
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
이 튜토리얼은 문자 기반 RNN을 사용하여 텍스트를 생성하는 방법을 보여줍니다. Andrej Karpathy의 The Unreasonable Effectiveness of Recurrent Neural Networks 에서 셰익스피어의 저작 데이터 세트로 작업합니다. 이 데이터의 문자 시퀀스("Shakespear")가 주어지면 시퀀스의 다음 문자("e")를 예측하도록 모델을 훈련시킵니다. 모델을 반복적으로 호출하여 더 긴 텍스트 시퀀스를 생성할 수 있습니다.
이 자습서에는 tf.keras 및 즉시 실행 을 사용하여 구현된 실행 가능한 코드가 포함되어 있습니다. 다음은 이 튜토리얼의 모델이 30개의 에포크에 대해 훈련되고 프롬프트 "Q"로 시작했을 때의 샘플 출력입니다.
QUEENE: I had thought thou hadst a Roman; for the oracle, Thus by All bids the man against the word, Which are so weak of care, by old care done; Your children were in your holy love, And the precipitation through the bleeding throne. BISHOP OF ELY: Marry, and will, my lord, to weep in such a one were prettiest; Yet now I was adopted heir Of the world's lamentable day, To watch the next way with his father with his face? ESCALUS: The cause why then we are all resolved more sons. VOLUMNIA: O, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, it is no sin it should be dead, And love and pale as any will to that word. QUEEN ELIZABETH: But how long have I heard the soul for this world, And show his hands of life be proved to stand. PETRUCHIO: I say he look'd on, if I must be content To stay him from the fatal of our country's bliss. His lordship pluck'd from this sentence then for prey, And then let us twain, being the moon, were she such a case as fills m
일부 문장은 문법적이지만 대부분은 이해가 되지 않습니다. 모델은 단어의 의미를 학습하지 않았지만 다음을 고려하십시오.
모델은 캐릭터 기반입니다. 훈련이 시작되었을 때 모델은 영어 단어의 철자법을 몰랐거나 단어가 텍스트의 단위라는 것도 몰랐습니다.
출력 구조는 연극과 유사합니다. 텍스트 블록은 일반적으로 데이터 세트와 유사한 모든 대문자로 화자 이름으로 시작합니다.
아래에 설명된 것처럼 이 모델은 작은 배치의 텍스트(각각 100자)에 대해 학습되며 일관된 구조로 더 긴 텍스트 시퀀스를 생성할 수 있습니다.
설정
TensorFlow 및 기타 라이브러리 가져오기
import tensorflow as tf
import numpy as np
import os
import time
셰익스피어 데이터 세트 다운로드
자신의 데이터에 대해 이 코드를 실행하려면 다음 줄을 변경하세요.
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt 1122304/1115394 [==============================] - 0s 0us/step 1130496/1115394 [==============================] - 0s 0us/step
데이터 읽기
먼저 텍스트를 살펴보십시오.
# Read, then decode for py2 compat.
text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# length of text is the number of characters in it
print(f'Length of text: {len(text)} characters')
Length of text: 1115394 characters
# Take a look at the first 250 characters in text
print(text[:250])
First Citizen: Before we proceed any further, hear me speak. All: Speak, speak. First Citizen: You are all resolved rather to die than to famish? All: Resolved. resolved. First Citizen: First, you know Caius Marcius is chief enemy to the people.
# The unique characters in the file
vocab = sorted(set(text))
print(f'{len(vocab)} unique characters')
65 unique characters
텍스트 처리
텍스트를 벡터화
훈련하기 전에 문자열을 숫자 표현으로 변환해야 합니다.
tf.keras.layers.StringLookup 레이어는 각 문자를 숫자 ID로 변환할 수 있습니다. 먼저 텍스트를 토큰으로 분할하기만 하면 됩니다.
example_texts = ['abcdefg', 'xyz']
chars = tf.strings.unicode_split(example_texts, input_encoding='UTF-8')
chars
<tf.RaggedTensor [[b'a', b'b', b'c', b'd', b'e', b'f', b'g'], [b'x', b'y', b'z']]>
이제 tf.keras.layers.StringLookup 레이어를 생성합니다.
ids_from_chars = tf.keras.layers.StringLookup(
vocabulary=list(vocab), mask_token=None)
토큰에서 문자 ID로 변환합니다.
ids = ids_from_chars(chars)
ids
<tf.RaggedTensor [[40, 41, 42, 43, 44, 45, 46], [63, 64, 65]]>
이 자습서의 목표는 텍스트를 생성하는 것이므로 이 표현을 반전하고 사람이 읽을 수 있는 문자열을 복구하는 것도 중요합니다. 이를 위해 tf.keras.layers.StringLookup(..., invert=True) 을 사용할 수 있습니다.
chars_from_ids = tf.keras.layers.StringLookup(
vocabulary=ids_from_chars.get_vocabulary(), invert=True, mask_token=None)
이 레이어는 ID 벡터에서 문자를 복구하고 문자의 tf.RaggedTensor 로 반환합니다.
chars = chars_from_ids(ids)
chars
<tf.RaggedTensor [[b'a', b'b', b'c', b'd', b'e', b'f', b'g'], [b'x', b'y', b'z']]>
tf.strings.reduce_join 을 사용하여 문자를 다시 문자열로 결합할 수 있습니다.
tf.strings.reduce_join(chars, axis=-1).numpy()
array([b'abcdefg', b'xyz'], dtype=object)
def text_from_ids(ids):
return tf.strings.reduce_join(chars_from_ids(ids), axis=-1)
예측 작업
한 문자 또는 일련의 문자가 주어졌을 때 가장 가능성이 높은 다음 문자는 무엇입니까? 수행할 모델을 훈련시키는 작업입니다. 모델에 대한 입력은 일련의 문자가 될 것이며 출력을 예측하도록 모델을 훈련합니다(각 시간 단계에서 다음 문자).
RNN은 지금까지 계산된 모든 문자가 주어지면 이전에 본 요소에 의존하는 내부 상태를 유지하므로 다음 문자는 무엇입니까?
교육 예제 및 대상 만들기
다음으로 텍스트를 예제 시퀀스로 나눕니다. 각 입력 시퀀스에는 텍스트의 seq_length 문자가 포함됩니다.
각 입력 시퀀스에 대해 해당 대상은 한 문자를 오른쪽으로 이동한 것을 제외하고 동일한 길이의 텍스트를 포함합니다.
따라서 텍스트를 seq_length+1 덩어리로 나눕니다. 예를 들어 seq_length 가 4이고 텍스트가 "Hello"라고 가정합니다. 입력 시퀀스는 "Hell"이고 대상 시퀀스는 "ello"입니다.
이렇게 하려면 먼저 tf.data.Dataset.from_tensor_slices 함수를 사용하여 텍스트 벡터를 문자 인덱스 스트림으로 변환합니다.
all_ids = ids_from_chars(tf.strings.unicode_split(text, 'UTF-8'))
all_ids
<tf.Tensor: shape=(1115394,), dtype=int64, numpy=array([19, 48, 57, ..., 46, 9, 1])>
ids_dataset = tf.data.Dataset.from_tensor_slices(all_ids)
for ids in ids_dataset.take(10):
print(chars_from_ids(ids).numpy().decode('utf-8'))
F i r s t C i t i
seq_length = 100
examples_per_epoch = len(text)//(seq_length+1)
batch 방법을 사용하면 이러한 개별 문자를 원하는 크기의 시퀀스로 쉽게 변환할 수 있습니다.
sequences = ids_dataset.batch(seq_length+1, drop_remainder=True)
for seq in sequences.take(1):
print(chars_from_ids(seq))
tf.Tensor( [b'F' b'i' b'r' b's' b't' b' ' b'C' b'i' b't' b'i' b'z' b'e' b'n' b':' b'\n' b'B' b'e' b'f' b'o' b'r' b'e' b' ' b'w' b'e' b' ' b'p' b'r' b'o' b'c' b'e' b'e' b'd' b' ' b'a' b'n' b'y' b' ' b'f' b'u' b'r' b't' b'h' b'e' b'r' b',' b' ' b'h' b'e' b'a' b'r' b' ' b'm' b'e' b' ' b's' b'p' b'e' b'a' b'k' b'.' b'\n' b'\n' b'A' b'l' b'l' b':' b'\n' b'S' b'p' b'e' b'a' b'k' b',' b' ' b's' b'p' b'e' b'a' b'k' b'.' b'\n' b'\n' b'F' b'i' b'r' b's' b't' b' ' b'C' b'i' b't' b'i' b'z' b'e' b'n' b':' b'\n' b'Y' b'o' b'u' b' '], shape=(101,), dtype=string) 2022-01-26 01:13:19.940550: W tensorflow/core/data/root_dataset.cc:200] Optimization loop failed: CANCELLED: Operation was cancelled
토큰을 다시 문자열로 결합하면 이것이 무엇을 하는지 더 쉽게 알 수 있습니다.
for seq in sequences.take(5):
print(text_from_ids(seq).numpy())
b'First Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou ' b'are all resolved rather to die than to famish?\n\nAll:\nResolved. resolved.\n\nFirst Citizen:\nFirst, you k' b"now Caius Marcius is chief enemy to the people.\n\nAll:\nWe know't, we know't.\n\nFirst Citizen:\nLet us ki" b"ll him, and we'll have corn at our own price.\nIs't a verdict?\n\nAll:\nNo more talking on't; let it be d" b'one: away, away!\n\nSecond Citizen:\nOne word, good citizens.\n\nFirst Citizen:\nWe are accounted poor citi'
훈련을 위해서는 (input, label) 쌍의 데이터 세트가 필요합니다. 여기서 input 및 label 은 시퀀스입니다. 각 시간 단계에서 입력은 현재 문자이고 레이블은 다음 문자입니다.
다음은 시퀀스를 입력으로 받아 복제하고 이동하여 각 시간 단계에 대한 입력과 레이블을 정렬하는 함수입니다.
def split_input_target(sequence):
input_text = sequence[:-1]
target_text = sequence[1:]
return input_text, target_text
split_input_target(list("Tensorflow"))
(['T', 'e', 'n', 's', 'o', 'r', 'f', 'l', 'o'], ['e', 'n', 's', 'o', 'r', 'f', 'l', 'o', 'w'])
dataset = sequences.map(split_input_target)
for input_example, target_example in dataset.take(1):
print("Input :", text_from_ids(input_example).numpy())
print("Target:", text_from_ids(target_example).numpy())
Input : b'First Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou' Target: b'irst Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou '
훈련 배치 생성
tf.data 를 사용하여 텍스트를 관리 가능한 시퀀스로 분할했습니다. 그러나 이 데이터를 모델에 제공하기 전에 데이터를 섞고 일괄 처리해야 합니다.
# Batch size
BATCH_SIZE = 64
# Buffer size to shuffle the dataset
# (TF data is designed to work with possibly infinite sequences,
# so it doesn't attempt to shuffle the entire sequence in memory. Instead,
# it maintains a buffer in which it shuffles elements).
BUFFER_SIZE = 10000
dataset = (
dataset
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE, drop_remainder=True)
.prefetch(tf.data.experimental.AUTOTUNE))
dataset
<PrefetchDataset element_spec=(TensorSpec(shape=(64, 100), dtype=tf.int64, name=None), TensorSpec(shape=(64, 100), dtype=tf.int64, name=None))>
모델 구축
이 섹션에서는 모델을 keras.Model 하위 클래스로 정의합니다(자세한 내용은 하위 분류를 통해 새 레이어 및 모델 만들기 참조).
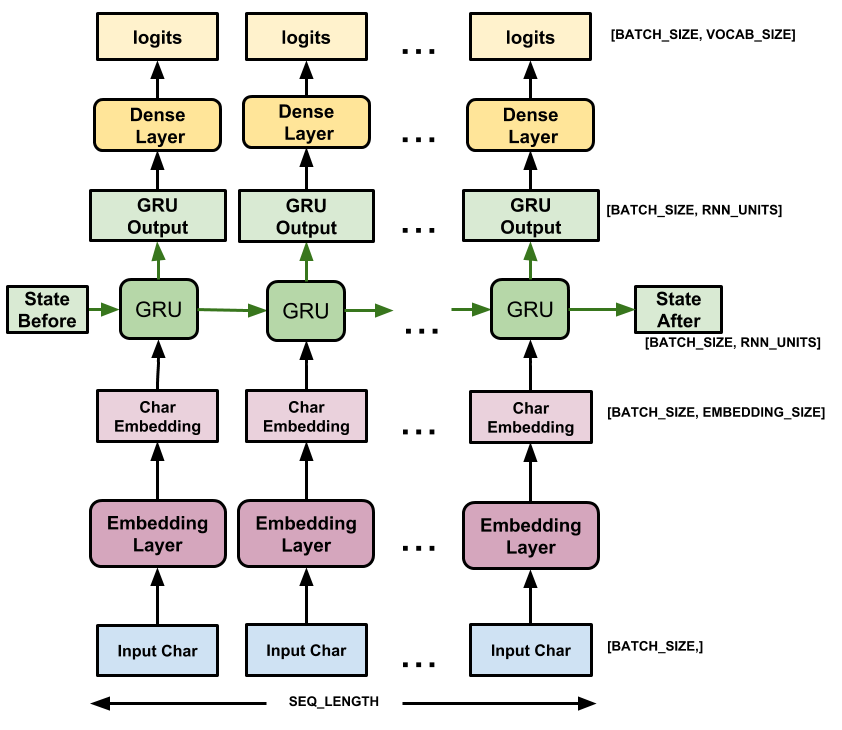
이 모델에는 세 개의 레이어가 있습니다.
-
tf.keras.layers.Embedding: 입력 레이어입니다. 각 문자 ID를embedding_dim차원이 있는 벡터에 매핑하는 학습 가능한 조회 테이블. -
tf.keras.layers.GRU: 크기가units=rnn_units인 RNN의 한 유형(여기서 LSTM 레이어를 사용할 수도 있습니다.) -
tf.keras.layers.Dense:vocab_size출력이 있는 출력 레이어. 어휘의 각 문자에 대해 하나의 로짓을 출력합니다. 이는 모델에 따른 각 문자의 로그 가능성입니다.
# Length of the vocabulary in chars
vocab_size = len(vocab)
# The embedding dimension
embedding_dim = 256
# Number of RNN units
rnn_units = 1024
class MyModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, rnn_units):
super().__init__(self)
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(rnn_units,
return_sequences=True,
return_state=True)
self.dense = tf.keras.layers.Dense(vocab_size)
def call(self, inputs, states=None, return_state=False, training=False):
x = inputs
x = self.embedding(x, training=training)
if states is None:
states = self.gru.get_initial_state(x)
x, states = self.gru(x, initial_state=states, training=training)
x = self.dense(x, training=training)
if return_state:
return x, states
else:
return x
model = MyModel(
# Be sure the vocabulary size matches the `StringLookup` layers.
vocab_size=len(ids_from_chars.get_vocabulary()),
embedding_dim=embedding_dim,
rnn_units=rnn_units)
각 문자에 대해 모델은 임베딩을 조회하고 임베딩을 입력으로 사용하여 GRU를 한 시간 단계 실행하고 밀집 계층을 적용하여 다음 문자의 로그 가능성을 예측하는 로짓을 생성합니다.
모델을 시도
이제 모델을 실행하여 예상대로 작동하는지 확인합니다.
먼저 출력의 모양을 확인하십시오.
for input_example_batch, target_example_batch in dataset.take(1):
example_batch_predictions = model(input_example_batch)
print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")
(64, 100, 66) # (batch_size, sequence_length, vocab_size)
위의 예에서 입력의 시퀀스 길이는 100 이지만 모델은 모든 길이의 입력에서 실행할 수 있습니다.
model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) multiple 16896
gru (GRU) multiple 3938304
dense (Dense) multiple 67650
=================================================================
Total params: 4,022,850
Trainable params: 4,022,850
Non-trainable params: 0
_________________________________________________________________
모델에서 실제 예측을 얻으려면 출력 분포에서 샘플링하여 실제 문자 인덱스를 가져와야 합니다. 이 분포는 문자 어휘에 대한 로짓으로 정의됩니다.
배치의 첫 번째 예에 대해 시도해 보십시오.
sampled_indices = tf.random.categorical(example_batch_predictions[0], num_samples=1)
sampled_indices = tf.squeeze(sampled_indices, axis=-1).numpy()
이것은 각 시간 단계에서 다음 문자 인덱스에 대한 예측을 제공합니다.
sampled_indices
array([29, 23, 11, 14, 42, 27, 56, 29, 14, 6, 9, 65, 22, 15, 34, 64, 44,
41, 11, 51, 10, 44, 42, 56, 13, 50, 1, 33, 45, 23, 28, 43, 12, 62,
45, 60, 43, 62, 38, 19, 50, 35, 19, 14, 60, 56, 10, 64, 39, 56, 2,
51, 63, 42, 39, 64, 43, 20, 20, 17, 40, 15, 52, 46, 7, 25, 34, 43,
11, 11, 31, 34, 38, 44, 22, 49, 23, 4, 27, 0, 31, 39, 5, 9, 43,
58, 33, 30, 49, 6, 63, 5, 50, 4, 6, 14, 62, 3, 7, 35])
이 훈련되지 않은 모델에 의해 예측된 텍스트를 보려면 이를 디코딩하십시오.
print("Input:\n", text_from_ids(input_example_batch[0]).numpy())
print()
print("Next Char Predictions:\n", text_from_ids(sampled_indices).numpy())
Input: b":\nWherein the king stands generally condemn'd.\n\nBAGOT:\nIf judgement lie in them, then so do we,\nBeca" Next Char Predictions: b"PJ:AcNqPA'.zIBUyeb:l3ecq?k\nTfJOd;wfudwYFkVFAuq3yZq lxcZydGGDaBmg,LUd::RUYeIjJ\\(N[UNK]RZ&.dsTQj'x&k\\)'Aw!,V"
모델 훈련
이 시점에서 문제는 표준 분류 문제로 취급될 수 있습니다. 이전 RNN 상태와 이 시간 단계의 입력이 주어지면 다음 문자의 클래스를 예측합니다.
옵티마이저와 손실 함수를 붙입니다.
표준 tf.keras.losses.sparse_categorical_crossentropy 손실 함수는 예측의 마지막 차원에 적용되기 때문에 이 경우에 작동합니다.
모델이 logits를 반환하기 때문에 from_logits 플래그를 설정해야 합니다.
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True)
example_batch_mean_loss = loss(target_example_batch, example_batch_predictions)
print("Prediction shape: ", example_batch_predictions.shape, " # (batch_size, sequence_length, vocab_size)")
print("Mean loss: ", example_batch_mean_loss)
Prediction shape: (64, 100, 66) # (batch_size, sequence_length, vocab_size) Mean loss: tf.Tensor(4.1895466, shape=(), dtype=float32)
새로 초기화된 모델은 스스로를 너무 확신해서는 안 되며, 출력 로짓은 모두 비슷한 크기를 가져야 합니다. 이를 확인하기 위해 평균 손실의 지수가 어휘 크기와 거의 같은지 확인할 수 있습니다. 훨씬 높은 손실은 모델이 오답을 확신하고 잘못 초기화되었음을 의미합니다.
tf.exp(example_batch_mean_loss).numpy()
65.99286
tf.keras.Model.compile 메서드를 사용하여 훈련 절차를 구성합니다. 기본 인수 및 손실 함수와 함께 tf.keras.optimizers.Adam 을 사용합니다.
model.compile(optimizer='adam', loss=loss)
체크포인트 구성
tf.keras.callbacks.ModelCheckpoint 를 사용하여 훈련 중에 체크포인트가 저장되도록 합니다.
# Directory where the checkpoints will be saved
checkpoint_dir = './training_checkpoints'
# Name of the checkpoint files
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)
훈련을 실행
훈련 시간을 합리적으로 유지하려면 10 Epoch를 사용하여 모델을 훈련합니다. Colab에서 더 빠른 학습을 위해 런타임을 GPU로 설정합니다.
EPOCHS = 20
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])
Epoch 1/20 172/172 [==============================] - 7s 25ms/step - loss: 2.7409 Epoch 2/20 172/172 [==============================] - 5s 24ms/step - loss: 2.0092 Epoch 3/20 172/172 [==============================] - 5s 24ms/step - loss: 1.7211 Epoch 4/20 172/172 [==============================] - 5s 24ms/step - loss: 1.5550 Epoch 5/20 172/172 [==============================] - 5s 24ms/step - loss: 1.4547 Epoch 6/20 172/172 [==============================] - 5s 24ms/step - loss: 1.3865 Epoch 7/20 172/172 [==============================] - 5s 24ms/step - loss: 1.3325 Epoch 8/20 172/172 [==============================] - 5s 24ms/step - loss: 1.2875 Epoch 9/20 172/172 [==============================] - 5s 24ms/step - loss: 1.2474 Epoch 10/20 172/172 [==============================] - 5s 24ms/step - loss: 1.2066 Epoch 11/20 172/172 [==============================] - 5s 24ms/step - loss: 1.1678 Epoch 12/20 172/172 [==============================] - 5s 24ms/step - loss: 1.1270 Epoch 13/20 172/172 [==============================] - 5s 24ms/step - loss: 1.0842 Epoch 14/20 172/172 [==============================] - 5s 24ms/step - loss: 1.0388 Epoch 15/20 172/172 [==============================] - 5s 24ms/step - loss: 0.9909 Epoch 16/20 172/172 [==============================] - 5s 24ms/step - loss: 0.9409 Epoch 17/20 172/172 [==============================] - 5s 24ms/step - loss: 0.8887 Epoch 18/20 172/172 [==============================] - 5s 24ms/step - loss: 0.8373 Epoch 19/20 172/172 [==============================] - 5s 24ms/step - loss: 0.7849 Epoch 20/20 172/172 [==============================] - 5s 24ms/step - loss: 0.7371
텍스트 생성
이 모델로 텍스트를 생성하는 가장 간단한 방법은 루프에서 실행하고 실행할 때 모델의 내부 상태를 추적하는 것입니다.
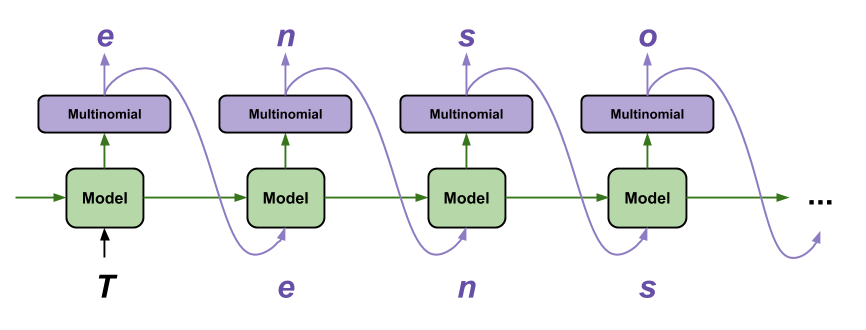
모델을 호출할 때마다 일부 텍스트와 내부 상태를 전달합니다. 모델은 다음 문자와 새 상태에 대한 예측을 반환합니다. 텍스트 생성을 계속하려면 예측 및 상태를 다시 전달하십시오.
다음은 단일 단계 예측을 수행합니다.
class OneStep(tf.keras.Model):
def __init__(self, model, chars_from_ids, ids_from_chars, temperature=1.0):
super().__init__()
self.temperature = temperature
self.model = model
self.chars_from_ids = chars_from_ids
self.ids_from_chars = ids_from_chars
# Create a mask to prevent "[UNK]" from being generated.
skip_ids = self.ids_from_chars(['[UNK]'])[:, None]
sparse_mask = tf.SparseTensor(
# Put a -inf at each bad index.
values=[-float('inf')]*len(skip_ids),
indices=skip_ids,
# Match the shape to the vocabulary
dense_shape=[len(ids_from_chars.get_vocabulary())])
self.prediction_mask = tf.sparse.to_dense(sparse_mask)
@tf.function
def generate_one_step(self, inputs, states=None):
# Convert strings to token IDs.
input_chars = tf.strings.unicode_split(inputs, 'UTF-8')
input_ids = self.ids_from_chars(input_chars).to_tensor()
# Run the model.
# predicted_logits.shape is [batch, char, next_char_logits]
predicted_logits, states = self.model(inputs=input_ids, states=states,
return_state=True)
# Only use the last prediction.
predicted_logits = predicted_logits[:, -1, :]
predicted_logits = predicted_logits/self.temperature
# Apply the prediction mask: prevent "[UNK]" from being generated.
predicted_logits = predicted_logits + self.prediction_mask
# Sample the output logits to generate token IDs.
predicted_ids = tf.random.categorical(predicted_logits, num_samples=1)
predicted_ids = tf.squeeze(predicted_ids, axis=-1)
# Convert from token ids to characters
predicted_chars = self.chars_from_ids(predicted_ids)
# Return the characters and model state.
return predicted_chars, states
one_step_model = OneStep(model, chars_from_ids, ids_from_chars)
루프에서 실행하여 일부 텍스트를 생성합니다. 생성된 텍스트를 보면 모델이 대문자를 사용하고 단락을 만들고 셰익스피어와 같은 쓰기 어휘를 모방할 때를 알고 있음을 알 수 있습니다. 적은 수의 훈련 에포크(epoch)로 인해 일관된 문장을 형성하는 법을 아직 배우지 못했습니다.
start = time.time()
states = None
next_char = tf.constant(['ROMEO:'])
result = [next_char]
for n in range(1000):
next_char, states = one_step_model.generate_one_step(next_char, states=states)
result.append(next_char)
result = tf.strings.join(result)
end = time.time()
print(result[0].numpy().decode('utf-8'), '\n\n' + '_'*80)
print('\nRun time:', end - start)
ROMEO: This is not your comfort, when you see-- Huntsmit, we have already, let us she so hard, Matters there well. Thou camallo, this night, you should her. Gar of all the world to save my life, I'll do well for one boy, and fetch she pass The shadow with others' sole. First Huntsman: O rude blue, come,' to woe, and beat my beauty is ears. An, thither, be ruled betimes, be cruel wonder That hath but adainst my head. Nurse: Peter, your ancest-ticked faint. MIRANDA: More of Hereford, speak you: father, for our gentleman Who do I not? look, soars! CORIOLANUS: Why, sir, what was done to brine? I pray, how many mouth A brave defence speak to us: he has not out To hold my soldiers; like one another smiled Than a mad father's boots, you know, my lord, Where is he was better than you see, of the town, our kindred heart, that would sudden to the worse, An if I met, yet fetch him own. LUCENTIO: I may be relight. MENENIUS: Ay, with sixteen years, finders both, and as the most proportion's mooners ________________________________________________________________________________ Run time: 2.67258358001709
결과를 개선하기 위해 할 수 있는 가장 쉬운 방법은 더 오래 훈련하는 것입니다( EPOCHS = 30 시도).
또한 다른 시작 문자열로 실험하거나 다른 RNN 레이어를 추가하여 모델의 정확도를 향상시키거나 온도 매개변수를 조정하여 다소간의 임의 예측을 생성할 수도 있습니다.
모델이 텍스트를 더 빨리 생성하도록 하려면 가장 쉬운 방법은 텍스트 생성을 일괄 처리하는 것입니다. 아래 예에서 모델은 위의 1개를 생성하는 데 걸리는 시간과 거의 동일한 시간에 5개의 출력을 생성합니다.
start = time.time()
states = None
next_char = tf.constant(['ROMEO:', 'ROMEO:', 'ROMEO:', 'ROMEO:', 'ROMEO:'])
result = [next_char]
for n in range(1000):
next_char, states = one_step_model.generate_one_step(next_char, states=states)
result.append(next_char)
result = tf.strings.join(result)
end = time.time()
print(result, '\n\n' + '_'*80)
print('\nRun time:', end - start)
tf.Tensor( [b"ROMEO:\nThe execution forbear that I was a kiss\nA mother in their ownsation with out the rest;\nNor seal'd-me to tell thee joyful? what said Yor Marcius! woe\nThat banish'd unrever-elent I confess\nA husband.\n\nLADY ANNE:\nTo men of summon encest wond\nlike him, Anding your freth hate for vain\nMay hardly slakes meer's name, o' no voice,\nBegail that passing child that valour'd gown?\n\nWARWICK:\nOxford, how much that made the rock Tarpeian?\n\nLUCENTIO:\nImirougester: I am too your freeds.\n\nCAPULET:\nThen I will wash\nBecause the effect of the citizens,\nOur skifts are born. Know the most patards time and will\nwomen! compare of the coronation, I did\nif you find it won to him and I.\n\nROMEO:\nGood evil; get you gone, let me have married me but yet.\n\nWARWICK:\nWhy, thou hast said his hastings? King Henry's head,\nAnd doth our scene stubility in merit ot perils\nHere to revenge, I say, proud queen,\nUnless you hence, my sons of weary perfects;\nReshon'd the prisoner in blood of jocund\nIn every scoutness' gentle Rucuov" b"ROMEO: go. Take it on yon placking for me, if thou didst love so blunt,\nLest old Lucio, whom I defy years, fellow-hands,\nThis very approbation lives.\n\nLADY ANNE:\nThat's your yel; if it come.\n\nKATHARINA:\nI'll pray you, sit,\nPut not your boot of such as they were, at length\nWas grieved for grept Hanting, on my service, kill, kill, kissis;\nAnd yet I was an Edward in every but a\ngreat maker your flesh and gold, another fear,\nAnd this, before your brother's son,\nWith its strange: but he will set upon you.\n\nCORIOLANUS:\nAy, my lord.\n\nFRIAR LAURENCE:\nRomeo! O, ho! first let remembers to piece away.\nThis is the Tower.\n\nThird Citizen:\nBehold, the matter?\n\nDUKE VINCENTIO:\nYou are too blind so many; yet so I did will take Mercutio,\nI may be jogging whiles; he sees it.\n\nCLARENCE:\nMethought that evil weeps so Romeo?\nWho be so heavy? I think they speak,\nBefore she will be flight.\n\nAll:\nOl, is become of such hath call'd hims, study and dance.\nIf that my powerful sings\nshould be a beacheries. Edward as 'lon " b"ROMEO:\nThe son, peace! thy sacred lizer throne,\nRather my tongue upon't. I can, bethick your help!\nJust of a king, woe's stand and love.\n\nBRUTUS:\nI can better divish'd and not all under affect:\nO, be quickly, villain, to report this school,\nI had none seen the dust of Hortensio.\n\nBIANCA:\nGod's good, my lord, to help your rece,ter famina,\nAnd Juliet like my hold, Liest your best:\nTo-morrow that I keep in some villaging\nAnd make her beauty continued in pees.\nMethoughts to London with our bodies in bounting love,\nCompliment by ups my green as I do favours\nWith a precious wind with child by adly way in love\nUnder the world; and so it is the malmsey-butt in\nThe very new offing to your follies.\n\nJULIET:\nCome on, lay here in hazarring her to bring me. I less there\nEscaped for flight, we may do infringe him.\n\nKeeper:\nMy lord, I have no other bent.\nWhere be the ped-she king's great aid;\nIf you'll more entertainment from you betred,\nThe secrets me to keep him soft; to curse the war,\nThe care colour. W" b"ROMEO:\nGood vows. Thou dead to lurp!\nO God! I cannot make, you have desert\nThan my passes to women all hopes with him?\n\nSecond Musician:\nNo, my liege, in gistocking a cockle or a month o' the peoper.\n\nDUKE VINCENTIO:\nNow, hark! the day; and therefore stand at safe\nWill come, to accuse my dusy hath done, upon you\nBut your will make me out in high forget. If you're past me leave,\nIf not, Saint George I bid thee here,\nMy father, eyes; and I fear any think\nTo the purpose magiin: I find thou refuse\nAnd bethink me to the earth the dire part and day strike.\n\nKING EDWARD IV:\nWhat were you lose. Father, I fear\nIs true the liquid dress: but 'tis a wildly\nkindly, proud I am severe;\nThe time shall point your state as voices and chartels\nclow the king's, being rather tell me out.\n\nPOLIXENES:\nA ponder, cord, not title and heart-honour in host;\nAnd call ummised the injury\nAs many as your tert of honour, this steep\nTo your infinity, if thou owest to\nforsworn you word unbrain; for, brings an edg,\nPloceed pas" b"ROMEO:\nNumbering, and may not unking, methinks, Lord Hastings, let him left your\nresolution as I live in solemn-more,\nAs if this still and scars of ceremony,\nShowing, as in a month being rather child,\nLook on my banish'd hands;\nWho after many moticing Romans,\nThat quickly shook like soft and stone with me.\n\nQUEEN MARGARET:\nAnd limp her tender than thy embassist, fines,\nWith enns most kinding eee:\nOr else you do to help him there:\nIf thou behold, by his rapher,\nAnd 'genty men's sake. Awar!\n\nISABELLA:\nO, pardon me, indeed, didst not a friend for aid\nMyself to-night: thou hast proved corooling\nWhom his oath rides of steeded knaves. I am\ngentlemen, you have come to both groan and my love.\n\nLUCIO:\nBador,ly, madam, but ne'er cause the crown,\nAnd, if I live, my lord.\n\nKING LEWIS XI:\nWarwick, Plaunis; and seeing thou hast slain\nThe bastardy of England am alike.'\nThe royal rabot, to appoint their power,\nFor such a day for this for me; so it is\nmoney, and again with lightning breasts: taste\nThese dece"], shape=(5,), dtype=string) ________________________________________________________________________________ Run time: 2.5006580352783203
발전기 내보내기
이 단일 단계 모델은 쉽게 저장하고 복원 할 수 있으므로 tf.saved_model 이 허용되는 모든 곳에서 사용할 수 있습니다.
tf.saved_model.save(one_step_model, 'one_step')
one_step_reloaded = tf.saved_model.load('one_step')
WARNING:tensorflow:Skipping full serialization of Keras layer <__main__.OneStep object at 0x7fbb7c739510>, because it is not built. 2022-01-26 01:15:24.355813: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as gru_cell_layer_call_fn, gru_cell_layer_call_and_return_conditional_losses while saving (showing 2 of 2). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: one_step/assets INFO:tensorflow:Assets written to: one_step/assets
states = None
next_char = tf.constant(['ROMEO:'])
result = [next_char]
for n in range(100):
next_char, states = one_step_reloaded.generate_one_step(next_char, states=states)
result.append(next_char)
print(tf.strings.join(result)[0].numpy().decode("utf-8"))
ROMEO: Take man's, wife, mark me, and be advised. Fool, in the crown, unhappy is the easy throne, Enforced
고급: 맞춤형 교육
위의 훈련 절차는 간단하지만 많은 제어를 제공하지 않습니다. 잘못된 예측이 모델에 피드백되는 것을 방지하는 교사 강제를 사용하므로 모델은 실수로부터 복구하는 법을 배우지 않습니다.
이제 모델을 수동으로 실행하는 방법을 보았으므로 이제 훈련 루프를 구현합니다. 예를 들어 모델의 개방 루프 출력을 안정화하는 데 도움이 되는 커리큘럼 학습 을 구현하려는 경우 시작점이 됩니다.
맞춤형 훈련 루프의 가장 중요한 부분은 훈련 단계 함수입니다.
tf.GradientTape 를 사용하여 그라디언트를 추적합니다. Eager Execution 가이드 를 읽으면 이 접근 방식에 대해 자세히 알아볼 수 있습니다.
기본 절차는 다음과 같습니다.
- 모델을 실행하고
tf.GradientTape에서 손실을 계산합니다. - 업데이트를 계산하고 최적화 프로그램을 사용하여 모델에 적용합니다.
class CustomTraining(MyModel):
@tf.function
def train_step(self, inputs):
inputs, labels = inputs
with tf.GradientTape() as tape:
predictions = self(inputs, training=True)
loss = self.loss(labels, predictions)
grads = tape.gradient(loss, model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, model.trainable_variables))
return {'loss': loss}
위의 train_step 메서드 구현은 Keras 의 train_step 규칙 을 따릅니다. 이것은 선택 사항이지만 학습 단계의 동작을 변경하고 여전히 keras의 Model.compile 및 Model.fit 메서드를 사용할 수 있습니다.
model = CustomTraining(
vocab_size=len(ids_from_chars.get_vocabulary()),
embedding_dim=embedding_dim,
rnn_units=rnn_units)
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True))
model.fit(dataset, epochs=1)
172/172 [==============================] - 7s 24ms/step - loss: 2.6916 <keras.callbacks.History at 0x7fbb9c5ade90>
또는 더 많은 제어가 필요한 경우 자신만의 완전한 맞춤형 훈련 루프를 작성할 수 있습니다.
EPOCHS = 10
mean = tf.metrics.Mean()
for epoch in range(EPOCHS):
start = time.time()
mean.reset_states()
for (batch_n, (inp, target)) in enumerate(dataset):
logs = model.train_step([inp, target])
mean.update_state(logs['loss'])
if batch_n % 50 == 0:
template = f"Epoch {epoch+1} Batch {batch_n} Loss {logs['loss']:.4f}"
print(template)
# saving (checkpoint) the model every 5 epochs
if (epoch + 1) % 5 == 0:
model.save_weights(checkpoint_prefix.format(epoch=epoch))
print()
print(f'Epoch {epoch+1} Loss: {mean.result().numpy():.4f}')
print(f'Time taken for 1 epoch {time.time() - start:.2f} sec')
print("_"*80)
model.save_weights(checkpoint_prefix.format(epoch=epoch))
Epoch 1 Batch 0 Loss 2.1412 Epoch 1 Batch 50 Loss 2.0362 Epoch 1 Batch 100 Loss 1.9721 Epoch 1 Batch 150 Loss 1.8361 Epoch 1 Loss: 1.9732 Time taken for 1 epoch 5.90 sec ________________________________________________________________________________ Epoch 2 Batch 0 Loss 1.8170 Epoch 2 Batch 50 Loss 1.6815 Epoch 2 Batch 100 Loss 1.6288 Epoch 2 Batch 150 Loss 1.6625 Epoch 2 Loss: 1.6989 Time taken for 1 epoch 5.19 sec ________________________________________________________________________________ Epoch 3 Batch 0 Loss 1.6405 Epoch 3 Batch 50 Loss 1.5635 Epoch 3 Batch 100 Loss 1.5912 Epoch 3 Batch 150 Loss 1.5241 Epoch 3 Loss: 1.5428 Time taken for 1 epoch 5.33 sec ________________________________________________________________________________ Epoch 4 Batch 0 Loss 1.4469 Epoch 4 Batch 50 Loss 1.4512 Epoch 4 Batch 100 Loss 1.4748 Epoch 4 Batch 150 Loss 1.4077 Epoch 4 Loss: 1.4462 Time taken for 1 epoch 5.30 sec ________________________________________________________________________________ Epoch 5 Batch 0 Loss 1.3798 Epoch 5 Batch 50 Loss 1.3727 Epoch 5 Batch 100 Loss 1.3793 Epoch 5 Batch 150 Loss 1.3883 Epoch 5 Loss: 1.3793 Time taken for 1 epoch 5.41 sec ________________________________________________________________________________ Epoch 6 Batch 0 Loss 1.3024 Epoch 6 Batch 50 Loss 1.3325 Epoch 6 Batch 100 Loss 1.3483 Epoch 6 Batch 150 Loss 1.3362 Epoch 6 Loss: 1.3283 Time taken for 1 epoch 5.34 sec ________________________________________________________________________________ Epoch 7 Batch 0 Loss 1.2669 Epoch 7 Batch 50 Loss 1.2864 Epoch 7 Batch 100 Loss 1.2498 Epoch 7 Batch 150 Loss 1.2482 Epoch 7 Loss: 1.2832 Time taken for 1 epoch 5.27 sec ________________________________________________________________________________ Epoch 8 Batch 0 Loss 1.2289 Epoch 8 Batch 50 Loss 1.2577 Epoch 8 Batch 100 Loss 1.2070 Epoch 8 Batch 150 Loss 1.2333 Epoch 8 Loss: 1.2436 Time taken for 1 epoch 5.18 sec ________________________________________________________________________________ Epoch 9 Batch 0 Loss 1.2138 Epoch 9 Batch 50 Loss 1.2410 Epoch 9 Batch 100 Loss 1.1898 Epoch 9 Batch 150 Loss 1.2157 Epoch 9 Loss: 1.2038 Time taken for 1 epoch 5.23 sec ________________________________________________________________________________ Epoch 10 Batch 0 Loss 1.1200 Epoch 10 Batch 50 Loss 1.1545 Epoch 10 Batch 100 Loss 1.1688 Epoch 10 Batch 150 Loss 1.1748 Epoch 10 Loss: 1.1642 Time taken for 1 epoch 5.53 sec ________________________________________________________________________________