
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
В этом руководстве демонстрируется увеличение данных: метод увеличения разнообразия обучающей выборки путем применения случайных (но реалистичных) преобразований, таких как поворот изображения.
Вы узнаете, как применять увеличение данных двумя способами:
- Используйте слои предварительной обработки Keras, такие как
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlipиtf.keras.layers.RandomRotation. - Используйте методы
tf.image, такие какtf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_cropиtf.image.stateless_random*.
Настраивать
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Скачать набор данных
В этом руководстве используется набор данных tf_flowers . Для удобства загрузите набор данных с помощью TensorFlow Datasets . Если вы хотите узнать о других способах импорта данных, ознакомьтесь с руководством по загрузке изображений .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Набор данных цветов имеет пять классов.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Давайте извлечем изображение из набора данных и используем его для демонстрации увеличения данных.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Используйте слои предварительной обработки Keras
Изменение размера и масштабирование
Вы можете использовать слои предварительной обработки Keras для изменения размера изображений до постоянной формы (с помощью tf.keras.layers.Resizing ) и для изменения значений пикселей (с помощью tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
Вы можете визуализировать результат применения этих слоев к изображению.
result = resize_and_rescale(image)
_ = plt.imshow(result)
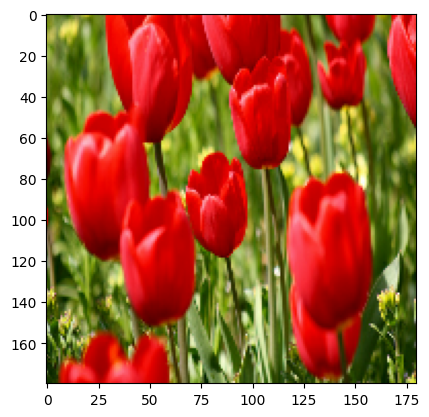
Убедитесь, что пиксели находятся в диапазоне [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Увеличение данных
Вы также можете использовать слои предварительной обработки Keras для увеличения данных, такие как tf.keras.layers.RandomFlip и tf.keras.layers.RandomRotation .
Давайте создадим несколько слоев предварительной обработки и применим их несколько раз к одному и тому же изображению.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Существует множество слоев предварительной обработки, которые вы можете использовать для увеличения данных, включая tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom и другие.
Два варианта использования слоев предварительной обработки Keras
Есть два способа использования этих слоев предварительной обработки с важными компромиссами.
Вариант 1. Сделайте слои предварительной обработки частью вашей модели.
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
В этом случае нужно знать два важных момента:
Расширение данных будет выполняться на устройстве синхронно с остальными слоями и получит ускорение графического процессора.
Когда вы экспортируете свою модель с помощью
model.save, слои предварительной обработки будут сохранены вместе с остальной частью вашей модели. Если вы позже развернете эту модель, она автоматически стандартизирует изображения (в соответствии с конфигурацией ваших слоев). Это может избавить вас от необходимости заново реализовывать эту логику на стороне сервера.
Вариант 2. Примените слои предварительной обработки к вашему набору данных.
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
При таком подходе вы используете Dataset.map для создания набора данных, который дает пакеты дополненных изображений. В таком случае:
- Увеличение данных будет происходить асинхронно на ЦП и не блокируется. Вы можете совместить обучение вашей модели на графическом процессоре с предварительной обработкой данных, используя
Dataset.prefetch, как показано ниже. - В этом случае слои предварительной обработки не будут экспортированы вместе с моделью при вызове
Model.save. Вам нужно будет прикрепить их к вашей модели перед ее сохранением или повторной реализацией на стороне сервера. После обучения вы можете прикрепить слои предварительной обработки перед экспортом.
Вы можете найти пример первого варианта в учебнике по классификации изображений . Давайте продемонстрируем здесь второй вариант.
Применение слоев предварительной обработки к наборам данных
Настройте наборы данных для обучения, проверки и тестирования с помощью созданных ранее слоев предварительной обработки Keras. Вы также настроите наборы данных для повышения производительности, используя параллельное чтение и буферизованную предварительную выборку, чтобы получать пакеты с диска без блокировки ввода-вывода. (Узнайте больше о производительности наборов данных в руководстве по повышению производительности с помощью API tf.data .)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
Обучить модель
Для полноты теперь вы будете обучать модель, используя только что подготовленные наборы данных.
Последовательная модель состоит из трех блоков свертки ( tf.keras.layers.Conv2D ) с максимальным объединяющим слоем ( tf.keras.layers.MaxPooling2D ) в каждом из них. Существует полносвязный слой ( tf.keras.layers.Dense ) со 128 единицами поверх него, который активируется функцией активации ReLU ( 'relu' ). Эта модель не была настроена на точность (цель — показать вам механику).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Выберите оптимизатор tf.keras.optimizers.Adam и функцию потерь tf.keras.losses.SparseCategoricalCrossentropy . Чтобы просмотреть точность обучения и проверки для каждой эпохи обучения, передайте аргумент metrics в Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Поезд на несколько эпох:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Расширение пользовательских данных
Вы также можете создавать пользовательские слои дополнения данных.
В этом разделе руководства показаны два способа сделать это:
- Сначала вы создадите слой
tf.keras.layers.Lambda. Это хороший способ написать лаконичный код. - Далее вы напишете новый слой с помощью подкласса , что даст вам больше контроля.
Оба слоя будут случайным образом инвертировать цвета изображения с некоторой вероятностью.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

Затем реализуйте пользовательский слой путем создания подкласса :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Оба этих слоя можно использовать, как описано в вариантах 1 и 2 выше.
Использование tf.image
Вышеупомянутые утилиты предварительной обработки Keras удобны. Но для более точного контроля вы можете написать свои собственные конвейеры или слои увеличения данных, используя tf.data и tf.image . (Вы также можете ознакомиться с TensorFlow Addons Image: Operations и TensorFlow I/O: Color Space Conversions .)
Поскольку набор данных цветов ранее был настроен с увеличением данных, давайте повторно импортируем его, чтобы начать заново:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Получить изображение для работы:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Давайте воспользуемся следующей функцией для визуализации и сравнения исходного и дополненного изображений:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Увеличение данных
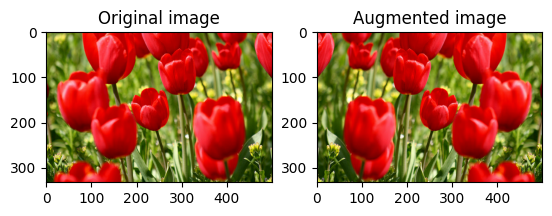
Перевернуть изображение
Переверните изображение по вертикали или по горизонтали с помощью tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
Оттенки серого изображения
Вы можете сделать изображение в градациях серого с помощью tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

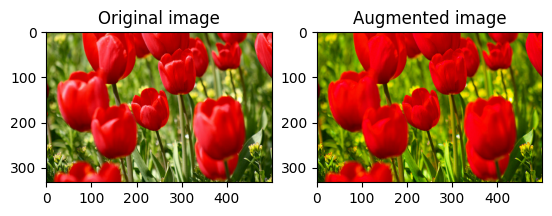
Насыщение изображения
Насыщайте изображение с помощью tf.image.adjust_saturation , указав коэффициент насыщения:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
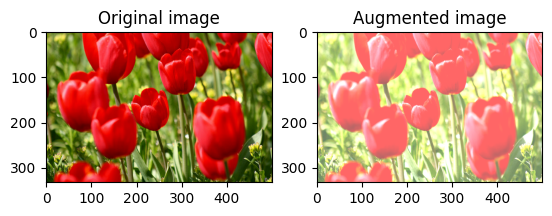
Изменить яркость изображения
Измените яркость изображения с помощью tf.image.adjust_brightness , указав коэффициент яркости:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
Обрезать изображение по центру
Обрежьте изображение от центра до нужной части изображения, используя tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
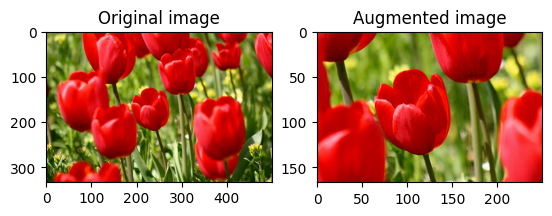
Повернуть изображение
Поверните изображение на 90 градусов с помощью tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

Случайные преобразования
Применение случайных преобразований к изображениям может дополнительно помочь обобщить и расширить набор данных. Текущий API tf.image предоставляет восемь таких случайных операций с изображениями (ops):
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Эти операции со случайными изображениями чисто функциональны: результат зависит только от ввода. Это упрощает их использование в высокопроизводительных детерминированных конвейерах ввода. Они требуют ввода seed значения на каждом шаге. Имея одно и то же seed значение, они возвращают одни и те же результаты независимо от того, сколько раз они вызываются.
В следующих разделах вы:
- Просмотрите примеры использования операций со случайными изображениями для преобразования изображения.
- Продемонстрируйте, как применять случайные преобразования к обучающему набору данных.
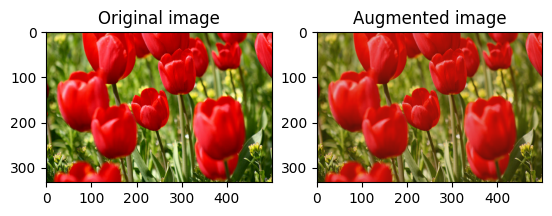
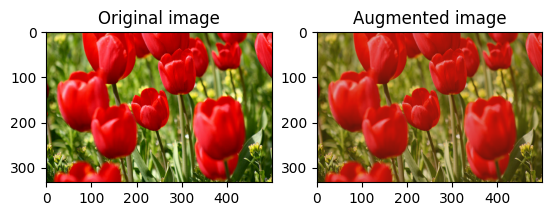
Случайное изменение яркости изображения
Произвольно измените яркость image с помощью tf.image.stateless_random_brightness , указав коэффициент яркости и seed значение. Коэффициент яркости выбирается случайным образом в диапазоне [-max_delta, max_delta) и связывается с заданным seed числом.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
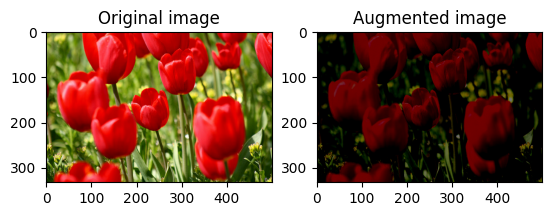
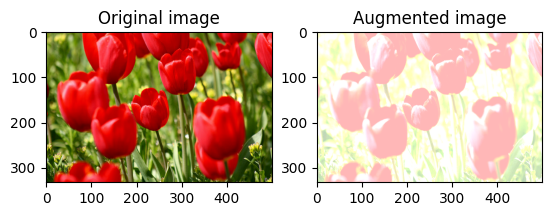
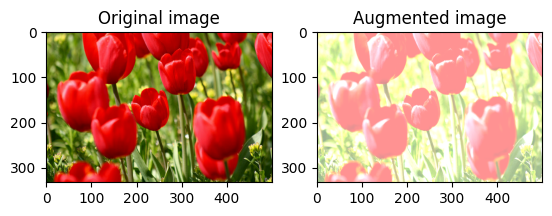
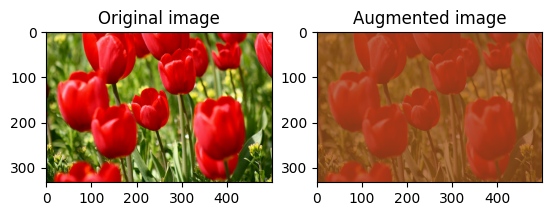
Произвольное изменение контраста изображения
Случайным образом измените контрастность image с помощью tf.image.stateless_random_contrast , указав диапазон контрастности и seed значение. Диапазон контрастности выбирается случайным образом в интервале [lower, upper] и связывается с заданным seed .
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
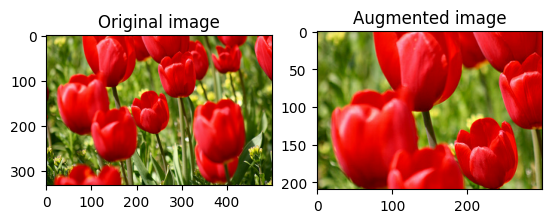
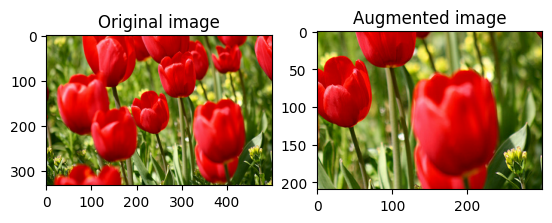
Случайно обрезать изображение
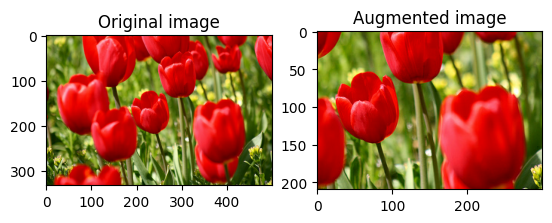
Случайно обрезать image с помощью tf.image.stateless_random_crop , указав целевой size и seed значение. Часть image , которая обрезается, находится со случайно выбранным смещением и связана с заданным seed .
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
Применение дополнения к набору данных
Давайте сначала снова загрузим набор данных изображений на случай, если они были изменены в предыдущих разделах.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Затем определите вспомогательную функцию для изменения размера и масштабирования изображений. Эта функция будет использоваться для унификации размера и масштаба изображений в наборе данных:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Давайте также определим функцию augment , которая может применять случайные преобразования к изображениям. Эта функция будет использоваться для набора данных на следующем шаге.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Вариант 1: Использование tf.data.experimental.Counter
Создайте объект tf.data.experimental.Counter (назовем его counter ) и Dataset.zip набор данных с помощью (counter, counter) . Это гарантирует, что каждое изображение в наборе данных будет связано с уникальным значением (формы (2,) ) на основе counter , который позже может быть передан в функцию augment в качестве seed значения для случайных преобразований.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
Сопоставьте функцию augment с обучающим набором данных:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Вариант 2: Использование tf.random.Generator
- Создайте объект
tf.random.Generatorс начальнымseedзначением. Вызов функцииmake_seedsдля одного и того же объекта-генератора всегда возвращает новое уникальноеseedзначение. - Определите функцию-оболочку, которая: 1) вызывает функцию
make_seeds; и 2) передает вновь сгенерированноеseedзначение в функциюaugmentдля случайных преобразований.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
Сопоставьте функцию-обертку f с обучающим набором данных, а функцию resize_and_rescale — с проверочным и тестовым наборами:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Эти наборы данных теперь можно использовать для обучения модели, как показано ранее.
Следующие шаги
В этом руководстве продемонстрировано увеличение данных с использованием слоев предварительной обработки Keras и tf.image .
- Чтобы узнать, как включить слои предварительной обработки в вашу модель, обратитесь к учебнику по классификации изображений .
- Вам также может быть интересно узнать, как слои предварительной обработки могут помочь вам классифицировать текст, как показано в учебнике по базовой классификации текста .
- Вы можете узнать больше о
tf.dataв этом руководстве , а узнать, как настроить конвейеры ввода для повышения производительности , можно здесь .