| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
Sử dụng TensorBoard Nhúng chiếu, bạn có thể đại diện đồ họa embeddings chiều cao. Điều này có thể hữu ích trong việc hình dung, kiểm tra và hiểu các lớp nhúng của bạn.

Trong hướng dẫn này, bạn sẽ học cách trực quan hóa loại lớp được đào tạo này.
Thành lập
Đối với hướng dẫn này, chúng tôi sẽ sử dụng TensorBoard để trực quan hóa một lớp nhúng được tạo để phân loại dữ liệu đánh giá phim.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Dữ liệu IMDB
Chúng tôi sẽ sử dụng tập dữ liệu gồm 25.000 đánh giá phim IMDB, mỗi đánh giá trong số đó có nhãn cảm xúc (tích cực / tiêu cực). Mỗi bài đánh giá được xử lý trước và mã hóa thành một chuỗi các chỉ mục từ (số nguyên). Để đơn giản, các từ được lập chỉ mục theo tần suất tổng thể trong tập dữ liệu, ví dụ: số nguyên "3" mã hóa từ thường xuyên thứ 3 xuất hiện trong tất cả các bài đánh giá. Điều này cho phép thực hiện các thao tác lọc nhanh chóng như: "chỉ xem xét top 10.000 từ phổ biến nhất, nhưng loại bỏ 20 từ phổ biến nhất".
Theo quy ước, "0" không phải là đại diện cho bất kỳ từ cụ thể nào, mà thay vào đó được sử dụng để mã hóa bất kỳ từ nào chưa biết. Ở phần sau của hướng dẫn, chúng tôi sẽ xóa hàng cho "0" trong hình ảnh.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Lớp nhúng Keras
Một lớp Keras Nhúng thể được sử dụng để đào tạo một nhúng cho mỗi từ trong vốn từ vựng của bạn. Mỗi từ (hoặc từ con trong trường hợp này) sẽ được liên kết với một vectơ 16 chiều (hoặc phép nhúng) sẽ được mô hình huấn luyện.
Xem hướng dẫn này để tìm hiểu thêm về embeddings từ.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Tiết kiệm dữ liệu cho TensorBoard
TensorBoard đọc các tensor và siêu dữ liệu từ nhật ký của các dự án tensorflow của bạn. Đường dẫn đến thư mục log được quy định với log_dir dưới đây. Đối với hướng dẫn này, chúng tôi sẽ sử dụng /logs/imdb-example/ .
Để tải dữ liệu vào Tensorboard, chúng ta cần lưu điểm kiểm tra huấn luyện vào thư mục đó, cùng với siêu dữ liệu cho phép hiển thị trực quan lớp cụ thể quan tâm trong mô hình.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
Phân tích
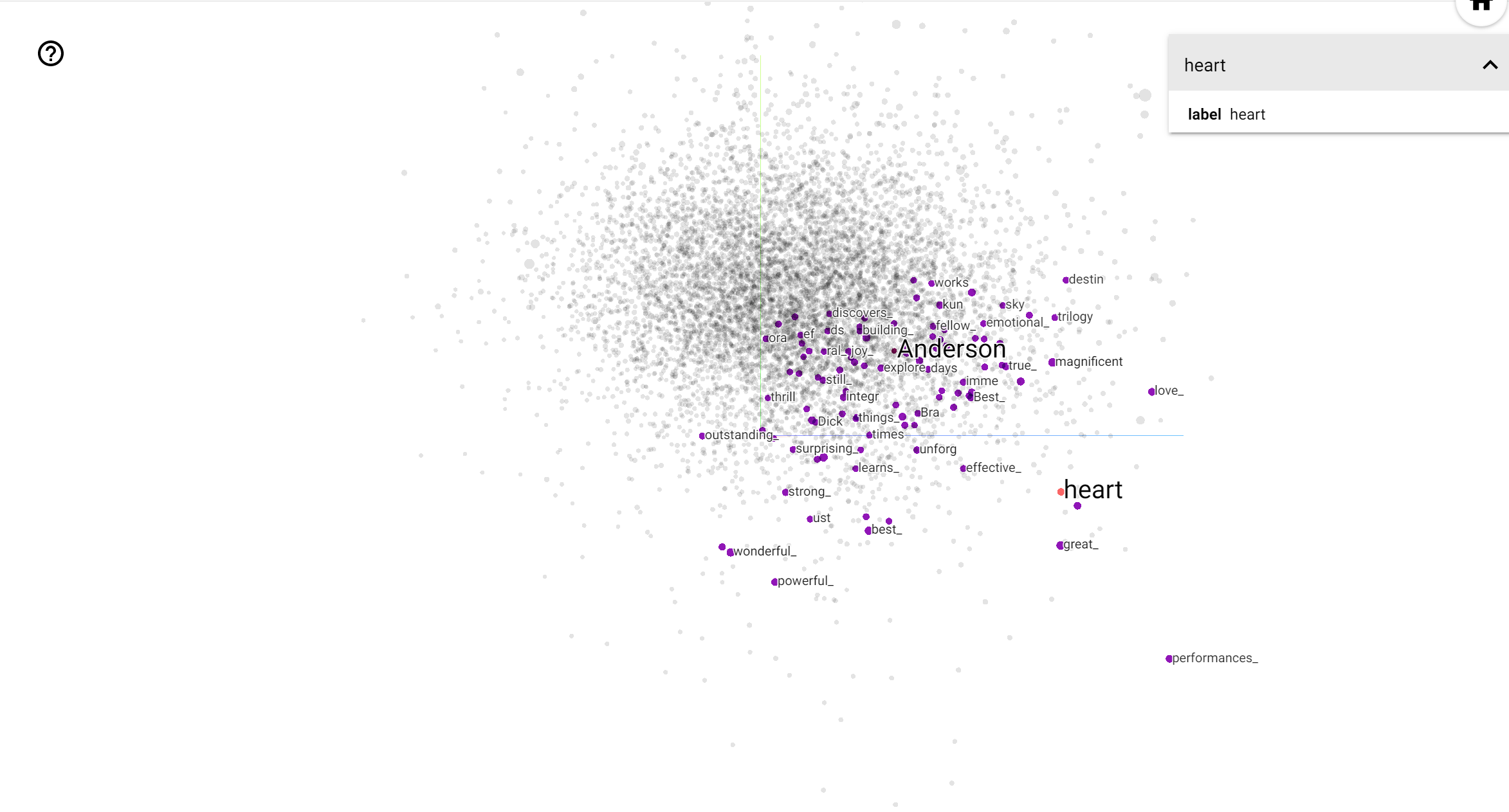
Máy chiếu TensorBoard là một công cụ tuyệt vời để giải thích và hiển thị hình ảnh nhúng. Trang tổng quan cho phép người dùng tìm kiếm các cụm từ cụ thể và đánh dấu các từ liền kề nhau trong không gian nhúng (chiều thấp). Từ ví dụ này chúng ta có thể thấy rằng Wes Anderson và Alfred Hitchcock là cả về khá trung lập, nhưng họ được tham chiếu trong ngữ cảnh khác nhau.

Trong không gian này, Hitchcock là gần gũi hơn với những từ như nightmare , mà có thể do thực tế rằng ông được gọi là "Master of Suspense", trong khi Anderson là gần gũi hơn với các từ heart , đó là phù hợp với và phong cách ấm áp không ngừng chi tiết của mình .