
การแนะนำ
TFX เป็นแพลตฟอร์มแมชชีนเลิร์นนิง (ML) ระดับการผลิตจริงของ Google ซึ่งอิงจาก TensorFlow โดยจัดเตรียมเฟรมเวิร์กการกำหนดค่าและไลบรารีที่ใช้ร่วมกันเพื่อรวมส่วนประกอบทั่วไปที่จำเป็นในการกำหนด เปิดใช้งาน และติดตามระบบแมชชีนเลิร์นนิงของคุณ
ทีเอฟเอ็กซ์ 1.0
เรามีความยินดีที่จะประกาศความพร้อมของ TFX 1.0.0 นี่เป็นการเปิดตัว TFX หลังเบต้าครั้งแรก ซึ่งมี API และอาร์ติแฟกต์สาธารณะที่เสถียร คุณสามารถมั่นใจได้ว่าท่อส่ง TFX ในอนาคตของคุณจะยังคงทำงานต่อไปหลังจากการอัปเกรดภายในขอบเขตความเข้ากันได้ที่กำหนดไว้ใน RFC นี้
การติดตั้ง

![]()
pip install tfx
แพ็คเกจกลางคืน
TFX ยังโฮสต์แพ็คเกจรายคืนที่ https://pypi-nightly.tensorflow.org บน Google Cloud หากต้องการติดตั้งแพ็คเกจกลางคืนล่าสุด โปรดใช้คำสั่งต่อไปนี้:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
สิ่งนี้จะติดตั้งแพ็คเกจกลางคืนสำหรับการขึ้นต่อกันที่สำคัญของ TFX เช่น TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD)
เกี่ยวกับ TFEX
TFX เป็นแพลตฟอร์มสำหรับการสร้างและจัดการเวิร์กโฟลว์ ML ในสภาพแวดล้อมการใช้งานจริง TFX มีดังต่อไปนี้:
ชุดเครื่องมือสำหรับสร้างไปป์ไลน์ ML ไปป์ไลน์ TFX ช่วยให้คุณจัดการเวิร์กโฟลว์ ML บนหลายแพลตฟอร์ม เช่น Apache Airflow, Apache Beam และ Kubeflow Pipelines
ชุดส่วนประกอบมาตรฐานที่คุณสามารถใช้เป็นส่วนหนึ่งของไปป์ไลน์หรือเป็นส่วนหนึ่งของสคริปต์การฝึก ML ของคุณได้ ส่วนประกอบมาตรฐาน TFX มอบฟังก์ชันการทำงานที่ได้รับการพิสูจน์แล้วเพื่อช่วยให้คุณเริ่มต้นสร้างกระบวนการ ML ได้อย่างง่ายดาย
ไลบรารีที่ให้ฟังก์ชันการทำงานพื้นฐานสำหรับส่วนประกอบมาตรฐานหลายๆ รายการ คุณสามารถใช้ไลบรารี TFX เพื่อเพิ่มฟังก์ชันนี้ให้กับส่วนประกอบที่คุณกำหนดเอง หรือใช้แยกกัน
TFX เป็นชุดเครื่องมือแมชชีนเลิร์นนิงในระดับที่ใช้งานจริงของ Google ซึ่งอิงจาก TensorFlow โดยจัดเตรียมเฟรมเวิร์กการกำหนดค่าและไลบรารีที่ใช้ร่วมกันเพื่อรวมส่วนประกอบทั่วไปที่จำเป็นในการกำหนด เปิดใช้งาน และติดตามระบบแมชชีนเลิร์นนิงของคุณ
ส่วนประกอบมาตรฐาน TFX
ไปป์ไลน์ TFX คือลำดับของส่วนประกอบที่ใช้ ไปป์ไลน์ ML ซึ่งได้รับการออกแบบมาโดยเฉพาะสำหรับงานแมชชีนเลิร์นนิงที่ปรับขนาดได้และมีประสิทธิภาพสูง ซึ่งรวมถึงการสร้างแบบจำลอง การฝึกอบรม การให้บริการการอนุมาน และการจัดการการปรับใช้กับเป้าหมายออนไลน์ อุปกรณ์เคลื่อนที่แบบเนทีฟ และ JavaScript
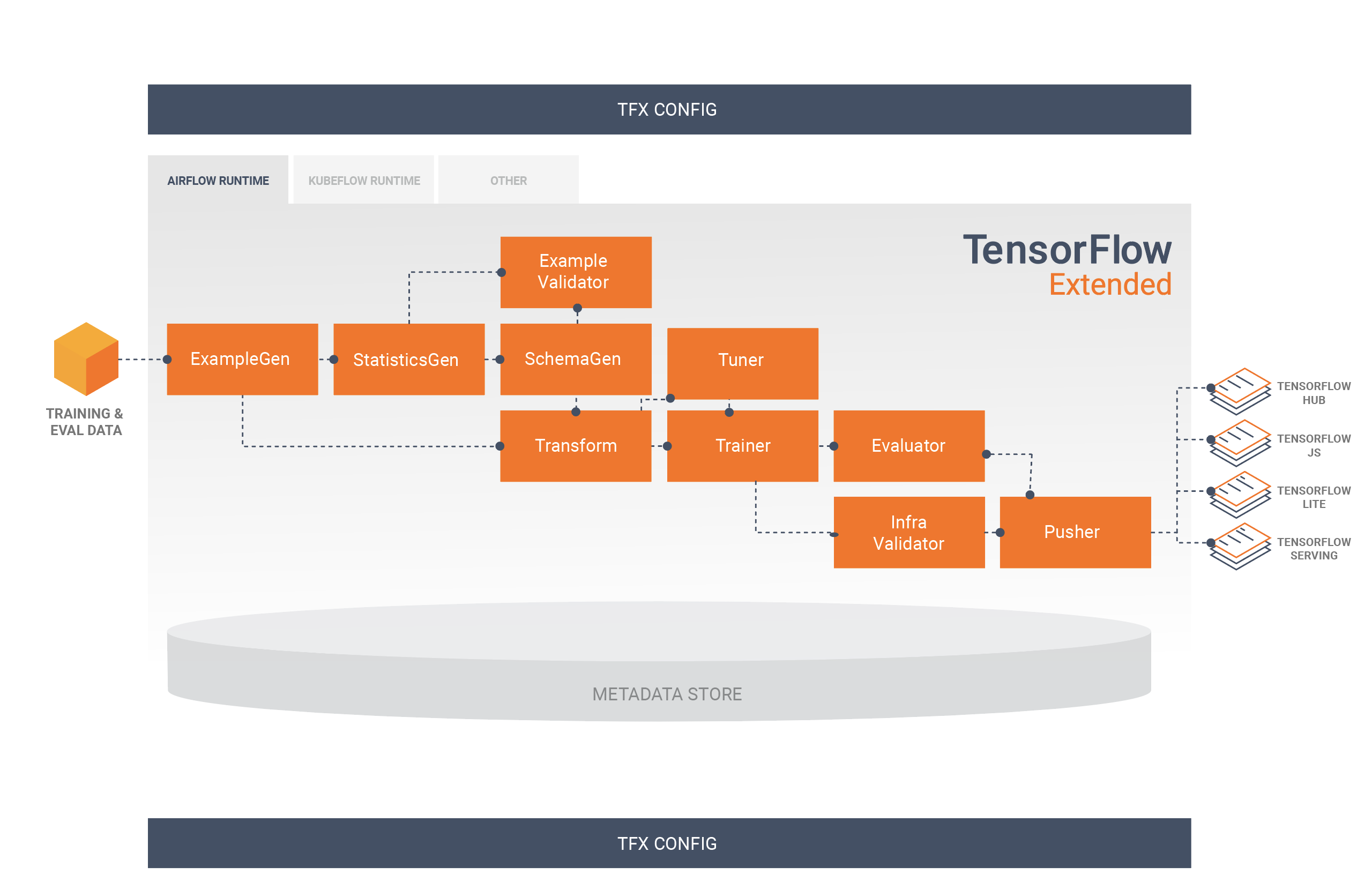
โดยทั่วไปไปป์ไลน์ TFX จะมีส่วนประกอบต่อไปนี้:
ExampleGen เป็นองค์ประกอบอินพุตเริ่มต้นของไปป์ไลน์ที่นำเข้าและเลือกที่จะแยกชุดข้อมูลอินพุต
StatisticsGen คำนวณสถิติสำหรับชุดข้อมูล
SchemaGen ตรวจสอบสถิติและสร้างสคีมาข้อมูล
ExampleValidator ค้นหาความผิดปกติและค่าที่หายไปในชุดข้อมูล
การแปลง ดำเนินการทางวิศวกรรมคุณลักษณะบนชุดข้อมูล
เทรนเนอร์ ฝึกโมเดล
จูนเนอร์ จะปรับแต่งไฮเปอร์พารามิเตอร์ของโมเดล
ผู้ประเมิน ทำการวิเคราะห์ผลการฝึกอบรมเชิงลึก และช่วยคุณตรวจสอบแบบจำลองที่ส่งออกของคุณ เพื่อให้มั่นใจว่าโมเดลเหล่านั้น "ดีเพียงพอ" ที่จะถูกผลักดันไปสู่การใช้งานจริง
InfraValidator จะตรวจสอบว่าโมเดลนั้นให้บริการได้จริงจากโครงสร้างพื้นฐาน และป้องกันไม่ให้มีการพุชโมเดลที่ไม่ดี
Pusher ปรับใช้โมเดลบนโครงสร้างพื้นฐานที่ให้บริการ
BulkInferrer ดำเนินการประมวลผลเป็นชุดในโมเดลที่มีการร้องขอการอนุมานที่ไม่มีป้ายกำกับ
แผนภาพนี้แสดงการไหลของข้อมูลระหว่างส่วนประกอบเหล่านี้:
ห้องสมุด TFX
TFX มีทั้งไลบรารีและส่วนประกอบไปป์ไลน์ แผนภาพนี้แสดงความสัมพันธ์ระหว่างไลบรารี TFX และส่วนประกอบไปป์ไลน์:
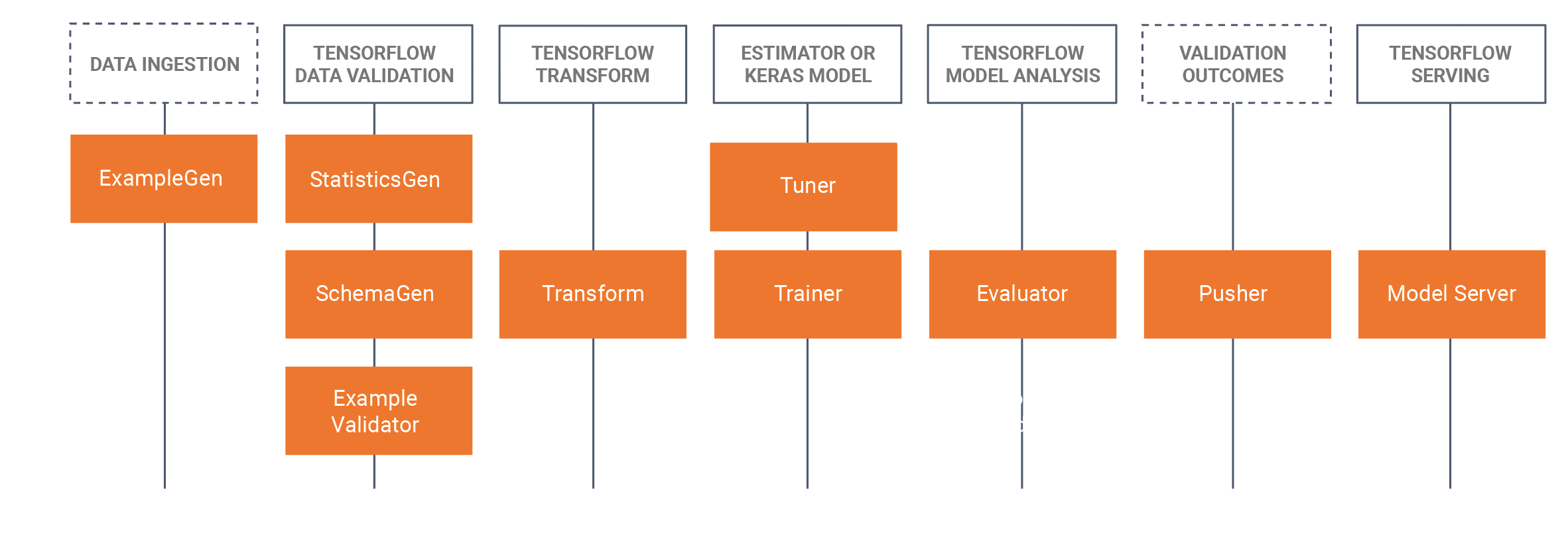
TFX มีแพ็คเกจ Python หลายแพ็คเกจที่เป็นไลบรารีที่ใช้ในการสร้างส่วนประกอบไปป์ไลน์ คุณจะใช้ไลบรารีเหล่านี้เพื่อสร้างส่วนประกอบของไปป์ไลน์ของคุณ เพื่อให้โค้ดของคุณสามารถมุ่งเน้นไปที่ลักษณะเฉพาะของไปป์ไลน์ของคุณ
ไลบรารี TFX ประกอบด้วย:
TensorFlow Data Validation (TFDV) เป็นไลบรารีสำหรับการวิเคราะห์และตรวจสอบความถูกต้องของข้อมูลแมชชีนเลิร์นนิง ได้รับการออกแบบมาให้สามารถปรับขนาดได้สูงและทำงานได้ดีกับ TensorFlow และ TFX TFDV รวมถึง:
- การคำนวณสถิติสรุปของข้อมูลการฝึกอบรมและการทดสอบที่ปรับขนาดได้
- การบูรณาการกับโปรแกรมดูเพื่อการกระจายข้อมูลและสถิติ รวมถึงการเปรียบเทียบคู่ชุดข้อมูล (Facets) แบบเหลี่ยมเพชรพลอย
- การสร้างสคีมาข้อมูลอัตโนมัติเพื่ออธิบายความคาดหวังเกี่ยวกับข้อมูล เช่น ค่า ช่วง และคำศัพท์ที่ต้องการ
- โปรแกรมดูสคีมาเพื่อช่วยคุณตรวจสอบสคีมา
- การตรวจจับความผิดปกติเพื่อระบุความผิดปกติ เช่น คุณสมบัติที่ขาดหายไป ค่าที่อยู่นอกขอบเขต หรือประเภทคุณสมบัติที่ไม่ถูกต้อง เป็นต้น
- โปรแกรมดูความผิดปกติเพื่อให้คุณสามารถดูว่าฟีเจอร์ใดมีความผิดปกติและเรียนรู้เพิ่มเติมเพื่อแก้ไขให้ถูกต้อง
TensorFlow Transform (TFT) เป็นไลบรารีสำหรับการประมวลผลข้อมูลล่วงหน้าด้วย TensorFlow TensorFlow Transform มีประโยชน์สำหรับข้อมูลที่ต้องใช้ฟูลพาส เช่น:
- ทำให้ค่าอินพุตเป็นมาตรฐานด้วยค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐาน
- แปลงสตริงให้เป็นจำนวนเต็มโดยการสร้างคำศัพท์บนค่าอินพุตทั้งหมด
- แปลงจำนวนทศนิยมเป็นจำนวนเต็มโดยกำหนดให้กับที่เก็บข้อมูลตามการกระจายข้อมูลที่สังเกตได้
TensorFlow ใช้สำหรับโมเดลการฝึกด้วย TFX นำเข้าข้อมูลการฝึกอบรมและโค้ดการสร้างแบบจำลอง และสร้างผลลัพธ์ SavedModel นอกจากนี้ยังผสานรวมไปป์ไลน์วิศวกรรมฟีเจอร์ที่สร้างขึ้นโดย TensorFlow Transform สำหรับการประมวลผลข้อมูลอินพุตล่วงหน้า
KerasTuner ใช้สำหรับปรับแต่งไฮเปอร์พารามิเตอร์สำหรับโมเดล
TensorFlow Model Analysis (TFMA) เป็นไลบรารีสำหรับประเมินโมเดล TensorFlow โดยใช้ร่วมกับ TensorFlow เพื่อสร้าง EvalSavedModel ซึ่งกลายเป็นพื้นฐานสำหรับการวิเคราะห์ ช่วยให้ผู้ใช้สามารถประเมินแบบจำลองของตนกับข้อมูลจำนวนมากในลักษณะแบบกระจาย โดยใช้หน่วยเมตริกเดียวกันที่กำหนดไว้ในโปรแกรมฝึกสอน หน่วยวัดเหล่านี้สามารถคำนวณบนส่วนข้อมูลต่างๆ และแสดงเป็นภาพในสมุดบันทึก Jupyter
ข้อมูลเมตาของ TensorFlow (TFMD) ให้การนำเสนอมาตรฐานสำหรับข้อมูลเมตาที่มีประโยชน์เมื่อฝึกโมเดลการเรียนรู้ของเครื่องด้วย TensorFlow ข้อมูลเมตาอาจสร้างขึ้นด้วยมือหรือโดยอัตโนมัติในระหว่างการวิเคราะห์ข้อมูลอินพุต และอาจใช้สำหรับการตรวจสอบความถูกต้องของข้อมูล การสำรวจ และการแปลงข้อมูล รูปแบบการทำให้เป็นอนุกรมของข้อมูลเมตาประกอบด้วย:
- สคีมาที่อธิบายข้อมูลแบบตาราง (เช่น tf.Examples)
- การรวบรวมสถิติสรุปของชุดข้อมูลดังกล่าว
ML Metadata (MLMD) คือไลบรารีสำหรับบันทึกและดึงข้อมูลเมตาที่เกี่ยวข้องกับเวิร์กโฟลว์นักพัฒนา ML และนักวิทยาศาสตร์ข้อมูล ส่วนใหญ่แล้วข้อมูลเมตาจะใช้การแสดง TFMD MLMD จัดการความคงอยู่โดยใช้ SQL-Lite , MySQL และที่เก็บข้อมูลอื่นที่คล้ายคลึงกัน
เทคโนโลยีที่รองรับ
ที่จำเป็น
- Apache Beam เป็นโมเดลโอเพ่นซอร์สแบบครบวงจรสำหรับกำหนดไปป์ไลน์การประมวลผลข้อมูลแบบขนานทั้งแบบแบตช์และสตรีมมิง TFX ใช้ Apache Beam เพื่อใช้ไปป์ไลน์ข้อมูลแบบขนาน จากนั้นไปป์ไลน์จะถูกดำเนินการโดยแบ็คเอนด์การประมวลผลแบบกระจายที่รองรับของ Beam ซึ่งรวมถึง Apache Flink, Apache Spark, Google Cloud Dataflow และอื่นๆ
ไม่จำเป็น
ผู้ควบคุมระบบ เช่น Apache Airflow และ Kubeflow ช่วยให้การกำหนดค่า ดำเนินการ ตรวจสอบ และบำรุงรักษาไปป์ไลน์ ML ง่ายขึ้น
Apache Airflow เป็นแพลตฟอร์มสำหรับเขียน กำหนดเวลา และตรวจสอบเวิร์กโฟลว์โดยทางโปรแกรม TFX ใช้ Airflow เพื่อสร้างเวิร์กโฟลว์เป็นกราฟอะไซคลิกโดยตรง (DAG) ของงาน ตัวกำหนดเวลา Airflow ดำเนินงานกับอาร์เรย์ของผู้ปฏิบัติงานในขณะที่ติดตามการขึ้นต่อกันที่ระบุ ยูทิลิตี้บรรทัดคำสั่งที่หลากหลายทำให้การผ่าตัดที่ซับซ้อนบน DAG เป็นเรื่องง่าย อินเทอร์เฟซผู้ใช้ที่หลากหลายทำให้ง่ายต่อการเห็นภาพไปป์ไลน์ที่ใช้งานจริง ติดตามความคืบหน้า และแก้ไขปัญหาเมื่อจำเป็น เมื่อเวิร์กโฟลว์ถูกกำหนดให้เป็นโค้ด เวิร์กโฟลว์เหล่านั้นจะบำรุงรักษาได้ กำหนดเวอร์ชันได้ ทดสอบได้ และทำงานร่วมกันได้มากขึ้น
Kubeflow ทุ่มเทเพื่อทำให้เวิร์กโฟลว์แมชชีนเลิร์นนิง (ML) ใช้งานบน Kubernetes ได้ง่าย พกพาสะดวก และปรับขนาดได้ เป้าหมายของ Kubeflow ไม่ใช่การสร้างบริการอื่นๆ ขึ้นใหม่ แต่เป็นการนำเสนอวิธีที่ตรงไปตรงมาในการปรับใช้ระบบโอเพ่นซอร์สที่ดีที่สุดสำหรับ ML ไปยังโครงสร้างพื้นฐานที่หลากหลาย Kubeflow Pipelines ช่วยให้สามารถจัดองค์ประกอบและดำเนินการเวิร์กโฟลว์ที่ทำซ้ำได้บน Kubeflow ซึ่งผสานรวมกับการทดลองและประสบการณ์บนโน้ตบุ๊ก บริการ Kubeflow Pipelines บน Kubernetes ประกอบด้วยที่เก็บข้อมูลเมตาที่โฮสต์ กลไกการจัดการตามคอนเทนเนอร์ เซิร์ฟเวอร์โน้ตบุ๊ก และ UI เพื่อช่วยให้ผู้ใช้พัฒนา เรียกใช้ และจัดการไปป์ไลน์ ML ที่ซับซ้อนในวงกว้าง Kubeflow Pipelines SDK ช่วยให้สามารถสร้างและแบ่งปันส่วนประกอบและองค์ประกอบของไปป์ไลน์โดยทางโปรแกรม
การพกพาและการทำงานร่วมกัน
TFX ได้รับการออกแบบมาให้พกพาได้กับสภาพแวดล้อมและเฟรมเวิร์กการประสานที่หลากหลาย รวมถึง Apache Airflow , Apache Beam และ Kubeflow นอกจากนี้ยังสามารถพกพาไปยังแพลตฟอร์มการประมวลผลต่างๆ รวมถึงในองค์กรและแพลตฟอร์มคลาวด์ เช่น แพลตฟอร์ม Google Cloud (GCP) โดยเฉพาะอย่างยิ่ง TFX ทำงานร่วมกับบริการ GCP ที่จัดการโดยเซิร์ฟเวอร์ เช่น Cloud AI Platform for Training and Prediction และ Cloud Dataflow สำหรับการประมวลผลข้อมูลแบบกระจายสำหรับแง่มุมอื่นๆ หลายประการของวงจรการใช้งาน ML
โมเดลกับโมเดลที่บันทึกไว้
แบบอย่าง
แบบจำลองคือผลลัพธ์ของกระบวนการฝึกอบรม เป็นบันทึกต่อเนื่องของตุ้มน้ำหนักที่ได้รับการเรียนรู้ในระหว่างกระบวนการฝึกอบรม น้ำหนักเหล่านี้สามารถใช้เพื่อคำนวณการทำนายสำหรับตัวอย่างอินพุตใหม่ได้ในภายหลัง สำหรับ TFX และ TensorFlow 'โมเดล' หมายถึงจุดตรวจสอบที่มีน้ำหนักที่เรียนรู้จนถึงจุดนั้น
โปรดทราบว่า 'โมเดล' อาจหมายถึงคำจำกัดความของกราฟการคำนวณ TensorFlow (เช่น ไฟล์ Python) ที่แสดงวิธีคำนวณการทำนาย ประสาทสัมผัสทั้งสองอาจใช้สลับกันได้ขึ้นอยู่กับบริบท
โมเดลที่บันทึกไว้
- SavedModel คืออะไร : การทำให้เป็นอนุกรมที่เป็นสากล เป็นกลางทางภาษา สุญญากาศ และสามารถกู้คืนได้ของโมเดล TensorFlow
- เหตุใดจึงสำคัญ : ช่วยให้ระบบระดับสูงสามารถสร้าง แปลง และใช้โมเดล TensorFlow โดยใช้นามธรรมเดียว
SavedModel คือรูปแบบการทำให้เป็นอนุกรมที่แนะนำสำหรับการให้บริการโมเดล TensorFlow ในการใช้งานจริง หรือการส่งออกโมเดลที่ผ่านการฝึกอบรมสำหรับแอปพลิเคชันมือถือหรือ JavaScript แบบเนทีฟ ตัวอย่างเช่น หากต้องการเปลี่ยนโมเดลให้เป็นบริการ REST สำหรับการคาดการณ์ คุณสามารถทำให้โมเดลเป็นอนุกรมเป็น SavedModel และให้บริการโดยใช้ TensorFlow Serving ดู การให้บริการโมเดล TensorFlow สำหรับข้อมูลเพิ่มเติม
สคีมา
ส่วนประกอบ TFX บางอย่างใช้คำอธิบายข้อมูลอินพุตของคุณที่เรียกว่า สคีมา สคีมาเป็นตัวอย่างของ schema.proto สคีมาเป็น บัฟเฟอร์โปรโตคอล ประเภทหนึ่ง หรือที่เรียกกันทั่วไปว่า "โปรโตบัฟ" สคีมาสามารถระบุประเภทข้อมูลสำหรับค่าคุณลักษณะ ไม่ว่าคุณลักษณะจะต้องมีอยู่ในตัวอย่างทั้งหมด ช่วงค่าที่อนุญาต และคุณสมบัติอื่นๆ หรือไม่ ข้อดีอย่างหนึ่งของการใช้ TensorFlow Data Validation (TFDV) ก็คือ การสร้างสคีมาโดยอัตโนมัติโดยการอนุมานประเภท หมวดหมู่ และช่วงจากข้อมูลการฝึก
นี่เป็นข้อความที่ตัดตอนมาจาก schema protobuf:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
ส่วนประกอบต่อไปนี้ใช้สคีมา:
- การตรวจสอบข้อมูล TensorFlow
- การแปลงเทนเซอร์โฟลว์
ในไปป์ไลน์ TFX ทั่วไป TensorFlow Data Validation จะสร้างสคีมาซึ่งคอมโพเนนต์อื่นๆ จะใช้
การพัฒนาด้วย TFX
TFX มอบแพลตฟอร์มที่ทรงพลังสำหรับทุกขั้นตอนของโปรเจ็กต์แมชชีนเลิร์นนิง ตั้งแต่การวิจัย การทดลอง และการพัฒนาบนเครื่องในพื้นที่ของคุณ ไปจนถึงการปรับใช้งาน เพื่อหลีกเลี่ยงการเกิดโค้ดที่ซ้ำซ้อนและกำจัดโอกาสที่จะเกิด การฝึกฝน/การให้บริการที่บิดเบือน ขอแนะนำอย่างยิ่งให้ใช้ไปป์ไลน์ TFX ของคุณสำหรับทั้งการฝึกโมเดลและการปรับใช้โมเดลที่ได้รับการฝึก และใช้ส่วนประกอบ Transform ซึ่งใช้ประโยชน์จากไลบรารี TensorFlow Transform สำหรับทั้งการฝึกและการอนุมาน การทำเช่นนี้ คุณจะใช้โค้ดการประมวลผลล่วงหน้าและการวิเคราะห์เดียวกันอย่างสม่ำเสมอ และหลีกเลี่ยงความแตกต่างระหว่างข้อมูลที่ใช้สำหรับการฝึกและข้อมูลที่ป้อนให้กับโมเดลที่ได้รับการฝึกในการผลิต รวมถึงการได้รับประโยชน์จากการเขียนโค้ดนั้นเพียงครั้งเดียว
การสำรวจข้อมูล การแสดงภาพ และการทำความสะอาด
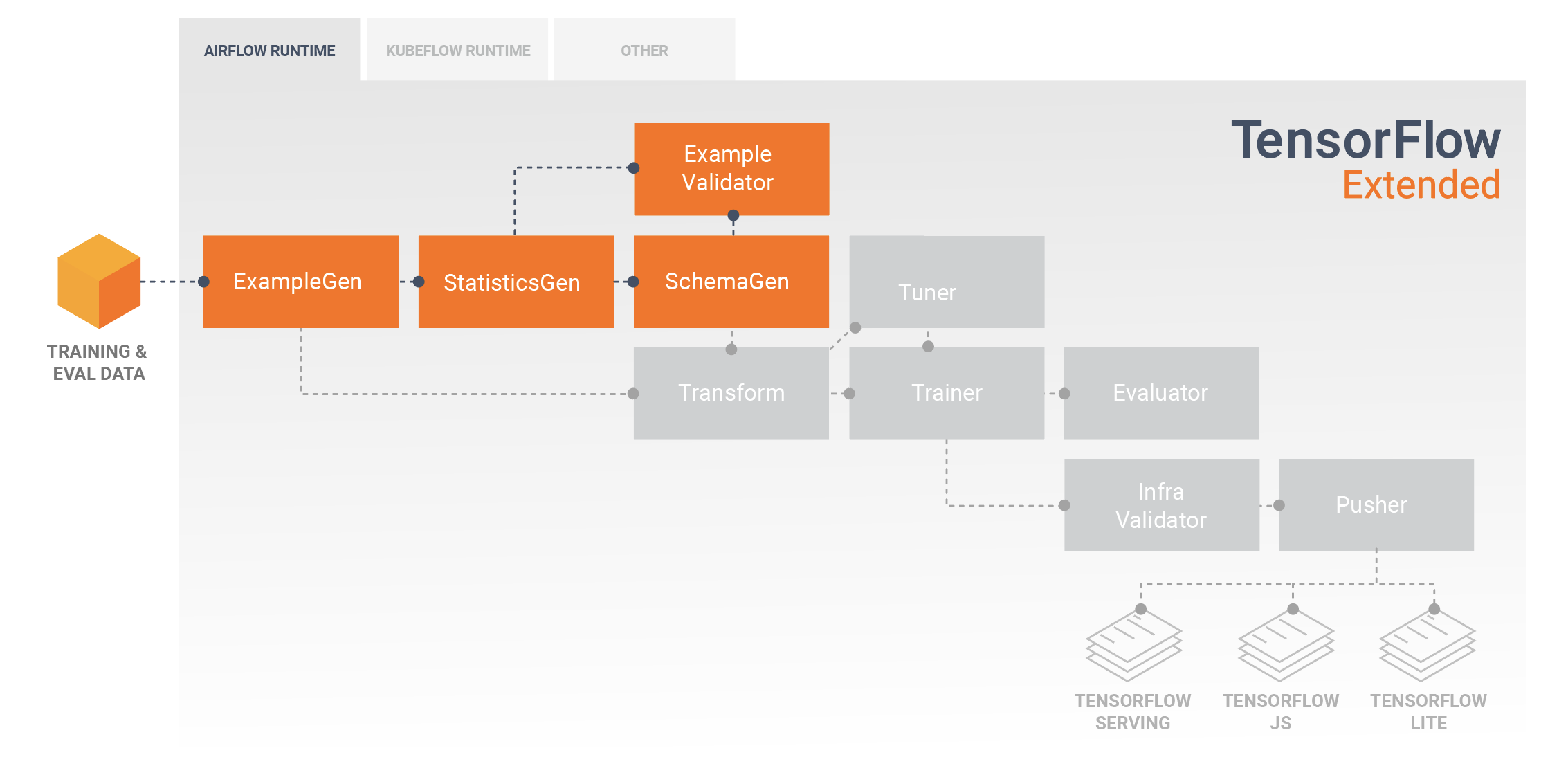
โดยทั่วไปไปป์ไลน์ TFX จะเริ่มต้นด้วยส่วนประกอบ ExampleGen ซึ่งยอมรับข้อมูลอินพุตและจัดรูปแบบเป็น tf.Examples บ่อยครั้งจะทำสิ่งนี้หลังจากแยกข้อมูลออกเป็นชุดข้อมูลการฝึกอบรมและการประเมินผล เพื่อให้มีส่วนประกอบของ ExampleGen สองชุด โดยแต่ละชุดสำหรับการฝึกอบรมและการประเมินผล โดยทั่วไปจะตามด้วยองค์ประกอบ StatisticsGen และส่วนประกอบ SchemaGen ซึ่งจะตรวจสอบข้อมูลของคุณและอนุมานสคีมาข้อมูลและสถิติ สคีมาและสถิติจะถูกใช้โดยคอมโพเนนต์ ExampleValidator ซึ่งจะค้นหาความผิดปกติ ค่าที่หายไป และประเภทข้อมูลที่ไม่ถูกต้องในข้อมูลของคุณ ส่วนประกอบทั้งหมดเหล่านี้ใช้ประโยชน์จากความสามารถของไลบรารี การตรวจสอบความถูกต้องของข้อมูล TensorFlow
TensorFlow Data Validation (TFDV) เป็นเครื่องมืออันทรงคุณค่าเมื่อทำการสำรวจ การแสดงภาพ และการทำความสะอาดชุดข้อมูลเบื้องต้น TFDV ตรวจสอบข้อมูลของคุณและอนุมานประเภทข้อมูล หมวดหมู่ และช่วง จากนั้นจะช่วยระบุความผิดปกติและค่าที่หายไปโดยอัตโนมัติ นอกจากนี้ยังมีเครื่องมือการแสดงภาพที่สามารถช่วยคุณตรวจสอบและทำความเข้าใจชุดข้อมูลของคุณได้ หลังจากที่ไปป์ไลน์ของคุณเสร็จสมบูรณ์ คุณสามารถอ่านข้อมูลเมตาจาก MLMD และใช้เครื่องมือการแสดงภาพของ TFDV ในสมุดบันทึก Jupyter เพื่อวิเคราะห์ข้อมูลของคุณได้
หลังจากการฝึกอบรมและการปรับใช้โมเดลเบื้องต้นของคุณ คุณสามารถใช้ TFDV เพื่อตรวจสอบข้อมูลใหม่จากคำขออนุมานไปยังโมเดลที่ใช้งานของคุณ และค้นหาความผิดปกติและ/หรือการเบี่ยงเบน สิ่งนี้มีประโยชน์อย่างยิ่งสำหรับข้อมูลอนุกรมเวลาที่เปลี่ยนแปลงเมื่อเวลาผ่านไปอันเป็นผลมาจากแนวโน้มหรือฤดูกาล และสามารถช่วยแจ้งเมื่อเกิดปัญหาข้อมูลหรือเมื่อใดจำเป็นต้องฝึกแบบจำลองกับข้อมูลใหม่อีกครั้ง
การแสดงข้อมูล
หลังจากที่คุณเรียกใช้ข้อมูลครั้งแรกผ่านส่วนของไปป์ไลน์ที่ใช้ TFDV (โดยทั่วไปคือ StatisticsGen, SchemaGen และ ExampleValidator) เสร็จแล้ว คุณจะเห็นภาพผลลัพธ์ในสมุดบันทึกสไตล์ Jupyter ได้ สำหรับการรันเพิ่มเติม คุณสามารถเปรียบเทียบผลลัพธ์เหล่านี้ในขณะที่คุณทำการปรับเปลี่ยน จนกว่าข้อมูลของคุณจะเหมาะสมที่สุดสำหรับรุ่นและแอปพลิเคชันของคุณ
ขั้นแรกคุณจะต้องค้นหา ข้อมูลเมตาของ ML (MLMD) เพื่อค้นหาผลลัพธ์ของการดำเนินการของส่วนประกอบเหล่านี้ จากนั้นใช้ API การสนับสนุนการแสดงภาพใน TFDV เพื่อสร้างการแสดงภาพในสมุดบันทึกของคุณ ซึ่งรวมถึง tfdv.load_statistics() และ tfdv.visualize_statistics() การใช้การแสดงภาพนี้จะทำให้คุณเข้าใจคุณลักษณะของชุดข้อมูลได้ดีขึ้น และหากจำเป็น ให้แก้ไขตามความจำเป็น
การพัฒนาและการฝึกอบรมโมเดล
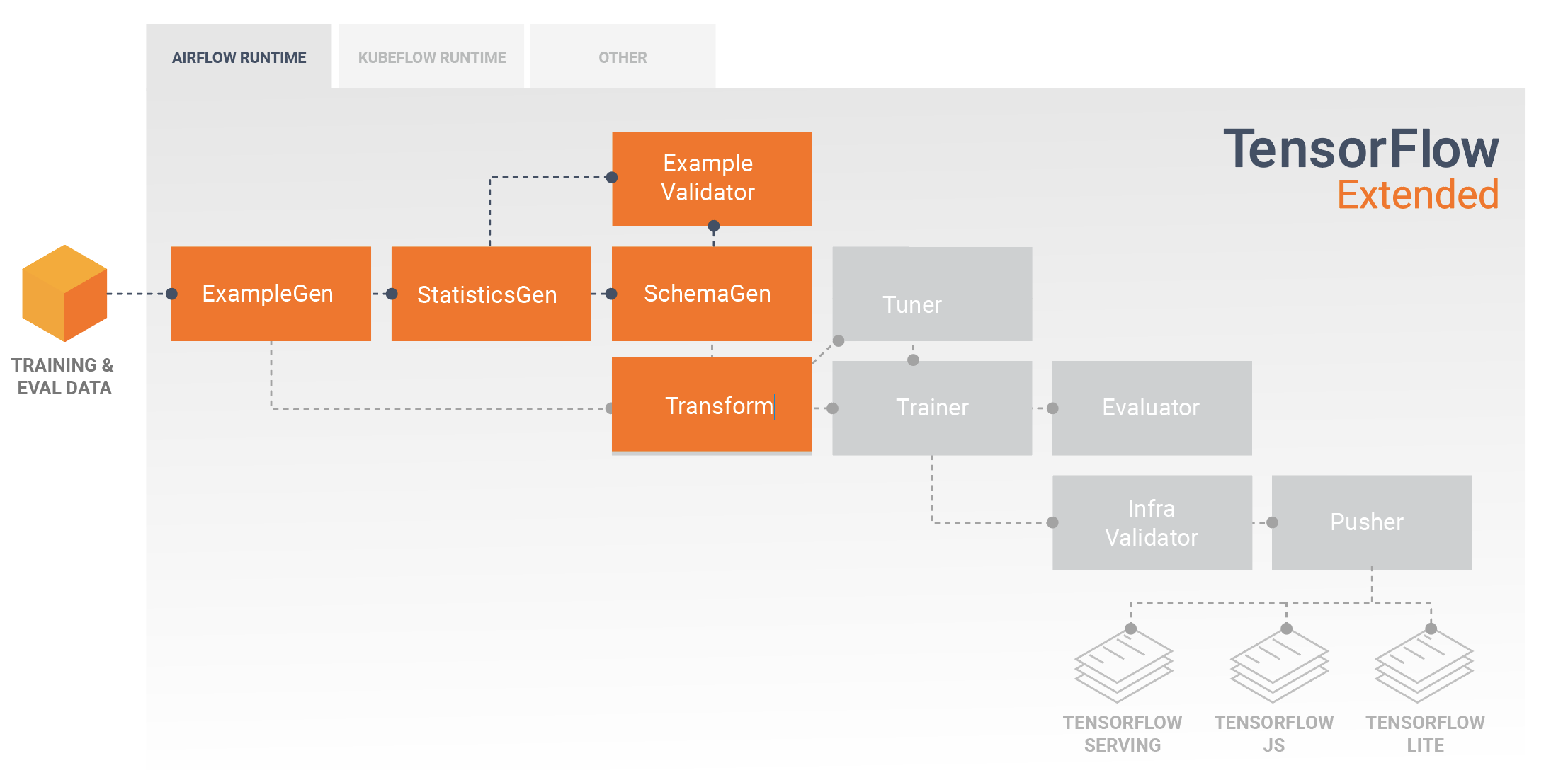
ไปป์ไลน์ TFX ทั่วไปจะรวมส่วนประกอบ Transform ซึ่งจะดำเนินการทางวิศวกรรมฟีเจอร์โดยใช้ประโยชน์จากความสามารถของไลบรารี TensorFlow Transform (TFT) ส่วนประกอบการแปลงใช้สคีมาที่สร้างโดยส่วนประกอบ SchemaGen และใช้ การแปลงข้อมูล เพื่อสร้าง รวม และแปลงคุณสมบัติที่จะใช้ในการฝึกโมเดลของคุณ การล้างค่าที่หายไปและการแปลงประเภทควรทำในคอมโพเนนต์การแปลง หากมีความเป็นไปได้ที่สิ่งเหล่านี้จะปรากฏในข้อมูลที่ส่งสำหรับการร้องขอการอนุมานด้วย มีข้อควรพิจารณาที่สำคัญบางประการ เมื่อออกแบบโค้ด TensorFlow สำหรับการฝึกใน TFX
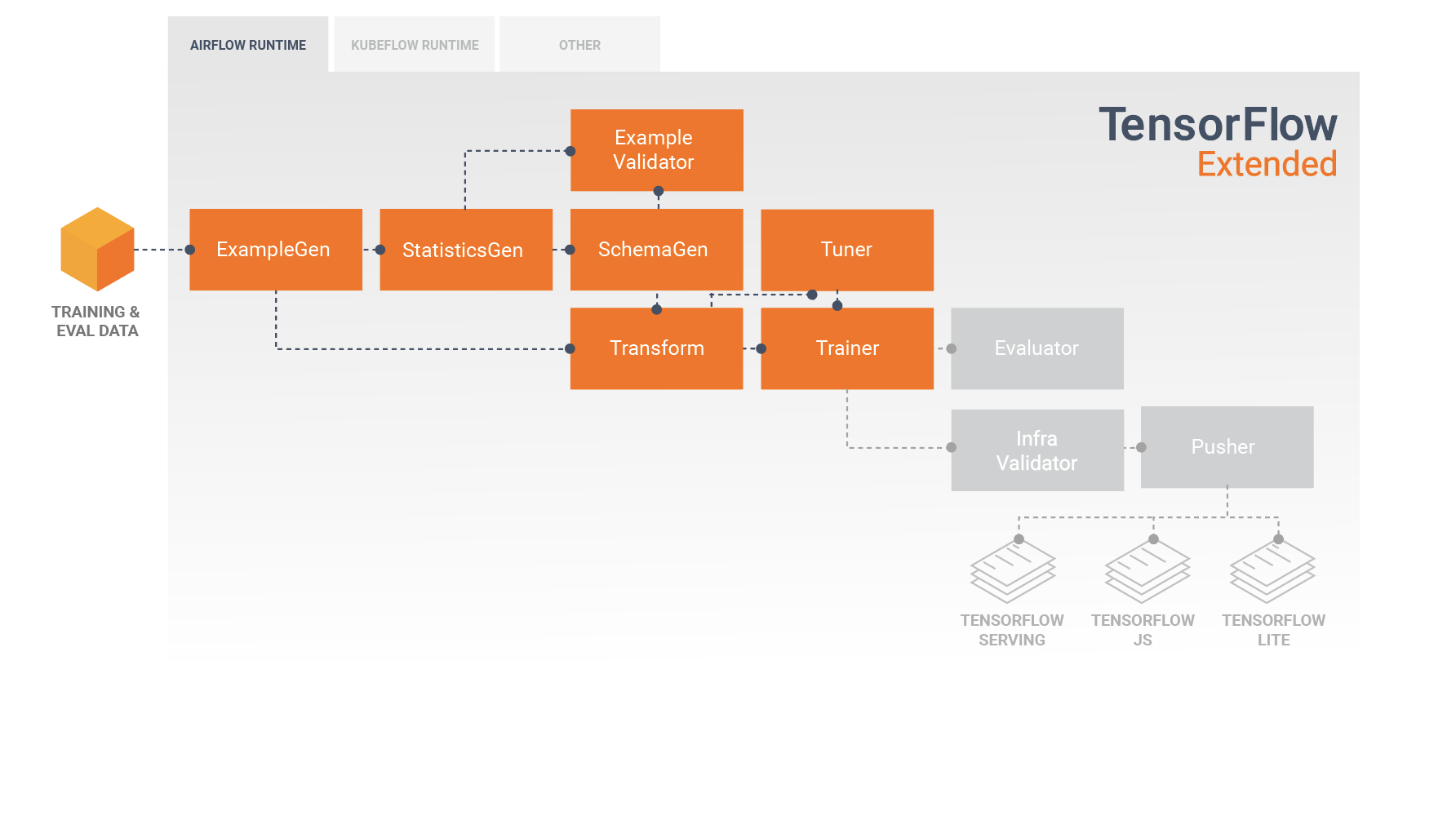
ผลลัพธ์ของส่วนประกอบ Transform คือ SavedModel ซึ่งจะถูกนำเข้าและใช้ในโค้ดการสร้างแบบจำลองของคุณใน TensorFlow ระหว่างส่วนประกอบ Trainer SavedModel นี้รวมการเปลี่ยนแปลงทางวิศวกรรมข้อมูลทั้งหมดที่สร้างขึ้นในส่วนประกอบ Transform เพื่อให้การแปลงที่เหมือนกันดำเนินการโดยใช้โค้ดเดียวกันทุกประการระหว่างการฝึกและการอนุมาน การใช้โค้ดการสร้างแบบจำลอง รวมถึง SavedModel จากส่วนประกอบ Transform ทำให้คุณสามารถใช้ข้อมูลการฝึกและการประเมินผล และฝึกโมเดลของคุณได้
เมื่อทำงานกับโมเดลที่ใช้ Estimator ส่วนสุดท้ายของโค้ดการสร้างแบบจำลองของคุณควรบันทึกโมเดลของคุณเป็นทั้ง SavedModel และ EvalSavedModel การบันทึกเป็น EvalSavedModel ช่วยให้มั่นใจได้ว่าหน่วยวัดที่ใช้ในเวลาฝึกอบรมจะพร้อมใช้งานในระหว่างการประเมินด้วย (โปรดทราบว่าไม่จำเป็นสำหรับโมเดลที่ใช้ keras) การบันทึก EvalSavedModel กำหนดให้คุณต้องนำเข้าไลบรารี TensorFlow Model Analysis (TFMA) ในส่วนประกอบ Trainer ของคุณ
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
คุณสามารถเพิ่มส่วนประกอบ จูนเนอร์ เสริมก่อน Trainer เพื่อปรับแต่งไฮเปอร์พารามิเตอร์ (เช่น จำนวนเลเยอร์) สำหรับโมเดล ด้วยโมเดลที่กำหนดและพื้นที่การค้นหาของไฮเปอร์พารามิเตอร์ อัลกอริธึมการปรับแต่งจะค้นหาไฮเปอร์พารามิเตอร์ที่ดีที่สุดตามวัตถุประสงค์
การวิเคราะห์และทำความเข้าใจประสิทธิภาพของโมเดล
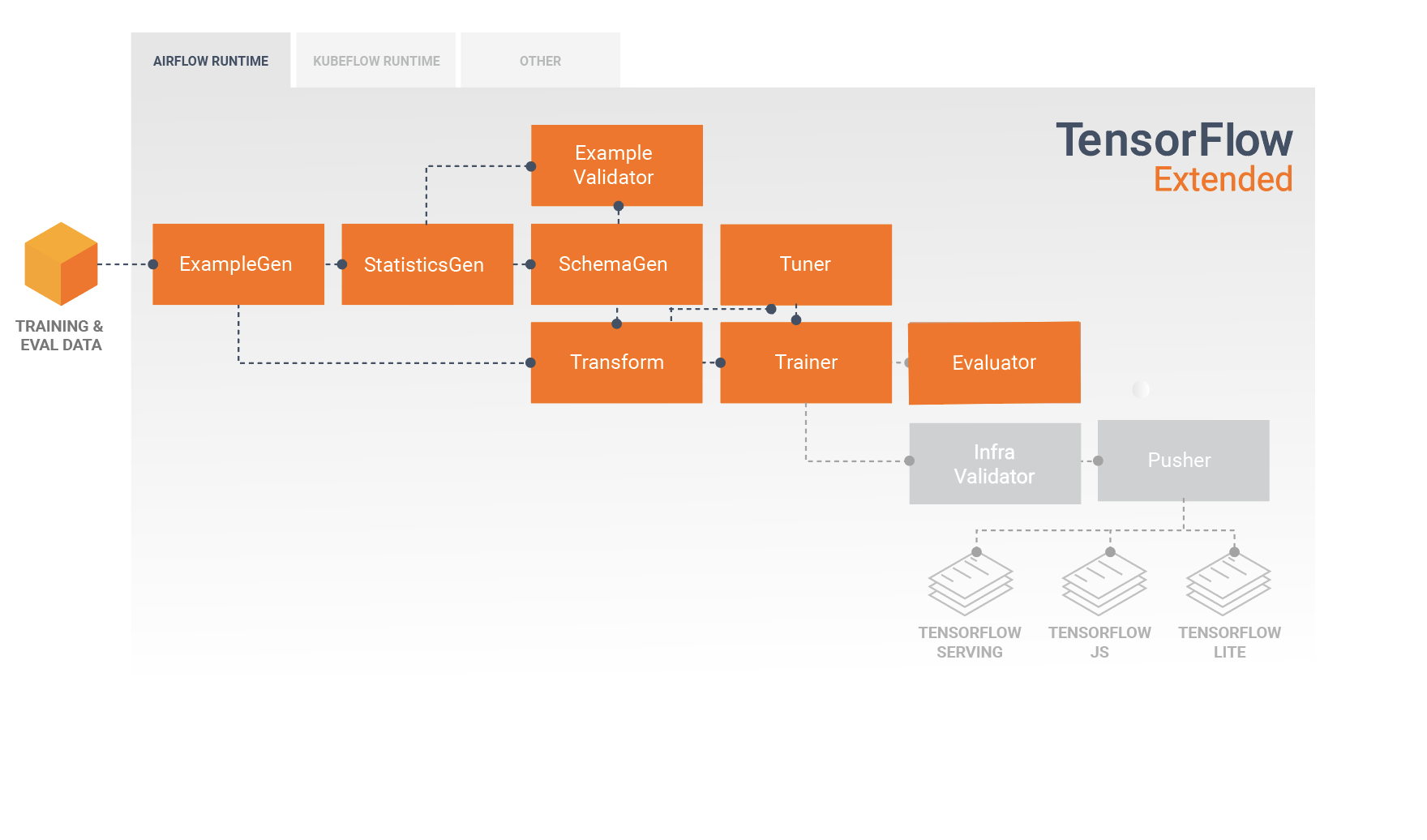
หลังจากการพัฒนาและการฝึกอบรมโมเดลเบื้องต้น สิ่งสำคัญคือต้องวิเคราะห์และทำความเข้าใจประสิทธิภาพของโมเดลของคุณอย่างแท้จริง ไปป์ไลน์ TFX ทั่วไปจะรวมส่วนประกอบ Evaluator ซึ่งใช้ประโยชน์จากความสามารถของไลบรารี TensorFlow Model Analysis (TFMA) ซึ่งจัดเตรียมชุดเครื่องมืออันทรงพลังสำหรับระยะการพัฒนานี้ ส่วนประกอบ Evaluator จะใช้โมเดลที่คุณส่งออกไปด้านบน และอนุญาตให้คุณระบุรายการ tfma.SlicingSpec ที่คุณสามารถใช้เมื่อแสดงภาพและวิเคราะห์ประสิทธิภาพของโมเดลของคุณ SlicingSpec แต่ละรายการจะกำหนดส่วนของข้อมูลการฝึกของคุณที่คุณต้องการตรวจสอบ เช่น หมวดหมู่เฉพาะสำหรับคุณสมบัติที่เป็นหมวดหมู่ หรือช่วงเฉพาะสำหรับคุณสมบัติเชิงตัวเลข
ตัวอย่างเช่น นี่อาจเป็นสิ่งสำคัญสำหรับการพยายามทำความเข้าใจประสิทธิภาพของแบบจำลองของคุณสำหรับลูกค้ากลุ่มต่างๆ ซึ่งอาจแบ่งกลุ่มตามการซื้อรายปี ข้อมูลทางภูมิศาสตร์ กลุ่มอายุ หรือเพศ สิ่งนี้อาจมีความสำคัญอย่างยิ่งสำหรับชุดข้อมูลที่มีหางยาว ซึ่งประสิทธิภาพของกลุ่มที่โดดเด่นอาจปกปิดประสิทธิภาพที่ยอมรับไม่ได้สำหรับกลุ่มที่สำคัญแต่มีขนาดเล็ก ตัวอย่างเช่น แบบจำลองของคุณอาจทำงานได้ดีสำหรับพนักงานทั่วไป แต่ล้มเหลวสำหรับเจ้าหน้าที่ระดับผู้บริหาร และอาจเป็นสิ่งสำคัญสำหรับคุณที่จะรู้เรื่องนี้
การวิเคราะห์แบบจำลองและการแสดงภาพ
หลังจากที่คุณดำเนินการเรียกใช้ข้อมูลครั้งแรกผ่านการฝึกอบรมโมเดลของคุณ และใช้งานส่วนประกอบ Evaluator (ซึ่งใช้ประโยชน์จาก TFMA ) กับผลลัพธ์การฝึกอบรมแล้ว คุณสามารถแสดงภาพผลลัพธ์ในสมุดบันทึกสไตล์ Jupyter ได้ สำหรับการวิ่งเพิ่มเติม คุณสามารถเปรียบเทียบผลลัพธ์เหล่านี้ในขณะที่คุณทำการปรับเปลี่ยน จนกว่าผลลัพธ์ของคุณจะเหมาะสมที่สุดสำหรับรุ่นและการใช้งานของคุณ
ขั้นแรกคุณจะต้องค้นหา ข้อมูลเมตาของ ML (MLMD) เพื่อค้นหาผลลัพธ์ของการดำเนินการของส่วนประกอบเหล่านี้ จากนั้นใช้ API การสนับสนุนการแสดงภาพใน TFMA เพื่อสร้างการแสดงภาพในสมุดบันทึกของคุณ ซึ่งรวมถึง tfma.load_eval_results และ tfma.view.render_slicing_metrics การใช้การแสดงภาพนี้จะทำให้คุณเข้าใจคุณลักษณะของโมเดลได้ดีขึ้น และหากจำเป็น ให้แก้ไขตามความจำเป็น
การตรวจสอบประสิทธิภาพของโมเดล
ในการวิเคราะห์ประสิทธิภาพของโมเดล คุณอาจต้องการตรวจสอบประสิทธิภาพเทียบกับข้อมูลพื้นฐาน (เช่น โมเดลที่ให้บริการในปัจจุบัน) การตรวจสอบความถูกต้องของแบบจำลองจะดำเนินการโดยการส่งทั้งแบบจำลองที่เป็นตัวเลือกและแบบจำลองพื้นฐานไปยังส่วนประกอบของ Evaluator ผู้ประเมินจะคำนวณหน่วยวัด (เช่น AUC, การสูญเสีย) สำหรับทั้งผู้สมัครและเกณฑ์พื้นฐานพร้อมกับชุดหน่วยวัดส่วนต่างที่สอดคล้องกัน จากนั้นเกณฑ์อาจถูกนำมาใช้และใช้เพื่อผลักดันโมเดลของคุณไปสู่การใช้งานจริง
การตรวจสอบความถูกต้องว่าโมเดลสามารถใช้งานได้
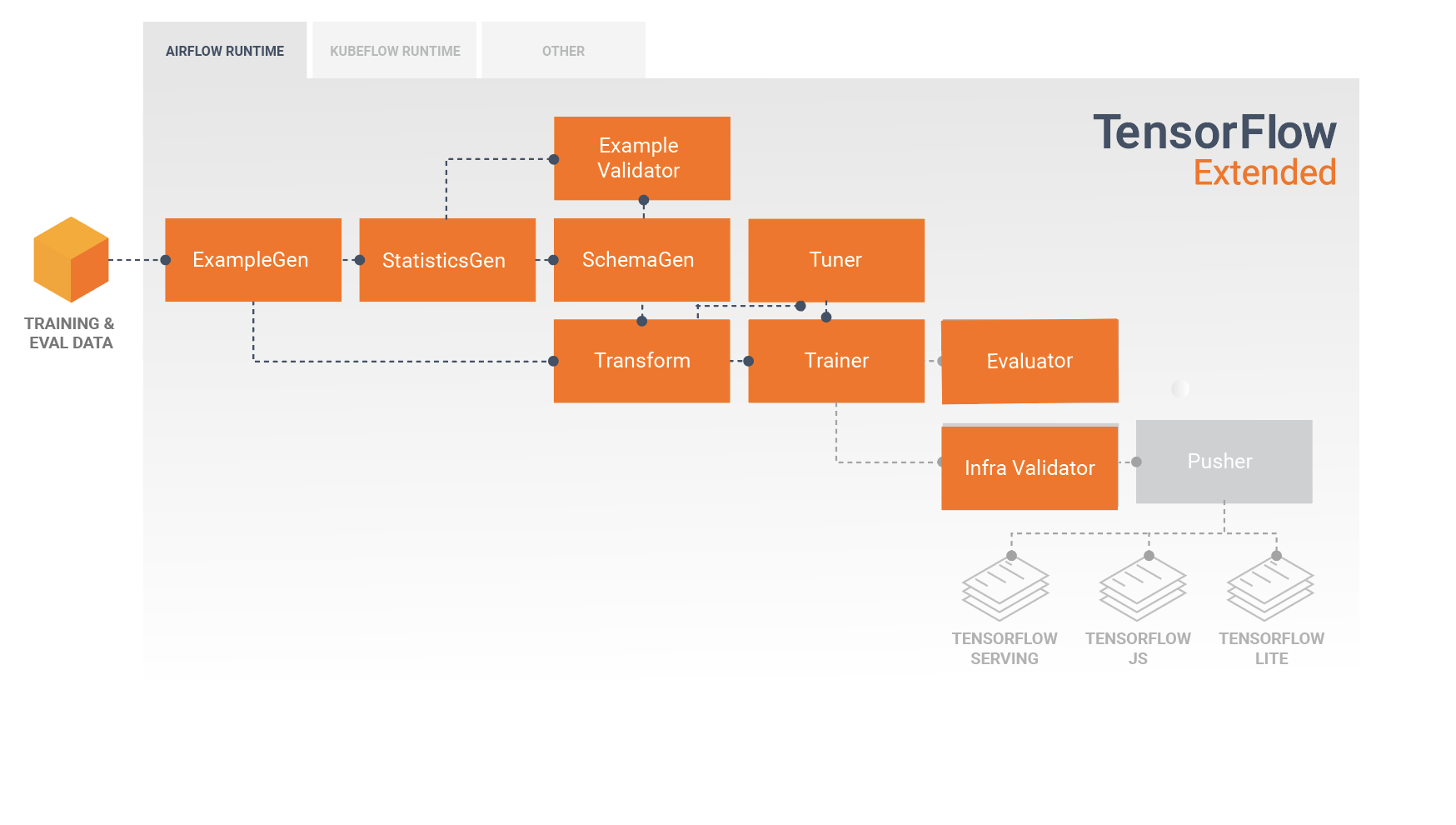
ก่อนที่จะปรับใช้โมเดลที่ผ่านการฝึกอบรม คุณอาจต้องการตรวจสอบว่าโมเดลนั้นให้บริการได้จริงในโครงสร้างพื้นฐานที่ให้บริการหรือไม่ นี่เป็นสิ่งสำคัญอย่างยิ่งในสภาพแวดล้อมการผลิตเพื่อให้แน่ใจว่าแบบจำลองที่เผยแพร่ใหม่ไม่ได้ป้องกันระบบจากการให้บริการการคาดการณ์ ส่วนประกอบ InfraValidator จะทำให้โมเดลของคุณใช้งานได้แบบคานารีในสภาพแวดล้อมแบบแซนด์บ็อกซ์ และอาจส่งคำขอจริงเพื่อตรวจสอบว่าโมเดลของคุณทำงานอย่างถูกต้องหรือไม่
เป้าหมายการปรับใช้
เมื่อคุณได้พัฒนาและฝึกอบรมโมเดลที่คุณพอใจแล้ว ก็ถึงเวลาปรับใช้โมเดลดังกล่าวกับเป้าหมายการปรับใช้ตั้งแต่หนึ่งเป้าหมายขึ้นไปซึ่งโมเดลจะได้รับคำขออนุมาน TFX รองรับการปรับใช้กับเป้าหมายการปรับใช้สามคลาส โมเดลที่ผ่านการฝึกอบรมซึ่งได้รับการส่งออกเป็น SavedModels สามารถปรับใช้กับเป้าหมายการปรับใช้เหล่านี้บางส่วนหรือทั้งหมดได้
การอนุมาน: การแสดง TensorFlow
TensorFlow Serving (TFS) คือระบบการให้บริการที่ยืดหยุ่นและมีประสิทธิภาพสูงสำหรับโมเดลการเรียนรู้ของเครื่อง ซึ่งออกแบบมาสำหรับสภาพแวดล้อมการใช้งานจริง ใช้ SavedModel และจะยอมรับคำขอการอนุมานผ่านอินเทอร์เฟซ REST หรือ gRPC โดยทำงานเป็นชุดของกระบวนการบนเซิร์ฟเวอร์เครือข่ายตั้งแต่หนึ่งเซิร์ฟเวอร์ขึ้นไป โดยใช้สถาปัตยกรรมขั้นสูงตัวใดตัวหนึ่งเพื่อจัดการการซิงโครไนซ์และการคำนวณแบบกระจาย ดู เอกสารประกอบ TFS สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการพัฒนาและการปรับใช้โซลูชัน TFS
ในไปป์ไลน์ทั่วไป SavedModel ซึ่งได้รับการฝึกฝนในส่วนประกอบ Trainer จะได้รับการตรวจสอบความถูกต้องโดยอินฟราเรดในส่วนประกอบ InfraValidator ก่อน InfraValidator เปิดตัวเซิร์ฟเวอร์โมเดล TFS canary เพื่อให้บริการ SavedModel จริงๆ หากผ่านการตรวจสอบแล้ว ส่วนประกอบ Pusher จะปรับใช้ SavedModel กับโครงสร้างพื้นฐาน TFS ของคุณในที่สุด ซึ่งรวมถึงการจัดการหลายเวอร์ชันและการอัปเดตโมเดล
การอนุมานในแอปพลิเคชัน Native Mobile และ IoT: TensorFlow Lite
TensorFlow Lite เป็นชุดเครื่องมือที่ช่วยให้นักพัฒนาใช้โมเดล TensorFlow ที่ได้รับการฝึกอบรมในแอปพลิเคชันมือถือและ IoT แบบเนทีฟโดยเฉพาะ ใช้ SavedModels เดียวกันกับ TensorFlow Serving และใช้การปรับให้เหมาะสม เช่น การหาปริมาณและการตัด เพื่อเพิ่มขนาดและประสิทธิภาพของโมเดลผลลัพธ์ให้เหมาะสมสำหรับความท้าทายในการทำงานบนอุปกรณ์เคลื่อนที่และอุปกรณ์ IoT ดูเอกสาร TensorFlow Lite สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการใช้ TensorFlow Lite
การอนุมานใน JavaScript: TensorFlow JS
TensorFlow JS เป็นไลบรารี JavaScript สำหรับการฝึกอบรมและปรับใช้โมเดล ML ในเบราว์เซอร์และบน Node.js โดยจะใช้ SavedModels เดียวกันกับ TensorFlow Serving และ TensorFlow Lite และแปลงเป็นรูปแบบเว็บของ TensorFlow.js ดูเอกสารประกอบของ TensorFlow JS สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับการใช้ TensorFlow JS
การสร้างไปป์ไลน์ TFX ด้วย Airflow
ตรวจสอบ เวิร์คช็อปการไหลเวียนของอากาศ เพื่อดูรายละเอียด
การสร้างไปป์ไลน์ TFX ด้วย Kubeflow
ตั้งค่า
Kubeflow ต้องใช้คลัสเตอร์ Kubernetes เพื่อเรียกใช้ไปป์ไลน์ในวงกว้าง ดูหลักเกณฑ์การปรับใช้ Kubeflow ที่แนะนำตัวเลือกต่างๆ สำหรับ การปรับใช้คลัสเตอร์ Kubeflow
กำหนดค่าและเรียกใช้ไปป์ไลน์ TFX
โปรดปฏิบัติตาม บทช่วยสอน TFX บน Cloud AI Platform Pipeline เพื่อเรียกใช้ไปป์ไลน์ตัวอย่าง TFX บน Kubeflow ส่วนประกอบ TFX ได้รับการบรรจุในคอนเทนเนอร์เพื่อเขียนไปป์ไลน์ Kubeflow และตัวอย่างแสดงให้เห็นถึงความสามารถในการกำหนดค่าไปป์ไลน์เพื่ออ่านชุดข้อมูลสาธารณะขนาดใหญ่ และดำเนินการฝึกอบรมและขั้นตอนการประมวลผลข้อมูลในวงกว้างในระบบคลาวด์
อินเทอร์เฟซบรรทัดคำสั่งสำหรับการดำเนินการไปป์ไลน์
TFX จัดเตรียม CLI แบบรวมซึ่งช่วยในการดำเนินการไปป์ไลน์อย่างเต็มรูปแบบ เช่น สร้าง อัปเดต เรียกใช้ แสดงรายการ และลบไปป์ไลน์บนตัวจัดการต่างๆ รวมถึง Apache Airflow, Apache Beam และ Kubeflow สำหรับรายละเอียด โปรดปฏิบัติตาม คำแนะนำเหล่านี้