| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Ringkasan
Menggunakan TensorBoard Embedding Projector, Anda grafis dapat mewakili embeddings dimensi tinggi. Ini dapat membantu dalam memvisualisasikan, memeriksa, dan memahami lapisan penyematan Anda.

Dalam tutorial ini, Anda akan belajar bagaimana memvisualisasikan jenis lapisan terlatih ini.
Mempersiapkan
Untuk tutorial ini, kita akan menggunakan TensorBoard untuk memvisualisasikan lapisan embedding yang dihasilkan untuk mengklasifikasikan data ulasan film.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Data IMDB
Kami akan menggunakan kumpulan data 25.000 ulasan film IMDB, yang masing-masing memiliki label sentimen (positif/negatif). Setiap ulasan diproses sebelumnya dan dikodekan sebagai urutan indeks kata (bilangan bulat). Untuk mempermudah, kata-kata diindeks berdasarkan frekuensi keseluruhan dalam kumpulan data, misalnya bilangan bulat "3" mengkodekan kata ke-3 yang paling sering muncul di semua ulasan. Ini memungkinkan operasi pemfilteran cepat seperti: "hanya pertimbangkan 10.000 kata paling umum teratas, tetapi hilangkan 20 kata paling umum teratas".
Sebagai konvensi, "0" tidak berarti kata tertentu, tetapi digunakan untuk menyandikan kata yang tidak dikenal. Nanti di tutorial, kita akan menghapus baris untuk "0" di visualisasi.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Lapisan Penyematan Keras
Sebuah Lapisan Keras Embedding dapat digunakan untuk melatih embedding untuk setiap kata dalam kosakata Anda. Setiap kata (atau sub-kata dalam kasus ini) akan diasosiasikan dengan vektor 16-dimensi (atau embedding) yang akan dilatih oleh model.
Lihat tutorial ini untuk mempelajari lebih lanjut tentang embeddings kata.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Menyimpan Data untuk TensorBoard
TensorBoard membaca tensor dan metadata dari log proyek tensorflow Anda. Path ke direktori log ditentukan dengan log_dir bawah. Untuk tutorial ini, kita akan menggunakan /logs/imdb-example/ .
Untuk memuat data ke dalam Tensorboard, kita perlu menyimpan pos pemeriksaan pelatihan ke direktori tersebut, bersama dengan metadata yang memungkinkan visualisasi lapisan tertentu yang diminati dalam model.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
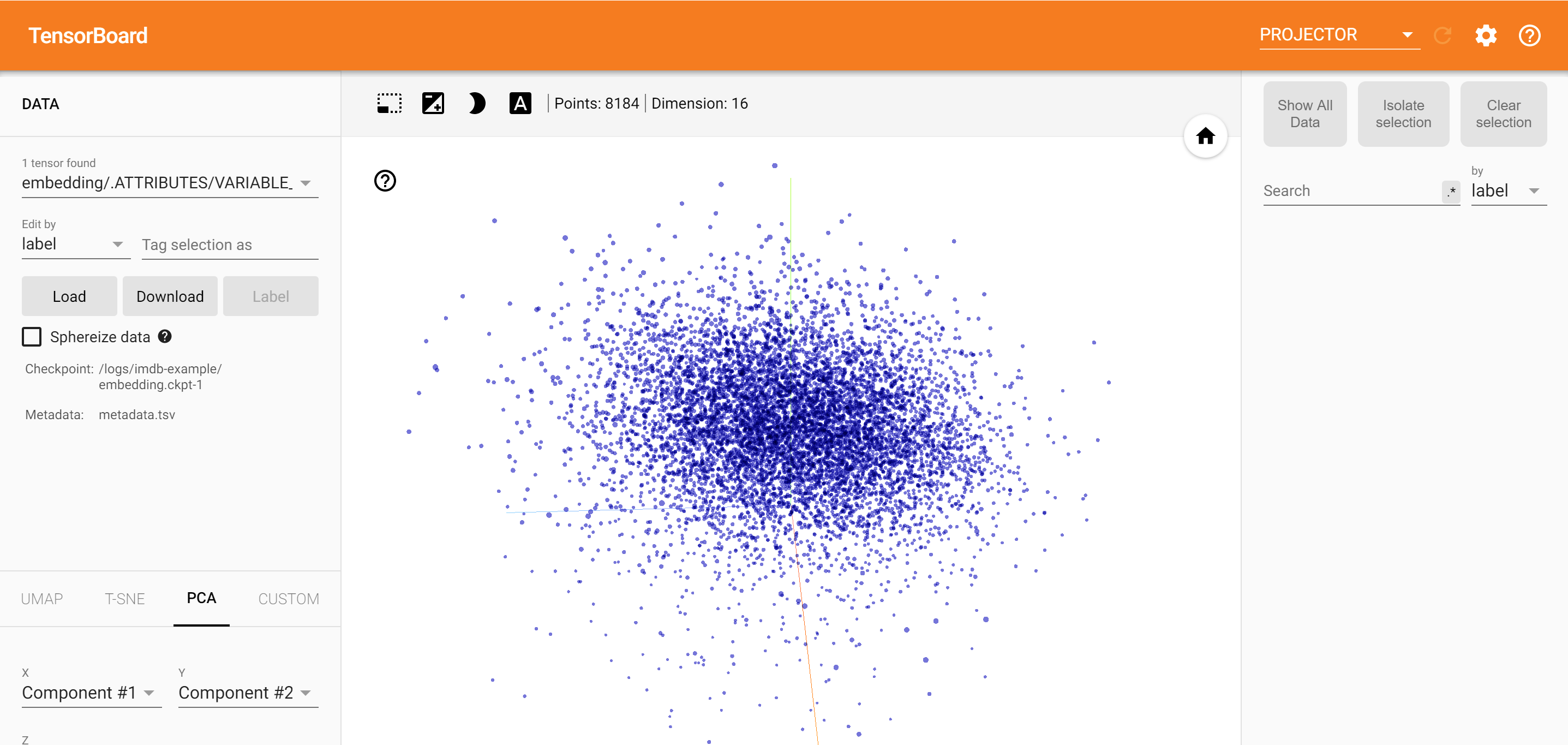
Analisis
Proyektor TensorBoard adalah alat yang hebat untuk menafsirkan dan memvisualisasikan penyematan. Dasbor memungkinkan pengguna untuk mencari istilah tertentu, dan menyoroti kata-kata yang berdekatan satu sama lain dalam ruang embedding (dimensi rendah). Dari contoh ini kita dapat melihat bahwa Wes Anderson dan Alfred Hitchcock yang kedua istilah agak netral, tetapi bahwa mereka dirujuk dalam konteks yang berbeda.
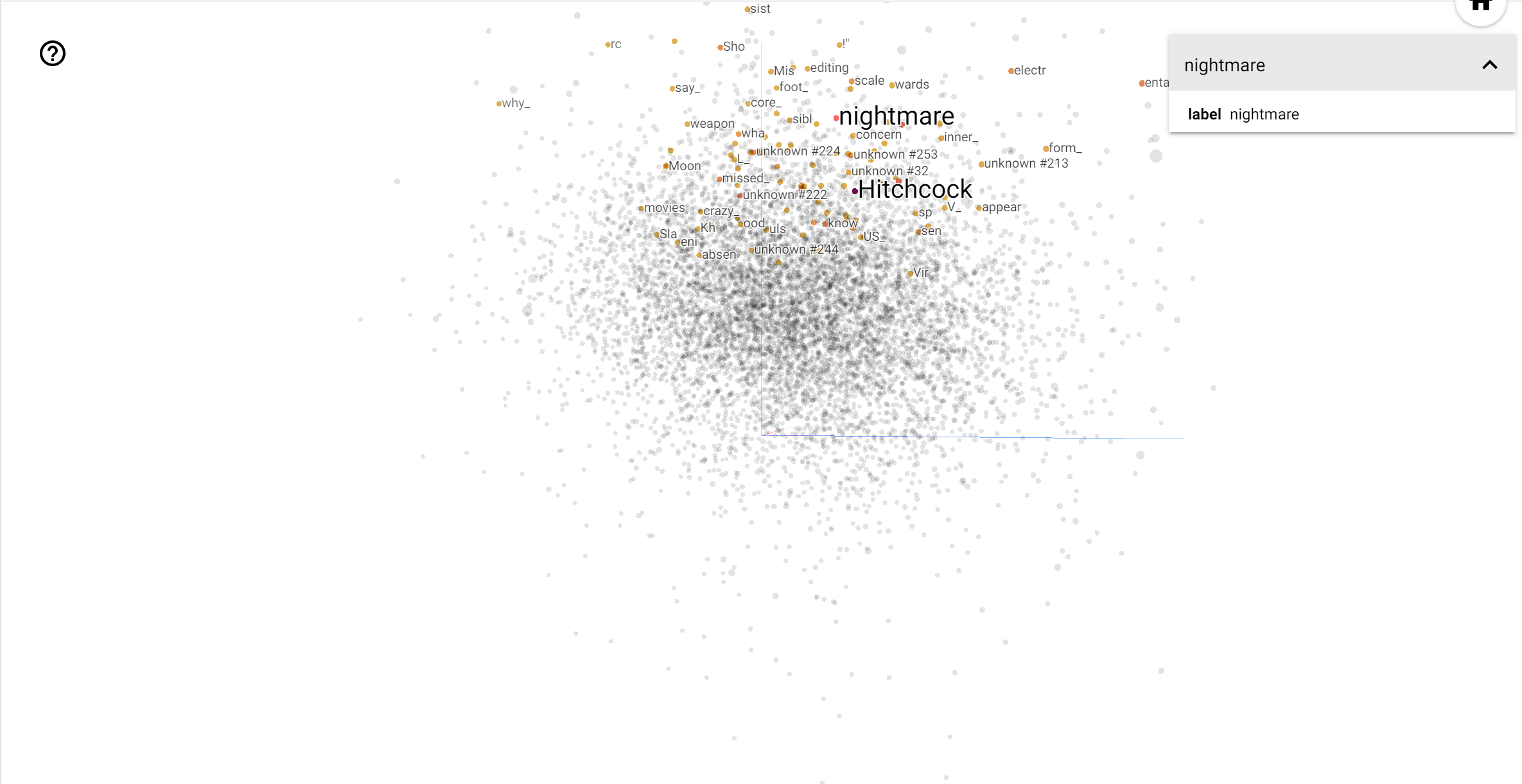
Dalam ruang ini, Hitchcock lebih dekat dengan kata-kata seperti nightmare , yang kemungkinan karena fakta bahwa ia dikenal sebagai "Master of Suspense", sedangkan Anderson lebih dekat dengan kata heart , yang konsisten dengan dan gaya mengharukan nya tanpa henti rinci .