
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве показано, как загрузить и предварительно обработать набор данных изображения тремя способами:
- Во-первых, вы будете использовать высокоуровневые утилиты предварительной обработки Keras (такие как
tf.keras.utils.image_dataset_from_directory) и слои (такие какtf.keras.layers.Rescaling) для чтения каталога изображений на диске. - Далее вы напишете свой собственный входной конвейер с нуля , используя tf.data .
- Наконец, вы загрузите набор данных из большого каталога , доступного в TensorFlow Datasets .
Настраивать
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Скачать набор цветов
В этом уроке используется набор данных из нескольких тысяч фотографий цветов. Набор данных цветов содержит пять подкаталогов, по одному на класс:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
После загрузки (218 МБ) у вас должна быть доступна копия фотографий цветов. Всего 3670 изображений:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Каждый каталог содержит изображения этого типа цветов. Вот несколько роз:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Загрузить данные с помощью утилиты Keras
Давайте загрузим эти образы с диска с помощью полезной утилиты tf.keras.utils.image_dataset_from_directory .
Создать набор данных
Определите некоторые параметры для загрузчика:
batch_size = 32
img_height = 180
img_width = 180
При разработке модели рекомендуется использовать разделение проверки. Вы будете использовать 80% изображений для обучения и 20% для проверки.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Вы можете найти имена классов в атрибуте class_names в этих наборах данных.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Визуализируйте данные
Вот первые девять изображений из набора обучающих данных.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
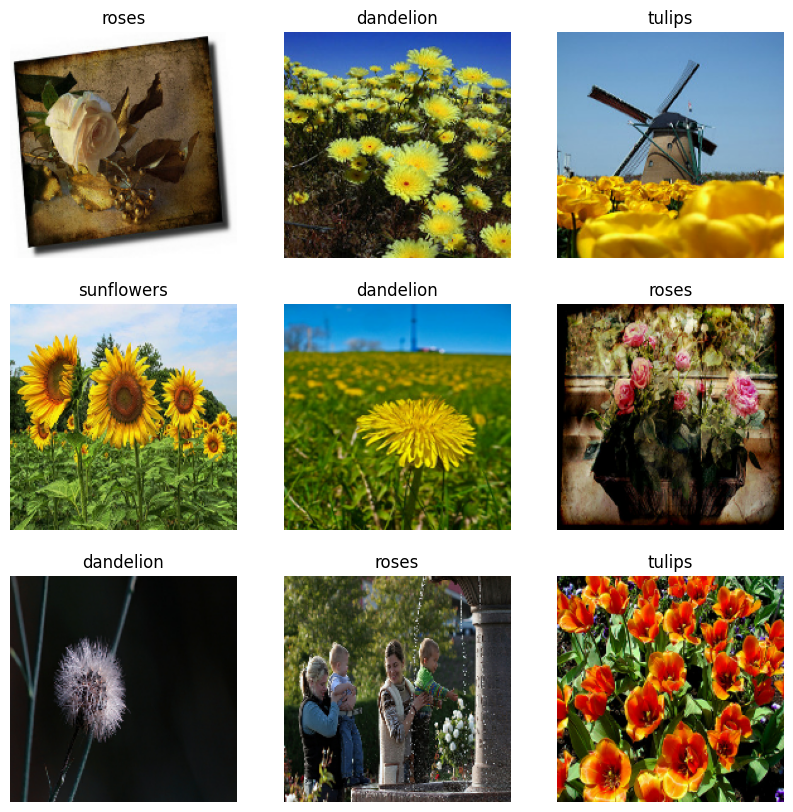
Вы можете обучить модель, используя эти наборы данных, передав их в model.fit (показано далее в этом руководстве). Если хотите, вы также можете вручную перебрать набор данных и получить пакеты изображений:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch представляет собой тензор формы (32, 180, 180, 3) . Это пакет из 32 изображений размером 180x180x3 (последний размер относится к цветовым каналам RGB). label_batch — это тензор формы (32,) , это соответствующие метки для 32 изображений.
Вы можете вызвать .numpy() для любого из этих тензоров, чтобы преобразовать их в numpy.ndarray .
Стандартизируйте данные
Значения канала RGB находятся в диапазоне [0, 255] . Это не идеально для нейронной сети; в общем, вы должны стремиться к тому, чтобы ваши входные значения были небольшими.
Здесь вы будете стандартизировать значения в диапазоне [0, 1] с помощью tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
Есть два способа использования этого слоя. Вы можете применить его к набору данных, вызвав Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
Или вы можете включить слой в определение вашей модели, чтобы упростить развертывание. Здесь вы будете использовать второй подход.
Настройте набор данных для производительности
Обязательно используйте предварительную выборку с буферизацией, чтобы вы могли получать данные с диска, не блокируя ввод-вывод. Вот два важных метода, которые вы должны использовать при загрузке данных:
-
Dataset.cacheхранит изображения в памяти после их загрузки с диска в течение первой эпохи. Это гарантирует, что набор данных не станет узким местом при обучении вашей модели. Если ваш набор данных слишком велик, чтобы поместиться в память, вы также можете использовать этот метод для создания производительного кэша на диске. -
Dataset.prefetchперекрывает предварительную обработку данных и выполнение модели во время обучения.
Заинтересованные читатели могут узнать больше об обоих методах, а также о том, как кэшировать данные на диск, в разделе Предварительная выборка руководства Повышение производительности с помощью API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Обучить модель
Для полноты вы покажете, как обучить простую модель, используя только что подготовленные наборы данных.
Последовательная модель состоит из трех блоков свертки ( tf.keras.layers.Conv2D ) с максимальным объединяющим слоем ( tf.keras.layers.MaxPooling2D ) в каждом из них. Существует полносвязный слой ( tf.keras.layers.Dense ) со 128 единицами поверх него, который активируется функцией активации ReLU ( 'relu' ). Эта модель никоим образом не настраивалась — цель состоит в том, чтобы показать вам механику с использованием только что созданных наборов данных. Чтобы узнать больше о классификации изображений, посетите учебник по классификации изображений .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
Выберите оптимизатор tf.keras.optimizers.Adam и функцию потерь tf.keras.losses.SparseCategoricalCrossentropy . Чтобы просмотреть точность обучения и проверки для каждой эпохи обучения, передайте аргумент metrics в Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Вы можете заметить, что точность проверки низка по сравнению с точностью обучения, что указывает на переоснащение вашей модели. Вы можете узнать больше о переоснащении и о том, как его уменьшить в этом уроке .
Использование tf.data для более тонкого контроля
Вышеупомянутая утилита предварительной обработки Keras — tf.keras.utils.image_dataset_from_directory — это удобный способ создать tf.data.Dataset из каталога изображений.
Для более точного контроля вы можете написать свой собственный входной конвейер, используя tf.data . В этом разделе показано, как это сделать, начиная с путей к файлам из загруженного ранее файла TGZ.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
Древовидную структуру файлов можно использовать для составления списка class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Разделите набор данных на наборы для обучения и проверки:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
Вы можете распечатать длину каждого набора данных следующим образом:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Напишите короткую функцию, которая преобразует путь к файлу в пару (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
Используйте Dataset.map для создания набора данных пар image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Настройка набора данных для повышения производительности
Чтобы обучить модель с этим набором данных, вам понадобятся данные:
- Чтобы хорошо перетасовать.
- Для пакетирования.
- Партии должны быть доступны как можно скорее.
Эти функции можно добавить с помощью API tf.data . Дополнительные сведения см. в руководстве по производительности входного конвейера .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
Визуализируйте данные
Вы можете визуализировать этот набор данных аналогично тому, который вы создали ранее:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
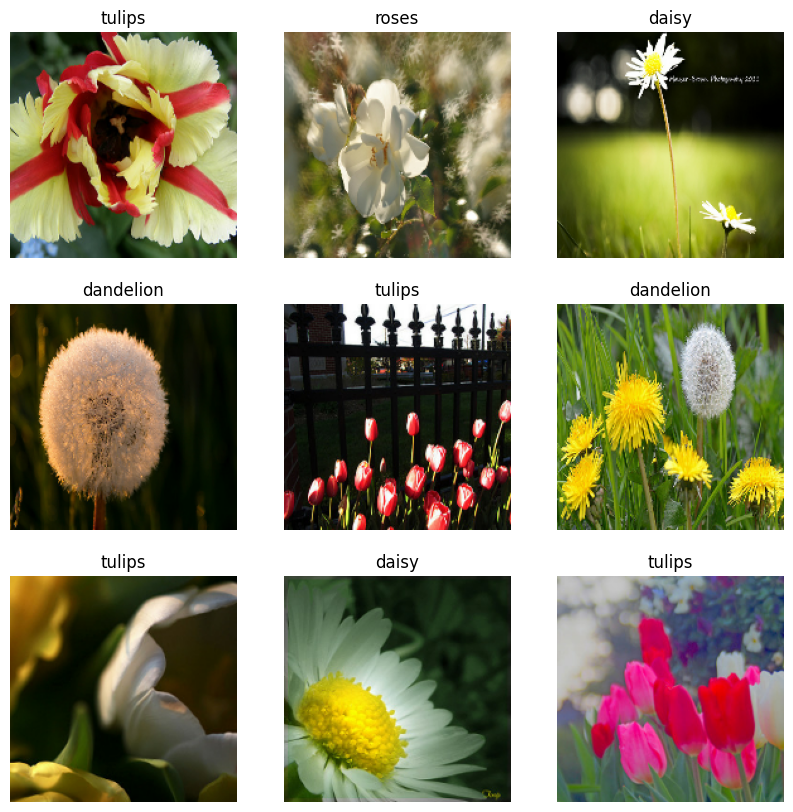
Продолжить обучение модели
Теперь вы вручную создали набор tf.data.Dataset , аналогичный тому, который был создан с помощью tf.keras.utils.image_dataset_from_directory выше. С ним вы можете продолжить обучение модели. Как и прежде, вы будете тренироваться всего несколько эпох, чтобы сократить время бега.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
Использование наборов данных TensorFlow
До сих пор это руководство было сосредоточено на загрузке данных с диска. Вы также можете найти набор данных для использования, изучив большой каталог легко загружаемых наборов данных на TensorFlow Datasets .
Поскольку ранее вы загрузили набор данных Flowers с диска, давайте теперь импортируем его с помощью наборов данных TensorFlow.
Загрузите набор данных Flowers с помощью наборов данных TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Набор данных цветов имеет пять классов:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Получить изображение из набора данных:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Как и прежде, не забывайте группировать, перемешивать и настраивать обучающие, проверочные и тестовые наборы для повышения производительности:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
Вы можете найти полный пример работы с набором данных Flowers и наборами данных TensorFlow, посетив учебник по расширению данных .
Следующие шаги
В этом руководстве показано два способа загрузки изображений с диска. Во-первых, вы узнали, как загружать и предварительно обрабатывать набор данных изображения, используя слои и утилиты предварительной обработки Keras. Далее вы узнали, как написать входной конвейер с нуля, используя tf.data . Наконец, вы узнали, как загрузить набор данных из наборов данных TensorFlow.
Для ваших следующих шагов:
- Вы можете узнать , как добавить увеличение данных .
- Чтобы узнать больше о
tf.data, вы можете посетить руководство tf.data: Build Input Pipelines TensorFlow .