
Walidacja danych TensorFlow (TFDV) może analizować dane szkoleniowe i udostępniające w celu:
obliczać statystyki opisowe,
wywnioskować schemat ,
wykrywać anomalie danych .
Podstawowy interfejs API obsługuje każdy element funkcjonalności za pomocą wygodnych metod, które można rozbudować i które można wywołać w kontekście notatników.
Obliczanie opisowej statystyki danych
TFDV może obliczać statystyki opisowe, które zapewniają szybki przegląd danych pod względem występujących cech i kształtów ich rozkładów wartości. Narzędzia takie jak Przegląd aspektów mogą zapewnić zwięzłą wizualizację tych statystyk w celu ułatwienia przeglądania.
Załóżmy na przykład, że path wskazuje plik w formacie TFRecord (w którym przechowywane są rekordy typu tensorflow.Example ). Poniższy fragment ilustruje obliczanie statystyk przy użyciu TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
Zwracana wartość to bufor protokołu DatasetFeatureStatisticsList . Przykładowy notatnik zawiera wizualizację statystyk przy użyciu Przeglądu aspektów :
tfdv.visualize_statistics(stats)
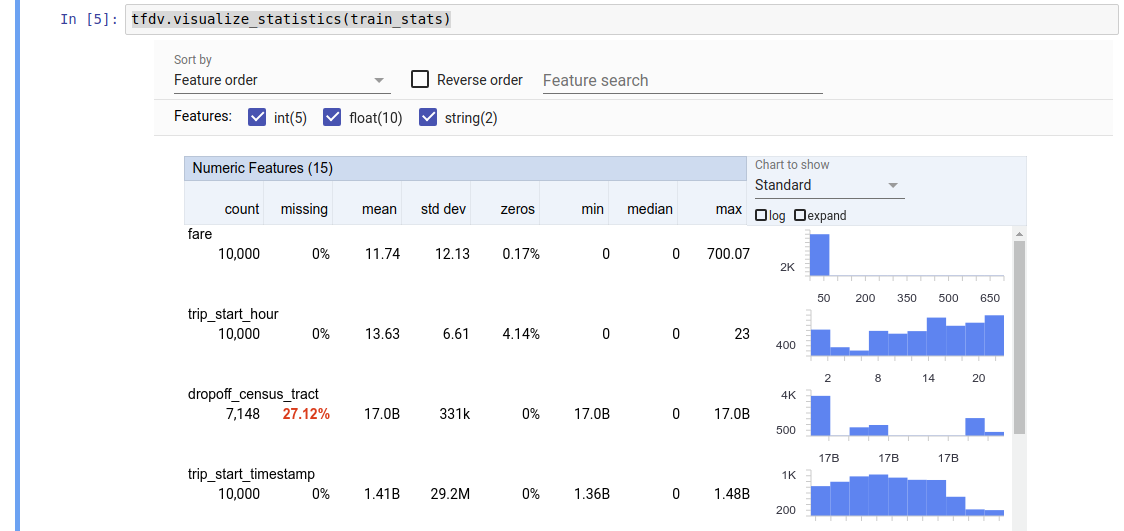
W poprzednim przykładzie założono, że dane są przechowywane w pliku TFRecord . TFDV obsługuje również format wejściowy CSV, z możliwością rozszerzenia na inne popularne formaty. Dostępne dekodery danych znajdziesz tutaj . Ponadto TFDV udostępnia funkcję użytkową tfdv.generate_statistics_from_dataframe dla użytkowników, których dane w pamięci są reprezentowane jako pandas DataFrame.
Oprócz obliczania domyślnego zestawu statystyk danych, TFDV może również obliczać statystyki dla domen semantycznych (np. obrazów, tekstu). Aby włączyć obliczanie statystyk domeny semantycznej, przekaż obiekt tfdv.StatsOptions z enable_semantic_domain_stats ustawioną na True do tfdv.generate_statistics_from_tfrecord .
Działa w chmurze Google
Wewnętrznie TFDV wykorzystuje platformę przetwarzania równoległego danych Apache Beam do skalowania obliczeń statystycznych na dużych zbiorach danych. W przypadku aplikacji, które chcą głębiej zintegrować się z TFDV (np. dołączanie generowania statystyk na końcu potoku generowania danych, generowanie statystyk dla danych w niestandardowym formacie ), API udostępnia również Beam PTransform do generowania statystyk.
Aby uruchomić TFDV w Google Cloud, należy pobrać plik koła TFDV i udostępnić pracownikom Dataflow. Pobierz plik koła do bieżącego katalogu w następujący sposób:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
Poniższy fragment przedstawia przykładowe użycie TFDV w Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
W tym przypadku wygenerowany proto statystyki jest przechowywany w pliku TFRecord zapisanym w GCS_STATS_OUTPUT_PATH .
UWAGA Podczas wywoływania dowolnej funkcji tfdv.generate_statistics_... (np. tfdv.generate_statistics_from_tfrecord ) w Google Cloud należy podać ścieżkę output_path . Określenie Brak może spowodować błąd.
Wnioskowanie schematu na podstawie danych
Schemat opisuje oczekiwane właściwości danych. Niektóre z tych właściwości to:
- jakich funkcji oczekuje się, że będą obecne
- ich typ
- liczba wartości cechy w każdym przykładzie
- obecność każdej cechy we wszystkich przykładach
- oczekiwane domeny cech.
Krótko mówiąc, schemat opisuje oczekiwania dotyczące „poprawnych” danych i dlatego można go wykorzystać do wykrywania błędów w danych (opisane poniżej). Co więcej, tego samego schematu można użyć do skonfigurowania TensorFlow Transform na potrzeby transformacji danych. Należy zauważyć, że schemat powinien być dość statyczny, np. kilka zbiorów danych może być zgodnych z tym samym schematem, podczas gdy statystyki (opisane powyżej) mogą się różnić w zależności od zbioru danych.
Ponieważ pisanie schematu może być żmudnym zadaniem, zwłaszcza w przypadku zbiorów danych z dużą liczbą funkcji, TFDV zapewnia metodę generowania początkowej wersji schematu w oparciu o statystyki opisowe:
schema = tfdv.infer_schema(stats)
Ogólnie rzecz biorąc, TFDV wykorzystuje konserwatywną heurystykę do wnioskowania o stabilnych właściwościach danych na podstawie statystyk, aby uniknąć nadmiernego dopasowania schematu do określonego zbioru danych. Zdecydowanie zaleca się przejrzenie wywnioskowanego schematu i udoskonalenie go w razie potrzeby , aby uchwycić całą wiedzę dziedzinową dotyczącą danych, które mogły zostać przeoczone przez heurystykę TFDV.
Domyślnie tfdv.infer_schema wnioskuje kształt każdej wymaganej cechy, jeśli value_count.min jest równa value_count.max dla tej funkcji. Ustaw argument infer_feature_shape na False, aby wyłączyć wnioskowanie o kształcie.
Sam schemat jest przechowywany jako bufor protokołu schematu i dlatego można go aktualizować/edytować przy użyciu standardowego interfejsu API bufora protokołu. TFDV udostępnia także kilka narzędzi ułatwiających przeprowadzanie aktualizacji. Załóżmy na przykład, że schemat zawiera następującą sekcję opisującą wymaganą funkcję ciągu payment_type , która przyjmuje pojedynczą wartość:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Aby zaznaczyć, że funkcja powinna być wypełniona w co najmniej 50% przykładów:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
Przykładowy notatnik zawiera prostą wizualizację schematu w postaci tabeli, zawierającą listę każdej funkcji i jej głównych cech zakodowanych w schemacie.
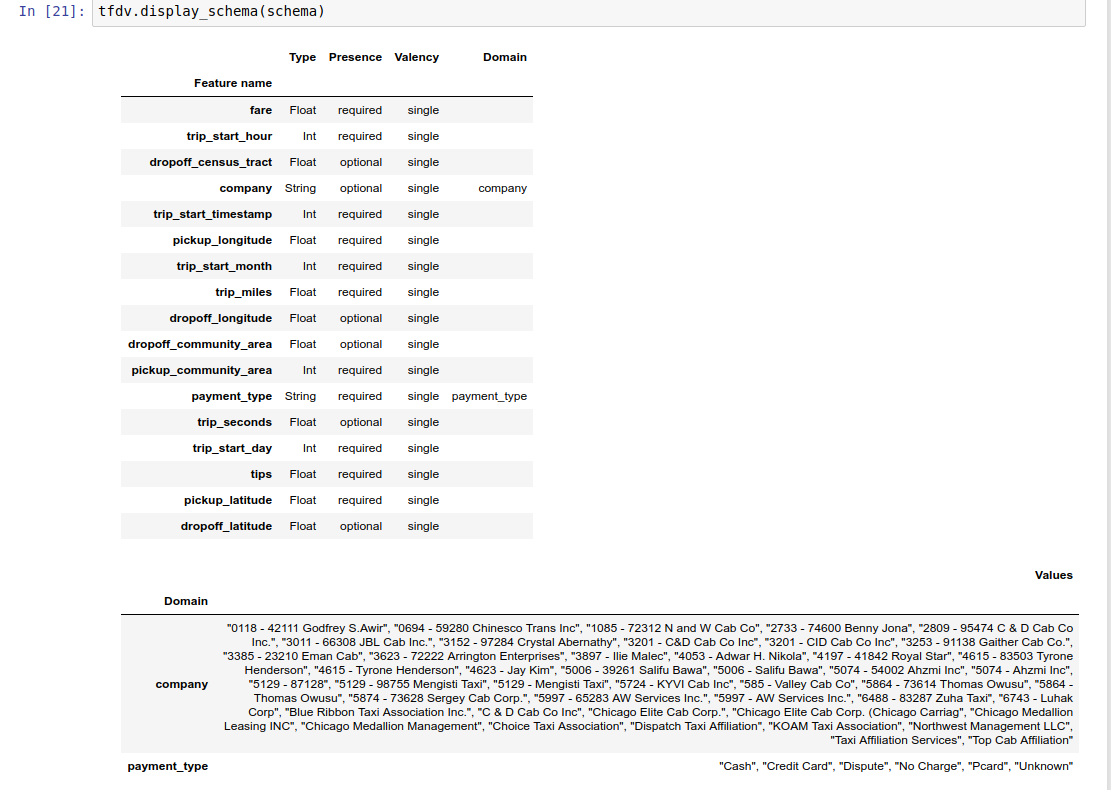
Sprawdzanie danych pod kątem błędów
Mając schemat, można sprawdzić, czy zbiór danych jest zgodny z oczekiwaniami określonymi w schemacie lub czy występują w nim jakieś anomalie . Możesz sprawdzić dane pod kątem błędów (a) zbiorczo w całym zbiorze danych, dopasowując statystyki zbioru danych do schematu lub (b) sprawdzając błędy w poszczególnych przykładach.
Dopasowywanie statystyk zbioru danych do schematu
Aby sprawdzić błędy w agregacji, TFDV dopasowuje statystyki zbioru danych do schematu i zaznacza wszelkie rozbieżności. Na przykład:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
Wynikiem jest instancja bufora protokołu Anomalies i opisuje wszelkie błędy, w których statystyki nie zgadzają się ze schematem. Załóżmy na przykład, że dane w other_path zawierają przykłady z wartościami dla funkcji payment_type spoza domeny określonej w schemacie.
To powoduje anomalię
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
wskazując, że w statystykach znaleziono wartość spoza domeny dla < 1% wartości cech.
Jeśli tego oczekiwano, schemat można zaktualizować w następujący sposób:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Jeśli anomalia rzeczywiście wskazuje na błąd danych, należy naprawić podstawowe dane przed użyciem ich do szkolenia.
Tutaj wymieniono różne typy anomalii, które może wykryć ten moduł.
Przykładowy notatnik zawiera prostą wizualizację anomalii w postaci tabeli, zawierającą listę funkcji, w których wykryto błędy, oraz krótki opis każdego błędu.

Sprawdzanie błędów na podstawie przykładu
TFDV zapewnia również opcję sprawdzania poprawności danych dla każdego przykładu, zamiast porównywać statystyki całego zbioru danych ze schematem. TFDV udostępnia funkcje sprawdzania danych dla każdego przykładu, a następnie generowania statystyk podsumowujących dla znalezionych nietypowych przykładów. Na przykład:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats zwracane przez validate_examples_in_tfrecord to bufor protokołu DatasetFeatureStatisticsList , w którym każdy zestaw danych składa się z zestawu przykładów wykazujących określoną anomalię. Można to wykorzystać do określenia liczby przykładów w zbiorze danych, które wykazują daną anomalię, oraz charakterystyki tych przykładów.
Środowiska schematów
Domyślnie w walidacjach zakłada się, że wszystkie zestawy danych w potoku są zgodne z jednym schematem. W niektórych przypadkach konieczne jest wprowadzenie niewielkich zmian w schemacie, na przykład funkcje używane jako etykiety są wymagane podczas szkolenia (i powinny zostać sprawdzone), ale brakuje ich podczas udostępniania.
Do wyrażenia takich wymagań można używać środowisk . W szczególności funkcje w schemacie można powiązać z zestawem środowisk przy użyciu ustawień default_environment, in_environment i not_in_environment.
Na przykład, jeśli funkcja wskazówek jest używana jako etykieta podczas szkolenia, ale brakuje jej w udostępnianych danych. Bez określonego środowiska będzie to widoczne jako anomalia.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Aby to naprawić, musimy ustawić domyślne środowisko dla wszystkich funkcji na „SZKOLENIE” i „SERVING” oraz wykluczyć funkcję „wskazówek” ze środowiska SERVING.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Sprawdzanie odchylenia i dryfu danych
Oprócz sprawdzania, czy zbiór danych jest zgodny z oczekiwaniami określonymi w schemacie, TFDV zapewnia również funkcje umożliwiające wykrycie:
- różnica między danymi szkoleniowymi i udostępnianymi
- dryft pomiędzy różnymi dniami danych treningowych
TFDV przeprowadza tę kontrolę, porównując statystyki różnych zbiorów danych w oparciu o komparatory dryfu/skosu określone w schemacie. Na przykład, aby sprawdzić, czy istnieje jakakolwiek rozbieżność między funkcją „payment_type” w zbiorze danych szkoleniowych i obsługujących:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
UWAGA Norma L-infinity wykrywa odchylenia tylko dla cech kategorycznych. Zamiast określać próg infinity_norm , określenie progu jensen_shannon_divergence w skew_comparator wykryje zniekształcenie zarówno dla cech numerycznych, jak i kategorycznych.
To samo dotyczy sprawdzania, czy zestaw danych jest zgodny z oczekiwaniami określonymi w schemacie, wynik jest również instancją bufora protokołu Anomalies i opisuje wszelkie odchylenia między zbiorami danych szkoleniowymi i obsługującymi. Załóżmy na przykład, że udostępniane dane zawierają znacznie więcej przykładów, a funkcja payement_type ma wartość Cash , co powoduje anomalię przekrzywienia
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Jeśli anomalia rzeczywiście wskazuje na rozbieżność między danymi szkoleniowymi i udostępniającymi, konieczne są dalsze badania, ponieważ może to mieć bezpośredni wpływ na wydajność modelu.
Przykładowy notatnik zawiera prosty przykład sprawdzania anomalii opartych na skośności.
Wykrywanie dryftu pomiędzy różnymi dniami danych treningowych można przeprowadzić w podobny sposób
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
UWAGA Norma L-infinity wykrywa odchylenia tylko dla cech kategorycznych. Zamiast określać próg infinity_norm , określenie progu jensen_shannon_divergence w skew_comparator wykryje zniekształcenie zarówno dla cech numerycznych, jak i kategorycznych.
Pisanie niestandardowego łącznika danych
Aby obliczyć statystyki danych, TFDV udostępnia kilka wygodnych metod obsługi danych wejściowych w różnych formatach (np. TFRecord z tf.train.Example , CSV, itp.). Jeśli Twojego formatu danych nie ma na tej liście, musisz napisać niestandardowy konektor danych do odczytu danych wejściowych i połączyć go z podstawowym interfejsem API TFDV w celu obliczania statystyk danych.
Podstawowym interfejsem API TFDV do obliczania statystyk danych jest Beam PTransform , który pobiera PCollection partii przykładów wejściowych (partia przykładów wejściowych jest reprezentowana jako Arrow RecordBatch) i generuje PCollection zawierającą pojedynczy bufor protokołu DatasetFeatureStatisticsList .
Po zaimplementowaniu niestandardowego łącznika danych, który grupuje przykłady wejściowe w Arrow RecordBatch, należy połączyć go z interfejsem API tfdv.GenerateStatistics w celu obliczenia statystyk danych. Weźmy na przykład TFRecord z tf.train.Example . tfx_bsl udostępnia łącznik danych TFExampleRecord , a poniżej znajduje się przykład połączenia go z interfejsem API tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Obliczanie statystyk na wycinkach danych
TFDV można skonfigurować tak, aby obliczał statystyki na wycinkach danych. Krojenie można włączyć, udostępniając funkcje krojenia, które pobierają Arrow RecordBatch i wysyłają sekwencję krotek formularza (slice key, record batch) . TFDV zapewnia łatwy sposób generowania funkcji wycinania opartych na wartościach cech , które można udostępnić jako część tfdv.StatsOptions podczas obliczania statystyk.
Gdy dzielenie na plasterki jest włączone, wyjściowy proto DatasetFeatureStatisticsList zawiera wiele proto DatasetFeatureStatistics , po jednym dla każdego wycinka. Każdy wycinek jest identyfikowany przez unikalną nazwę, która jest ustawiana jako nazwa zestawu danych w proto DatasetFeatureStatistics . Domyślnie TFDV oprócz skonfigurowanych wycinków oblicza statystyki dla całego zbioru danych.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])