
ML Metadata (MLMD) es una biblioteca para registrar y recuperar metadatos asociados con los flujos de trabajo de desarrolladores de ML y científicos de datos. MLMD es una parte integral de TensorFlow Extended (TFX) , pero está diseñado para que pueda usarse de forma independiente.
Cada ejecución de una canalización de ML de producción genera metadatos que contienen información sobre los diversos componentes de la canalización, sus ejecuciones (por ejemplo, ejecuciones de entrenamiento) y artefactos resultantes (por ejemplo, modelos entrenados). En caso de errores o comportamientos inesperados de la canalización, estos metadatos se pueden aprovechar para analizar el linaje de los componentes de la canalización y depurar problemas. Piense en estos metadatos como el equivalente a iniciar sesión en el desarrollo de software.
MLMD lo ayuda a comprender y analizar todas las partes interconectadas de su canal de ML en lugar de analizarlas de forma aislada y puede ayudarlo a responder preguntas sobre su canal de ML, como:
- ¿En qué conjunto de datos se entrenó el modelo?
- ¿Cuáles fueron los hiperparámetros utilizados para entrenar el modelo?
- ¿Qué tramo de tubería creó el modelo?
- ¿Qué entrenamiento condujo a este modelo?
- ¿Qué versión de TensorFlow creó este modelo?
- ¿Cuándo se impulsó el modelo fallido?
almacén de metadatos
MLMD registra los siguientes tipos de metadatos en una base de datos llamada Metadata Store .
- Metadatos sobre los artefactos generados a través de los componentes/pasos de sus canalizaciones de ML
- Metadatos sobre las ejecuciones de estos componentes/pasos.
- Metadatos sobre tuberías e información de linaje asociada.
El almacén de metadatos proporciona API para registrar y recuperar metadatos hacia y desde el backend de almacenamiento. El backend de almacenamiento es conectable y ampliable. MLMD proporciona implementaciones de referencia para SQLite (que admite memoria y disco) y MySQL listas para usar.
Este gráfico muestra una descripción general de alto nivel de los diversos componentes que forman parte de MLMD.
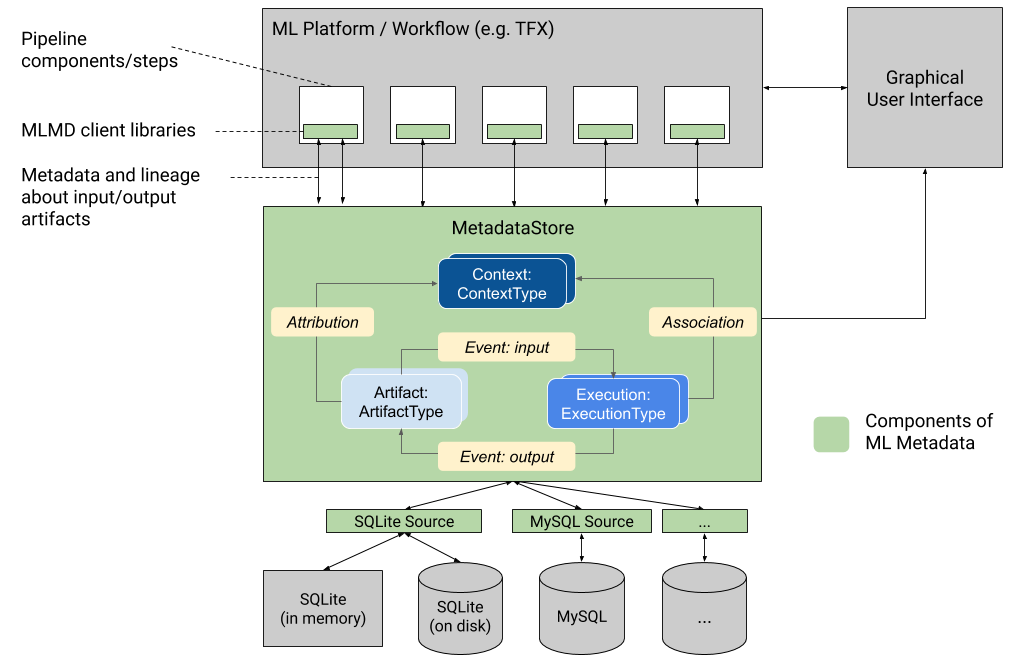
Backends de almacenamiento de metadatos y configuración de conexión de tienda
El objeto MetadataStore recibe una configuración de conexión que corresponde al backend de almacenamiento utilizado.
- Fake Database proporciona una base de datos en memoria (usando SQLite) para experimentación rápida y ejecuciones locales. La base de datos se elimina cuando se destruye el objeto de la tienda.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite lee y escribe archivos desde el disco.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL se conecta a un servidor MySQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
De manera similar, cuando se usa una instancia de MySQL con Google CloudSQL ( inicio rápido , descripción general de conexión ), también se puede usar la opción SSL, si corresponde.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL se conecta a un servidor PostgreSQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
De manera similar, cuando se usa una instancia de PostgreSQL con Google CloudSQL ( inicio rápido , descripción general de conexión ), también se puede usar la opción SSL, si corresponde.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
Modelo de datos
El almacén de metadatos utiliza el siguiente modelo de datos para registrar y recuperar metadatos del backend de almacenamiento.
-
ArtifactTypedescribe el tipo de artefacto y sus propiedades que se almacenan en el almacén de metadatos. Puede registrar estos tipos sobre la marcha con el almacén de metadatos en código, o puede cargarlos en el almacén desde un formato serializado. Una vez que registra un tipo, su definición está disponible durante toda la vida útil de la tienda. - Un
Artifactdescribe una instancia específica deArtifactTypey sus propiedades que se escriben en el almacén de metadatos. - Un
ExecutionTypedescribe un tipo de componente o paso en un flujo de trabajo y sus parámetros de tiempo de ejecución. - Una
Executiones un registro de la ejecución de un componente o un paso en un flujo de trabajo de ML y los parámetros de tiempo de ejecución. Una ejecución puede considerarse como una instancia deExecutionType. Las ejecuciones se registran cuando ejecuta una canalización o paso de ML. - Un
Eventes un registro de la relación entre artefactos y ejecuciones. Cuando ocurre una ejecución, los eventos registran cada artefacto que se utilizó en la ejecución y cada artefacto que se produjo. Estos registros permiten el seguimiento del linaje a lo largo de un flujo de trabajo. Al observar todos los eventos, MLMD sabe qué ejecuciones ocurrieron y qué artefactos se crearon como resultado. Luego, MLMD puede recurrir desde cualquier artefacto a todas sus entradas ascendentes. - Un
ContextTypedescribe un tipo de grupo conceptual de artefactos y ejecuciones en un flujo de trabajo, y sus propiedades estructurales. Por ejemplo: proyectos, ejecuciones de tuberías, experimentos, propietarios, etc. - Un
Contextes una instancia de unContextType. Captura la información compartida dentro del grupo. Por ejemplo: nombre del proyecto, ID de confirmación de la lista de cambios, anotaciones de experimentos, etc. Tiene un nombre único definido por el usuario dentro de suContextType. - Una
Attributiones un registro de la relación entre artefactos y contextos. - Una
Associationes un registro de la relación entre ejecuciones y contextos.
Funcionalidad MLMD
El seguimiento de las entradas y salidas de todos los componentes/pasos de un flujo de trabajo de ML y su linaje permite que las plataformas de ML habiliten varias características importantes. La siguiente lista proporciona una descripción general no exhaustiva de algunos de los principales beneficios.
- Enumere todos los artefactos de un tipo específico. Ejemplo: todos los Modelos que han sido entrenados.
- Cargue dos artefactos del mismo tipo para comparar. Ejemplo: comparar resultados de dos experimentos.
- Muestre un DAG de todas las ejecuciones relacionadas y sus artefactos de entrada y salida de un contexto. Ejemplo: visualizar el flujo de trabajo de un experimento para depuración y descubrimiento.
- Regrese a todos los eventos para ver cómo se creó un artefacto. Ejemplos: ver qué datos se incluyeron en un modelo; hacer cumplir los planes de retención de datos.
- Identifique todos los artefactos que se crearon utilizando un artefacto determinado. Ejemplos: ver todos los modelos entrenados a partir de un conjunto de datos específico; marcar modelos basados en datos incorrectos.
- Determine si se ha ejecutado una ejecución en las mismas entradas antes. Ejemplo: determine si un componente/paso ya ha completado el mismo trabajo y el resultado anterior puede simplemente reutilizarse.
- Registre y consulte el contexto de las ejecuciones del flujo de trabajo. Ejemplos: realizar un seguimiento del propietario y la lista de cambios utilizados para la ejecución de un flujo de trabajo; agrupar el linaje por experimentos; gestionar artefactos por proyectos.
- Capacidades de filtrado de nodos declarativos en propiedades y nodos de vecindad de 1 salto. Ejemplos: buscar artefactos de un tipo y bajo algún contexto de canalización; devolver artefactos escritos donde el valor de una propiedad determinada está dentro de un rango; encontrar ejecuciones anteriores en un contexto con las mismas entradas.
Consulte el tutorial de MLMD para ver un ejemplo que muestra cómo utilizar la API de MLMD y el almacén de metadatos para recuperar información de linaje.
Integre metadatos de ML en sus flujos de trabajo de ML
Si es un desarrollador de plataformas interesado en integrar MLMD en su sistema, utilice el flujo de trabajo de ejemplo siguiente para utilizar las API de MLMD de bajo nivel para realizar un seguimiento de la ejecución de una tarea de capacitación. También puede utilizar API de Python de nivel superior en entornos de portátiles para registrar metadatos de experimentos.
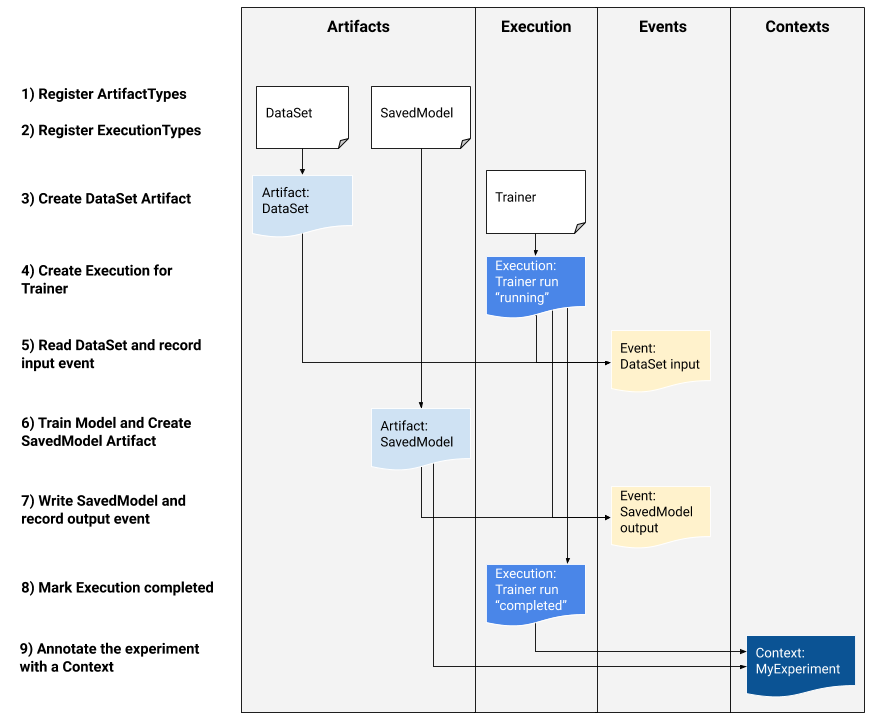
1) Registrar tipos de artefactos
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) Registre los tipos de ejecución para todos los pasos del flujo de trabajo de ML
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) Crear un artefacto de DataSet ArtifactType
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) Crear una ejecución de la ejecución del Entrenador.
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) Definir el evento de entrada y leer datos.
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) Declarar el artefacto de salida
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) Registre el evento de salida
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) Marcar la ejecución como completada.
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) Agrupar artefactos y ejecuciones bajo un contexto utilizando artefactos de atribuciones y afirmaciones.
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
Utilice MLMD con un servidor gRPC remoto
Puede usar MLMD con servidores gRPC remotos como se muestra a continuación:
- Iniciar un servidor
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
De forma predeterminada, el servidor utiliza una base de datos en memoria falsa por solicitud y no conserva los metadatos entre las llamadas. También se puede configurar con MLMD MetadataStoreServerConfig para usar archivos SQLite o instancias MySQL. La configuración se puede almacenar en un archivo protobuf de texto y pasar al binario con --metadata_store_server_config_file=path_to_the_config_file .
Un ejemplo de archivo MetadataStoreServerConfig en formato de texto protobuf:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- Cree el código auxiliar del cliente y utilícelo en Python
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- Utilice MLMD con llamadas RPC
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
Recursos
La biblioteca MLMD tiene una API de alto nivel que puede usar fácilmente con sus canalizaciones de ML. Consulte la documentación de la API MLMD para obtener más detalles.
Consulte el filtrado de nodos declarativos de MLMD para aprender a utilizar las capacidades de filtrado de nodos declarativos de MLMD en propiedades y nodos vecinos de 1 salto.
Consulte también el tutorial de MLMD para aprender a utilizar MLMD para rastrear el linaje de los componentes de su canalización.
MLMD proporciona utilidades para manejar migraciones de esquemas y datos entre versiones. Consulte la Guía MLMD para obtener más detalles.