
|
|
|
 깃허브(GitHub)에서 소스 보기 깃허브(GitHub)에서 소스 보기
|
|
텐서플로의 즉시 실행은 그래프를 생성하지 않고 함수를 바로 실행하는 명령형 프로그래밍 환경입니다.
나중에 실행하기 위해 계산가능한 그래프를 생성하는 대신에 계산값을 즉시 알려주는 연산입니다.
이러한 기능은 텐서플로를 시작하고 모델을 디버깅하는 것을 더욱 쉽게 만들고 불필요한 상용구 코드(boilerplate code) 작성을 줄여줍니다.
가이드를 따라하려면, 대화형 파이썬 해석기(interpreter)를 이용해 아래에 있는 코드 샘플을 실행하세요.
즉시 실행은 연구와 실험을 위한 유연한 기계학습 플랫폼으로 다음과 같은 기능을 제공합니다:
- 직관적인 인터페이스-코드를 자연스럽게 구조화하고 파이썬의 데이터 구조를 활용. 작은 모델과 작은 데이터를 빠르게 반복
- 손쉬운 디버깅-실행중인 모델을 검토하거나 변경 사항을 테스트해보기 위해서 연산을 직접 호출. 에러 확인을 위해서 표준 파이썬 디버깅 툴을 사용
- 자연스런 흐름 제어-그래프 제어 흐름 대신에 파이썬 제어 흐름을 사용함으로써 동적인 모델 구조의 단순화
즉시 실행은 대부분의 텐서플로 연산과 GPU 가속을 지원합니다.
설치와 기본 사용법
import tensorflow as tf
import cProfile
2022-12-14 21:09:18.853444: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:09:18.853541: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:09:18.853550: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
텐서플로 2.0에서 즉시 실행은 기본으로 활성화되어 있습니다.
tf.executing_eagerly()
True
이제부터는 텐서플로 연산을 바로 실행할 수 있고 결과를 즉시 확인할 수 있습니다:
x = [[2.]]
m = tf.matmul(x, x)
print("hello, {}".format(m))
hello, [[4.]]
즉시 실행 활성화는 텐서플로 연산을 바로 평가하고 그 결과를 파이썬에게 알려주는 방식으로 동작을 변경합니다.
tf.Tensor 객체는 계산 그래프에 있는 노드를 가르키는 간접 핸들(symbolic handle) 대신에 구체적인 값을 참조합니다.
나중에 실행하기 위해서 생성된 계산 그래프가 없기 때문에, print()나 디버거를 통해서 결과를 검토하기 쉽습니다.
텐서값을 평가, 출력하거나 확인하는 것이 그래디언트(gradients)를 계산하는 흐름을 방해하지 않습니다.
즉시 실행은 NumPy와 같이 잘 작동됩니다.
NumPy 연산에 tf.Tensor를 매개변수로 사용가능합니다.
텐서플로 수학 연산은 파이썬 객체와 NumPy 배열을 tf.Tensor 객체로 변환합니다.
tf.Tensor.numpy 메서드는 객체 값을 NumPy ndarray로 반환합니다.
a = tf.constant([[1, 2],
[3, 4]])
print(a)
tf.Tensor( [[1 2] [3 4]], shape=(2, 2), dtype=int32)
# 브로드캐스팅(Broadcasting) 지원
b = tf.add(a, 1)
print(b)
tf.Tensor( [[2 3] [4 5]], shape=(2, 2), dtype=int32)
# 연산자 오버로딩 지원
print(a * b)
tf.Tensor( [[ 2 6] [12 20]], shape=(2, 2), dtype=int32)
# NumPy값 사용
import numpy as np
c = np.multiply(a, b)
print(c)
[[ 2 6] [12 20]]
# 텐서로부터 numpy 값 얻기:
print(a.numpy())
# => [[1 2]
# [3 4]]
[[1 2] [3 4]]
동적인 제어 흐름
즉시 실행의 가장 큰 이점은 모델을 실행하는 동안에도 호스트 언어의 모든 기능을 활용할 수 있다는 것입니다. 그래서 다음과 같이 fizzbuzz를 손쉽게 작성할 수 있습니다:
def fizzbuzz(max_num):
counter = tf.constant(0)
max_num = tf.convert_to_tensor(max_num)
for num in range(1, max_num.numpy()+1):
num = tf.constant(num)
if int(num % 3) == 0 and int(num % 5) == 0:
print('FizzBuzz')
elif int(num % 3) == 0:
print('Fizz')
elif int(num % 5) == 0:
print('Buzz')
else:
print(num.numpy())
counter += 1
fizzbuzz(15)
1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzz
여기에 텐서값에 따른 조건절이 있고 실행중에 그 결과를 출력합니다.
즉시 훈련
그래디언트 계산하기
자동 미분은 인공 신경망 훈련을 위한
역전파와 같은 기계학습 알고리즘을 구현하는데 유용합니다.
즉시 실행을 사용하는 동안에는, 나중에 그래디언트를 계산하는 연산을 추적하기 위해 tf.GradientTape을 사용하세요.
즉시 실행 중에 그래디언트를 계산하고 모델 훈련에 이용하기 위해서 tf.GradientTape을 사용할 수 있습니다.
특히 복잡하고 반복적인 훈련인 경우에 더 유용합니다.
매번 실행될 때 서로 다른 연산이 수행될 수 있기 때문에 모든 정방향(forward-pass) 연산은 "tape"에 기록됩니다.
그다음 tape를 거꾸로 돌려 그래디언트를 계산한 후 tape를 폐기합니다.
특정한 tf.GradientTape는 오직 하나의 그래디언트만을 계산할 수 있고 부가적인 호출은 실행중 에러(runtime error)를 발생시킵니다.
w = tf.Variable([[1.0]])
with tf.GradientTape() as tape:
loss = w * w
grad = tape.gradient(loss, w)
print(grad) # => tf.Tensor([[ 2.]], shape=(1, 1), dtype=float32)
tf.Tensor([[2.]], shape=(1, 1), dtype=float32)
모델 훈련
다음 예는 표준 MNIST 손글씨 분류를 위한 다층 모델을 생성합니다. 즉시 실행 환경에서 훈련가능한 그래프를 생성하기 위한 옵티마이저(optimizer)와 층 API를 보여줍니다.
# mnist 데이터 가져오기 및 포맷 맞추기
(mnist_images, mnist_labels), _ = tf.keras.datasets.mnist.load_data()
dataset = tf.data.Dataset.from_tensor_slices(
(tf.cast(mnist_images[...,tf.newaxis]/255, tf.float32),
tf.cast(mnist_labels,tf.int64)))
dataset = dataset.shuffle(1000).batch(32)
# 모델 생성
mnist_model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,[3,3], activation='relu',
input_shape=(None, None, 1)),
tf.keras.layers.Conv2D(16,[3,3], activation='relu'),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(10)
])
즉시 실행에서는 훈련을 하지 않아도 모델을 사용하고 결과를 점검할 수 있습니다:
for images,labels in dataset.take(1):
print("로짓: ", mnist_model(images[0:1]).numpy())
로짓: [[ 0.00129889 0.01228362 -0.0372225 0.01005802 -0.00351836 0.0153954 -0.01946059 -0.00020366 -0.03208666 -0.06244648]]
케라스 모델은 자체적인 훈련 메서드(fit)을 포함하고 있지만 때로는 좀 더 수정할 필요가 있습니다. 다음은 즉시 실행을 활용한 반복적인 훈련의 예입니다:
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
loss_history = []
def train_step(images, labels):
with tf.GradientTape() as tape:
logits = mnist_model(images, training=True)
# 결과의 형태를 확인하기 위해서 단언문 추가
tf.debugging.assert_equal(logits.shape, (32, 10))
loss_value = loss_object(labels, logits)
loss_history.append(loss_value.numpy().mean())
grads = tape.gradient(loss_value, mnist_model.trainable_variables)
optimizer.apply_gradients(zip(grads, mnist_model.trainable_variables))
def train():
for epoch in range(3):
for (batch, (images, labels)) in enumerate(dataset):
train_step(images, labels)
print ('에포크 {} 종료'.format(epoch))
train()
WARNING:tensorflow:5 out of the last 5 calls to <function _BaseOptimizer._update_step_xla at 0x7f07ac1389d0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details. WARNING:tensorflow:6 out of the last 6 calls to <function _BaseOptimizer._update_step_xla at 0x7f07ac1389d0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details. 에포크 0 종료 에포크 1 종료 에포크 2 종료
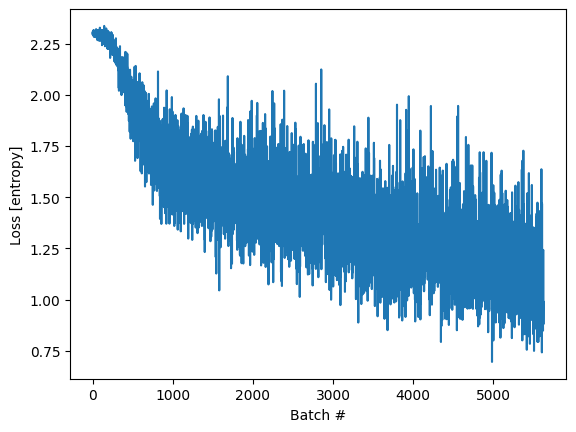
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.xlabel('Batch #')
plt.ylabel('Loss [entropy]')
Text(0, 0.5, 'Loss [entropy]')
변수와 옵티마이저
tf.Variable 객체는 자동 미분을 쉽게 하기 위해서 학습동안 변경된 tf.Tensor 값을 저장합니다.
모델 파라미터는 클래스 인스턴스 변수로 캡슐화될 수 있습니다.
효과적으로 모델 파라미터를 캡슐화하려면 tf.Variable을 tf.GradientTape과 함께 사용합니다.
예를 들어, 위의 자동 미분은 다음과 같이 재작성 가능합니다:
class Model(tf.keras.Model):
def __init__(self):
super(Model, self).__init__()
self.W = tf.Variable(5., name='weight')
self.B = tf.Variable(10., name='bias')
def call(self, inputs):
return inputs * self.W + self.B
# 약 3 * x + 2개의 점으로 구성된 실험 데이터
NUM_EXAMPLES = 2000
training_inputs = tf.random.normal([NUM_EXAMPLES])
noise = tf.random.normal([NUM_EXAMPLES])
training_outputs = training_inputs * 3 + 2 + noise
# 최적화할 손실함수
def loss(model, inputs, targets):
error = model(inputs) - targets
return tf.reduce_mean(tf.square(error))
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets)
return tape.gradient(loss_value, [model.W, model.B])
# 정의:
# 1. 모델
# 2. 모델 파라미터에 대한 손실 함수의 미분
# 3. 미분에 기초한 변수 업데이트 전략
model = Model()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
print("초기 손실: {:.3f}".format(loss(model, training_inputs, training_outputs)))
# 반복 훈련
for i in range(300):
grads = grad(model, training_inputs, training_outputs)
optimizer.apply_gradients(zip(grads, [model.W, model.B]))
if i % 20 == 0:
print("스텝 {:03d}에서 손실: {:.3f}".format(i, loss(model, training_inputs, training_outputs)))
print("최종 손실: {:.3f}".format(loss(model, training_inputs, training_outputs)))
print("W = {}, B = {}".format(model.W.numpy(), model.B.numpy()))
초기 손실: 68.819 스텝 000에서 손실: 66.154 스텝 020에서 손실: 30.232 스텝 040에서 손실: 14.127 스텝 060에서 손실: 6.906 스텝 080에서 손실: 3.667 스텝 100에서 손실: 2.214 스텝 120에서 손실: 1.562 스텝 140에서 손실: 1.270 스텝 160에서 손실: 1.139 스텝 180에서 손실: 1.080 스텝 200에서 손실: 1.053 스텝 220에서 손실: 1.041 스텝 240에서 손실: 1.036 스텝 260에서 손실: 1.034 스텝 280에서 손실: 1.033 최종 손실: 1.032 W = 3.00956130027771, B = 1.9996976852416992
즉시 실행에서 상태를 위한 객체 사용
텐서플로 1.x 그래프 실행에서, 프로그램 상태(예: 변수)는 전역 컬렉션에 저장되고 그 수명은 tf.Session 객체에 의해서 관리됩니다.
반면에 즉시 실행에서 상태 객체 수명은 그와 관련된 파이썬 객체 수명에 의해서 결정됩니다.
변수는 객체입니다
즉시 실행에서 변수는 그 객체의 마지막 참조가 제거될 때까지 유지되고 그 이후 삭제됩니다.
if tf.config.experimental.list_physical_devices("GPU"):
with tf.device("gpu:0"):
print("GPU 사용 가능")
v = tf.Variable(tf.random.normal([1000, 1000]))
v = None # v는 더이상 GPU 메모리를 사용하지 않음
GPU 사용 가능
객체 기반의 저장
이번 장은 훈련 체크포인트 가이드 요약버전입니다.
tf.train.Checkpoint는 tf.Variable을 체크포인트 파일로 저장하거나 체크포인트 파일에서 복구할 수 있습니다:
x = tf.Variable(10.)
checkpoint = tf.train.Checkpoint(x=x)
x.assign(2.) # 변수에 새로운 값을 할당하고 저장
checkpoint_path = './ckpt/'
checkpoint.save('./ckpt/')
'./ckpt/-1'
x.assign(11.) # 저장한 후에 변수 변경
# 체크포인트로부터 값을 복구
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_path))
print(x) # => 2.0
<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=2.0>
모델을 저장하거나 읽어들이기 위해서, tf.train.Checkpoint는 숨겨진 변수를 요구하지 않고 객체 내부 상태를 저장합니다.
옵티마이저와 모델, 전역 단계 상태를 기록하려면 tf.train.Checkpoint에 전달하면 됩니다:
import os
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,[3,3], activation='relu'),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(10)
])
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
checkpoint_dir = 'path/to/model_dir'
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
root = tf.train.Checkpoint(optimizer=optimizer,
model=model)
root.save(checkpoint_prefix)
root.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f07a00a5b20>
객체 지향형 지표
tf.keras.metrics는 객체로 저장됩니다.
새로운 데이터를 이 객체에 전달하여 지표를 수정하고 tf.keras.metrics.result 메서드를 사용해 그 결과를 얻습니다.
예를 들어:
m = tf.keras.metrics.Mean("loss")
m(0)
m(5)
m.result() # => 2.5
m([8, 9])
m.result() # => 5.5
<tf.Tensor: shape=(), dtype=float32, numpy=5.5>
서머리(summary)와 텐서보드
텐서보드는 훈련과정에서 모델을 파악하거나 디버깅하고 최적화하기 위해 사용하는 시각화 도구입니다. 텐서보드는 프로그램이 실행되는 동안 작성된 서머리 이벤트를 사용합니다.
즉시 실행에서 변수의 서머리 정보를 기록하기 위해서 tf.summary를 사용합니다.
예를 들어, 다음은 매 100번째 훈련마다 loss의 서머리 정보를 기록합니다:
logdir = "./tb/"
writer = tf.summary.create_file_writer(logdir)
with writer.as_default(): # 또는 반복 전에 writer.set_as_default()를 호출
for i in range(1000):
step = i + 1
# 실제 훈련 함수로 손실을 계산
loss = 1 - 0.001 * step
if step % 100 == 0:
tf.summary.scalar('손실', loss, step=step)
ls tb/events.out.tfevents.1671052246.kokoro-gcp-ubuntu-prod-1438429585.86417.0.v2
자동 미분 관련 고급편
동적 모델
tf.GradientTape는 또한 동적인 모델에서도 사용가능합니다.
아래 예는 역추적 길찾기 알고리즘의 복잡한 제어 흐름에도 불구하고,
그래디언트가 있으며 미분 가능이 하다는 것을 제외하면 일반적인 NumPy으로 작성한 코드처럼 보입니다:
def line_search_step(fn, init_x, rate=1.0):
with tf.GradientTape() as tape:
# 변수는 자동적으로 기록되지만 텐서는 사용자가 스스로 확인해야 함
tape.watch(init_x)
value = fn(init_x)
grad = tape.gradient(value, init_x)
grad_norm = tf.reduce_sum(grad * grad)
init_value = value
while value > init_value - rate * grad_norm:
x = init_x - rate * grad
value = fn(x)
rate /= 2.0
return x, value
사용자 정의 그래디언트
사용자 정의 그래디언트는 그래디언트를 재정의(override)하는 가장 쉬운 방법입니다. 정방향 함수안에서 입력값 또는 출력값, 중간값과 관련된 그래디언트를 정의해야 합니다. 예를 들어 다음은 역전파 과정에서 그래디언트의 놈(norm)을 클리핑(clip)하는 가장 쉬운 방법입니다:
@tf.custom_gradient
def clip_gradient_by_norm(x, norm):
y = tf.identity(x)
def grad_fn(dresult):
return [tf.clip_by_norm(dresult, norm), None]
return y, grad_fn
사용자 정의 그래디언트는 일반적으로 연산에 대해 수치적으로(numerically) 안정된 그래디언트를 제공하기 위해 사용됩니다:
def log1pexp(x):
return tf.math.log(1 + tf.exp(x))
def grad_log1pexp(x):
with tf.GradientTape() as tape:
tape.watch(x)
value = log1pexp(x)
return tape.gradient(value, x)
# 그래디언트 계산은 x = 0일 때 잘 동작
grad_log1pexp(tf.constant(0.)).numpy()
0.5
# 그러나, x = 100일 때 수치적으로 불안정하기 때문에 실패
grad_log1pexp(tf.constant(100.)).numpy()
nan
여기 log1pexp 함수는 이론적으로 사용자 정의 그래디언트를 활용해 간결해 질 수 있습니다.
아래 구현은 불필요한 계산을 제거함으로써 계산을 좀 더 효율적으로 하기 위해 정방향 경로안에서 계산된 tf.exp(x)값을 재사용합니다:
@tf.custom_gradient
def log1pexp(x):
e = tf.exp(x)
def grad(dy):
return dy * (1 - 1 / (1 + e))
return tf.math.log(1 + e), grad
def grad_log1pexp(x):
with tf.GradientTape() as tape:
tape.watch(x)
value = log1pexp(x)
return tape.gradient(value, x)
# 전처럼, 그래디언트 계산은 x = 0일 때 잘 동작
grad_log1pexp(tf.constant(0.)).numpy()
0.5
# 그래디언트 계산은 x = 100일 때 역시 잘 동작
grad_log1pexp(tf.constant(100.)).numpy()
1.0
성능
즉시 실행에서 계산은 자동으로 GPU로 분배됩니다.
만약 계산 분배를 사용자가 제어하고 싶다면 그 부분을 tf.device('/gpu:0') 블록 (또는 CPU도 동일)으로 감싸서 실행하세요:
import time
def measure(x, steps):
# 텐서플로는 처음 사용할 때 GPU를 초기화, 시간계산에서 제외
tf.matmul(x, x)
start = time.time()
for i in range(steps):
x = tf.matmul(x, x)
# tf.matmul는 행렬 곱셈을 완료하기 전에 결과를 반환할 수 있습니다
# (예, CUDA 스트림 대기열에 연산을 추가한 후에 결과를 반환할 수 있다).
# 아래 x.numpy() 호출은 대기열에 추가된 모든 연산이 완료될 것임을 보장합니다
# (그리고 그 결과가 호스트 메모리에 복사될 것이고,
# 그래서 matnul 연산시간보다는 조금 많은 연산시간이
# 포함됩니다).
_ = x.numpy()
end = time.time()
return end - start
shape = (1000, 1000)
steps = 200
print("{} 크기 행렬을 자기 자신과 {}번 곱했을 때 걸리는 시간:".format(shape, steps))
# CPU에서 실행:
with tf.device("/cpu:0"):
print("CPU: {} 초".format(measure(tf.random.normal(shape), steps)))
# GPU에서 실행, 가능하다면:
if tf.config.experimental.list_physical_devices("GPU"):
with tf.device("/gpu:0"):
print("GPU: {} 초".format(measure(tf.random.normal(shape), steps)))
else:
print("GPU: 없음")
(1000, 1000) 크기 행렬을 자기 자신과 200번 곱했을 때 걸리는 시간: CPU: 0.4814612865447998 초 GPU: 0.0684516429901123 초
tf.Tensor 객체는 실제로 그 연산을 수행할 다른 디바이스로 복사될 수 있습니다:
if tf.config.experimental.list_physical_devices("GPU"):
x = tf.random.normal([10, 10])
x_gpu0 = x.gpu()
x_cpu = x.cpu()
_ = tf.matmul(x_cpu, x_cpu) # CPU에서 실행
_ = tf.matmul(x_gpu0, x_gpu0) # GPU:0에서 실행
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_86417/2531695931.py:4: _EagerTensorBase.gpu (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.identity instead. WARNING:tensorflow:From /tmpfs/tmp/ipykernel_86417/2531695931.py:5: _EagerTensorBase.cpu (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.identity instead.
벤치마크
GPU에서 학습을 하는 ResNet50 같은 계산량이 많은 모델에서,
즉시 실행 성능은 tf.function 실행과 비교될 수 있습니다.
그러나 이러한 차이는 계산량이 작은 모델인 경우 더 커지고, 수많은 작은 연산으로 구성된 모델은 자주 반복되는 부분을 최적화하는 사례도 있습니다.
함수를 활용
즉시 실행이 개발과 디버깅 과정을 좀 더 대화형(interactive)으로 만들어 주지만
텐서플로 1.x 형태 그래프 실행은 학습의 분산과 성능, 운영 배포에 장점을 가지고 있습니다.
이러한 차이를 해소하기 위해서, 텐서플로 2.0에서는 tf.function API를 도입했습니다.
자세한 내용은 tf.function 가이드를 참고하세요.