
ML Metadata (MLMD) est une bibliothèque permettant d'enregistrer et de récupérer des métadonnées associées aux flux de travail des développeurs ML et des data scientists. MLMD fait partie intégrante de TensorFlow Extended (TFX) , mais est conçu pour pouvoir être utilisé indépendamment.
Chaque exécution d'un pipeline ML de production génère des métadonnées contenant des informations sur les différents composants du pipeline, leurs exécutions (par exemple, les exécutions de formation) et les artefacts résultants (par exemple, les modèles entraînés). En cas de comportement inattendu du pipeline ou d'erreurs, ces métadonnées peuvent être exploitées pour analyser la lignée des composants du pipeline et les problèmes de débogage. Considérez ces métadonnées comme l'équivalent de la connexion dans le développement de logiciels.
MLMD vous aide à comprendre et à analyser toutes les parties interconnectées de votre pipeline ML au lieu de les analyser de manière isolée et peut vous aider à répondre à des questions sur votre pipeline ML telles que :
- Sur quel ensemble de données le modèle s'est-il entraîné ?
- Quels ont été les hyperparamètres utilisés pour entraîner le modèle ?
- Quelle exécution de pipeline a créé le modèle ?
- Quelle formation a conduit à ce modèle ?
- Quelle version de TensorFlow a créé ce modèle ?
- Quand le modèle défaillant a-t-il été mis en avant ?
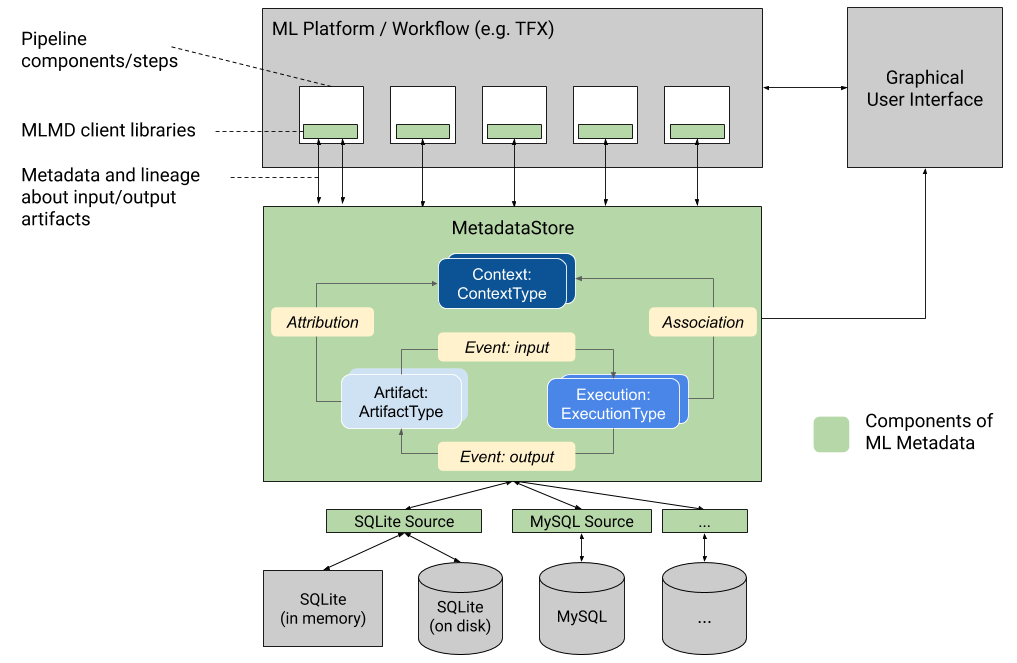
Magasin de métadonnées
MLMD enregistre les types de métadonnées suivants dans une base de données appelée Metadata Store .
- Métadonnées sur les artefacts générés via les composants/étapes de vos pipelines ML
- Métadonnées sur les exécutions de ces composants/étapes
- Métadonnées sur les pipelines et informations de lignage associées
Le magasin de métadonnées fournit des API pour enregistrer et récupérer des métadonnées vers et depuis le backend de stockage. Le backend de stockage est enfichable et peut être étendu. MLMD fournit des implémentations de référence pour SQLite (qui prend en charge la mémoire et le disque) et MySQL prêtes à l'emploi.
Ce graphique présente une présentation générale des différents composants qui font partie de MLMD.
Backends de stockage de métadonnées et configuration de la connexion au magasin
L'objet MetadataStore reçoit une configuration de connexion qui correspond au backend de stockage utilisé.
- Fake Database fournit une base de données en mémoire (utilisant SQLite) pour une expérimentation rapide et des exécutions locales. La base de données est supprimée lorsque l'objet du magasin est détruit.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite lit et écrit des fichiers à partir du disque.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL se connecte à un serveur MySQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
De même, lors de l'utilisation d'une instance MySQL avec Google CloudSQL ( quickstart , connect-overview ), on peut également utiliser l'option SSL, le cas échéant.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL se connecte à un serveur PostgreSQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
De même, lors de l'utilisation d'une instance PostgreSQL avec Google CloudSQL ( quickstart , connect-overview ), on peut également utiliser l'option SSL, le cas échéant.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
Modèle de données
Le magasin de métadonnées utilise le modèle de données suivant pour enregistrer et récupérer les métadonnées du backend de stockage.
-
ArtifactTypedécrit le type d'un artefact et ses propriétés stockées dans le magasin de métadonnées. Vous pouvez enregistrer ces types à la volée auprès du magasin de métadonnées sous forme de code, ou vous pouvez les charger dans le magasin à partir d'un format sérialisé. Une fois que vous avez enregistré un type, sa définition est disponible pendant toute la durée de vie du magasin. - Un
Artifactdécrit une instance spécifique d'unArtifactTypeet ses propriétés qui sont écrites dans le magasin de métadonnées. - Un
ExecutionTypedécrit un type de composant ou d'étape dans un flux de travail et ses paramètres d'exécution. - Une
Executionest un enregistrement d'une exécution de composant ou d'une étape dans un workflow ML et des paramètres d'exécution. Une exécution peut être considérée comme une instance d'unExecutionType. Les exécutions sont enregistrées lorsque vous exécutez un pipeline ou une étape ML. - Un
Eventest un enregistrement de la relation entre les artefacts et les exécutions. Lorsqu'une exécution a lieu, les événements enregistrent chaque artefact utilisé par l'exécution et chaque artefact produit. Ces enregistrements permettent le suivi de la lignée tout au long d'un flux de travail. En examinant tous les événements, MLMD sait quelles exécutions ont eu lieu et quels artefacts ont été créés en conséquence. MLMD peut ensuite revenir de n'importe quel artefact à toutes ses entrées en amont. - Un
ContextTypedécrit un type de groupe conceptuel d'artefacts et d'exécutions dans un flux de travail, ainsi que ses propriétés structurelles. Par exemple : projets, exécutions de pipelines, expériences, propriétaires, etc. - Un
Contextest une instance d'unContextType. Il capture les informations partagées au sein du groupe. Par exemple : nom du projet, identifiant de validation de la liste de modifications, annotations d'expérience, etc. Il a un nom unique défini par l'utilisateur dans sonContextType. - Une
Attributionest un enregistrement de la relation entre les artefacts et les contextes. - Une
Associationest un enregistrement de la relation entre les exécutions et les contextes.
Fonctionnalité MLMD
Le suivi des entrées et des sorties de tous les composants/étapes d'un flux de travail ML et de leur lignée permet aux plates-formes ML d'activer plusieurs fonctionnalités importantes. La liste suivante donne un aperçu non exhaustif de certains des principaux avantages.
- Répertoriez tous les artefacts d’un type spécifique. Exemple : tous les modèles qui ont été formés.
- Chargez deux artefacts du même type pour comparaison. Exemple : comparer les résultats de deux expériences.
- Afficher un DAG de toutes les exécutions associées et leurs artefacts d'entrée et de sortie d'un contexte. Exemple : visualisez le flux de travail d'une expérience pour le débogage et la découverte.
- Revenez en arrière sur tous les événements pour voir comment un artefact a été créé. Exemples : voir quelles données ont été entrées dans un modèle ; appliquer des plans de conservation des données.
- Identifiez tous les artefacts créés à l’aide d’un artefact donné. Exemples : voir tous les modèles formés à partir d'un ensemble de données spécifique ; marquer les modèles en fonction de mauvaises données.
- Déterminez si une exécution a déjà été exécutée sur les mêmes entrées. Exemple : déterminez si un composant/une étape a déjà effectué le même travail et si la sortie précédente peut simplement être réutilisée.
- Enregistrez et interrogez le contexte des exécutions de flux de travail. Exemples : suivez le propriétaire et la liste de modifications utilisés pour une exécution de flux de travail ; regrouper la lignée par expériences ; gérer les artefacts par projets.
- Capacités de filtrage des nœuds déclaratifs sur les propriétés et les nœuds de voisinage à 1 saut. Exemples : recherchez des artefacts d'un type et dans un contexte de pipeline ; renvoyer des artefacts typés où la valeur d'une propriété donnée se situe dans une plage ; retrouver les exécutions précédentes dans un contexte avec les mêmes entrées.
Consultez le didacticiel MLMD pour obtenir un exemple qui vous montre comment utiliser l'API MLMD et le magasin de métadonnées pour récupérer des informations de lignage.
Intégrez les métadonnées ML dans vos flux de travail ML
Si vous êtes un développeur de plateforme souhaitant intégrer MLMD dans votre système, utilisez l'exemple de flux de travail ci-dessous pour utiliser les API MLMD de bas niveau afin de suivre l'exécution d'une tâche de formation. Vous pouvez également utiliser des API Python de niveau supérieur dans des environnements de bloc-notes pour enregistrer les métadonnées des expériences.
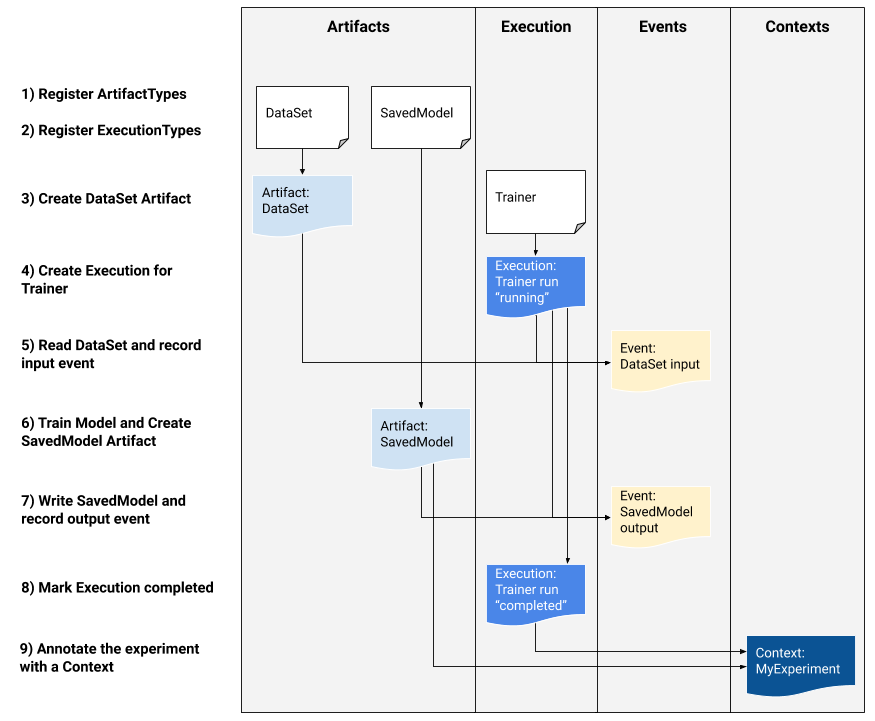
1) Enregistrez les types d'artefacts
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) Enregistrez les types d'exécution pour toutes les étapes du flux de travail ML
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) Créer un artefact de DataSet ArtifactType
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) Créer une exécution de l'exécution du formateur
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) Définir l'événement d'entrée et lire les données
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) Déclarez l'artefact de sortie
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) Enregistrez l'événement de sortie
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) Marquer l'exécution comme terminée
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) Regrouper les artefacts et les exécutions dans un contexte en utilisant des artefacts d'attributions et d'assertions
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
Utiliser MLMD avec un serveur gRPC distant
Vous pouvez utiliser MLMD avec des serveurs gRPC distants comme indiqué ci-dessous :
- Démarrer un serveur
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
Par défaut, le serveur utilise une fausse base de données en mémoire par requête et ne conserve pas les métadonnées entre les appels. Il peut également être configuré avec un MLMD MetadataStoreServerConfig pour utiliser des fichiers SQLite ou des instances MySQL. La configuration peut être stockée dans un fichier texte protobuf et transmise au binaire avec --metadata_store_server_config_file=path_to_the_config_file .
Un exemple de fichier MetadataStoreServerConfig au format texte protobuf :
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- Créez le stub client et utilisez-le en Python
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- Utiliser MLMD avec les appels RPC
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
Ressources
La bibliothèque MLMD dispose d'une API de haut niveau que vous pouvez facilement utiliser avec vos pipelines ML. Consultez la documentation de l'API MLMD pour plus de détails.
Consultez Filtrage des nœuds déclaratifs MLMD pour savoir comment utiliser les capacités de filtrage des nœuds déclaratifs MLMD sur les propriétés et les nœuds de voisinage à 1 saut.
Consultez également le didacticiel MLMD pour savoir comment utiliser MLMD pour tracer le lignage des composants de votre pipeline.
MLMD fournit des utilitaires pour gérer les migrations de schémas et de données entre les versions. Consultez le guide MLMD pour plus de détails.