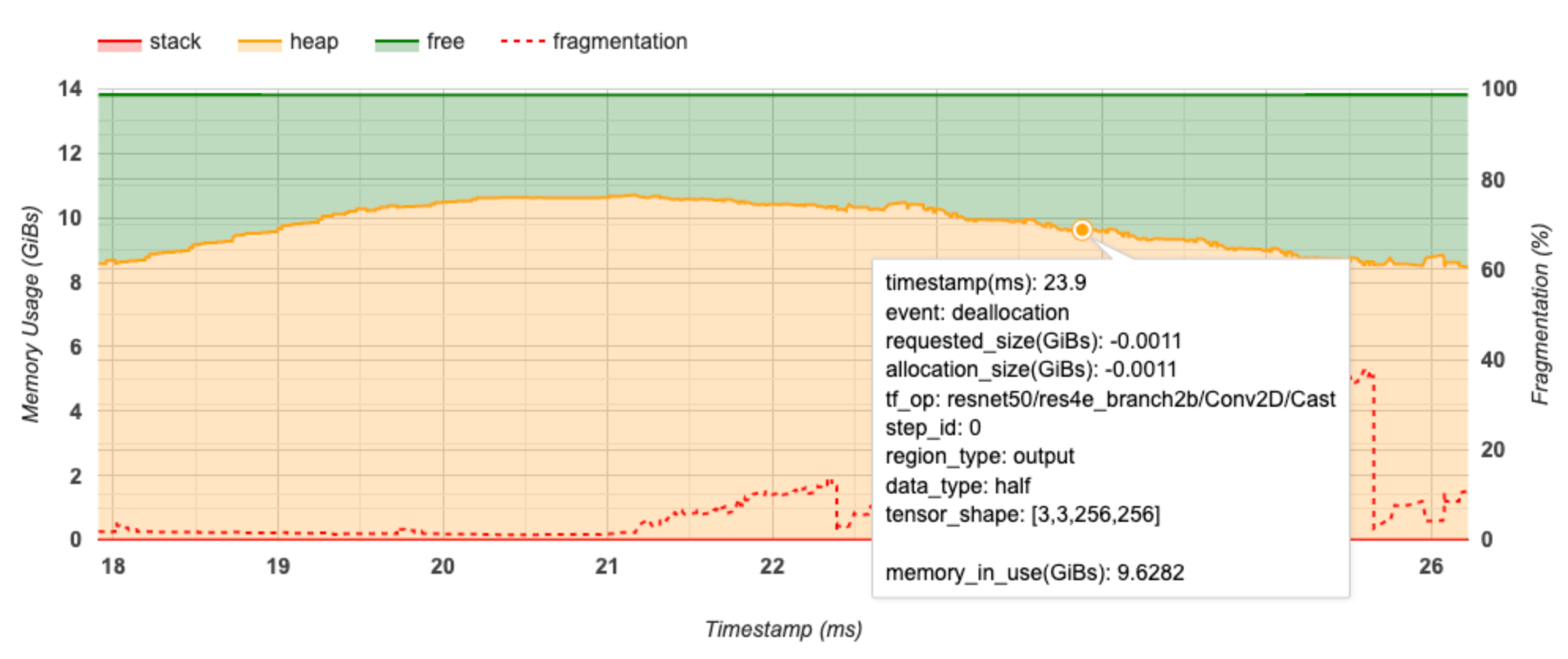
Во всплывающем окне отображается следующая информация:
- timestamp(ms) : Местоположение выбранного события на временной шкале.
- событие : тип события (выделение или освобождение).
- Request_size(GiBs) : запрошенный объем памяти. Это будет отрицательное число для событий освобождения.
- location_size(GiBs) : фактический объем выделенной памяти. Это будет отрицательное число для событий освобождения.
- tf_op : операция TensorFlow, которая запрашивает выделение/освобождение.
- Step_id : шаг обучения, на котором произошло это событие.
- Region_type : тип объекта данных, для которого предназначена эта выделенная память. Возможные значения:
tempдля временных объектов,outputдля активаций и градиентов иpersist/dynamicдля весов и констант. - data_type : тип тензорного элемента (например, uint8 для 8-битного целого числа без знака).
- tensor_shape : форма выделяемого/освобождаемого тензора.
- Memory_in_use(GiBs) : общий объем памяти, используемый в данный момент.
Таблица распределения памяти
В этой таблице показано выделение активной памяти в момент пикового использования памяти в интервале профилирования.
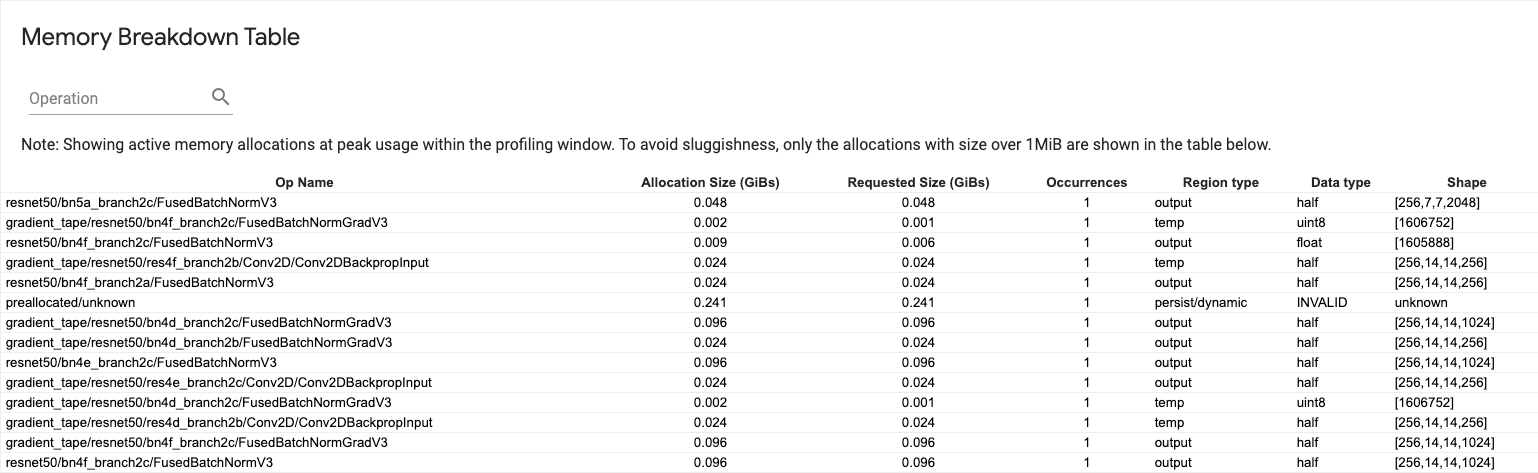
Для каждой операции TensorFlow имеется одна строка, и каждая строка имеет следующие столбцы:
- Имя операции : имя операции TensorFlow.
- Размер выделения (ГиБ) : общий объем памяти, выделенный для этой операции.
- Запрошенный размер (ГиБ) : общий объем памяти, запрошенный для этой операции.
- Вхождения : количество выделений для этой операции.
- Тип региона : тип объекта данных, для которого предназначена эта выделенная память. Возможные значения:
tempдля временных объектов,outputдля активаций и градиентов иpersist/dynamicдля весов и констант. - Тип данных : тип тензорного элемента.
- Форма : Форма выделенных тензоров.
Средство просмотра модулей
Инструмент Pod Viewer показывает разбивку этапов обучения для всех работников.
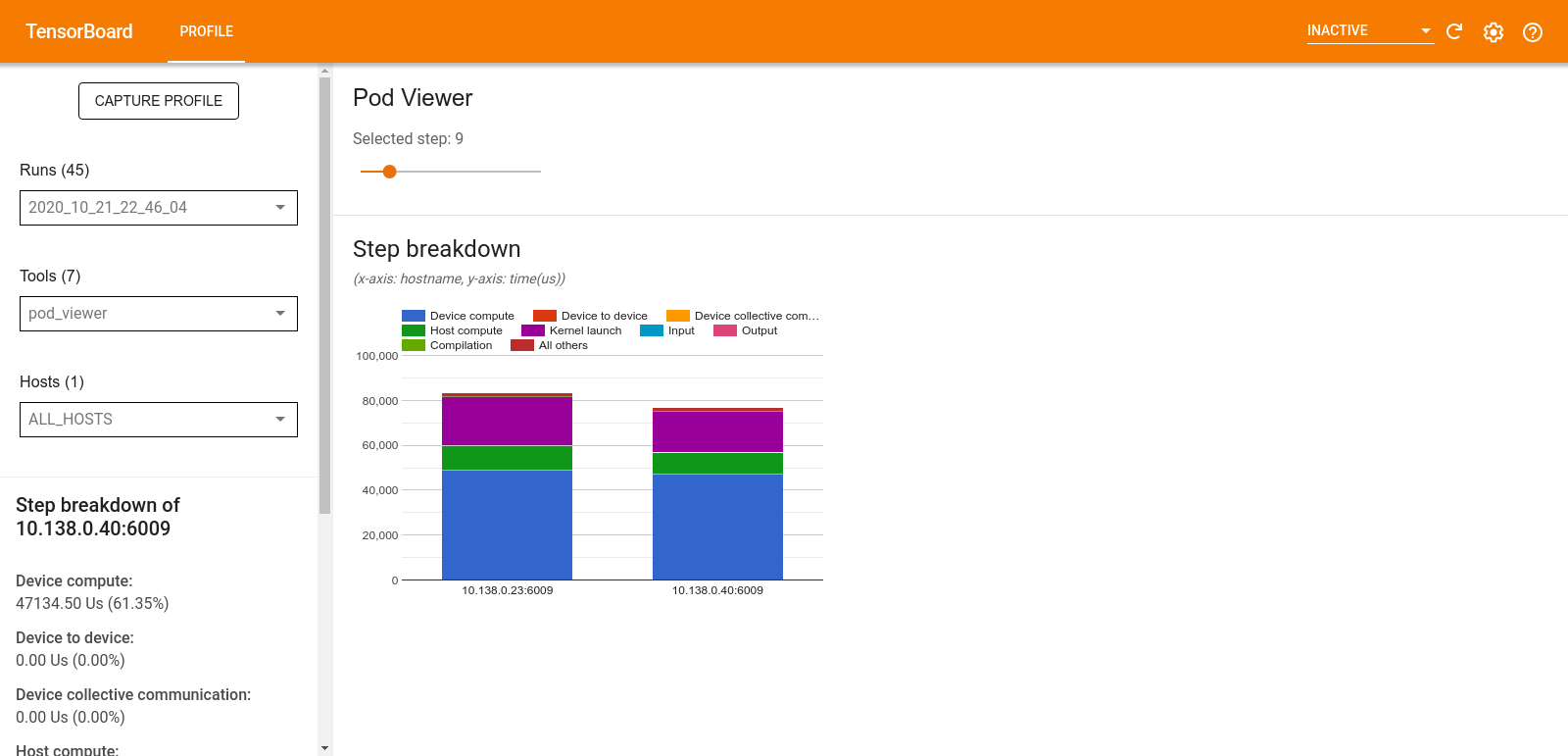
- В верхней панели имеется ползунок для выбора номера шага.
- В нижней панели отображается столбчатая диаграмма с накоплением. Это высокоуровневое представление разбитых категорий времени шага, расположенных друг над другом. Каждый столбец с накоплением представляет собой уникального работника.
- При наведении курсора на составной столбец на карточке слева отображается более подробная информация о разбивке по шагам.
анализ узких мест tf.data
Инструмент анализа узких мест tf.data автоматически обнаруживает узкие места во входных конвейерах tf.data в вашей программе и предоставляет рекомендации по их устранению. Он работает с любой программой, использующей tf.data независимо от платформы (ЦП/ГП/ТПУ). Его анализ и рекомендации основаны на этом руководстве .
Он обнаруживает узкое место, выполнив следующие действия:
- Найдите хост с наибольшим количеством входных данных.
- Найдите самое медленное выполнение входного конвейера
tf.data. - Восстановите граф входного конвейера из трассировки профилировщика.
- Найдите критический путь в графе входного конвейера.
- Определите самое медленное преобразование на критическом пути как узкое место.
Пользовательский интерфейс разделен на три раздела: «Сводка анализа производительности» , «Сводка всех входных конвейеров» и «График входного конвейера» .
Сводка анализа производительности

В этом разделе представлена сводка анализа. Он сообщает о медленных входных конвейерах tf.data , обнаруженных в профиле. В этом разделе также показан хост с наибольшим количеством входных данных и его самый медленный входной конвейер с максимальной задержкой. Самое главное — он определяет, какая часть входного конвейера является узким местом и как это исправить. Информация об узких местах предоставляется с помощью типа итератора и его длинного имени.
Как прочитать длинное имя итератора tf.data
Длинное имя форматируется как Iterator::<Dataset_1>::...::<Dataset_n> . В длинном имени <Dataset_n> соответствует типу итератора, а другие наборы данных в длинном имени представляют последующие преобразования.
Например, рассмотрим следующий набор данных входного конвейера:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Длинные имена итераторов из приведенного выше набора данных будут:
| Тип итератора | Длинное имя |
|---|---|
| Диапазон | Итератор::Batch::Repeat::Map::Range |
| Карта | Итератор::Batch::Repeat::Map |
| Повторить | Итератор::Пакет::Повторить |
| Партия | Итератор::Пакет |
Сводка всех входных конвейеров
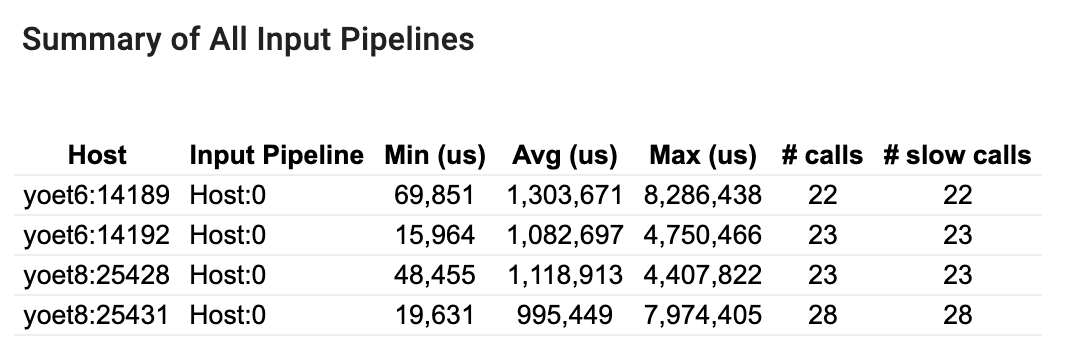
В этом разделе представлена сводная информация обо всех входных конвейерах на всех хостах. Обычно имеется один входной конвейер. При использовании стратегии распределения имеется один входной конвейер хоста, выполняющий код программы tf.data , и несколько входных конвейеров устройств, извлекающих данные из входного конвейера хоста и передающих их на устройства.
Для каждого входного конвейера отображается статистика времени его выполнения. Вызов считается медленным, если он длится более 50 мкс.
График входного конвейера

В этом разделе показан граф входного конвейера с информацией о времени выполнения. Вы можете использовать «Хост» и «Входной конвейер», чтобы выбрать хост и входной конвейер для просмотра. Выполнения входного конвейера сортируются по времени выполнения в порядке убывания, который вы можете выбрать с помощью раскрывающегося списка «Ранг» .
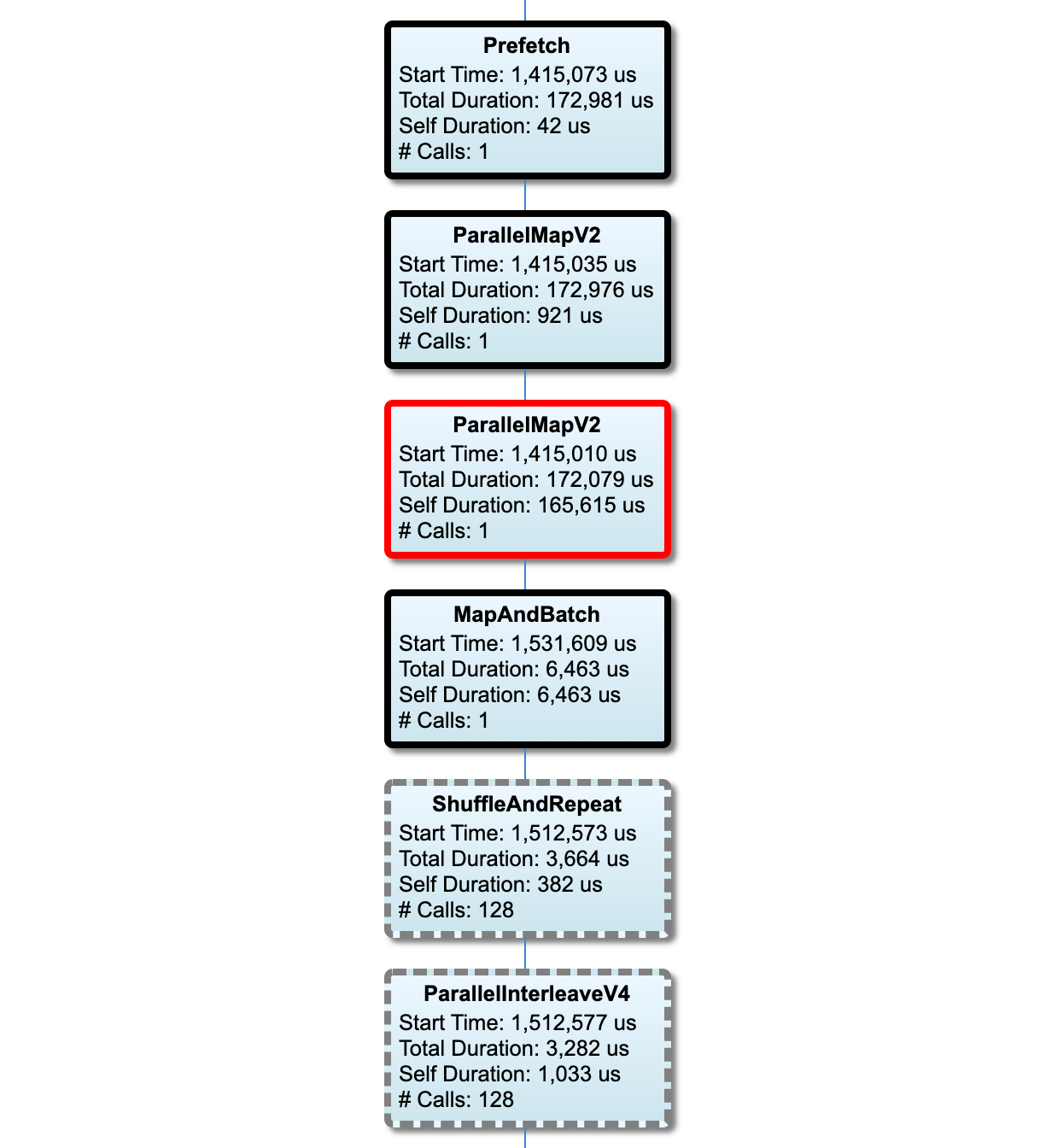
Узлы критического пути имеют жирный контур. Узел узкого места, то есть узел с самым длинным собственным временем на критическом пути, имеет красный контур. Остальные некритические узлы имеют серые пунктирные контуры.
В каждом узле Start Time указывает время начала выполнения. Один и тот же узел может выполняться несколько раз, например, если во входном конвейере есть Batch операция. Если он выполняется несколько раз, это время начала первого выполнения.
Общая длительность — это время выполнения. Если он выполняется несколько раз, это сумма времени стенок всех выполнений.
Само время — это общее время без перекрытия времени с его непосредственными дочерними узлами.
«# Вызовов» — это количество раз, когда выполняется входной конвейер.
Сбор данных о производительности
Профилировщик TensorFlow собирает действия хоста и трассировки графического процессора вашей модели TensorFlow. Вы можете настроить профилировщик для сбора данных о производительности либо в программном режиме, либо в режиме выборки.
API-интерфейсы профилирования
Для профилирования можно использовать следующие API.
Программный режим с использованием обратного вызова TensorBoard Keras (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Программный режим с использованием API функции
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Программный режим с использованием контекстного менеджера
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Режим выборки: выполните профилирование по требованию с помощью
tf.profiler.experimental.server.start, чтобы запустить сервер gRPC с запуском вашей модели TensorFlow. После запуска сервера gRPC и запуска вашей модели вы можете записать профиль с помощью кнопки «Захватить профиль» в плагине профиля TensorBoard. Используйте сценарий из раздела «Установка профилировщика» выше, чтобы запустить экземпляр TensorBoard, если он еще не запущен.В качестве примера:
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Пример профилирования нескольких работников:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
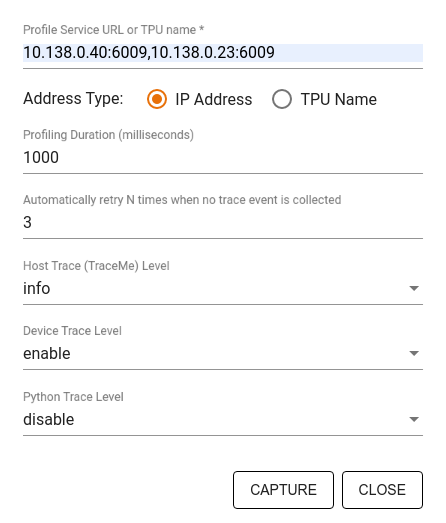
Используйте диалоговое окно «Захват профиля» , чтобы указать:
- Список URL-адресов служб профилей или имен TPU, разделенный запятыми.
- Продолжительность профилирования.
- Уровень отслеживания вызовов устройств, хостов и функций Python.
- Сколько раз вы хотите, чтобы профилировщик повторил попытку захвата профилей, если поначалу это не удалось.
Профилирование пользовательских циклов обучения
Чтобы профилировать пользовательские циклы обучения в коде TensorFlow, оснастите цикл обучения API tf.profiler.experimental.Trace , чтобы отметить границы шагов для профилировщика.
Аргумент name используется в качестве префикса для имен шагов, аргумент ключевого слова step_num добавляется к именам шагов, а аргумент ключевого слова _r заставляет это событие трассировки обрабатываться профилировщиком как событие шага.
В качестве примера:
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Это позволит профилировщику выполнять поэтапный анализ производительности и отображать события шагов в средстве просмотра трассировки.
Обязательно включите итератор набора данных в контекст tf.profiler.experimental.Trace для точного анализа входного конвейера.
Фрагмент кода ниже является антишаблоном:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Профилирование вариантов использования
Профилировщик охватывает ряд вариантов использования по четырем различным осям. Некоторые комбинации поддерживаются в настоящее время, другие будут добавлены в будущем. Некоторые из вариантов использования:
- Локальное и удаленное профилирование . Это два распространенных способа настройки среды профилирования. При локальном профилировании API профилирования вызывается на том же компьютере, на котором работает ваша модель, например на локальной рабочей станции с графическими процессорами. При удаленном профилировании API профилирования вызывается на другом компьютере, на котором выполняется ваша модель, например на облачном TPU.
- Профилирование нескольких рабочих : вы можете профилировать несколько машин при использовании возможностей распределенного обучения TensorFlow.
- Аппаратная платформа : профиль процессоров, графических процессоров и TPU.
В таблице ниже представлен краткий обзор упомянутых выше вариантов использования, поддерживаемых TensorFlow:
| API профилирования | Местный | Удаленный | Несколько работников | Аппаратные платформы |
|---|---|---|---|---|
| Обратный вызов TensorBoard Keras | Поддерживается | Не поддерживается | Не поддерживается | ЦП, графический процессор |
tf.profiler.experimental API запуска/остановки | Поддерживается | Не поддерживается | Не поддерживается | ЦП, графический процессор |
tf.profiler.experimental client.trace API | Поддерживается | Поддерживается | Поддерживается | ЦП, графический процессор, ТПУ |
| API контекстного менеджера | Поддерживается | Не поддерживается | Не поддерживается | ЦП, графический процессор |
Рекомендации по обеспечению оптимальной производительности модели
Используйте следующие рекомендации, применимые к вашим моделям TensorFlow, для достижения оптимальной производительности.
В общем, выполните все преобразования на устройстве и убедитесь, что вы используете последнюю совместимую версию библиотек, таких как cuDNN и Intel MKL, для вашей платформы.
Оптимизировать конвейер входных данных
Используйте данные из [#input_pipeline_analyzer] для оптимизации конвейера ввода данных. Эффективный конвейер ввода данных может значительно повысить скорость выполнения вашей модели за счет сокращения времени простоя устройства. Попробуйте применить лучшие практики, описанные в руководстве «Повышение производительности с помощью tf.data API» и ниже, чтобы сделать ваш конвейер ввода данных более эффективным.
В целом, распараллеливание любых операций, которые не нужно выполнять последовательно, может существенно оптимизировать конвейер ввода данных.
Во многих случаях помогает изменить порядок некоторых вызовов или настроить аргументы так, чтобы они лучше подходили для вашей модели. При оптимизации конвейера входных данных тестируйте только загрузчик данных без этапов обучения и обратного распространения ошибки, чтобы независимо оценить эффект от оптимизации.
Попробуйте запустить модель с синтетическими данными, чтобы проверить, не является ли входной конвейер узким местом производительности.
Используйте
tf.data.Dataset.shardдля обучения с несколькими графическими процессорами. Убедитесь, что вы выполняете сегментирование на самом раннем этапе цикла ввода, чтобы предотвратить снижение пропускной способности. При работе с TFRecords убедитесь, что вы сегментируете список TFRecords, а не содержимое TFRecords.Распараллельте несколько операций, динамически задав значение
num_parallel_callsс помощьюtf.data.AUTOTUNE.Рассмотрите возможность ограничения использования
tf.data.Dataset.from_generator, поскольку он медленнее по сравнению с чистыми операциями TensorFlow.Рассмотрите возможность ограничения использования
tf.py_function, поскольку она не может быть сериализована и не поддерживается для запуска в распределенном TensorFlow.Используйте
tf.data.Optionsдля управления статической оптимизацией входного конвейера.
Также прочтите руководство по анализу производительности tf.data , чтобы получить дополнительные рекомендации по оптимизации входного конвейера.
Оптимизация увеличения данных
При работе с данными изображения повысьте эффективность увеличения данных за счет приведения к различным типам данных после применения пространственных преобразований, таких как переворот, обрезка, вращение и т. д.
Используйте NVIDIA® DALI
В некоторых случаях, например, если у вас есть система с высоким соотношением графического процессора к процессору, всех вышеперечисленных оптимизаций может быть недостаточно для устранения узких мест в загрузчике данных, вызванных ограничениями циклов процессора.
Если вы используете графические процессоры NVIDIA® для приложений компьютерного зрения и глубокого обучения аудио, рассмотрите возможность использования библиотеки загрузки данных ( DALI ) для ускорения конвейера данных.
Список поддерживаемых операций DALI см. в документации NVIDIA® DALI: Operations .
Используйте многопоточность и параллельное выполнение
Запускайте операции в нескольких потоках ЦП с помощью API tf.config.threading , чтобы выполнять их быстрее.
TensorFlow автоматически устанавливает количество потоков параллелизма по умолчанию. Пул потоков, доступный для выполнения операций TensorFlow, зависит от количества доступных потоков ЦП.
Управляйте максимальным ускорением параллельного выполнения для одной операции с помощью tf.config.threading.set_intra_op_parallelism_threads . Обратите внимание: если вы запускаете несколько операций параллельно, все они будут совместно использовать доступный пул потоков.
Если у вас есть независимые неблокирующие операции (операции без направленного пути между ними на графе), используйте tf.config.threading.set_inter_op_parallelism_threads для их одновременного запуска с использованием доступного пула потоков.
Разнообразный
При работе с меньшими моделями на графических процессорах NVIDIA® вы можете установить tf.compat.v1.ConfigProto.force_gpu_compatible=True чтобы принудительно распределить все тензоры ЦП с закрепленной памятью CUDA, чтобы значительно повысить производительность модели. Однако будьте осторожны при использовании этой опции для неизвестных/очень больших моделей, поскольку это может отрицательно повлиять на производительность хоста (ЦП).
Улучшите производительность устройства
Следуйте рекомендациям, подробно описанным здесь и в руководстве по оптимизации производительности графического процессора , чтобы оптимизировать производительность модели TensorFlow на устройстве.
Если вы используете графические процессоры NVIDIA, запишите использование графического процессора и памяти в файл CSV, выполнив:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Настройка макета данных
При работе с данными, содержащими информацию о каналах (например, изображениями), оптимизируйте формат размещения данных, чтобы каналы отдавались последними (NHWC вместо NCHW).
Форматы данных последнего канала улучшают использование Tensor Core и обеспечивают значительное повышение производительности, особенно в сверточных моделях в сочетании с AMP. С макетами данных NCHW по-прежнему могут работать тензорные ядра, но это приводит к дополнительным накладным расходам из-за операций автоматического транспонирования.
Вы можете оптимизировать макет данных, чтобы отдать предпочтение макетам NHWC, установив data_format="channels_last" для таких слоев, как tf.keras.layers.Conv2D , tf.keras.layers.Conv3D и tf.keras.layers.RandomRotation .
Используйте tf.keras.backend.set_image_data_format , чтобы установить формат макета данных по умолчанию для внутреннего API Keras.
Максимально используйте кэш L2
При работе с графическими процессорами NVIDIA® перед циклом обучения выполните приведенный ниже фрагмент кода, чтобы максимально увеличить степень детализации выборки L2 до 128 байт.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Настройка использования потоков графического процессора
Режим потоков графического процессора определяет, как будут использоваться потоки графического процессора.
Установите режим потока на gpu_private чтобы гарантировать, что предварительная обработка не крадет все потоки графического процессора. Это уменьшит задержку запуска ядра во время обучения. Вы также можете установить количество потоков на GPU. Установите эти значения, используя переменные среды.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Настройка параметров памяти графических процессоров
В общем, увеличьте размер партии и масштабируйте модель, чтобы лучше использовать графические процессоры и получить более высокую пропускную способность. Обратите внимание, что увеличение размера партии изменит точность модели, поэтому модель должна быть масштабирована путем настройки гиперпараметров, таких как скорость обучения, чтобы соответствовать целевой точности.
Кроме того, используйте tf.config.experimental.set_memory_growth чтобы позволить графическим памяти расти, чтобы предотвратить полное распределение всей доступной памяти на OPS, которая требует лишь доли памяти. Это позволяет другим процессам, которые потребляют память графических процессоров для работы на одном устройстве.
Чтобы узнать больше, ознакомьтесь с ограничивающим руководством по росту памяти графического процессора в руководстве по графическим процессорам, чтобы узнать больше.
Разнообразный
Увеличьте учебную мини-размер (количество обучающих образцов, используемых на устройство, в одной итерации обучающего цикла) до максимального количества, которое подходит без ошибки вне памяти (OOM) на GPU. Увеличение размера партии воздействует на точность модели - так что убедитесь, что вы масштабируете модель, настраивая гиперпараметры, чтобы соответствовать целевой точности.
Отключить ошибки отчетности во время распределения тензора в производственном коде. Установить
report_tensor_allocations_upon_oom=Falseвtf.compat.v1.RunOptions.Для моделей со слоями свертки удалите добавление смещения при использовании нормализации партии. Нормализация пакетов смещает значения на их среднее значение, и это устраняет необходимость иметь постоянный термин смещения.
Используйте статистику TF, чтобы выяснить, насколько эффективно работают OPS.
Используйте
tf.functionдля выполнения вычислений и, необязательно, включитеjit_compile=Trueflag (tf.function(jit_compile=True). Чтобы узнать больше, перейдите, чтобы использовать xla tf.function .Минимизируйте операции Python в хосте между шагами и уменьшите обратные вызовы. Рассчитайте метрики каждые несколько шагов, а не на каждом шаге.
Держите устройство, вычислительные подразделения заняты.
Отправьте данные на несколько устройств параллельно.
Рассмотрим использование 16-битных численных представлений , таких как
fp16-формат с плавающей запятой полуопределением, указанный IEEE-или формат BFLOAT16 с плавающей точкой.
Дополнительные ресурсы
- Tensorflow Profiler: Model Model Reliem с керами и Tensorboard, где вы можете применить советы в этом руководстве.
- Профилирование производительности в Tensorflow 2 разговоры с Tensorflow Dev Summit 2020.
- Демонстрация Tensorflow Profiler от Tensorflow Dev Summit 2020.
Известные ограничения
Профилирование нескольких графических процессоров на Tensorflow 2.2 и Tensorflow 2.3
Tensorflow 2.2 и 2.3 поддерживают несколько профилирования графических процессоров только для отдельных систем хоста; Многочисленное профилирование графических процессоров для систем с несколькими хостами не поддерживается. Чтобы профилировать конфигурации графических процессоров с несколькими работниками, каждый работник должен быть представлен независимо. Из TensorFlow 2.4 несколько работников могут быть профилированы с использованием tf.profiler.experimental.client.trace API.
CUDA® Toolkit 10.2 или более поздний цвет требуется для профила нескольких графических процессоров. Поскольку TensorFlow 2.2 и 2.3 поддерживают версии Cuda® Toolkit только до 10,1, вам необходимо создать символические ссылки на libcudart.so.10.1 и libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1